
Section 02. 분석모형 개선
1. Overfitting 방지
1-1. 모델 복잡도 감소
- 정규화,
Dropout등을 통해 적절한 복잡도의 모델 탐색 - 가중치 매개변수(학습 중 지속적으로 가중치 변화) → 상수값 하이퍼 파라미터 사용\
1-2. 가중치 감소
- 큰 가중치 = 큰 패널티, 가중치의 절대값 감소
- 모델을 강제로 제한해 과적합 방지
- L2 규제
: 가중치 값을 비용함수 모델에 비해 작게 유지
: loss function + L2 norm^2 = 가중치 값을 비용함수 모델에 비해 작게
:L2 = ||w||^2 = ∑w^2
: 강도를 세게 할 수록 가중치는0에 가까워짐- 회귀 모델 + L2 규제 =
Ridge
- 회귀 모델 + L2 규제 =
- L1 규제
:L2 규제의 가중치 제곱을 절대값으로 변환
: loss function + L1 norm = 대부분의 특성 가중치를0으로
:L1 = ||w|| = ∑|w|- 회귀모델 + L1 규제 =
Lasso
- 회귀모델 + L1 규제 =
1-3. 편향-분산 Trade Off
- OverFitting ↔ UnderFitting 간 적절한 Trade Off 필요
: 절충점
2. 매개변수 최적화
-
신경망 학습이란?
: loss function 값을 최소화하는 매개변수 도출 -
매개변수 최적화
: loss funtion 값 최소화를 위한 매개변수의 최적값을 찾는 과정
2-1. 확률적 경사 하강법 : SGD
- loss function의 기울기 따라 매개변수 업데이트 → 가장 작은 지점에 도달
- 랜덤으로 선택한 하나의 데이터로만 계산해 단순, 명확함
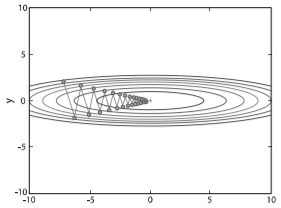
2-2. 모멘텀
SGD+ 관성물리법칙- 최적점 수렴 빠름
2-3. AdaGrad
- 개별 매개변수에 적응적 학습률 조정
- 최적점에 가까울수록 학습률↓
2-4. Adam
모멘텀+AdaGrad- 3개 파라미터로 구성
: 학습률 + 일차 모멘템 계수 + 이차 모멘텀 계수
2-5. Hyper Parameter 최적화
Hyper Parameter
: 사람이 직접 설정하는 매개변수
: 뉴런 수, 학습률, 배치 크기, 은닉층 수 등
-
학습률
: 기울기 방향으로 빠르게 이동하는 정도
:학습률 ∝ 1/학습시간,학습률 ∝ 발산 정도 -
미니배치 크기
: 전체 훈련 데이터를 Batch 크기로 나눈 것
:배치 크기 ∝ 병렬 연산 수 -
epoch
: 훈련 데이터가 신경망을 통과한 횟수 -
Iteration
: 하나의 미니배치 학습 시, 1Iteration = 1회 파라미터 업데이트
: 미니배치 수 = Iteration 수 -
은닉층 수
: 은닉층 수 증가 = 특정 훈련 데이터 최적화
: 모든 은닉층의 뉴런 수가 동일한 것이 더 효과적
3. 분석 모형 융합
3-1. 앙상블 학습
- 여러 분석 예측 모형 결합을 통해 하나의 예측 모형 도출
- 균형적 결과 도출, 변동성 및 과적합 여지 감소
Bagging,Boosting,Random Forest
3-2. 결합분석 모형
- 2개 이상의 결과 변수에 대해 동시 분석
- 결과변수 간 유의성/관련성 설명
4. 최종 모형 선정
4-1. 회귀모형 주요 성능 지표
-
SSE
:∑(실제값 - 예측값)^2 -
결정계수
R^2
: 회귀모형이 실제값에 적합한 비율 -
MAE
:1/n * ∑|실제값 - 예측값| -
MAPE
:MAE에서 실제값에 대한 상대적 비율 고려
4-2. 분류모형 주요 성능 지표
-
특이도(Specificity)
: 음성 중 실제 음성
:TN / TN + FP -
정밀도(Precision)
: 양성 중 실제 양성
:TP / TP + FP -
재현율(Recall)
: 전체 양성 중 맞춘 양성
:TP / TP + FN -
정확도(Accuracy)
: 전체 수 중 실제값을 맞춘 수
:TP + FN / TP + TN + FP + FN
4-3. 비지도학습 주요 성능 지표
- 군집분석
- 군집 타당성 지표
: 군집 간 거리, 군집의 지름, 군집의 분산
:Dunn Index,실루엣 계수
- 군집 타당성 지표
- 연관분석
지지도, 신뢰도 > 최소지지도

Being a Modern Project Manager