
개요
앞선 데이터베이스 시리즈에서 관계형 데이터베이스(RDBMS)의 구조와 특징,
그리고 실무에서 데이터베이스를 사용할 때 고려해야 할 보안 이슈들을 살펴봤습니다.
이번 글에서는 한 걸음 더 나아가,
최근 빅데이터, 실시간 처리, 대용량 트래픽 환경에서 주목받는 NoSQL 데이터베이스를 조명하고,
기존 SQL(RDBMS)과는 어떻게 다르고,
실제 서비스 개발에서 어떤 상황에 적합한지 비교해보고자 합니다.
NoSQL은 기존 RDBMS와는 전혀 다른 방식의 데이터 저장 구조와 확장성을 제공하지만,
그만큼 장단점도 뚜렷합니다.
이 글을 통해 NoSQL의 대표적인 저장 방식과 특징,
그리고 SQL과의 차이점, 선택 기준을 정리해
실제 서비스나 프로젝트에서 상황에 따라
어떤 데이터베이스가 더 적합할지 직접 비교하고 결정할 수 있도록 내용을 구성했습니다.
1. NoSQL이란?
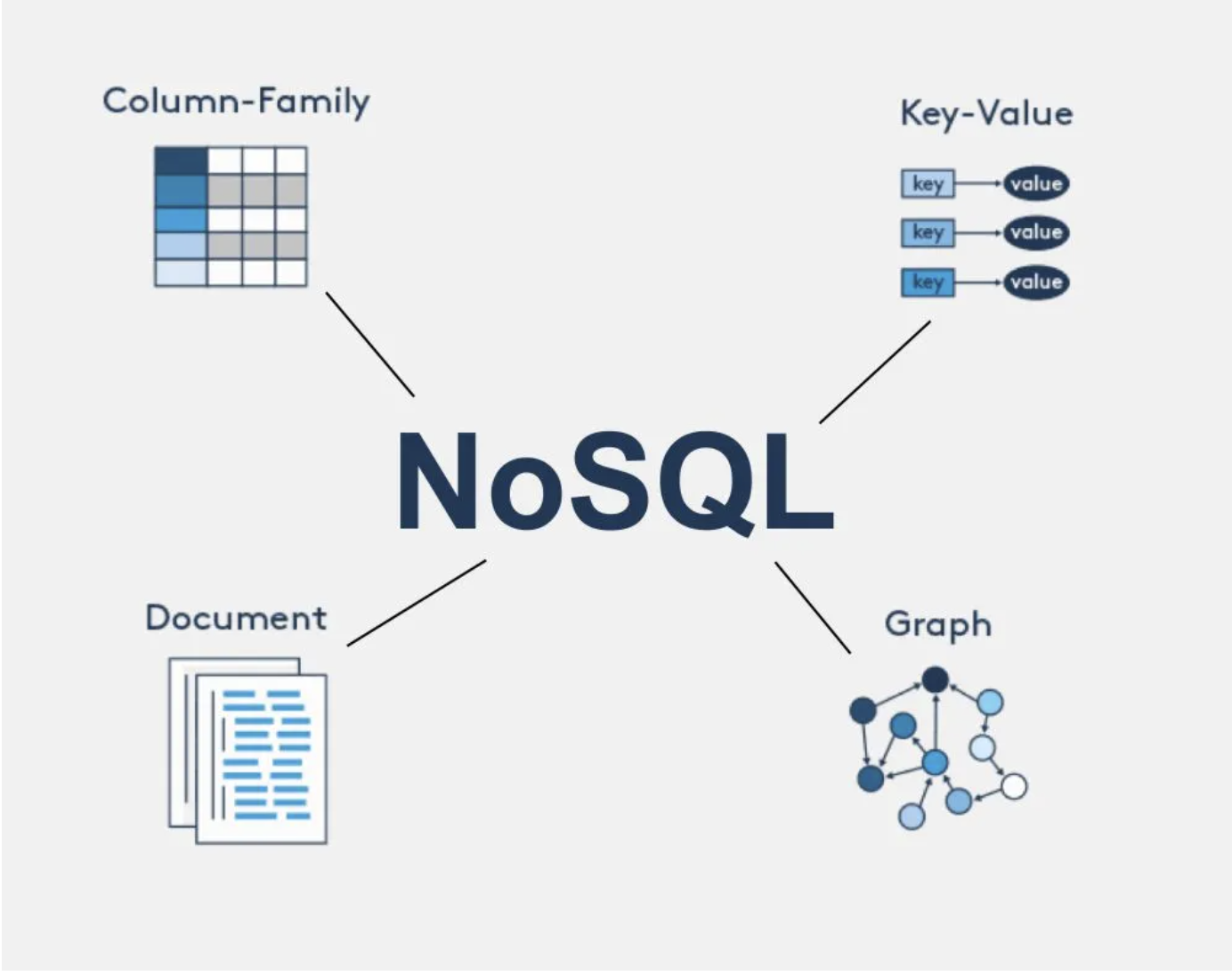
NoSQL이란 ?
Not Only SQL 혹은 Non-Relational Operational DataBase의 약자로 비관계형 데이터베이스를 지칭합니다.
기존에 앞선 글에서 주로 다뤘던 관계형 데이터베이스와 같은 관계형 데이터 모델과 달리,
대량의 분산된 비정형 데이터를 저장하고 조회하는 데 특화된 데이터베이스 모델입니다.
그렇다면 비정형 데이터란 무엇을 말하는 걸까요?
예를 들어,
- 소셜 미디어의 피드(글, 댓글, 좋아요 등 다양한 형태)
- 사용자 로그(접속 기록, 행동 이력 등)
- 센서 데이터(IoT에서 발생하는 다양한 구조의 데이터)
- 이미지, 동영상, JSON, XML 등
처럼, 고정된 테이블 구조가 아니라 다양한 구조나 형태를 가진 데이터를 의미합니다.
등장 배경
초기 데이터베이스 시스템(RDBMS)은 은행, 회계 등 정형 데이터(테이블 형태)에 매우 강점을 보였습니다.
하지만 현대의 웹 서비스, 빅데이터 환경에서는
- 데이터 양이 폭발적으로 증가하고
- 구조가 자주 변경되거나,
- 다양한 형식의 데이터가 유입되는
새로운 요구가 등장했습니다.
이러한 변화에 유연하게 대응하고,
확장성과 성능을 확보하기 위해
NoSQL 데이터베이스가 등장하게 되었습니다.
2. NoSQL의 주요 특징
1) 스키마 유연성
- NoSQL DB는 정해진 스키마(테이블 구조) 없이 데이터를 저장할 수 있습니다.
- 새로운 속성이 추가되거나, 데이터 구조가 바뀌어도 기존 데이터를 수정하지 않고 바로 저장할 수 있습니다.
- 빠르게 변화하는 서비스 요구사항에 대응하기 좋고,
스타트업이나 프로토타입 개발 등에서 구조 변경에 대한 부담이 매우 적습니다.
2) 대규모 데이터 처리 및 확장성
- NoSQL은 수평적 확장(Scale-Out)에 최적화되어 있습니다.
- NoSQL의 경우 설계 자체가 여러 대의 서버에서 데이터 분산/병렬 처리에 최적화 되어 있습니다.- 서버(노드)를 여러 대 추가해서 용량과 처리량을 늘릴 수 있습니다.
- 반면, 전통적인 RDBMS는 주로 수직적 확장(Scale-Up, 즉 더 좋은 서버로 업그레이드)에 의존하는 경우가 많습니다.
- 빅데이터 환경이나 트래픽이 급격하게 증가하는 서비스에 매우 유리합니다.
- 대용량 데이터 저장, 대량의 읽기/쓰기 요청을 분산해서 처리
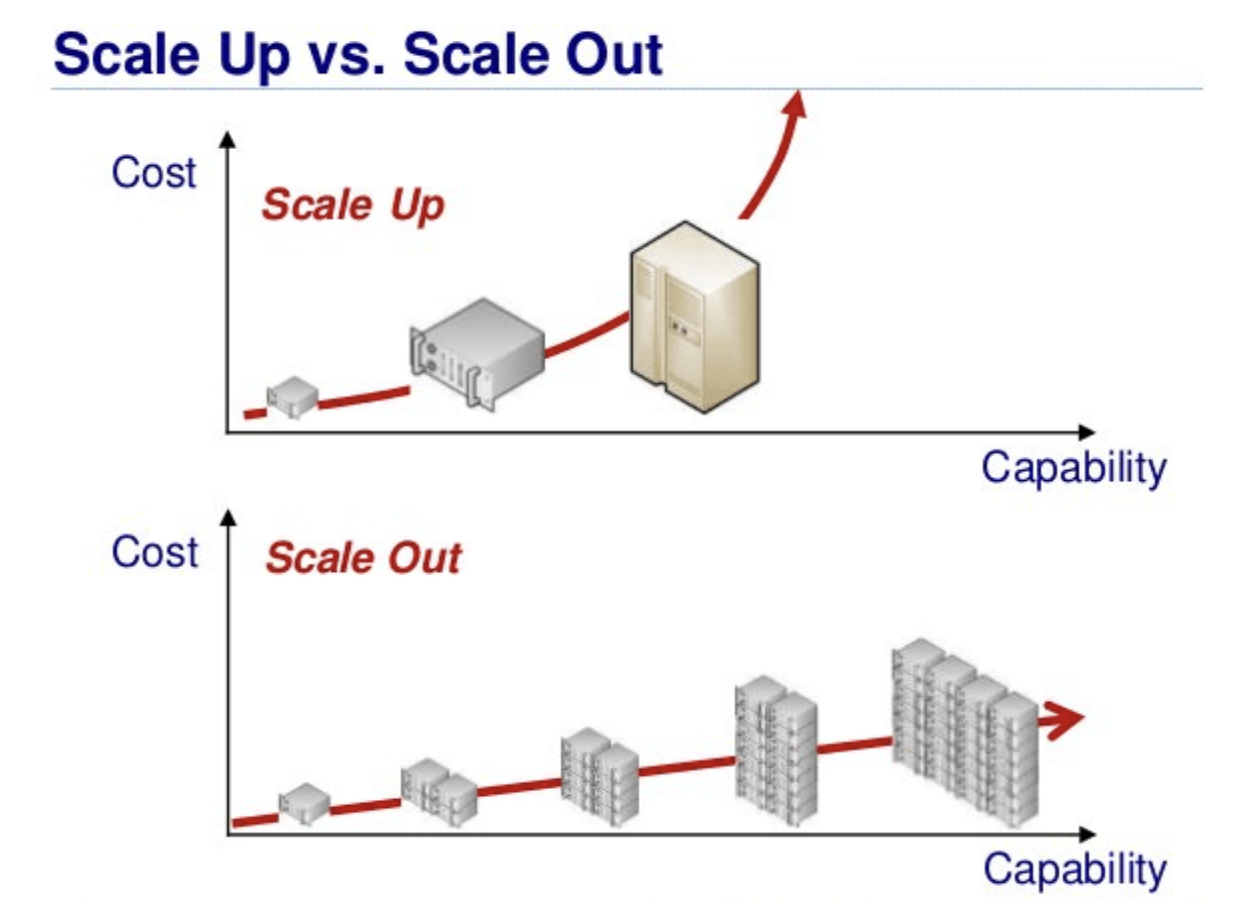
수평적 확장 vs 수직적 확장
✅ 수직적 확장(Scale-Up)이란?
-
정의:
하나의 서버(노드)에 더 좋은 CPU, 더 많은 메모리, 빠른 디스크 등 더 강력한 하드웨어로 업그레이드하는 방식 -
특징:
- 시스템 아키텍처 변경 없이 성능 향상 가능
- 구축과 관리가 비교적 단순
- 하드웨어의 한계(물리적 한계, 비용)가 있음
-
예시:
- 8GB RAM 서버 → 32GB RAM 서버로 교체
- 4코어 → 32코어 CPU로 교체
-
단점:
- 한계에 도달하면 더 이상 확장 불가
- 고성능 장비일수록 가격이 기하급수적으로 비싸짐
- 서버 다운 시 서비스 전체가 중단될 위험이 큼 (Single Point of Failure)
✅ 수평적 확장(Scale-Out)이란?
-
정의:
여러 대의 서버(노드)를 추가해서 시스템 전체 용량과 처리량을 늘리는 방식 -
특징:
- 비교적 저렴한 서버 여러 대로 확장 가능
- 필요에 따라 서버 추가/제거가 유연
- 대규모 데이터/트래픽에 강함
- 분산 환경 설계가 필요(샤딩 등)
-
예시:
- 8GB RAM 서버 1대 → 8GB RAM 서버 10대
- 데이터베이스 샤딩, 클러스터링, 분산 파일 시스템 등
-
장점:
- 확장성이 거의 무한 (서버를 계속 추가)
- 장애 발생 시 일부 노드만 영향(가용성↑)
- 클라우드 환경에서 효과적(자동 스케일링 등)
-
단점:
- 분산 시스템 설계, 데이터 일관성 유지 등이 복잡
- 조인, 트랜잭션 등 구현 난이도↑
표로 정리
| 수직적 확장(Scale-Up) | 수평적 확장(Scale-Out) | |
|---|---|---|
| 방법 | 서버 성능 업그레이드 | 서버 대수 추가 |
| 한계 | 하드웨어 물리적 한계 | 이론상 무한 확장 가능 |
| 비용 | 기하급수적으로 증가 | 개별 서버는 저렴, 총합 조절 |
| 장애 | 단일 장애 지점(SPOF) | 일부 노드만 영향 |
| 대표 | 전통적 RDBMS | NoSQL, 분산 DB, 클라우드 |
3) 다양한 저장 모델 지원
- NoSQL은 한 가지 형태의 데이터만 저장하는 것이 아니라,
서비스의 특성에 맞는 다양한 저장 모델을 선택할 수 있습니다.- Key-Value형: 단순한 데이터 캐싱/세션 관리 등 (예: Redis)
- Document형: 복잡한 구조의 데이터를 유연하게 저장 (예: MongoDB)
- Column형: 대규모 분석, 타임시리즈 데이터 (예: Cassandra)
- Graph형: 복잡한 관계/연결 데이터(예: 친구관계, 추천 등) (예: Neo4j)
- 데이터의 특성/용도에 따라 최적의 모델을 선택할 수 있는 점이 큰 장점입니다.
- 다양한 저장 모델에 대해서는 아래에서 다시 다루도록 하겠습니다.
3. NoSQL의 분류와 저장 방식
1) Key-Value Database
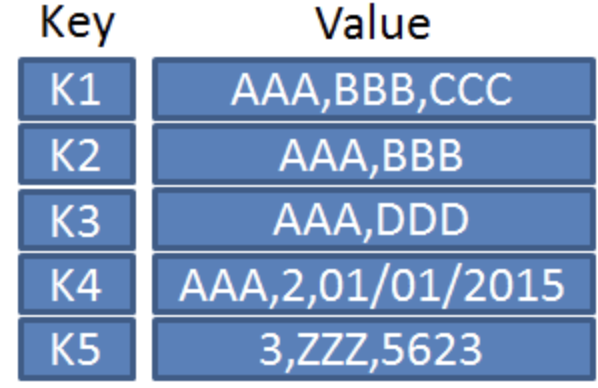
Key-Value 형식의 특징
-
키와 벨류로만 이루어진, 저장과 조회라는 가장 간단한 원칙에 충실한 데이터 베이스이다.
-
key의 값은 중복이 안된다.
-
key값을 통해 value를 찾을수 있다.
-
In-Memory 저장 방식이다.
-
Key-value형태이므로 조회 속도가 빠르다.
-
key-value형 구조는 아래와 같은 형태의 애플리케이션에서 주로 사용된다.
- 성능 향상을 위해 관계형 데이터베이스에서 데이터 캐싱
- 장바구니 같은 웹 애플리케이션에서 일시적인 속성 추적
- 모바일 애플리케이션용 사용자 데이터 정보와 구성 정보 저장
- 이미지나 오디오 파일 같은 대용량 객체 저장
대표적인 key-value Database
- Redis
- Riak
2) Document형
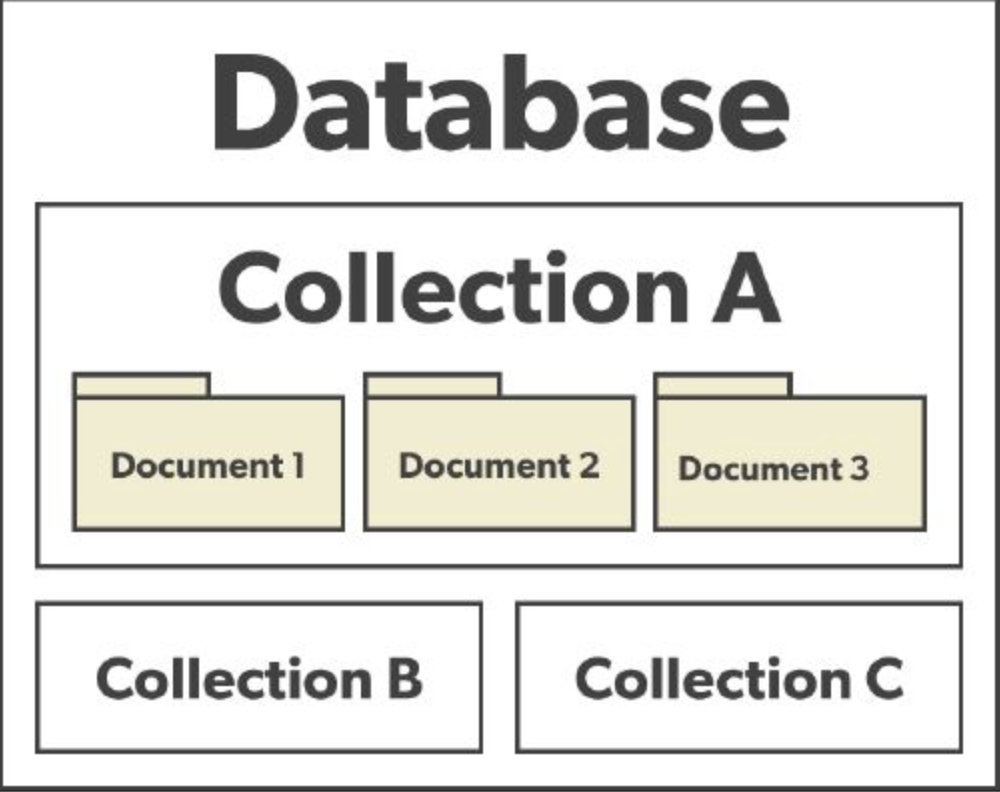
Document 형식의 특징
- Key-Value 구조에서 Value 부분이 단순 데이터가 아니라 문서(Document) 자체입니다.
- 이 문서는 보통 JSON, BSON, XML과 같은 반정형(Semi-structured) 데이터 형식으로 저장됩니다.
- 문서마다 저장되는 필드(구조)가 달라도 됨 → 스키마가 유연함!
- 중첩 구조, 배열 등 복잡한 데이터 구조를 한 번에 저장 가능.
- 다양한 필드 기준으로 검색/필터링/정렬 등 쿼리가 가능함.
- 하나의 문서에 실제 서비스의 “게시글”, “주문”, “사용자 정보” 등 복잡한 데이터를 통째로 담을 수 있음.
Document DB는 아래와 같은 애플리케이션에서 주로 사용됩니다
- JSON 데이터를 그대로 저장/조회하는 웹·모바일 백엔드
- 구조가 자주 바뀌거나, 다양한 속성이 존재하는 데이터 관리
- 복잡하게 중첩된(비정규화된) 데이터를 사용하는 서비스
- 로그 데이터, 이벤트 데이터, 메타데이터 저장
대표적인 Document Database
- MongoDB
- CouchDB
- Couchbase
Key-Value형과 Document형의 차이점
| 구분 | Key-Value DB (Redis) | Document DB (MongoDB) |
|---|---|---|
| 저장 구조 | key : value (값은 단순 데이터/문자열) | key : document(복잡한 JSON/문서) |
| 스키마 유연성 | 단순 (key와 value만) | 매우 유연 (문서마다 구조 다름) |
| 검색/조회 | key로만 조회 (O(1) 속도) | key + document 내 필드로도 검색 |
| 중첩/복합 구조 | 불가 (value에 배열/객체 직접X) | 가능 (JSON 구조 그대로 저장/검색) |
| 예시 | 로그인 세션 저장, 캐시 | 게시글, 상품 정보, 주문 내역 |
Document형 과 RDBMS의 차이
| 구분 | Document형(DB) | RDBMS (관계형 DB) |
|---|---|---|
| 저장 구조 | Collection(=Table)에 Document(=Row) 단위로 JSON/BSON 등 반정형 데이터 저장 | Table에 Row, Column 정형 데이터 저장 |
| 스키마 | 유연/동적: 문서마다 구조(필드) 달라도 됨 | 엄격/정적: 컬럼/타입 고정, 구조 변경 어려움 |
| 확장성 | 수평 확장(Sharding) 용이 | 주로 수직 확장(Scale up) 선호 |
| 관계 표현 | JOIN 없음 (중첩, 비정규화, 데이터 복제) | JOIN 지원: 테이블 간 관계 표현 용이 |
| 데이터 구조 | 중첩/배열/복잡 데이터 1문서에 모두 저장 가능 | 각 데이터는 테이블/행/열에 분산 저장 |
| 트랜잭션 | 단일 문서 단위 ACID(최근에는 멀티문서 지원 일부) | 강력한 ACID 트랜잭션 지원 |
| 검색/조회 | key, document 내 필드 등 다양한 기준으로 빠른 조회 | 복잡한 SQL, 다양한 조건/조인 지원 |
| 변경/확장 | 구조, 필드 변경 쉽고 빠름 | 구조 변경 제약 많고, 마이그레이션 부담 |
| 적합 분야 | 로그, 유저 정보, 메타데이터, 구조 자주 바뀌는 서비스 | 금융, ERP, 이커머스, 강한 무결성/정합성 필요 서비스 |
| 예시 | MongoDB, CouchDB 등 | MySQL, MariaDB, Oracle, PostgreSQL 등 |
예시로 보는 Document형
{
"_id": "user_1001", // ← key
"name": "홍길동",
"email": "hong@naver.com",
"age": 31,
"roles": ["admin", "user"],
"profile": {
"city": "Seoul",
"joined": "2024-01-12"
}
}3) Column(열기반) 형

Column(열기반) 형식의 특징
- 한 컬럼(열)별로 데이터를 연속 저장
(ex: 이름만, 점수만 한 줄로 쭉 저장) - 데이터의 압축률이 높음 → 저장 공간 효율, I/O 성능 개선
- 일부 컬럼만 빠르게 조회 가능 → 대용량 데이터 분석/통계에 강점
- 수평 확장(분산) 구조를 쉽게 지원
Column형 구조는 아래와 같은 형태의 애플리케이션에서 주로 사용된다
- 대량의 로그, 이벤트 데이터, IoT 센서 데이터 등 빠른 집계/분석이 필요한 서비스
- BI(비즈니스 인텔리전스), 데이터 웨어하우스, 리포팅 시스템
- 수백만~수억건의 데이터에서 특정 컬럼(필드)만 추출해서 통계/분석
대표적인 Column Database
- Apache HBase
- Apache Cassandra
- Amazon Redshift
예시로 보는 Column형
| id | name | age | score |
|---|---|---|---|
| 1 | Alice | 23 | 85 |
| 2 | Bob | 25 | 92 |
| 3 | Carol | 22 | 78 |
이러한 데이터가 있다고 가정하자
예를들어 행기반 RDBMS의 저장 형태는
[1, Alice, 23, 85], [2, Bob, 25, 92], [3, Carol, 22, 78]
한 Row(행)이 통째로 한 블록에 저장된다.
OLTP(온라인 트랜잭션)에 적합하다.
반대로 컬럼(행) 기반 데이터베이스가 저장되는 구조는
id: [1, 2, 3]
name: [Alice, Bob, Carol]
age: [23, 25, 22]
score:[85, 92, 78]같은 컬럼끼리 묶어서 저장된다.
OLAP(온라인 분석처리)에 적합하다.
4) Graph(그래프) Database
Graph(그래프) 형식의 특징
- 데이터(노드, Node)와 데이터 간의 관계(간선, Edge)를 그래프 구조로 저장
- 노드(Node): 사람, 장소, 제품 등 실제 엔터티(객체)를 나타냄
- 간선(Edge): 노드 간의 “관계”를 표현 (예: 친구, 팔로우, 구매함 등)
- 각 노드/간선은 다양한 속성(필드, Property)을 가질 수 있음
- 관계 기반 쿼리
(ex: "A와 B가 얼마나 가까운가?", "누가 누구의 친구의 친구인가?")에 최적화 - 관계를 빠르게 탐색하고, 복잡한 네트워크 분석에 강점
그래프형 구조는 아래와 같은 형태의 애플리케이션에서 주로 사용된다
- 소셜 네트워크 (예: 친구 관계, 팔로우 관계)
- 추천 시스템 (ex: “이 사람이 이 상품도 구매했음”)
- 조직 구조, 계층 구조, 인맥 분석
- 사기 탐지(Fraud Detection)
- 경로 탐색 (ex: 네비게이션, 배송 경로 최적화)
대표적인 Graph Database
- Neo4j
- Amazon Neptune
- TigerGraph
- ArangoDB (멀티모델 지원)
예시로 보는 Graph 형
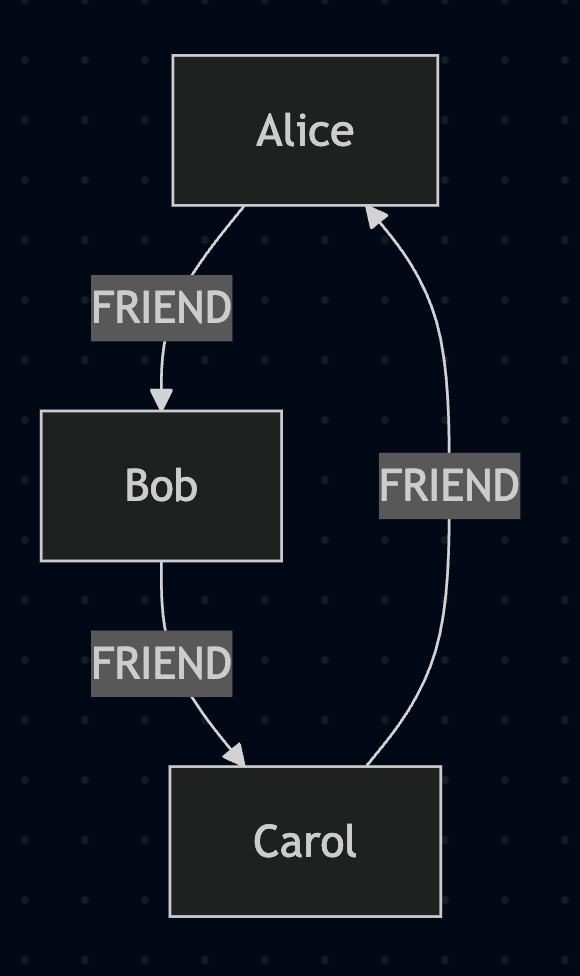
(소셜 네트워크에서의 친구 관계 데이터)
노드:
- UserA (id: 1, name: "Alice")
- UserB (id: 2, name: "Bob")
- UserC (id: 3, name: "Carol")
간선:
- Alice –[FRIEND]→ Bob
- Bob –[FRIEND]→ Carol
- Carol –[FRIEND]→ Alice
4. SQL vs NoSQL: 실제로 무엇이 다를까?

그렇다면 관계형 데이터베이스와 비관계형 데이터베이스는 서로 어떤 장단점을 갖고 있을까?
실질적으로 두 시스템이 어떻게 다르고, 어떤 상황에서 더 적합한지 4가지 핵심 기준을 중심으로 정리 해보았다.
1) 데이터 모델 / 스키마 유연성
SQL(RDBMS)
- 정해진 스키마(테이블 구조)에 따라 데이터를 저장해야 한다.
- 테이블을 생성할 때 각 컬럼(필드)의 데이터 타입과 구조를 미리 정의.
- 데이터의 일관성과 무결성을 DBMS 차원에서 강제함.
- 구조가 바뀌면(컬럼 추가/삭제 등) 테이블 스키마를 변경하는 명령이 필요하고,
데이터 마이그레이션이 번거로울 수 있음.
NoSQL
- 스키마가 고정되어 있지 않거나 매우 유연하다.
- Document DB는 문서마다 구조(필드, 타입 등)가 달라도 저장 가능.
- Key-Value/Column/Graph 등 각기 다른 구조를 지원.
- 데이터 구조가 자주 바뀌는 서비스, 빠른 프로토타이핑, 다양한 데이터 포맷에 특히 유리함.
- 하지만, DB 자체에서 무결성 보장 기능이 약할 수 있음 (애플리케이션에서 관리 필요).
2) 확장성(Scalability)
SQL(RDBMS)
- 수직적 확장(Scale-Up)이 기본 전략.
- 더 빠른 CPU, 더 많은 메모리/스토리지로 서버 성능을 올리는 방식.
- 단일 서버 성능에 의존 → 하드웨어 한계에 도달 시 확장 한계가 명확함.
- 샤딩 등으로 분산(Scale-Out)도 가능하지만, 구조가 복잡하고,
대부분의 전통적인 RDBMS는 수평 확장에 최적화되어 있지 않음.
NoSQL
- 설계 자체가 수평적 확장(Scale-Out)에 최적화되어 있음.
- 여러 대의 서버에 데이터 분산(샤딩, 클러스터링) 구조.
- 서버(노드)를 추가하면 처리량/용량이 실시간으로 거의 선형적으로 증가.
- 빅데이터, 대규모 트래픽, 클라우드 환경에서 탁월한 확장성 제공.
3) 일관성 및 트랜잭션(Consistency & Transaction)
SQL(RDBMS)
- ACID(Atomicity, Consistency, Isolation, Durability)
트랜잭션을 엄격하게 보장한다.- 복잡한 거래, 이체, 주문 등 일관성이 반드시 필요한 시스템에 매우 적합.
- 다중 테이블 조인, 복잡한 롤백, 강한 일관성 유지 등 가능.
- 데이터 무결성/정합성이 최우선인 경우(예: 은행, 회계) 표준 선택지.
NoSQL
- 대부분 BASE(Basically Available, Soft state, Eventual consistency)
원칙을 따른다.- 완화된 일관성(최종적 일관성)을 제공하는 경우가 많다.
- 즉, 데이터가 모든 노드에 “즉시” 동일하게 반영되지 않고,
일정 시간이 지난 후 일관성이 맞춰질 수 있음.
- 트랜잭션/일관성이 아예 없는 것은 아니나,
단일 문서/객체 수준의 트랜잭션을 지원하는 것이 일반적. - 최신 NoSQL 중에서는 멀티-문서 트랜잭션 지원이 늘고 있으나,
복잡도와 성능의 trade-off가 존재함.
4) 적합한 사용 사례/환경
SQL(RDBMS)가 적합한 경우
- 데이터 구조가 명확하고, 변하지 않는 경우(예: 회원관리, 회계)
- 트랜잭션, 강한 일관성, 무결성이 중요한 금융, ERP, 주문/결제 시스템
- 복잡한 쿼리, 다중 테이블 조인, 집계 등 관계형 데이터 처리
- 데이터를 오래, 안정적으로 보관해야 하는 핵심 업무 시스템
NoSQL이 적합한 경우
- 데이터 구조가 자주 바뀌거나, 다양한 데이터가 들어오는 경우(비정형, 반정형)
- 수평 확장이 꼭 필요한 빅데이터, 대규모 트래픽 서비스(예: 소셜 미디어, IoT, 로그분석)
- 빠른 개발, 프로토타이핑, 유연한 스키마 요구
- 분산 환경/클라우드에서 성능과 가용성이 최우선인 서비스
- “관계”가 중요한 경우(그래프 DB, 추천, 인맥 등)
5) NoSQL의 장점/단점 포함 요약 표
| 항목 | SQL(RDBMS) | NoSQL |
|---|---|---|
| 스키마 | 고정, 명확(변경 번거로움) | 유연/동적(변경 용이) |
| 확장성 | 주로 수직적(Scale-Up) | 수평적(Scale-Out) |
| 일관성 | 강한 일관성, ACID 보장 | 최종적 일관성, BASE(가벼운 트랜잭션) |
| 쿼리 | 복잡한 쿼리, 조인, 집계 가능 | 단순 쿼리, 조인 약함, 집계는 제한적 |
| 성능 | 적은 데이터/OLTP에 최적, 느려질 수 있음 | 대량 데이터/OLAP에 강점, 분산 성능 |
| 단점 | 확장 한계, 스키마 유연성 부족 | 복잡한 관계, 트랜잭션 한계 |
| 대표 사례 | 금융, ERP, 전통적 엔터프라이즈 시스템 | 소셜, 빅데이터, IoT, 로그, 캐시 |
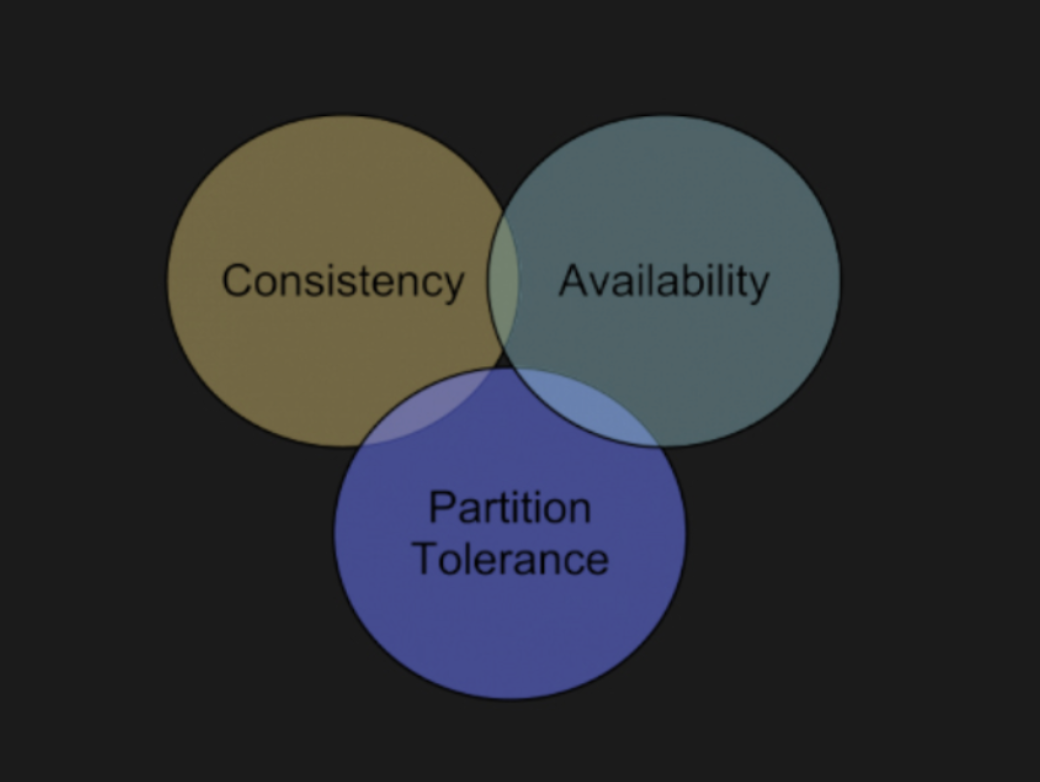
5. CAP 이론과 NoSQL
분산 데이터베이스를 이해할 때 꼭 알아야 하는 이론이 바로 CAP 이론입니다.
해당 내용에 대한 좀 더 자세한 내용을 확인 할 수 있는 링크는 밑에 남겨두겠습니다.
CAP이란
- Consistency(일관성)
- Availability(가용성)
- Partition Tolerance(분할 허용성)
세 가지 속성의 약자로,
"분산 시스템에서는 이 세 가지 중 두 가지만 동시에 완벽하게 만족시킬 수 있고,
세 가지를 모두 만족하는 건 불가능하다"는 내용을 담고 있습니다.
CAP 이론을 쉽게 풀이하면?
-
일관성(Consistency)
- 어떤 노드에 데이터를 저장하든, 즉시 모든 노드에서 항상 같은 데이터를 조회할 수 있다.
- 예) A에서 잔고를 변경하면, B에서도 바로 그 결과가 보여야 함
-
가용성(Availability)
- 모든 요청에 반드시 응답해야 한다.
- 일부 데이터가 최신이 아닐 수 있지만, 서비스가 멈추지 않아야 한다.
- 예) 한쪽 서버가 죽어도, 남은 서버가 항상 응답
-
분할 허용성(Partition Tolerance)
- 네트워크 장애 등으로 노드 간 통신이 끊겨도 시스템 전체가 동작해야 한다.
- 예) 서버 간 연결이 끊겨도 각각 독립적으로 서비스 유지
현실 세계에서는?
- 실제 분산 시스템(특히 NoSQL)은 P(Partition Tolerance)는 반드시 가져가야 합니다.
- 그래서 보통 아래 두 가지 중 하나를 선택합니다.
| 유형 | 특성 | 예시 |
|---|---|---|
| CP (일관성+분할 허용) | 데이터 정합성이 가장 중요, 가용성은 잠시 희생할 수 있음 | MongoDB, HBase |
| AP (가용성+분할 허용) | 서비스 중단보단, 일관성은 나중에 맞추더라도 즉시 응답 | Cassandra, DynamoDB |
비유로 정리하자면?
-
CP 시스템:
“동기화가 될 때까지 잠시 기다려서라도 항상 같은 결과를 보여주자”
→ ex) 금융 서비스, 은행 -
AP 시스템:
“잠깐 데이터가 달라도 일단 서비스부터 계속 응답!”
→ ex) 소셜 서비스, 로그 저장, 알림 등
[Reference]

좋은 글 감사합니다🙇♂️