
Part 2. 빅데이터 탐색
Chapter 01. 데이터 전처리
Section 01. 데이터 정제
- 데이터 관련 정의
- 데이터 : 사실/자료, 기호화/수치화된 자료
- 단위(Unit) : 관찰되는 항목
- 관측값 : 조사 단위별 기록 정보/특성
- 변수 : 각 단위에서 측정된 특성 결과
- 원 자료(Raw Data) : 정제를 거치지 않은 최초의 자료
데이터 종류
- 단변량 자료 : 특성 변수(자료의 특성을 대표)가 하나
- 다변량 자료 : 특성 변수 두 개 이상
- 질적 자료 : 정성적/범주형, 자료를 범주(Category)로 분류 => 명목자료/서열자료
- 수치 자료 : 정량적/연속적, 수의 크기에 의미를 부여(구간, 비율)
- 시계열 자료(
Time Series) : 일정 시간 간격 동안 수집, 시간 개념이 포함된 자료 (ex) 주식) - 횡적 자료(
Cross Sectional) : 횡단면 자료, 특정 단일 시점에 여러 대상으로부터 수집 - 종적 자료 : 시계열 + 횡적 자료
데이터 정제
-
분석에 필요한 데이터 추출 및 통합
: 데이터 구성의 일관성 향상 + 도출된 결과의 신뢰성 향상 -
비정형 데이터는 기본적으로 정형 데이터로 변환하면서 결측치, 오류 수정의 과정을 거침
정제 과정
: 데이터 수집 ▶ 변환 ▶ 교정 ▶ 통합
정제 방법
- 집계(
Aggregation)
: 데이터 요약 및 그룹화,SUM,AVG, 중앙값, 최빈값,MIN,MAX - 일반화(
Generalization)
: 일반적 특성/패턴 도출, 복잡성 ↓, 주요 특징 강조 - 정규화(
Normalization)
: 데이터 표준화, 수치형 데이터로의 변환, 상대적 비교 가능, Outlier에 대한 영향 감소 - 평활화(
Smoothing)
: 데이터 변동 감소, Noise 제거,이동평균법,지수평활법
1. 데이터 결측값 처리
결측치 : Missing Data
- 임의 제거
: 데이터 손실은 데이터 수집 실패로 이어질 수 있음 - 임의 대체
: bias 발생으로 이어져 결과의 신뢰성 저하따라서, 데이터에 기반한 결측치 처리 방안 필요
결측 데이터 종류
-
MCAR : 완전 무작위 결측
: 결측 데이터와 나머지 간 관계 X -
MAR : 무작위 결측
: 결측 데이터와 관측 데이터간 관계 O, 비관측 데이터간 관계 X -
NMAR : 비무작위 결측
: 결측 변수 값이 결측 이유와 관련
결측값 유형 분석 및 대치
- MCAR하에 처리 = 불완전 자료 무시 + 완전 관측 자료만으로 표준적 분석 수행
단, 효율성, 자료처리의 복잡성, bias 고려 필수
대치법
- 결측값을 처리하는 방식에서의 차이
1. 단순 대치법
- 기본적으로 MCAR, MAR로 판단
-
완전 분석 : 불완전 자료 완전 무시
=> 분식 용이성↑, 효율성↓ 및 통계적 추론 타당성↓ -
평균 대치법 : 결측치 = 데이터들의 평균
=> 효율성↑, 통게량 표준오차 과소 추정 -
회귀 대치법 : 회귀분석에 의한 예측치로 결측치 대치
=> 데이터 변동성 반응↑, 독립변수와 종속변수간 관계가 강할 수록 신뢰성이 올라감 -
단순 확률 대치법 : Hot-Deck 방법, 확률 추출에 의해 전체 데이터 중 무작위로 대치
-
최근접 대치법 : 전체 표본을 몇 개의 대체군으로 분류 → 응답 자료를 순서대로 정렬해 결측값 이전 데이터로 대치
=> 응답값 중복 사용 가능
2. 다충 대치법
-
통계적 효율성 및 일치성 문제를 보완함
:n개의 단순 대치 →n개의 새로운 자료에 대한 분석 시행 → 결과 통계량에 대해 통계량 및 분산 결합 -
다중 대치 단계
-
대치 단계
: 복수의 대치에 의한 결측을 대치한 데이터 생성 -
분석 단계
: 복수개의 Dataset에 대한 분석 시행 -
결합 단계
: 분석결과들에 대한 통계적 결합으로 결과 도출
-
2. 데이터 이상값 처리
Outlier
- 데이터 전처리 과정에서 발생
- 정상의 범주에서 벗어난 값
- 오차, 극단적인 값
=> 분석 결과의 왜곡 발생
이상치 종류
-
단변수
: 하나의 데이터 분포에서 발생하는 이상치 -
다변수
: 연결된 데이터 분포들에서 발생하는 이상치
이상치 발생 원인(비자연적 이상치)
: 입력 실수, 측정 오류, 실험 오류, 의도적 이상치, 자료처리 오류, 표본 오류(모집단에서 표본 추출 중 발생한 bias)
이상치 탐지
- 데이터 분포에 따라 종속변수가 단변량 인지 다변량 인지 고려
- 모수적(
Parametric) vs 비모수적(Non-Parametric)
비모수적 & 단변량
= 독립변수: 범주형, 종속변수: 수치형
-
시각화
- 상자 수염 그림(
Box-Plot)
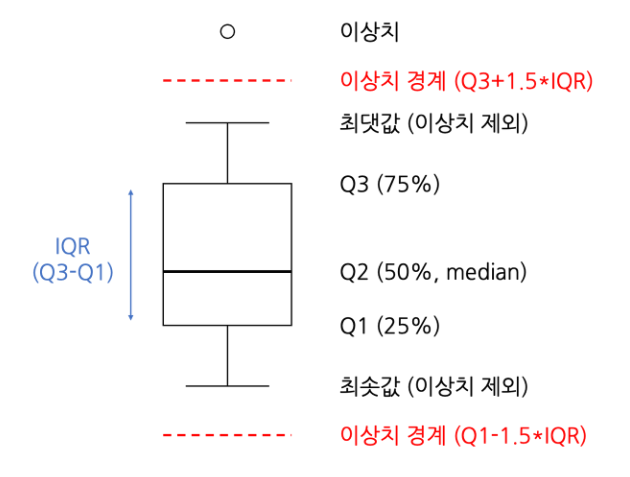
: 데이터 분포를 한 눈에 파악 가능
: 최소값, 최대값, 중앙값, 1사분위수(Q1, 25%), 3사분위수(Q3, 75%)
: 사분위 범위(A) =Q3 - Q1
: 최대값 =Q3 + 1.5 x A/ 최소값 =Q1 - 1.5 x A
: 이상치 =value > (Q3 + 1.5 x A)orvalue < (Q1 - 1.5 x A) - 상자 수염 그림(
모수적 & 단변량
-
Z-Score
: Data Point와 평균과의 거리를 표준편차 단위로 표현
=> 데이터가 정규 분포를 따른다는 가정 하에- 과정
- 데이터 정규화(평균 = 0, 표준편차 = 1)
- 정규화된 Data Point의
Z-Score계산 :Z = x−μ / σ 1σ: 68.27%,2σ: 95.45%,3σ: 99.73%
비모수적 & 다변량
-
DBSCAN
: 군집 간 밀도 이용
:특정 거리 내 데이터 수 > 지정 개수=> 군집 형성 -
고립의사나무 :
Isolation Forest
: 데이터가 다른 데이터들과 얼마나 분리되어있는지 측정- 과정
- Data Point 분할
- 분할 기준 설정
- 분할된 데이터 영역 계산
- 이상치 탐지
- 의사결정나무 생성
