
JPA를 사용하다 보면 'N+1 문제'라는 용어를 자주 접하게 된다. 이 문제는 JPA를 통해 데이터를 조회할 때 연관된 엔티티를 조회하는 과정에서 발생하는 비효율적인 쿼리 문제를 말한다. 쉽게 말해, 하나의 쿼리로 원하는 데이터를 조회하고 나면, 연관된 엔티티들을 추가로 N번 반복해서 조회하는 쿼리가 발생하여 성능 문제가 발생하는 것을 의미한다. 이러한 문제는 데이터베이스에 불필요한 쿼리를 다수 생성하여 응답 시간을 느리게 하고, 서버의 부하를 증가시킨다.
내가 개발하는 프로젝트에서 n+1 문제가 발생할만한 데이터 조회를 하지 않아서 처음에는 n+1문제에 대해서 크게 신경을 쓰지 않았다. 그러나 관리자관련 api를 작성하려고 전체 데이터를 조회하려는데 불필요한 쿼리가 굉장히 많이 발생하는 것을 확인하였고, n+1문제에 대해 실감하여 해결하기 시작하였다.
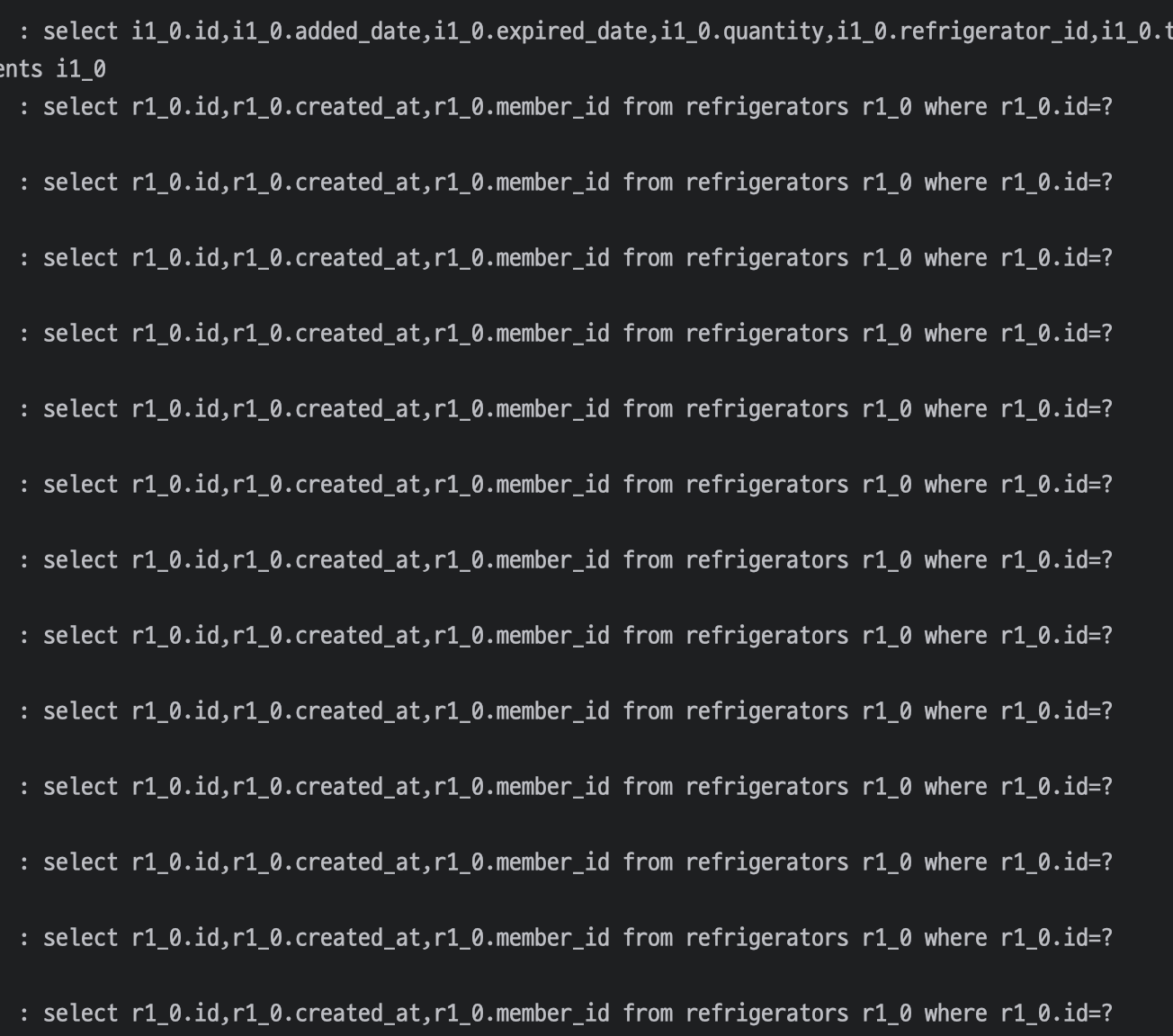
기존 도메인 상황
먼저, 내 프로젝트에 존재하는 도메인에 대해서 살펴보려고 한다. 연관관계 맵핑이 되어있는 도메인은 2개가 있는데 각각 OneToMany, ManyToOne으로 구성되어 있다. 처음에는 단방향으로 설정하였지만 양쪽 모두에서 데이터 조회가 필요한 로직이 발생하여 양방향으로 바꾸었다.
하나의 냉장고안에 여러 개의 재료가 들어있는 상태이다. 이때, 연관관계의 주인은 재료로 설정하였다.
public class Refrigerator {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private Long memberId;
@OneToMany(mappedBy = "refrigerator", cascade = CascadeType.ALL, orphanRemoval = true)
@JsonManagedReference
private List<Ingredient> ingredients = new ArrayList<>();
@CreatedDate
LocalDateTime createdAt;
}public class Ingredient {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private IngredientType type;
@Column(nullable = false)
private int quantity;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private UnitType unitType;
@CreatedDate
private LocalDate addedDate;
@Column(nullable = false)
private LocalDate expiredDate;
@ManyToOne
@JoinColumn(name = "refrigerator_id")
@JsonBackReference
private Refrigerator refrigerator;
public void updateQuantity(int quantity) {
this.quantity = quantity;
}
}위와 같이 mappedBy 옵션과 JoinColumn을 사용해서 연관관계 주인을 명시해주었다.
문제 발생
n+1문제를 확인하고 정확히 볼 수 있도록 테스트 코드를 작성하였다.
@Test
@DisplayName("냉장고 조회시, n+1문제 발생 확인")
public void testNPlusOneProblemInRefrigerators() {
System.out.println("-------- 냉장고 전체 조회 요청 --------");
List<Refrigerator> refrigerators = refrigeratorRepository.findAll();
System.out.println("-------- 냉장고 조회 완료 --------");
refrigerators.forEach(refrigerator -> {
System.out.println("Refrigerator ID: " + refrigerator.getId());
refrigerator.getIngredients().forEach(ingredient -> {
System.out.println(" Ingredient Type: " + ingredient.getType() +
", Quantity: " + ingredient.getQuantity() +
", Unit: " + ingredient.getUnitType());
});
});
}
@Test
@DisplayName("재료 조회시, n+1문제 발생 확인")
public void testNPlusOneProblemInIngredients() {
System.out.println("-------- 재료 전체 조회 요청 --------");
List<Ingredient> ingredients = ingredientRepository.findAll();
System.out.println("-------- 재료 조회 완료 --------");
ingredients.forEach(ingredient -> {
System.out.println("Ingredients ID: " + ingredient.getId());
});
}먼저 현재 테스트용 데이터베이스에는 냉장고 10개를 생성하고 각 냉장고에 2개의 재료를 넣어놓은 상태이다. 만약 존재하는 모든 냉장고나 재료를 조회하는 쿼리를 발생시켰을 때 SELECT FROM refrigerators 또는 SELECT FROM ingredients가 한번만 실행되어야 한다. 그러나 위 테스트의 결과를 보면 그렇지 않다는 것을 확인할 수 있다.
냉장고 전체 조회 결과
-------- 냉장고 전체 조회 요청 --------
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0
-------- 냉장고 조회 완료 --------
Refrigerator ID: 1
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 2
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 3
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 4
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 5
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 6
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 7
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 8
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 9
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER
Refrigerator ID: 10
Hibernate: select i1_0.refrigerator_id,i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.type,i1_0.unit_type from ingredients i1_0 where i1_0.refrigerator_id=?
Ingredient Type: EGG, Quantity: 10, Unit: COUNT
Ingredient Type: MILK, Quantity: 2, Unit: LITER냉장고를 조회하는 요청에는 하나의 쿼리가 발생하였지만 불러온 냉장고에서 냉장고에 들어있는 재료를 확인하려 했더니 냉장고의 개수만큼 추가로 10개의 쿼리가 발생하였다. 냉장고와 관련된 재료 데이터는 기본적으로 LAZY 로딩 전략을 사용하므로 냉장고만 조회했을 경우 하나의 쿼리가 실행되지만, 냉장고의 각 재료를 접근할 때마다 결국 냉장고의 개수만큼 추가로 쿼리가 발생하는 것이다. Fetch.Lazy는 결국 n+1 문제의 발생 시점을 늦출 뿐이다.
재료 전체 조회 결과
-------- 재료 전체 조회 요청 --------
Hibernate: select i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,i1_0.refrigerator_id,i1_0.type,i1_0.unit_type from ingredients i1_0
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
Hibernate: select r1_0.id,r1_0.created_at,r1_0.member_id from refrigerators r1_0 where r1_0.id=?
-------- 재료 조회 완료 --------
Ingredients ID: 1
Ingredients ID: 2
Ingredients ID: 3
Ingredients ID: 4
Ingredients ID: 5
Ingredients ID: 6
Ingredients ID: 7
Ingredients ID: 8
Ingredients ID: 9
Ingredients ID: 10
Ingredients ID: 11
Ingredients ID: 12
Ingredients ID: 13
Ingredients ID: 14
Ingredients ID: 15
Ingredients ID: 16
Ingredients ID: 17
Ingredients ID: 18
Ingredients ID: 19
Ingredients ID: 20재료를 조회하는 테스트의 결과에서는 재료를 조회하는 쿼리가 1개 발생한 이우, 냉장고 데이터를 조회하는 쿼리가 재료의 수만큼 반복되어서 나타났다.
문제 해결
냉장고, 재료를 조회하는 로직에서 서로의 연관관계가 단방향으로 보면 다르기 때문에 각각 다른 문제 해결 방법을 적용해야 한다.
재료 전체 조회시 발생하는 문제 해결 (@ManyToOne 관계로 연관된 데이터가 조회)
먼저, 재료를 조회하면서 냉장고를 함께 조회하였을 때의 경우이다. 위에서는 두번 째 문제 발생 상황이라고 생각하면 된다.
1. Fetch Join
Fetch Join은 JPQL에서 연관된 엔티티를 한 번에 조회하도록 돕는 기능이다. 이를 통해 불필요한 N번의 추가 쿼리를 줄일 수 있다. 앞서 언급한 재료 조회시 사용되는 Repository에 아래와 같이 추가 쿼리를 작성해야한다.
@Query("select i from Ingredient i join fetch i.refrigerator")
List<Ingredient> findAll();Fetch Join을 적용한 다음 다시 재료 전체 조회 테스트를 진행해본 결과 아래와 같이 재료를 조회하는 하나의 쿼리만 발생한 것을 확인하였다.
-------- 재료 전체 조회 요청 --------
Hibernate: select i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,r1_0.id,r1_0.created_at,r1_0.member_id,i1_0.type,i1_0.unit_type from ingredients i1_0 join refrigerators r1_0 on r1_0.id=i1_0.refrigerator_id
-------- 재료 조회 완료 --------
Ingredients ID: 1
Ingredients ID: 2
Ingredients ID: 3
Ingredients ID: 4
Ingredients ID: 5
Ingredients ID: 6
Ingredients ID: 7
Ingredients ID: 8
Ingredients ID: 9
Ingredients ID: 10
Ingredients ID: 11
Ingredients ID: 12
Ingredients ID: 13
Ingredients ID: 14
Ingredients ID: 15
Ingredients ID: 16
Ingredients ID: 17
Ingredients ID: 18
Ingredients ID: 19
Ingredients ID: 20단 한번의 쿼리 조회만으로 모든 재료의 아이디를 가져온 것이다.
2. Entity Graph
EntityGraph는 JPA에서 제공하는 n+1 문제의 또 다른 해결 방법이다. 특정 엔티티를 조회할 때 연관된 엔티티를 함께 로딩하도록 설정할 수 있으며, 이는 Fetch Join과 유사한 방식으로 동작한다고 생각하면다. 단, Fetch Join과 다른 점은 하드 코딩을 하지 않아도 된다는 점에서 Entity Graph만의 장점을 가진다. AttributePaths로 연관관계를 맺어줘서 해당 엔티티를 fetch join으로 조회할 수 있게 해준다.
적용하는 방법은 Fetch Join과 마찬가지고 Repository코드에 아래와 같이 어노테이션을 추가하면 된다.
@EntityGraph(attributePaths = {"refrigerator"})
List<Ingredient> findAll();위와 같이 적용하고 나서의 결과는 아래와 같다.
-------- 재료 전체 조회 요청 --------
Hibernate: select i1_0.id,i1_0.added_date,i1_0.expired_date,i1_0.quantity,r1_0.id,r1_0.created_at,r1_0.member_id,i1_0.type,i1_0.unit_type from ingredients i1_0 left join refrigerators r1_0 on r1_0.id=i1_0.refrigerator_id
-------- 재료 조회 완료 --------
Ingredients ID: 1
Ingredients ID: 2
Ingredients ID: 3
Ingredients ID: 4
Ingredients ID: 5
Ingredients ID: 6
Ingredients ID: 7
Ingredients ID: 8
Ingredients ID: 9
Ingredients ID: 10
Ingredients ID: 11
Ingredients ID: 12
Ingredients ID: 13
Ingredients ID: 14
Ingredients ID: 15
Ingredients ID: 16
Ingredients ID: 17
Ingredients ID: 18
Ingredients ID: 19
Ingredients ID: 20Fetch Join과 마찬가지도 재료 전체 조회에 대한 하나의 쿼리만 발생하였다. 그러나 Fetch Join 과 EntityGraph를 적용하였을 때의 발생하는 쿼리가 조금씩 다른 것을 확인하였다.
Inner Join VS Left Join
먼저 Fetch Join을 사용했을 때의 쿼리는 Inner Join 기법을 활용한다. Inner join은 두 테이블에 공통적으로 매칭되는 데이터만 결과로 반환한다. 즉, ingredients.refrigerator_id와 refrigerators.id가 매칭되는 경우에만 레코드가 선택된다. 그러므로 ingredients 테이블에 refrigerator_id가 NULL이거나, refrigerators 테이블에 해당 id가 없는 경우, 해당 ingredients 데이터는 반환되지 않는다.
반면, EntityGraph를 사용했을 때의 쿼리는 Left Join 기법을 활용한다. 말 그대로 왼쪽 테이블의 데이터를 기준으로 데이터를 가져온다. Inner Join과 다른 특징으로는 매칭되지 않은 데이터도 반환된다는 점이다. 즉, 데이터가 매칭이 되지 않는 경우에도 왼쪽 테이블의 데이터는 항상 포함되며, 오른쪽 테이블의 값은 NULL로 표기된다.
만약 매칭되는 데이터만 보고 싶을 때는 Inner Join을 사용하는 Fetch Join을 사용하면 되고 모든 데이터를 확인하고 싶을 때는 Left Join을 사용하는 EntityGraph를 사용하면 된다.
기본적으로는 join 기법이 위의 설명과 같이 사용되지만 JPA 설정에 따라 inner, left join이 fetch join, entity graph 둘 다 사용될 수 있으므로 이에 대해서는 명확히 알아보고 사용하길 바란다!
냉장고 전체 조회시 발생하는 문제 해결 (@OneToMany 관계로 연관된 데이터가 조회)
다음으로, 냉장고를 조회하면서 재료를 함께 조회하였을 경우이다. 문제 상황에서 첫 번째 상황이라고 생각하면 된다.
Batch Size 설정
배치 사이즈란 데이터베이스에서 관련된 엔티티들을 한꺼번에 가져오기 위해 설정하는 엔티티의 묶음 크기를 의미한다. 이를 통해 연관된 엔티티들을 한 번의 쿼리로 일정량씩 가져옴으로써 데이터베이스 접근 횟수를 줄이는 역할을 한다. 즉, n+1 문제를 해결하는데 효과적인 기법으로, 쿼리의 수를 최소화하여 성능을 개선할 수 있다.
Batch Size 적용하기
@BatchSize 어노테이션을 사용하여 배치 사이즈를 지정할 수 있다.
@OneToMany(mappedBy = "refrigerator", cascade = CascadeType.ALL, orphanRemoval = true)
@BatchSize(size = 100)
@JsonManagedReference
private List<Ingredient> ingredients = new ArrayList<>();위의 코드에서 @BatchSize(size = 10)을 사용하여 연관된 자식 엔티티인 ingredients를 10개씩 한 번에 가져오도록 설정하였다. 이를 통해, 부모 엔티티와 연관된 자식 엔티티들을 각각 따로 조회하지 않고, 배치 사이즈로 설정된 개수만큼 한 번에 로딩하여 데이터베이스 쿼리 횟수를 줄인다.
이와 같은 배치 페치(batch fetch) 기법은 연관된 데이터가 많을 때 특히 유용하다. 만약 연관된 데이터가 50개라면, 배치 사이즈가 10일 경우 데이터베이스는 5번의 쿼리를 통해 모든 자식 데이터를 가져오게 되므로, n+1 문제를 해결할 수 있을 뿐만 아니라 성능상에서도 큰 이점을 얻을 수 있다.
배치 사이즈 설정 전략: 경험을 바탕으로 한 최적화 방안
n+1 문제를 해결하기 위해 배치 사이즈(Batch Size)를 설정할 때, 모든 상황에서 동일한 값을 사용하는 것은 최적의 선택이 아닐 수 있다. 실제 개발 경험에서 적절한 배치 사이즈를 설정하지 않았을 때 발생했던 문제를 통해, 배치 사이즈 설정 전략에 대해 몇 가지 중요한 시사점을 얻을 수 있었다. 이를 바탕으로 배치 사이즈를 설정하는 전략을 다시 정리해보려고 한다.
- 배치 사이즈와 데이터 수의 관계
- 배치 사이즈는 실제 데이터 수와의 관계를 고려해야 한다. 실제 데이터 수보다 배치 사이즈가 클 경우, ORM 프레임워크가 데이터를 최적화된 방식으로 캐싱할 수 없게 되어, 예상하지 못한 쿼리의 수와 불규칙한 데이터 로딩 패턴이 발생할 수 있다. 이는 Hibernate가 배치 사이즈를 최적화하기 위해 절반씩 나누는 방식으로 캐싱을 수행하기 때문이다.
- 예를 들어, 배치 사이즈가 100으로 설정되었지만 실제 데이터 수가 20개일 경우, 쿼리가 예상하지 못한 12개와 8개로 나뉘어 발생하게 되는 현상이 있었다. 이러한 현상은 Hibernate가 배치 사이즈를 효율적으로 캐싱하기 위해 절반 단위로 나누어 저장하는 최적화 전략을 사용하기 때문이다. 따라서 배치 사이즈를 설정할 때는 데이터의 실제 수와 유사하게 맞추는 것이 좋다.
- 배치 사이즈 설정 시 고려사항
-
데이터 수가 많은 경우
- 데이터 수가 많을 경우, 일반적으로 권장되는 배치 사이즈(100~1000)를 사용하는 것이 적합하다. 이러한 큰 배치 사이즈는 많은 데이터를 한 번에 효율적으로 로딩하여 n+1 문제를 해결할 수 있다.
- 예를 들어, 사용자가 한 번에 다수의 게시글과 댓글을 로딩할 때, 배치 사이즈를 크게 설정하여 in 연산자를 활용함으로써 데이터베이스 접근 횟수를 줄이는 것이 효과적이다.
-
데이터 수가 적은 경우
- 데이터 수가 적다면 배치 사이즈를 실제 데이터 수보다 약간 작거나 근접하게 설정하는 것이 좋다. 예를 들어, 데이터 수가 20개일 경우 배치 사이즈를 40으로 설정하면 불필요한 추가 쿼리 분할 없이 한 번에 모든 데이터를 가져올 수 있다.
- 배치 사이즈가 실제 데이터 수보다 클 경우, Hibernate는 최적화를 위해 캐싱할 때 절반씩 나누는 방식으로 데이터를 가져오므로 쿼리가 여러 번 발생하게 된다. 따라서, 데이터 수에 비해 너무 큰 배치 사이즈를 설정하는 것은 성능 저하의 원인이 될 수 있다.
-
데이터 수가 자주 변동되는 경우
- 데이터 수가 지속적으로 변동되는 경우에는 배치 사이즈를 상황에 맞게 동적으로 조정할 필요가 있다. 데이터가 많아질 경우 배치 사이즈를 크게 설정하고, 데이터가 적어질 경우 이를 줄이는 것이 바람직하다.
- 배치 사이즈의 설정을 자동화하거나 상황에 맞게 조정하는 기능을 개발 환경에 추가하면, 데이터의 양과 특성에 따라 성능 최적화를 지속적으로 유지할 수 있다.
결과 : 성능비교하기
N+1 발생 전, 후에 대한 성능 비교를 통해 얼마나 성능이 좋아졌는지 확인해보았다. 총 10000개의 냉장고를 생성하고 위에서 같은 방식으로 테스트 코드를 실행해보았다. 이번에는 BeforeEach, AfterEach에 실행 시간을 확인할 수 있는 코드를 넣었다.
n+1 문제가 발생하였을 때
가장 먼저 n+1문제가 발생한 시점에서의 테스트 결과이다.
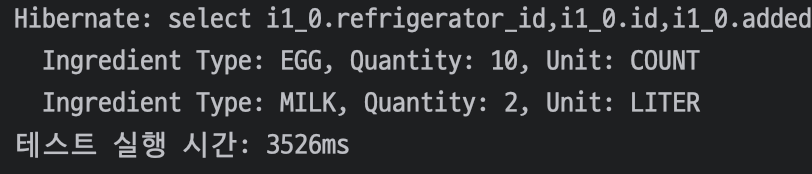
먼저 냉장고를 전체 조회하였을 때 소요되는 시간이다.
3526ms가 걸린 것을 확인할 수 있다.
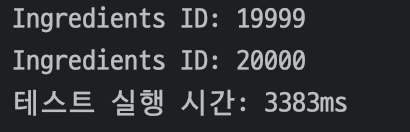
다음으로 재료를 전체 조회하였을 때 소요되는 시간이다.
3383ms가 걸린 것을 확인할 수 있다.
n+1 문제를 해결하고 난 후
다음으로 Fetch Join, Batch Size를 모두 적용하였을 때의 테스트 결과이다.
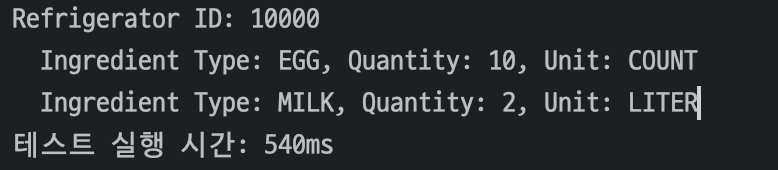
먼저 냉장고를 전체 조회하였을 때의 소요되는 시간이다.
540ms가 걸린 것을 확인할 수 있다.
다음으로 재료를 전체 조회하였을 때 소요되는 시간이다.
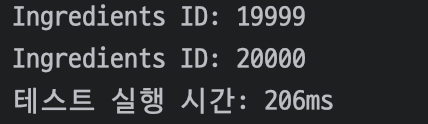
206ms가 걸린 것을 확인할 수 있다.
결과
위에서 나온 결과를 표로 정리하면 다음과 같다
| 종류 | 발생한 쿼리 개수 | 속도 |
|---|---|---|
| 냉장고 전체 조회 (n+1문제 해결 전) | 10001개 | 3526ms |
| 냉장고 전체 조회 (Batch Size 적용) | 1개 | 540ms |
| 재료 전체 조회 (n+1 문제 해결 전) | 10001개 | 3383ms |
| 재료 전체 조회 (Fetch Join 적용) | 1개 | 206ms |
@OneToMany 관계로 연관된 데이터가 조회되는 경우, 3526ms -> 540ms 로 약 85%의 성능 개선을 이루었다.
@ManyToOne 관계로 연관된 데이터가 조회되는 경우, 3383ms -> 206ms 로 약 94%의 성능 개선을 이루었다.
