
내일의 나 화이팅..
링크드리스트
https://velog.io/@keemtj/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EB%A7%81%ED%81%AC%EB%93%9C-%EB%A6%AC%EC%8A%A4%ED%8A%B8Linked-List
https://ybworld.tistory.com/85
➜ 링크드 리스트 = 단방향 연결 리스트(singly linked list)
데이터 저장시 데이터를 저장하는 공간과 다음 데이터의 주소값을 동시에 가진다 (node = data + pointer)
시작 노드는 head 끝노드는 tail
트리 구조의 근간이 된다
파이썬에서는 리스트가 링크드리스트의 모든 기능을 지원한다
-> 그렇다고 파이썬 리스트=링크드리스트라고 할 순 없..을것같은뎅
class Node:
def __init__(self,data,next=None):
self.data=data
self.next=next
def add(data):
node = head
while node.next:
node = node.next
node.next = Node(data)
# 노드 객체 생성
node1 = Node(1)
# 맨 앞 노드 구분을 위해 head지정
head = node1
# 새로운 노드 추가
add(3)
# 여기선 while의 조건이 None(false)이기때문에 바로 node.next = Node(3) 행으로 넘어감장점
- 미리 공간을 할당할 필요가 없고 유동적으로 데이터 추가 삭제가 가능하다
- 수정시 시간복잡도 O(1) = 속도가 일정하다?
단점
- 연결을 위한 공간이 필요하여 저장공간의 효율이 낮다
- 연결정보를 찾는 시간이 필요하므로 데이터 접근 속도가 느리다 O(n)
배열처럼 특정 index가 존재하는 것이 아니라 링크를 따라서 순차적으로 확인해야한다 - 데이터의 추가나 삭제시 데이터간 연결의 재구성이 필수적이다(코드상으로도)
-> head를 삭제할 경우 다음 노드가 헤드가 되도록하고
tail을 삭제할 경우 직전 노드의 주솟값을 null/none로 변경한다
중간 노드를 삭제할 경우 삭제할 노드의 직전 노드의 포인터가 직후의 노드를 가리키도록 한다node.next.next
링크드리스트의 종류
- 이중 연결 리스트(양방향): 더 빠른 탐색이 가능
- 원형 연결 리스트
- 다중 연결 리스트
우선순위 큐 priority queue
우선순위가 높은 원소를 먼저 꺼내기 위해서 만들어진 자료구조
https://velog.io/@msung99/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%ED%81%90priority-queue
- 원소를 빼낼 때 우선순위가 높은 순(루트가 최고 우선 순위)으로 나오는 큐
- 원소의 추가 삭제시 O(logn) - 힙의 형태를 유지시키기 위함
push- 새 원소가 리프노드의 가장 마지막 우측에 추가되고 이후 새로운 원소가 힙의 오름차순/내림차순 조건을 만족할 때까지 upheap을 수행한다
삭제- 루트를 삭제시키고 리프노드의 가장 마지막 우측 노드(인덱스가 가장 큰 노드)를 루트의 위치로 옮겨서 downheap 수행 - 원소 조회시 O(1)
- 일반적으로 배열로 구현(0번인덱스사용하지않음)
- 느슨한 정렬상태
힙(완전이진트리)
- 최대 힙 = 부모가 가장 큼
- 최소 힙 = 부모가 가장 작음
- 부모의 인덱스가 i일 때 왼쪽 자식 2i 오른쪽 2i+1 -> 인덱스를 보통 1부터 시작함
부모의 인덱스를 찾을 때 본인 인덱스/2 - heap sort: 힙에 원소를 넣고 pop을하면 정렬된 상태로 원소들이 빠져나오는 것 O(nlogn)
https://m.blog.naver.com/kks227/220791188929
원래 큐는 push, pop, top 연산밖에 없다
https://hongjw1938.tistory.com/22
파이썬 리스트 정리
https://tagilog.tistory.com/1046
- 파이썬 리스트 안에는 모든 종류의 요소가 다 섞여서 들어갈 수 있음 -> 이러면 자료구조의 배열은 아니지않나? 둘 중 하나가 요소가 다 똑같은 타입이어야 한다고 했는데
- list=list(range(10)) -> 0-9까지가 요소로 들어간 리스트가 만들어짐
- list.append(여기 들어오는 애): 자체를 하나의 요소로써 추가해줌
- list.extend(여기 들어오는 애가): iterable(str,tuple,list)하다면 각각의 요소로 쪼개서 넣어줌. 딕셔너리가 들어가면 키값만 요소로 연장됨
x=['a','b']
y='cd'
x.append(y) # x=['a','b','cd']
x.extend(y) # x=['a','b','c','d']-
list.sort(): 원래 리스트를 정렬하고 수정해서 저장함 결과값이 none이므로 정렬의 결과를 다른 변수에 넣을 수 없음
object.method-> 메소드(데이터타입별로 존재. 객체와 함께 호출되어야함) -
sorted(list): 원래 리스트는 변하지 않고 결과값을 다른 변수에 넣어서 저장할 수 있음
내장함수-> 언어 자체에서 제공하는 함수
TCP/IP
https://coding-factory.tistory.com/613
TCP:
최상위 게층인 TCP(데이터를 패킷으로 컴파일)도 있고 동료 TCP계층(패킷을 받아서 데이터로 변환, 손상이 있으면 재전송을 요청하는 패킷을 전송해서 다시 받음)도 있나봄
IP: Internet Protocol
- 인터넷에서 컴퓨터의 위치를 찾아서 데이터를 전송하기 위해 지켜야 할 규약
- IP주소는 각 컴퓨터마다 가지고 있는 고유한 주소
- IP는 4개의 숫자로 구성되며 숫자의 크기에 따라 IPv4(32비트, 각 숫자는 1바이트), IPv6(128비트, 각 숫자는 4바이트)로 나뉩니다. 일반적으로는 IPv4는 10진수로 표현하며 각 자리는 .으로 구분하고, IPv6는 각 자리를 4자리 16진수로 표현하며 각 자리는 :로 구분합니다.
맨 아래 계층인 IP는 올바른 목적지를 찾는 패킷 GPS 역할을합니다.
TCP/IP 4계층 = OSI 7계층 추상화
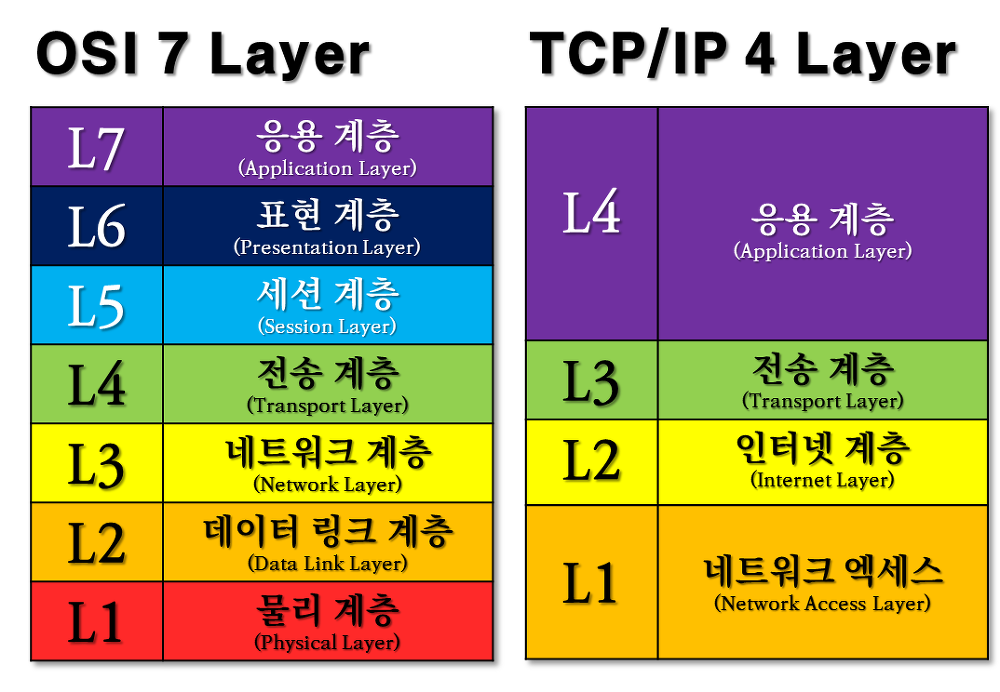
1게층: MAC사용, 에러검출, TCP/IP패킷을 네트워크 매체로 전달하고 받아들임
2계층: 어드레싱, 패키징, 라우팅기능. 네트워크상 최종 목적지까지 연결
3계층(7-4): 신뢰성있는 데이터 전송 TCP, UDP
4계층(7-5,6,7):데이터를 받는 곳 HTTP, SSH
제발 창 열어놓고 낼 봐야지 하지말자... 어제의 나 반성해..
DEL 상태코드
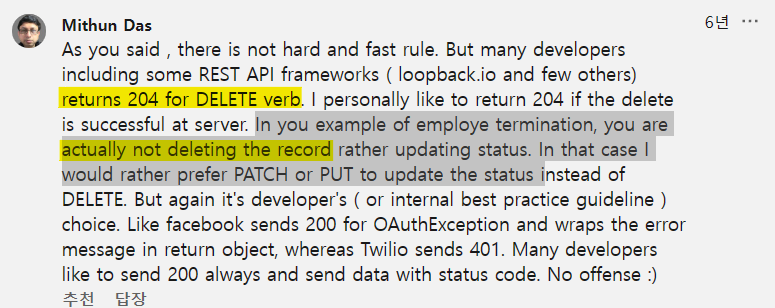
삭제시 204해서 오류났었던 거 기록해뒀던 것 같은데 어디있는지 모르겠다
서버에서 삭제가 그때 제대로 안됐었던건가??? 왜 오류났었지 제대로 삭제되면 이렇게해도 된다는데..
그때 200으로 고쳤던 것 같은데 찾아내야지 ..
JWT signature

역시 그림 최고
베이스 64로 인코딩한 헤더와 페이로드
거기에 시크릿키 합친걸 헤더에서 정의한 알고리즘으로 다시 암호화
HTTP VS HTTPS
HTTP:
- 평문(plain text) 데이터를 전송 -> 암호화가 되어있지 않아서 제3자가 조회할 수 있다
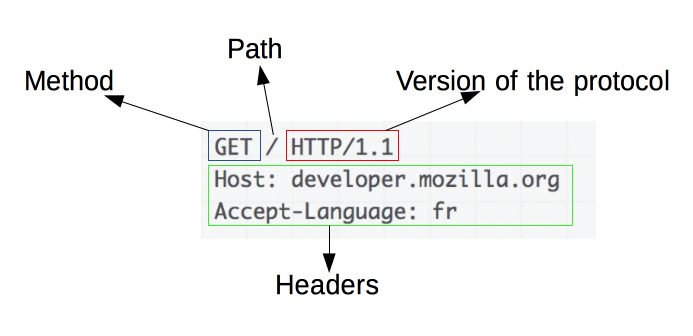
➜ HTTP는 어플리케이션 레벨의 프로토콜로 TCP/IP위에서 작동한다
STATELESS하며 METHOD, PATH, VERSION, HEADERS, BODY로 이뤄져있다
HTTPS:
-
HTTP over SSL, HTTP over TLS, HTTP Secure
-
HTTPS는 SSL인증서를 사용하여 HTTP를 보다 안전하게
-
HTTPS는 HTTP보다 더 안전한 보안용 프로토콜 속도는 아래 과정들때문에 조금 더 느리지만 거의 차이 안남
-
SSL(또는 TLS) 인증서는 일반 HTTP 요청 및 응답을 암호화
-
HTTPS를 사용한 웹 페이지를 통해 전송되는 모든 데이터는 추가적인 보안 계층이 있습니다
-
443번 포트 사용
-
대칭키(클라이언트와 서버가 동일한 키로 암호화 및 복호화를 함. 키 노출시 위험하나 속도가 빠름)와 비대칭키(1쌍의 공개키와 개인키-나만(서버)알고있어야함-를 암호화 및 복호화에 사용함. 키가 노출되어도 안전하지만 연산이 느림)가 있음
- 공개키 암호화: 공개키로 암호화를 하면 개인키로만 복호화할 수 있다. → 개인키는 나만 가지고 있으므로, 나만 볼 수 있다.
- 개인키 암호화: 개인키로 암호화하면 공개키로만 복호화할 수 있다. → 공개키는 모두에게 공개되어 있으므로, 내가 인증한 정보임을 알려 신뢰성을 보장할 수 있다.
HTTPS 연결 과정(Hand-Shaking) ✨
클라이언트(브라우저)가 서버로 최초 연결 시도를 함
서버는 공개키(엄밀히는 인증서)를 브라우저에게 넘겨줌
브라우저는 인증서의 유효성을 검사하고 세션키(대칭키)를 발급함
브라우저는 세션키를 보관하며 추가로 서버의 공개키로 세션키를 암호화하여 서버로 전송함
서버는 개인키로 암호화된 세션키를 복호화하여 세션키를 얻음
클라이언트와 서버는 동일한 세션키를 공유하므로 데이터를 전달할 때 세션키로 암호화/복호화를 진행함
➜ 세션키를 공유할 땐 안전성이 필요하므로 비대칭키를 사용, 안전성이 확보된 후 데이터를 교환하는 과정에선 빠른 연산이 필요하므로 대칭키를 사용
참고) 서버가 비대칭키를 발급받는 과정: https://mangkyu.tistory.com/98

메소드는 변수 객체 자체 값을 바꾸고 x.append(y)는 none이라구 아까 했자나..?