
대규모 트래픽 테스트
대규모 트래픽 테스트란?
대규모 트래픽 테스트란 애플리케이션 또는 시스템이 예상되는 높은 트래픽을 처리할 수 있는 능력을 평가하기 위해 수행하는 성능 테스트의 일종이다. 이를 통해 시스템의 병목현상이나 성능 문제를 사전에 파악하고 해결할 수 있다.
대규모 트래픽 테스트는 단순히 시스템의 부하를 확인하는 것이 아니라, 트래픽 증가에 따른 애플리케이션의 안정성과 처리 속도를 평가하는 중요한 과정이다. 이를 통해 서비스가 다양한 사용자 환경에서 일관된 성능을 제공할 수 있는지를 확인할 수 있다.
일반적으로 사용되는 트래픽 테스트 도구로는 JMeter, Gatling, Locust 등이 있다. 각각의 테스트 도구는 아래와 같은 고유의 장단점을 가지고 있다.
- JMeter
- 장점: 다양한 프로토콜 지원, 쉬운 GUI 기반 설정, 강력한 확장성. 특히 HTTP, FTP, 데이터베이스 쿼리, LDAP 등의 다양한 테스트 시나리오를 지원한다.
- 단점: 고성능 테스트 시 높은 메모리 사용량이 단점으로 작용할 수 있다.
- Gatling
- 장점: 코드 기반 시나리오 작성이 가능하여 복잡한 테스트를 설계하기에 유리하다. 또한, 비동기식 처리로 인해 높은 성능을 제공한다.
- 단점: 스크립트 작성에 익숙하지 않은 사용자에게는 러닝 커브가 높을 수 있다.
- Locust
- 장점: Python 기반의 유연한 스크립트 작성이 가능하며, 분산 테스트에 강점이 있다.
- 단점: 초보자에게 다소 복잡하게 느껴질 수 있다.
나는 이번 프로젝트에서 JMeter를 선택하였다. 그 이유는 GUI를 통해 테스트 시나리오를 직관적으로 설계할 수 있었기 때문이다. 또한, JMeter는 플러그인 생태계가 잘 갖추어져 있어 다양한 확장이 가능하며, 보고서 생성 기능이 강력하여 테스트 결과를 시각적으로 분석하기에 적합하였다. 이러한 점에서 JMeter는 이번 프로젝트의 요구 사항에 가장 적합한 도구였다.
대규모 트래픽 테스트를 도입한 이유
대규모 트래픽 테스트를 도입한 이유는 명확하다. 서비스의 주요 API가 높은 트래픽 상황에서도 안정적으로 동작할 수 있는지 확인하고, 병목 구간을 파악하여 최적화 방안을 모색하기 위해서이다.
특히, 본 프로젝트에서는 사용자들이 냉장고 데이터를 조회하는 Read API의 사용량이 높을 것으로 예상되었다. 이 API는 반복적인 데이터베이스 조회 작업을 포함하고 있었기 때문에, 대규모 트래픽이 발생할 경우 데이터베이스에 과도한 부하가 걸릴 가능성이 있었다. 대규모 트래픽 테스트는 이러한 문제를 사전에 발견하고, 해결 방안을 수립하는 데 필수적인 과정이었다.
더불어, 테스트를 통해 응답 시간과 처리량(Throughput)을 측정하여 시스템이 특정 트래픽 수준에서 얼마나 안정적으로 동작하는지 평가할 수 있었다. 이는 서비스 품질을 높이고 사용자 경험을 개선하는 데 중요한 역할을 하였다.
프로젝트 상황 및 변화
Create < Read
프로젝트를 완성한 후 리팩토링과 버그 수정 과정을 거치면서, Create API보다 Read API의 사용량이 많아 데이터베이스 조회에 많은 자원을 소비하게 될 것임을 예상하였다. 실제 데모 테스트에서도 홈 화면에서 냉장고 재료를 조회하는 API가 새로고침할 때마다 조회되어 사용량이 매우 많았다.
냉장고 데이터를 생성하는 Create API는 상대적으로 적은 데이터베이스 작업을 필요로 하였으나, 데이터를 조회하는 Read API는 사용자 요청마다 데이터베이스에서 정보를 검색해야 했다. 이로 인해 Read API의 응답 시간이 길어지고, 트래픽이 몰리는 상황에서는 데이터베이스 부하가 급격히 증가할 가능성이 있었다.
예를 들어, 냉장고 데이터의 조회 요청은 다양한 사용자에 의해 반복적으로 발생할 수 있으므로, 데이터베이스에 대한 부하가 누적될 가능성이 컸다. 이를 통해 Create API와 Read API 간의 성능 차이가 시스템의 병목 구간으로 작용할 수 있음을 확인하였다. 따라서 이를 해결하기 위한 최적화 작업이 반드시 필요하다고 판단하였다.
대규모 트래픽 테스트 환경
| Threads | Ramp-up Period | Loop Count |
|---|---|---|
| 300 | 2 | 100 |
앞으로 설명하는 모든 트래픽 테스트 환경으로는 위와 같이 스레드 수는 300, 시간은 2초, 반복은 100번으로 하여 진행하였다. 대규모 트래픽 테스트에서 Threads(300)는 동시에 접속하는 가상의 사용자 수를, Ramp-up Period(2초)는 이 사용자들이 2초 동안 점진적으로 생성되는 시간을, Loop Count(100)는 각 사용자가 100번씩 요청을 반복하는 횟수를 의미한다. 이 설정은 총 300명의 사용자가 2초에 걸쳐 생성되어 각각 100번의 요청을 보내며, 결과적으로 서버에 총 30,000번의 요청을 보내는 상황을 시뮬레이션한다.
대규모 트래픽 테스트 결과 (Redis 적용 전)
트래픽 테스트는 위와 같이 테스트, 정보 조회 3번으로 하도록 설계하였다. 하나의 스레드에 회원가입과 회원 정보 조회를 모두 넣은 이유는 JWT 때문이었다. 우리 프로젝트는 회원가입이 발급한 Access Token을 이용하여 API에 접근하여 사용자 인증을 하는데, 스레드를 따로 해버리면 토큰 발급을 해주는 API만을 따로 만들어야 했다. 이러한 방법이 번거롭다고 생각하여, 차라리 하나의 스레드에 넣어서 회원가입 API 응답 헤더에서 Access Token을 가져와 변수로 지정하여 회원 정보 조회 API 요청을 할 때 헤더에 넣어 요청하면 되겠다고 판단하였다.
(단위는 ms)
| Label | Average | 90% Line |
|---|---|---|
| 회원가입 테스트 | 976 | 1760 |
| 회원 정보 조회 1 | 1874 | 3055 |
| 회원 정보 조회 2 | 1798 | 2985 |
결과는 위와 같았다. 여러번 시도를 한 결과의 평균 값을 계산하였다. 회원가입에 비해 회원 정보 조회에 대한 응답 시간이 긴 것을 확인할 수 있었고 이에 따라 Redis 캐싱 도입을 고려한 것이다.
왜 회원 정보 조회를 3번이나??
처음에는 회원 정보 조회를 2번 실시하였다. 그 이유는 회원 정보를 처음하였을 때는 캐시가 없는 상태이므로 Cache Miss가 날 것이고 두 번째에는 Cache Hit가 발생하여 제대로 된 캐싱 응답 시간을 측정할 수 있기 때문이다. 그러나 Redis 캐싱을 도임한 이후에 한 번더 조회를 하면 이전과 비슷할 까 하는 호기심이 생겼고 회원 정보 조회를 3번 실시하였는데 평균적으로 응답시간이 더 빨라진 것을 확인할 수 있었다. 그래서 Cache Warmed up 이라는 개념을 학습하게 되었고 이에 대한 내용은 뒤에서 추가로 설명할 예정이다.
Redis 캐싱 도입 고려
응답 시간을 줄이기 위한 방법에는 여러 가지가 있다. 예를 들어, 쿼리 최적화, 인덱스 추가, 데이터베이스 샤딩 등이 있다. 그러나 이러한 방법들은 데이터베이스 자체의 구조를 변경하거나 추가적인 관리 부담을 초래할 수 있다.
반면, Redis를 통한 캐싱은 반복적인 조회 요청을 데이터베이스가 아닌 메모리에서 처리함으로써 데이터베이스 부하를 줄이고 응답 시간을 획기적으로 단축할 수 있다. Redis는 키-값 저장소로서 높은 성능과 안정성을 제공하며, 만료 시간을 설정하여 최신 데이터를 유지할 수 있는 장점도 있다.
Redis 캐싱 도입의 주요 이점은 다음과 같다.
- 고성능 : 메모리 기반 처리로 응답 속도가 매우 빠르다. 이는 대규모 트래픽 상황에서 특히 중요한 장점이다.
- 쉬운 통합 : Spring Boot와 같은 프레임워크에서 쉽게 통합 가능하다. 이를 통해 캐싱 기능을 빠르게 구현할 수 있다.
- 유연성 : 데이터 만료 시간을 설정하여 적절한 캐싱 정책을 구현할 수 있다. 이는 데이터 일관성을 유지하면서도 높은 성능을 제공할 수 있는 중요한 요소이다.
내 프로젝트에서는 위와 같은 이유로 Redis를 선택하였다. 특히, 캐싱 정책을 효과적으로 설계하여 자주 조회되는 데이터의 응답 속도를 대폭 개선할 수 있었다.
변화의 결과
Redis 캐싱 도입 전의 결과
위의 테스트에서 추가로 회원 정보 조회를 1번 더 추가한 결과이다.
(단위는 ms)
| Label | Average | 90% Line |
|---|---|---|
| 회원가입 테스트 | 976 | 1760 |
| 회원 정보 조회 1 | 1874 | 3055 |
| 회원 정보 조회 2 | 1798 | 2985 |
| 회원 정보 조회 3 | 1795 | 2894 |
회원 정보를 추가로 하여도 캐시를 하지 않았기 때문에 응답시간이 비슷한 것을 알 수 있다.
이를 그래프로 보면 아래와 같다.
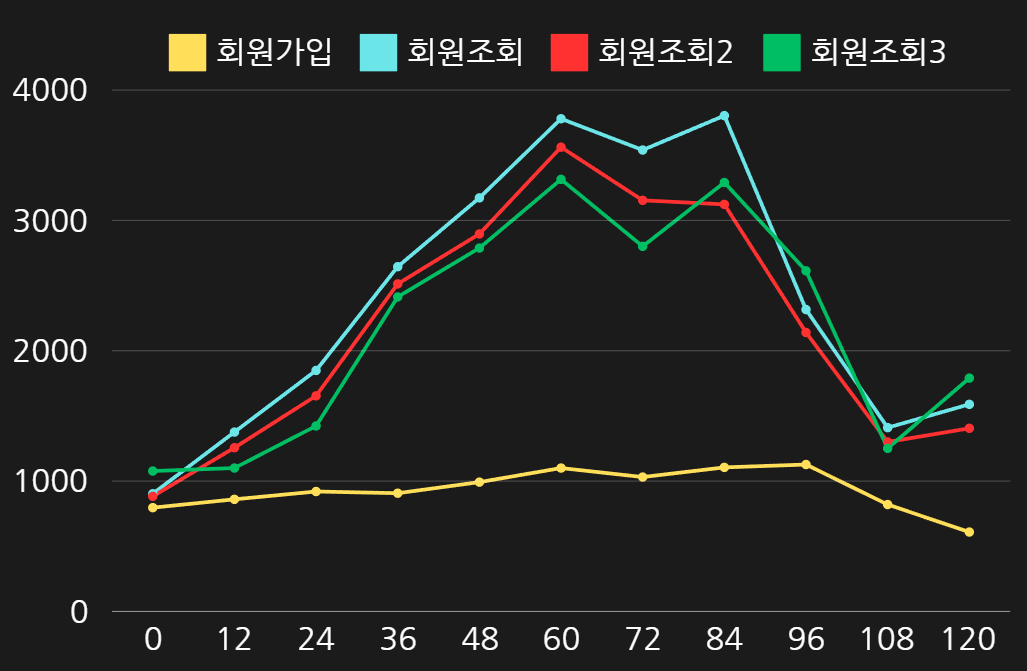
그래프로 보면 더 명확하게 회원 가입 테스트에 비해 회원 정보 조회에 대한 응답 시간이 긴 것을 확인할 수 있다.
Redis 캐싱 도입하기
1. Redis 캐시 설정
Redis 캐시는 Spring에서 CacheManager를 통해 관리되도록 하였다. RedisCacheManager를 사용하여 Redis와 통합하고, 캐시 키와 값을 직렬화하는 방식을 정의하였다.
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisCacheConfiguration cacheConfig = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer()))
.entryTtl(Duration.ofMinutes(5)); // 기본 캐시 TTL: 5분
RedisCacheConfiguration memberCacheConfig = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofHours(1)); // 회원 정보 캐시 TTL: 1시간
Map<String, RedisCacheConfiguration> cacheConfigurations = new HashMap<>();
cacheConfigurations.put("memberInfoCache", memberCacheConfig);
return RedisCacheManager.builder(factory)
.cacheDefaults(cacheConfig)
.withInitialCacheConfigurations(cacheConfigurations)
.build();
}- 직렬화 설정
- 키는
StringRedisSerializer를 사용하여 문자열로 저장. - 값은
GenericJackson2JsonRedisSerializer를 사용하여 JSON 형식으로 저장.
- 키는
- TTL 설정
- 기본 캐시 유효기간은 5분으로 설정.
- 특정 캐시(예:
memberInfoCache)는 1시간 동안 유지되도록 설정.
- RedisCacheManager
- Redis 연결을 기반으로 캐시 관리를 담당하며, 캐시 설정을 초기화한다.
2. 서비스 레이어에서 Redis 캐시 활용
실제 서비스에서 Redis 캐시를 사용할 때에는 Spring의 캐시 어노테이션을 사용하였다. 이때 @Cacheable, @CacheEvict 를 잘 활용하여 캐시를 생성하고 지우는 작업을 잘 선택해야 한다.
회원 정보 조회
회원 정보 조회 시, 먼저 Redis 캐시를 확인하고, 데이터가 없을 경우 데이터베이스에서 조회한 후 캐시에 저장한다.
@Override
@Transactional(readOnly = true)
@Cacheable(value = "memberInfoCache", key = "#root.args[0] != null ? #root.args[0] : 'defaultKey'")
public MyInfoResponse getMyInfo(String email) {
Member member = memberRepository.findByEmail(email)
.orElseThrow(() -> new MemberException(MemberExceptionType.MEMBER_NOT_FOUND));
return MyInfoResponse.of(member);
}@Cacheable: 캐시에 데이터가 없을 경우, 데이터베이스에서 조회한 결과를 캐시에 저장.value: 캐시 이름을 지정.key: 이메일을 캐시 키로 사용. 이메일 값이 없을 경우defaultKey를 사용.
회원 정보 업데이트
회원 정보를 수정하거나 삭제한 경우, 캐시에 저장된 데이터를 제거하여 데이터 불일치 문제를 방지한다.
@Override
@Transactional
@CacheEvict(value = "memberInfoCache", key = "#root.args[1] != null ? #root.args[1] : 'defaultKey'")
public MemberUpdateResponse update(MemberUpdateRequest request, String email) {
Member member = memberRepository.findByEmail(email)
.orElseThrow(() -> new MemberException(MemberExceptionType.MEMBER_NOT_FOUND));
if (memberRepository.findByNickname(request.newNickname()).isPresent()) {
throw new MemberException(MemberExceptionType.ALREADY_EXIST_NICKNAME);
}
member.updateNickname(request.newNickname());
return MemberUpdateResponse.of(member);
}@CacheEvict: 회원 정보 수정 후 해당 키에 저장된 캐시를 삭제하여 데이터가 갱신되도록 보장.value: 캐시 이름을 지정.key: 이메일을 캐시 키로 사용.
회원 탈퇴
회원 탈퇴 시, 데이터베이스에서 해당 회원 정보를 삭제한 후 Redis 캐시에 저장된 데이터를 제거하여 데이터 일관성을 유지하였다. 이는 탈퇴 이후에도 캐시에 남아 있는 데이터로 인해 발생할 수 있는 데이터 불일치 문제를 방지하기 위함이다.
@Override
@Transactional
@CacheEvict(value = "memberInfoCache", key = "#root.args[1] != null ? #root.args[1] : 'defaultKey'")
public MemberWithdrawResponse withdraw(MemberWithdrawRequest request, String email) {
Member member = memberRepository.findByEmail(email)
.orElseThrow(() -> new MemberException(MemberExceptionType.MEMBER_NOT_FOUND));
if (!member.getNickname().equals(request.nickname())) {
throw new MemberException(MemberExceptionType.NOT_MATCH_NICKNAME);
}
memberRepository.delete(member);
return MemberWithdrawResponse.of(email);
}@CacheEvict사용 : 회원 탈퇴 후 캐시에 저장된 데이터를 제거하여 불필요한 데이터가 유지되지 않도록 처리하였다.- 데이터 일관성 유지 : 데이터베이스에서 회원 정보를 삭제한 후 캐시 데이터를 정리하여, 삭제된 회원 정보가 캐시를 통해 다시 조회되는 문제를 방지하였다.
- 캐시 키 관리 : 이메일을 캐시 키로 사용하였으며, 키가 없을 경우 기본값으로
defaultKey를 사용하여 예외 상황을 처리하였다.
이를 통해 민감한 회원 정보 삭제 과정에서도 캐시와 데이터베이스 간의 데이터 정합성을 유지하고, 안정적인 시스템 동작을 보장할 수 있었다.
Redis 캐싱 도입 후의 결과
(단위는 ms)
| Label | Average | 90% Line |
|---|---|---|
| 회원가입 테스트 | 956 | 1606 |
| 회원 정보 조회 1 | 1556 | 2230 |
| 회원 정보 조회 2 | 684 | 1935 |
| 회원 정보 조회 3 | 610 | 1920 |
캐싱을 도입하고 나서 같은 트래픽 테스트의 환경에서 테스트 코드를 실행해보았더니 위와 같은 결과를 얻었다. Cache Hit가 발생한 2번째 회원 정보 조회부터 응답시간이 확연하게 짧아진 것을 확인할 수 있었다. 이를 그래프로 확인하면 아래와 같다.
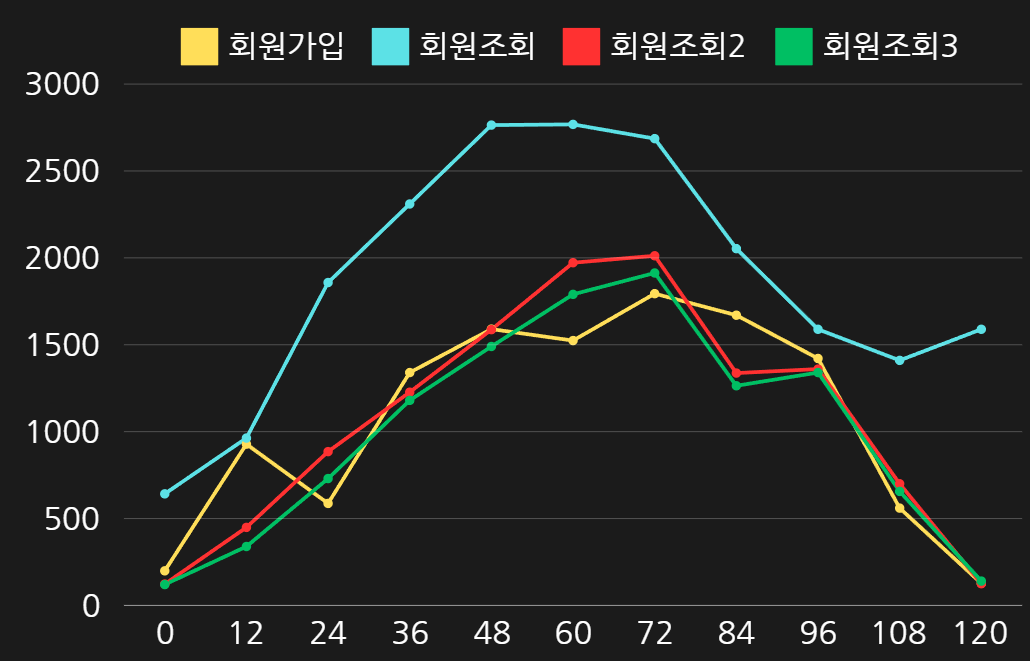
이번에는 회원가입과 회원정보 조회의 응답시간이 비슷하거나 오히려 조회에 대한 응답시간이 더 빨라진 것을 확인하였다. 그리고 회원 정보 조회를 3번째 하였을 때 계속해서 2번째 했을 때와 응답시간이 평균적으로 더 빠른 것을 확인하였는데, 이는 Cahce Warmed-Up 이라는 개념때문이라는 것을 학습할 수 있었다.
Cache Miss, Cache Hit, Cache Warmed Up ??
다시 한 번 이야기 하자면, 회원 정보 조회를 3번 실행한 결과, 1번, 2번, 3번 요청할수록 응답 시간이 점점 빨라지는 현상이 확인되었다. 이는 요청 처리 과정에서 발생하는 캐시 미스(Cache Miss), 캐시 히트(Cache Hit), 그리고 캐시가 충분히 채워진 상태(Cache Warmed Up)로 이어지는 캐시 동작 원리와 관련이 있다.
1. 첫 번째 요청: Cache Miss
첫 번째 요청에서는 캐시에 데이터가 존재하지 않았기 때문에, 원본 데이터 소스인 데이터베이스(DB)에서 직접 데이터를 조회한 후 이를 캐시에 저장하였다. 이 과정에서 데이터베이스 접근 시간이 소요되었으므로 응답 시간이 상대적으로 느렸다. 이 요청은 캐시 초기화 단계에 해당한다.
2. 두 번째 요청: Cache Hit
두 번째 요청부터는 데이터가 캐시에 저장되어 있었기 때문에, 데이터베이스를 거치지 않고 캐시에서 데이터를 바로 반환하였다. 이로 인해 응답 시간이 첫 번째 요청보다 현저히 빨라졌다. 이는 캐시가 성공적으로 동작하기 시작했음을 의미한다.
3. 세 번째 요청: Cache Warmed Up
세 번째 요청에서는 캐시에 필요한 데이터가 이미 모두 채워져 있었으므로, 데이터베이스 접근 없이 캐시만으로 요청을 처리할 수 있었다. 이 시점에서 캐시는 안정적으로 작동하며, 최적화된 응답 속도를 제공하였다. 이는 캐시가 완전히 준비된 상태, 즉 웜업된 상태에 도달했음을 나타낸다.
요청별 응답 시간 변화
- 첫 번째 요청(캐시 미스): 데이터베이스에서 데이터를 조회하였으므로 응답 시간이 느렸다.
- 두 번째 요청(캐시 히트): 캐시에서 데이터를 반환하였으므로 응답 시간이 빨라졌다.
- 세 번째 요청(캐시 웜업 완료): 캐시가 최적화된 상태에서 작동하였으므로 가장 빠른 응답 속도를 기록하였다.
결론
회원 정보 조회를 3번 실행하며, 요청할수록 응답 시간이 빨라진 이유는 첫 번째 요청에서 캐시 미스가 발생하였으나, 이후 요청에서 캐시 히트로 전환되었기 때문이다. 특히 세 번째 요청 시점에서는 캐시가 완전히 준비된 웜업 상태에 도달하여 최적의 응답 속도를 제공한 것이다.
Redis 캐싱을 도입하기 전과 후의 비교
(단위는 ms)
| Redis 적용 전 | Redis 적용 후 | |
|---|---|---|
| 회원 정보 조회 1 (Cache Miss) | 1874 | 1556 |
| 회원 정보 조회 2 (Cache Hit) | 1798 | 684 |
| 회원 정보 조회 3 (Warmed-Up) | 1795 | 610 |
Cache 적용 후 약 63.99% 성능을 개선하였다.
다음 이야기
Master Slave 데이터베이스 이중화
Redis 캐싱은 데이터베이스 부하를 줄이고 응답 속도를 개선하는 데 효과적이었지만, 더 많은 트래픽이 발생할 경우 근본적인 해결책은 될 수 없었다. 이를 해결하기 위해, 다음 단계로 마스터-슬레이브 데이터베이스 이중화를 도입하였다. 이는 데이터베이스의 읽기와 쓰기 작업을 분리하여 부하를 분산하는 방식이다.
다음 포스팅에서는 마스터-슬레이브 구조를 설계하고 도입한 과정을 자세히 다룰 예정이다.

대규모 트래픽 테스트를 어떻게 진행해야할지 막막했는데, 이렇게 잘 정리해주신 덕분에 좋은 방법 알고 갑니다 감사합니다! :)