
프로그래머스 문제풀기
➡️ 같은 숫자는 싫어
def no_continuous(s):
a = []
for i in s:
if a[-1:] == [i]: continue
# a의 가장 마지막 값만 담은 리스트랑 주어진 배열의 값을 리스트로 비교
a.append(i)
# 같지 않으면 append
return a슬라이싱은 인덱스값이 범위 초과해도 오류 안떠요
슬라이싱은 인덱스값이 범위 초과해도 오류 안떠요
슬라이싱은 인덱스값이 범위 초과해도 오류 안떠요
슬라이싱은 인덱스값이 범위 초과해도 오류 안떠요
슬라이싱은 인덱스값이 범위 초과해도 오류 안떠요
def no_continuous(s):
result = []
for c in s:
if (len(result) == 0) or (result[-1] != c):
# 처음 배열이 비어있을 때는 무조건 넣고
# 마지막 값이 c와 다르면 c를 append하면
# c는 순서대로 result에 들어감
result.append(c)
return result아 나도 진짜 range(len())그만 쓰고 싶다.. 난 왜 이걸 안쓰고 못할까......................
result[-1]
어차피 한개씩만 비교하는거고 append해서 뒤에 붙이는 거니까 맨 뒷 값만 생각하면 되는데 자꾸 걔의 길이를 모르면 인덱스를 모르면 못한다고 생각하지말라고?
enumerate() 만 써도 range(len())안써도 인덱스 값 나오는데..
def no_continuous(s):
s = list(s)
print('s:',s) # = print(s)
# s가 리스트여도 list(s)는 걍 리스트로 나옴
# s: [1, 3, 3, 0, 1, 1, 2, 2, 2, 2, 1]
j = 0
for i in range(len(s)-1):
if s[i+1+j] == s[i+j]:
# j값이 변하든 변하지 않든 두 요소의 인덱스 값의 차이는 항상 1임
del s[i+j]
# 요소를 하나 삭제하면 뒤의 요소들의 인덱스 값이 하나씩 작아지니까 j 값을 하나씩 줄임
j -= 1
return s➡️ 더 맵게
여기서 주의사항은 인덱스 0에 가장 작은 원소가 있다고 해서, 인덱스 1에 두번째 작은 원소, 인덱스 2에 세번째 작은 원소가 있다는 보장은 없다는 것입니다. 왜냐하면 힙은 heappop() 함수를 호출하여 원소를 삭제할 때마다
이진 트리의 재배치를 통해 매번 새로운 최소값을 인덱스 0에 위치시키기 때문입니다.따라서 두번째로 작은 원소를 얻으려면 바로 heap[1]으로 접근하면 안되고, 반드시 heappop()을 통해 가장 작은 원소를 삭제 후에 heap[0]를 통해 새로운 최소값에 접근해야 합니다.
https://www.daleseo.com/python-heapq/
from heapq import heapify,heappop,heappush
def solution(scoville, K):
count=0
heapify(scoville)
while scoville[0]<K:
if len(scoville)<2:
return -1
min1=heappop(scoville)
min2=heappop(scoville)
new=min1+min2*2
heappush(scoville,new)
count+=1
return count힙 리스트의 길이가 1인 경우 if문이 아래에 있으면 IndexError: index out of range 에러가 남

while에 애초에 길이 조건을 같이 걸어주고
while에 들어갈 길이에 해당하지 않을 경우엔 밖의 if문에 따라 리턴 값이 달라짐
계산을 다 끝낸 후에 조건에 따라서 분기를 나누니까 깔끔하고 보기가 좋은듯?
토끼반
다이내믹 프로그래밍 = 점화식(규칙성을 파악해서 식을 세운다)
- 포도주
모든 포도주의 양을 먼저 보고
첫번째+두번째만큼 먹을 수 있음
두번째+세번째만큼 먹거나 첫번째+세번째만큼 먹을 수 있음
몇번째까지 먹었을때 쵀대로 먹을 수 있는 포도주양을 기억해야함
- 더 맵게
파이썬 라이브러리를 이용해서 heapq 힙을 만들어서 heapify → 정렬이 자동으로됨
heappop, heappush를 해주면 간단한
최솟값과 최댓값을 이용하면서 범위가 넓으면 heap으로 푼다고 생각할 수 있다
- 시간 복잡도와 공간 복잡도
메모리의 양과 코드의 뭐를 뭐?
복습하는 게 먼저다
자료구조와 알고리즘을 배워야하는 이유: 성능, 용량, 결국 비용 때문
성능의 척도: 시간 복잡도
메모리 사용량의 척도: 공간 복잡도
알고리즘의 시간복잡도는 빅오표기법: 최악의 경우를 산정함
o(1)<o(n)<o(nlogn)<o(n^2)<o(2^n)<o(n!)
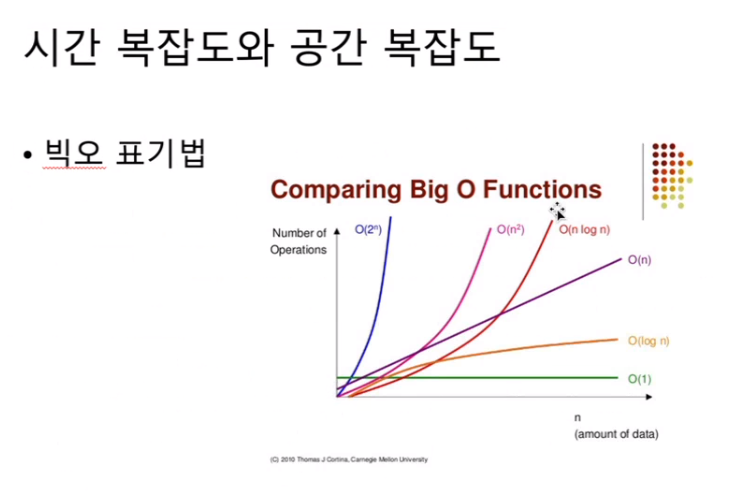
메모리 관리 기술(페이징~~)덕에 공간 복잡도는 크게 중요하지 않음
- 정리
탐욕법
해시: 빠른 입출력이 가능한 표 형태의 데이터(데이터 짝짓기)
정렬 알고리즘 찾아보기 - 파이썬 정렬 내장함수는 o(nlogn)
스택, 큐
...

한시간 넘어가면 해설 보기
