
데이터베이스 이중화를 선택한 이유
데이터베이스 이중화(Database Redundancy)란 단순히 데이터를 여러 서버에 분산 저장하는 것을 넘어, 시스템의 안정성과 가용성을 극대화하기 위하여 도입하는 기술이다. 비록 누군가는 이중화가 오버엔지니어링으로 평가될 수 있으나, 본 프로젝트에서는 다음과 같은 이유로 이중화 기술을 도입하였다.
-
실무 경험 쌓기
실무에서 대다수 기업이 채택하는 데이터베이스 이중화 아키텍처를 직접 경험함으로써, 실제 운영 환경에서의 문제 해결 능력과 시스템 설계 역량을 강화하고자 하였다. -
서비스 안정성 및 가용성 향상
단일 데이터베이스 서버에 장애가 발생할 경우 전체 시스템에 치명적인 영향을 미칠 우려가 있으므로, 이중화를 통해 읽기와 쓰기 작업을 분리하고 백업 및 복구 시간을 단축하여 시스템의 안정성과 서비스 가용성을 높이고자 하였다. -
확장성 및 성능 최적화
읽기 작업은 Slave 데이터베이스에서, 쓰기 작업은 Master 데이터베이스에서 처리함으로써 서버 부하를 분산시켜 전체 시스템의 성능을 최적화할 수 있다. 또한, 향후 트래픽이 증가할 경우 추가적인 Slave 노드 도입을 통해 수평 확장이 용이하도록 하였다.
MariaDB 데이터베이스 이중화하기 (Master - Slave)
MariaDB는 다양한 이중화 구성 방식을 선택할 수 있다. 본 프로젝트에서는 Master-Slave 구조를 채택하였다. Master-Master, Galera Cluster, Shared-Nothing 등등 여러 구조가 있었지만 Master-Slave 구조는 가장 보편적이면서 운영이 단순하다는 장점을 가지고 있었다. 또한, 우리 프로젝트에는 쓰기 트래픽 보다 읽기 트래픽이 많았기 때문에 읽기 부하 분산을 하기 위해 Master-Slave 구조를 선택하게 되었다.
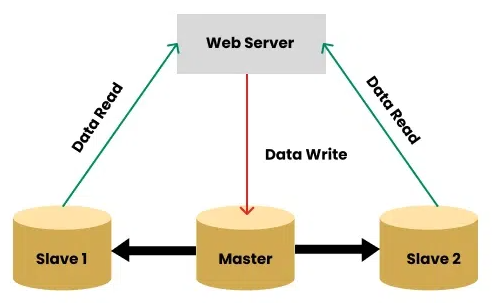
Master와 Slave의 개념
-
Master 데이터베이스
Master 서버는 주 데이터베이스로서 쓰기 작업(INSERT, UPDATE, DELETE 등)을 전담한다. 모든 변경 사항은 Master에서 처리한 후, Slave로 복제되어 데이터 일관성을 유지한다. -
Slave 데이터베이스
Slave 서버는 Master에서 발생한 변경 사항을 실시간 혹은 주기적으로 복제 받아 주로 읽기 작업(SELECT)을 수행한다. 이로써 읽기 부하를 분산시키고, Master 장애 발생 시 보조적으로 활용할 수 있는 기반을 마련하였다.
많은 기업이 데이터베이스 이중화를 선택하는 이유
- 장애 복구 및 무중단 서비스 제공
Master 서버에 장애가 발생하더라도 Slave 서버를 활용하여 데이터 손실 없이 서비스를 지속할 수 있다. - 부하 분산을 통한 성능 개선
읽기 전용 작업이 많은 경우 Slave 서버에서 해당 작업을 처리함으로써 Master의 부하를 경감하고 전체 시스템 응답 속도를 개선할 수 있다. - 데이터 백업 및 유지 관리 용이성
Slave 서버를 통해 실시간 데이터를 복제함으로써 보다 안전하게 데이터 백업 및 유지 관리 작업을 수행할 수 있다.
기존 프로젝트에 Master-Slave 도입
기존 프로젝트는 단일 데이터베이스 서버가 읽기와 쓰기 작업을 모두 담당하는 구조였다. 이러한 단일 구조는 다음과 같은 한계를 가지고 있다고 생각하였다.
- 단일 장애점(Single Point of Failure)
하나의 서버 장애 시 전체 서비스 중단의 위험이 존재하였다. - 성능 병목 현상
읽기와 쓰기 작업이 한 서버에 집중됨에 따라 서버 부하가 급격히 증가하여 성능 병목 현상이 발생하였다.
이전 포스팅에서 확인한 것처럼 읽기에 대한 API 요청이 쓰기 요청보다 더 많이 발생한다는 것을 대용량 트래픽 테스트를 시행하면서 알게 되었다. 따라서 나는 우리 프로젝트의 백엔드 개발자로서 읽기, 쓰기 요청을 분리할 필요가 있다고 생각을 하였고, 데이터베이스를 이중화하면서 Master-Slave를 본격적으로 도입하기 시작하였다.
Master-Slave 도입 전략
나는 데이터베이스의 Master-Slave 구조 도입을 통해 다음과 같은 전략을 가졌다.
-
읽기와 쓰기의 분리
- Master 서버: 데이터 입력, 수정, 삭제 등 쓰기 작업을 전담하도록 하였다.
- Slave 서버: 데이터 조회 등 읽기 작업을 전담하도록 구성하였다.
이와 같이 각 서버에 가해지는 부하를 효과적으로 분산하였다.
-
쿠버네티스를 활용한 배포
쿠버네티스(Kubernetes)를 활용하여 데이터베이스 서버를 파드(Pod)로 구성하였으며, 다음과 같은 방식으로 관리하였다.- Master와 Slave 각각의 파드를 별도로 관리하여 독립적인 스케일링 및 모니터링이 가능하도록 하였다.
- 데이터베이스 장애 발생 시 자동으로 새로운 파드를 생성하여 시스템 안정성을 확보하였다.
- 서비스 디스커버리(Service Discovery)를 통해 Master와 Slave 간의 통신 경로를 명확히 하고, 로드밸런서를 이용하여 클라이언트 요청을 적절히 분배하였다.
1. YAML 설정 분리
아래 Yaml 코드는 spring.datasource 아래에 master와 slave 섹션을 분리하여 각각 DB 정보를 정의한 코드이다. application.yml에 아래와 같이 작성하였다.
spring:
datasource:
master:
url: ${vault.master_mariadb_url}
driver-class-name: org.mariadb.jdbc.Driver
username: ${vault.master_mariadb_username}
password: ${vault.master_mariadb_password}
slave:
url: ${vault.slave_mariadb_url}
driver-class-name: org.mariadb.jdbc.Driver
username: ${vault.slave_mariadb_username}
password: ${vault.slave_mariadb_password}master와slave각각 별도의 마리아DB 접속 정보를 설정한다.- 실제 URL, 사용자명, 비밀번호 등의 민감 정보는 Vault, Config Server 또는 환경 변수 등을 통해 주입하였다.
2. DB 연결 설정: MariaDbProperties
위 Yaml 파일의 정보를 객체로 받아오는 클래스이다. Spring Boot의 @ConfigurationProperties를 활용하여 프로퍼티 바인딩을 수행하였다.
@Setter
@Getter
@Configuration
@ConfigurationProperties(prefix = "spring.datasource")
public class MariaDbProperties {
private DataSourceProperties master;
private DataSourceProperties slave;
@Setter
@Getter
public static class DataSourceProperties {
private String url;
private String driverClassName;
private String username;
private String password;
}
}spring.datasource.master에 해당하는 부분을master객체가,spring.datasource.slave는slave객체가 각각 매핑된다.
3. 마스터·슬레이브 DataSource Bean 등록: DataSourceConfig
3.1 기본 구조
@Configuration
@Slf4j
@EnableTransactionManagement
@RequiredArgsConstructor
@EnableJpaRepositories(
basePackages = "cloud.zipbob.edgeservice.domain.member.repository",
entityManagerFactoryRef = "masterEntityManagerFactory",
transactionManagerRef = "masterTransactionManager"
)
public class DataSourceConfig {
private final MariaDbProperties mariaDbProperties;
@Bean(name = "masterDataSource")
public DataSource masterDataSource() {
log.info("Initializing Master DataSource");
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(mariaDbProperties.getMaster().getUrl());
dataSource.setDriverClassName(mariaDbProperties.getMaster().getDriverClassName());
dataSource.setUsername(mariaDbProperties.getMaster().getUsername());
dataSource.setPassword(mariaDbProperties.getMaster().getPassword());
return dataSource;
}
@Bean(name = "slaveDataSource")
public DataSource slaveDataSource() {
log.info("Initializing Slave DataSource");
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(mariaDbProperties.getSlave().getUrl());
dataSource.setDriverClassName(mariaDbProperties.getSlave().getDriverClassName());
dataSource.setUsername(mariaDbProperties.getSlave().getUsername());
dataSource.setPassword(mariaDbProperties.getSlave().getPassword());
return dataSource;
}
...
}@Bean(name = "masterDataSource"): 마스터 DB 연결용 DataSource(HikariCP 활용)@Bean(name = "slaveDataSource"): 슬레이브 DB 연결용 DataSource(HikariCP 활용)
HikariDataSource 외에 다른 커넥션 풀을 사용할 수도 있으나, HikariCP가 경량화와 높은 성능 때문에 가장 널리 활용되는 추세이므로 나 또한 HikariCP를 활용하였다.
3.2 RoutingDataSource 등록
@Bean
@Primary
public DataSource dataSource() {
log.info("Initializing Routing DataSource");
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("master", masterDataSource());
targetDataSources.put("slave", slaveDataSource());
routingDataSource.setTargetDataSources(targetDataSources);
routingDataSource.setDefaultTargetDataSource(masterDataSource());
return routingDataSource;
}RoutingDataSource(뒤에서 소개)의targetDataSources맵에 “master”, “slave”로 구분하여 등록한다.- 디폴트(Default) 데이터소스를 마스터로 설정하였다.
@Primary를 명시함으로써 다른 Bean 주입 시 기본값으로 사용되도록 지정하였다.
3.3 엔티티 매니저 & 트랜잭션 매니저 설정
@Bean(name = "masterEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean masterEntityManagerFactory() {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setDataSource(dataSource());
factory.setPackagesToScan("cloud.zipbob.edgeservice.domain.member");
factory.setJpaVendorAdapter(new HibernateJpaVendorAdapter());
factory.setJpaPropertyMap(hibernateProperties());
return factory;
}
@Bean(name = "masterTransactionManager")
public PlatformTransactionManager masterTransactionManager(
LocalContainerEntityManagerFactoryBean masterEntityManagerFactory) {
return new JpaTransactionManager(
Objects.requireNonNull(masterEntityManagerFactory.getObject()));
}
private Map<String, Object> hibernateProperties() {
Map<String, Object> properties = new HashMap<>();
properties.put("hibernate.hbm2ddl.auto", "update");
properties.put("hibernate.show_sql", true);
properties.put("hibernate.format_sql", true);
properties.put("hibernate.use_sql_comments", true);
properties.put("hibernate.dialect", "org.hibernate.dialect.MariaDBDialect");
return properties;
}- 엔티티 매니저와 트랜잭션 매니저 모두 마스터 기준으로 설정하였다.
RoutingDataSource가 주입되므로, AOP를 통한 읽기/쓰기가 동적으로 분기된다.
4. 동적 라우팅 핵심 로직: RoutingDataSource
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.getDataSourceType();
}
}AbstractRoutingDataSource를 상속받아,determineCurrentLookupKey()에서 현재 쓰레드가 어떤 DB(“master” or “slave”)를 사용해야 하는지 반환한다.- 실제 “master” 혹은 “slave” 값은
DataSourceContextHolder를 통해 가져온다.
5. AOP를 통한 라우팅 제어: DataSourceAspect
5.1 AOP Aspect 설정
@Aspect
@Component
@Slf4j
public class DataSourceAspect {
@Before("execution(* cloud.zipbob.edgeservice.domain.member.service.*.get*(..)) "
+ "|| execution(* cloud.zipbob.edgeservice.domain.member.service.*.check*(..))")
public void setReadDataSource() {
log.info("Switching to Slave DataSource");
DataSourceContextHolder.setDataSourceType("slave");
}
@Before("execution(* cloud.zipbob.edgeservice.domain.member.service.*.save*(..)) "
+ "|| execution(* cloud.zipbob.edgeservice.domain.member.service.*.update*(..)) "
+ "|| execution(* cloud.zipbob.edgeservice.domain.member.service.*.delete*(..))")
public void setWriteDataSource() {
log.info("Switching to Master DataSource");
DataSourceContextHolder.setDataSourceType("master");
}
}@Before어노테이션을 이용하여, 해당 메서드의 실행 직전에 마스터 또는 슬레이브로 라우팅을 변경한다.- 예시에서는 메서드 이름에 따라 “get”·“check”로 시작하면 슬레이브, “save”·“update”·“delete”로 시작하면 마스터로 설정하도록 하였다.
5.2 DataSourceContextHolder
public class DataSourceContextHolder {
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
public static void setDataSourceType(String dataSourceType) {
contextHolder.set(dataSourceType);
}
public static String getDataSourceType() {
return contextHolder.get();
}
public static void clearDataSourceType() {
contextHolder.remove();
}
}- 쓰레드 로컬(ThreadLocal)을 활용하여 현재 쓰레드가 어떤 DB 타입(“master” 또는 “slave”)을 사용할지 기억하게 한다.
- AOP를 통해 메서드가 호출될 때
contextHolder에 값을 세팅하면,RoutingDataSource에서 이를 참조하여 DB 연결을 결정한다.
이중화 구현 시 고려사항 및 최적화 전략
데이터베이스 이중화를 구현하는 과정에서 다음과 같은 사항과 최적화 전략을 반드시 고려하였으며, 특히 이중화 구조의 특성에 따라 최종 일관성(Eventual Consistency) 전략을 적용하여 읽기-쓰기 분리를 효율적으로 구현하였다.
동기화 문제
- 데이터 일관성 관리
- Slave 서버에서 발생할 수 있는 읽기 지연으로 인해 최신 데이터가 반영되지 않을 수 있는 문제를 최소화하기 위해, 최종 일관성(Eventual Consistency) 전략과 트랜잭션 관리 기법을 도입하였다.
- 쓰기(Insert/Update/Delete) 연산은 Master에서 처리하되, 일반적인 조회(Read)는 Slave를 사용하여 부하를 분산하였으며, ‘중요 시점’에 최신 데이터를 반드시 보장해야 할 경우에는 AOP(Pointcut) 기반으로 Master에 직접 접근하도록 설정하였다(예: 쓰기 직후 곧바로 조회해야 하는 경우 등).
- 이를 통해 복제(Replication) 지연이 있더라도 시스템 전반의 성능을 높이면서, 필요 시에는 Master 조회를 통해 정확한 정합성을 확보할 수 있었다.
부하 분산 및 성능 최적화
- 쿼리 최적화
- Slave 서버에서 집중 처리되는 읽기 작업을 위해 복잡한 쿼리에 대한 인덱스 최적화와 쿼리 튜닝을 진행하였다.
- 오랜 시간 소요되는 조회 작업을 사전에 최적화함으로써, Slave 부하를 완화하고 전체 시스템의 성능 저하를 방지하였다.
- 자동 스케일링
- 쿠버네티스의 자동 스케일링 기능(HPA 등)을 적극 활용하여, 트래픽 증가 시 Slave 서버 파드를 동적으로 확장함으로써 안정적인 성능을 유지하였다.
- 이를 통해 특정 시간대나 이벤트성 트래픽이 몰릴 때도, Master-Slave 구조가 원활히 동작할 수 있도록 스케일 아웃(Scale-out)을 자동화하였다.
보안 및 접근 제어
- 네트워크 보안
- Master와 Slave 간 데이터 복제에 SSL/TLS 등 보안 프로토콜을 적용함으로써, 네트워크 구간에서의 데이터 전송을 안전하게 보호하였다.
- 내부 통신망이라도 TLS 암호화를 통해 침입 및 도청 위험을 줄였다.
- 접근 권한 관리
- 각 데이터베이스(특히 Master DB)에 대한 접근 권한을 최소화(Minimum Privilege)하여, 불필요한 권한 상승과 침입 시도를 사전에 차단하였다.
- 개발 및 운영환경에서의 접근 정책을 구분하여, 중요 데이터 변조 위험을 낮추었다.
실제 운영 시 장애 대응 및 모니터링 전략
안정적인 서비스 운영을 위하여 장애 대응 계획과 지속적인 모니터링 체계를 마련하였다. 특히 최종 일관성 기반 구조 특성상 복제 지연을 주기적으로 모니터링하고, 장애 발생 시 Master-Slave 전환에 즉각 대응할 수 있도록 하였다.
장애 대응 계획
- 자동 장애 감지 및 복구
- 쿠버네티스의 헬스체크(Health Check) 기능을 활용하여, Master 또는 Slave 서버에 장애가 발생할 경우 자동으로 새로운 인스턴스를 배포하도록 설정하였다.
- Slave 장애 시에는 빠른 복구가 가능하도록 여러 슬레이브 인스턴스를 운영하였고, 마스터 장애 시 슬레이브 승격(Promote) 절차를 대비해 Binlog 및 GTID 등을 면밀히 관리하였다.
- 데이터 복구 전략
- 정기적인 백업(예: 스냅샷, Point-in-time Recovery) 및 복구 테스트를 수행하여, 실제 장애 상황에서도 데이터 손실 없이 신속하게 복구가 가능하도록 준비하였다.
- 장애 시점을 기준으로 마스터-슬레이브 간 동기화 상태를 분석하고, 필요한 경우 수동 복원 절차도 마련하였다.
모니터링 및 로그 분석
- 실시간 모니터링 시스템 구축
- Prometheus, Grafana 등을 활용하여 데이터베이스 성능 지표, 네트워크 상태, 복제 지연(Seconds_Behind_Master) 등을 실시간 모니터링하였다.
- 최종 일관성 전략상, 슬레이브 지연이 임계값을 넘어설 경우 경보(Alarm)를 보내도록 구성하여 운영 리스크를 최소화하였다.
- 로그 분석 및 경보 시스템
- ELK 스택(Elasticsearch, Logstash, Kibana) 또는 Splunk와 같은 로그 관리 도구를 사용하여 서버 로그를 한 곳에 모아 분석하고, 이상 징후 발생 시 자동으로 경보를 발송하도록 구성하였다.
- AOP에 의해 마스터와 슬레이브로 분기되는 시점을 로그로 남기고, 오작동 발생 시 원인을 빠르게 파악할 수 있도록 로그 정책을 세분화하였다.
- 성능 지표 측정 및 보고
- 주기적으로 시스템 성능 리포트를 작성하여, 데이터베이스 이중화 운영의 효과(부하 분산, 복제 지연 추이 등)를 분석하고, 향후 개선 사항을 도출하였다.
- 마이크로서비스 간 API 호출이 많을 경우 추가 Latency가 생기지 않도록, 서킷 브레이커나 분산 추적(Distributed Tracing) 도구를 병행하여 모니터링하였다.
결론
프로젝트를 통하여 단순 이론적 이해에 머무르지 않고, 실제 운영 환경에서 MariaDB 데이터베이스 이중화를 구현하고 최적화하는 과정을 경험하였다.
Master-Slave 구조를 도입하여 시스템 안정성과 확장성을 확보하였고, 최종 일관성(Eventual Consistency) 전략에 따라 일시적인 비일관성을 허용하되, 중요 시점에서는 Master DB를 통해 정합성을 보장함으로써 실무에 적합한 읽기-쓰기 분리를 실현하였다.
또한, 쿠버네티스를 통한 배포 자동화 및 실시간 모니터링 체계를 구축하여, 장애 발생 시 즉각적인 복구와 확장이 가능한 환경을 마련하였다.
이와 같은 경험은 대규모 시스템 구축 및 운영에 필요한 필수 역량을 갖추고 대규모 트래픽을 다루는 전략을 키우는 것에 많은 도움이 되었다고 생각한다.
