1. 기존 CNN (합성곱) 모델은 이미지 분류를 위해 지역 특징 추출
=> ex) 고양이 이미지의 왼쪽 눈 특징을 추출하고자 한다면, 해당 부분에 해당하는 1,2,3,4 번 패치만 사용
2. ViT 는 셀프 어텐션을 통해 모든 이미지 패치의 상관관계를 학습하여 전체 특징을 추출한다.
※ 따라서, CNN 은 좁은 Receptive Field를 가지고, 이것으로 전체 이미지 정보를 표현하려면 여러 계층 필요. 반면, ViT의 경우 어텐션 거리를 계산하여 오직 하나의 ViT레이어로 전체 이미지 정보 표현
※ CNN은 픽셀 단위로 처리, ViT는 패치 단위로 처리하여 더 작은 모델로 높은 성능 얻을 수 있음
ViT 모델 구조
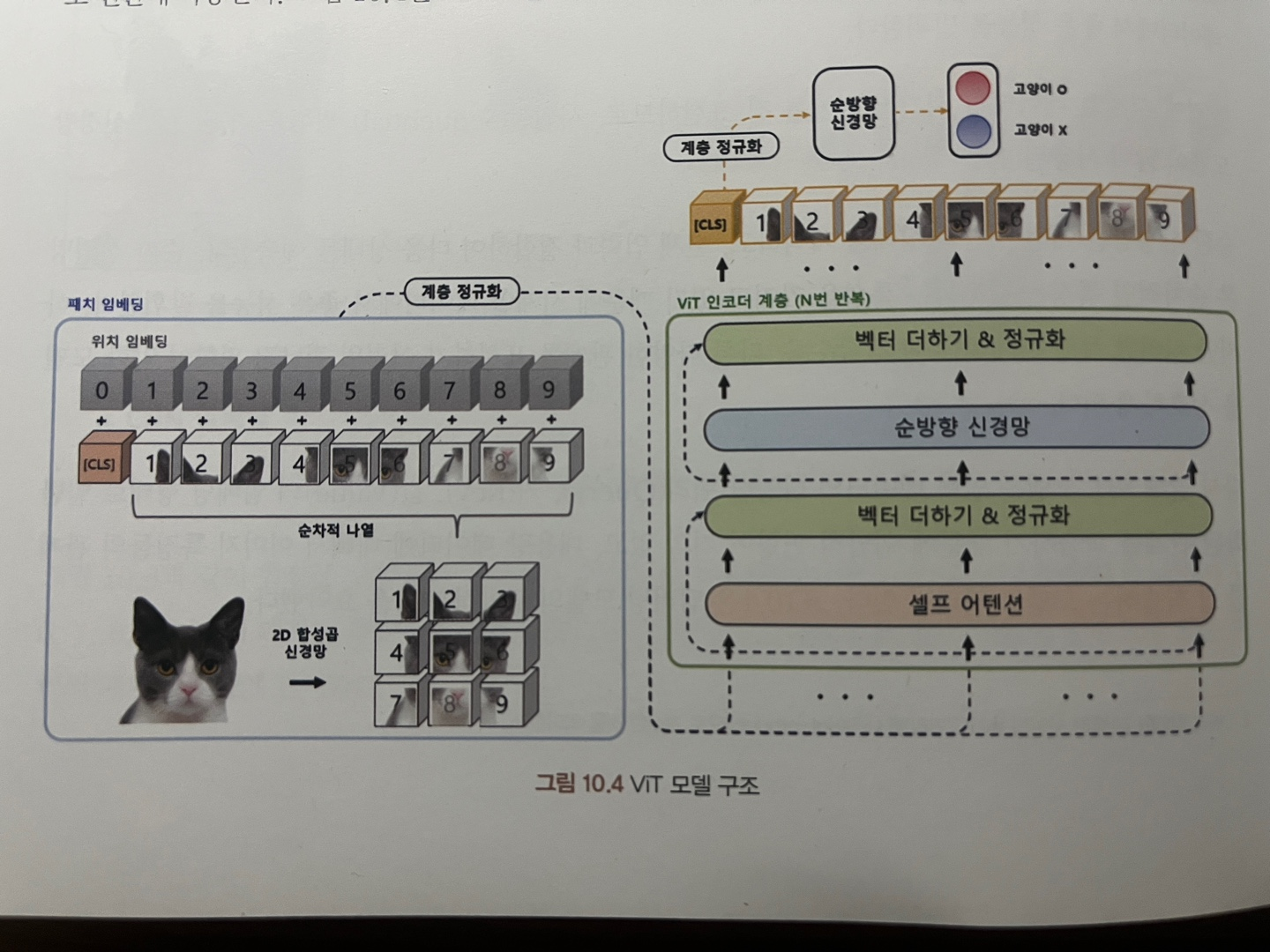
크게 다음과 같은 구조로 되어있다.
1단계 : 패치 임베딩
2단계 : 인코더 계층
3단계 : 분류나 회귀와 같은 작업에 맞는 출력값으로 변환
1단계 패치 임베딩
패치 임베딩은 입력 이미지를 작은 패치로 분할하는 과정
-
정방형 (224*224)와 같은 크기로 이미지 크기 전처리
-
CNN을 활용하여 전체 이미지를 패치 크기로 분할해 시퀀셜 배열을 만든다.
-
이 배열 가장 왼쪽에 분류 토큰(CLS)를 추가한다.
분류 토큰이란 전체 이미지를 대표하는 벡터로 특정 문제를 예측하는 데 사용한다. -
위치 임베딩을 사용하여 인접한 패치 간의 관계를 학습
위치 임베딩은 패치의 위치 정보를 임베딩 벡터로 변환하고 기존 이미지 패치 벡터들과 더한다.
- 계층 정규화 적용
2단계 인코더 계층
- N 개의 인코더 레이어를 반복적으로 적용
- 마지막 레이어에서는 분류 토큰(CLS)이라고 불리는 특별한 패치의 특징 벡터 추출
이 특징 벡터는 이후 다양한 이미지 분류 및 검색 문제를 해결하는 데 사용

Data Scientist (Computer Vision, Multimodal)