
목차
개요
앞선 글에서는 인덱스를 통해 데이터베이스가 방대한 양의 데이터에서도
얼마나 빠르고 효율적으로 원하는 정보를 찾을 수 있는지 살펴보았다.
그런데 대규모 데이터를 다룰 때,
검색 성능만큼이나 중요한 게 있다.
바로 데이터의 ‘정확성’과 ‘일관성’을 유지하는 것이다.
엑셀, 스프레드시트처럼 데이터가 이리저리 중복되어 있다면
“어디가 진짜지?” “왜 이 값이 서로 다르지?”
같은 혼란이 쉽게 발생한다.
실제로 서비스 규모가 커질수록
데이터 중복, 불일치, 이상(anomaly) 같은 문제가
빈번하게 발생하며,
이 때문에 서비스 장애, 운영 비용 증가,
최악의 경우엔 비즈니스 리스크로까지 번질 수 있다.
이런 문제를 근본적으로 해결하기 위해
데이터베이스에서는 ‘정규화(Normalization)’라는 설계 기법을 사용한다.
정규화란 무엇인가?
정규화란,
데이터의 중복을 최소화하고
이상(Anomaly)을 방지해
최적의 테이블 구조로 설계하는 데이터베이스 설계 기법입니다.
불필요하게 중복된 데이터를 줄이고,
데이터 변경/삽입/삭제 시 발생할 수 있는 ‘이상 현상’을 막기 위해 도입되었습니다.
정규화의 탄생 배경
- 왜 정규화가 필요한가?
- 초창기 DB는 설계가 단순하여,
데이터 중복 및 불필요한 데이터 증가로
‘삽입, 삭제, 갱신’ 등에서 예상치 못한 문제(이상, Anomaly)가 자주 발생함. - 이러한 데이터 이상을 예방하기 위해
정규화 과정이 탄생하였다.
- 초창기 DB는 설계가 단순하여,
이상이란?
데이터베이스에서의 "이상(Anomaly)"이란?
이상(Anomaly)이란
테이블(릴레이션) 설계가 비효율적이거나 정규화가 제대로 이루어지지 않았을 때,
데이터를 삽입, 수정(갱신), 삭제하는 과정에서
원하지 않거나 의도치 않은 데이터의 불일치, 중복, 손실이 발생하는 현상을 말한다.
아래 예시로 각 이상을 SQL 쿼리와 함께 실험해보았다.
먼저 각종 이상 실험을 위해 정규화가 되지 않은 테이블을 임시로 만들었다.
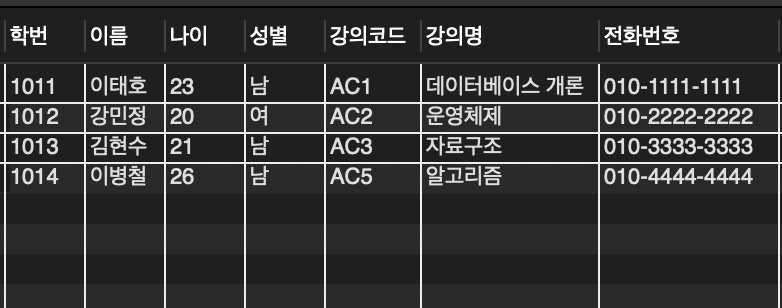
1. 삽입 이상 (Insertion Anomaly)
정의
- 자료를 삽입할 때 의도하지 않은 자료까지 같이 삽입하거나,
- 일부 정보만 추가할 수 없어 NULL 값이나 임의의 데이터를 넣어야 하는 현상
예시 상황
- 새로운 학생 ‘최영수’가 아직 수강한 강의가 없음
- 강의코드, 강의명에 값이 없으니 NULL을 넣을 수밖에 없음
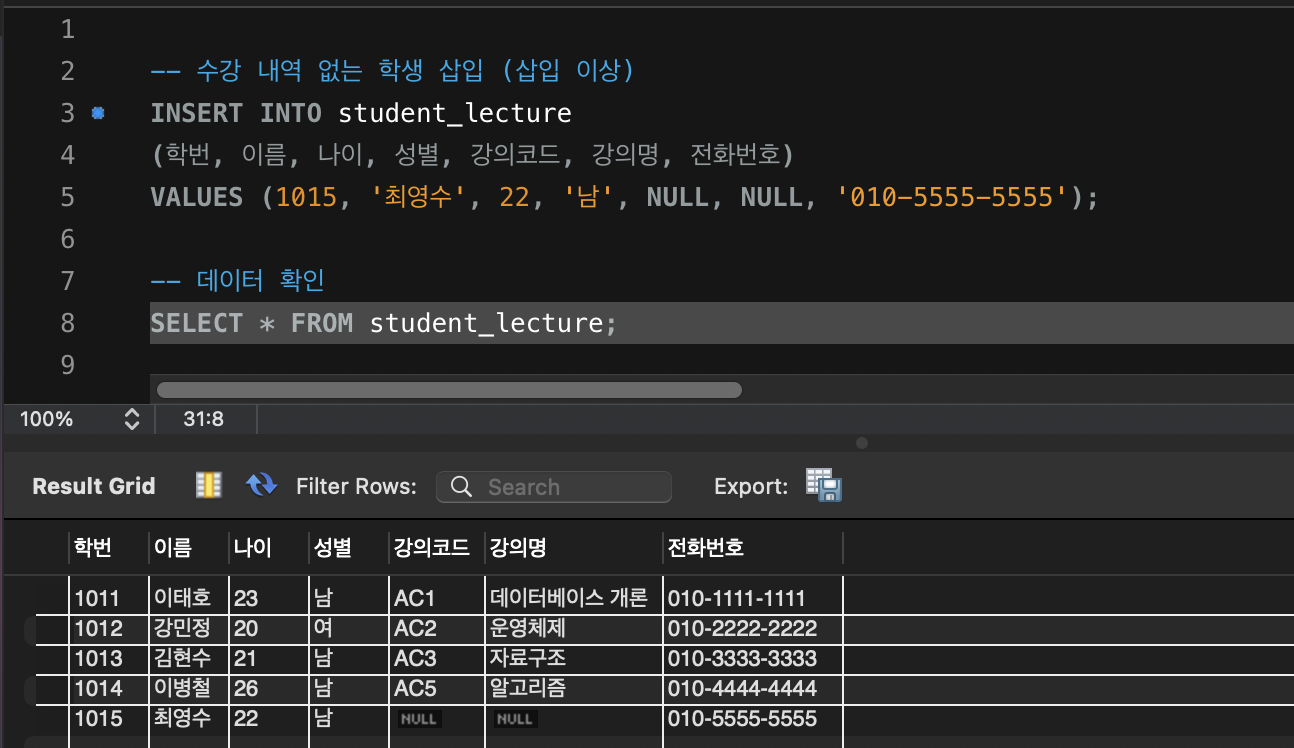
실험 쿼리
INSERT INTO student_lecture
(학번, 이름, 나이, 성별, 강의코드, 강의명, 전화번호)
VALUES (1015, '최영수', 22, '남', NULL, NULL, '010-5555-5555');- 강의 정보 없이 학생만 추가하려다 강의코드/강의명에 NULL을 넣게 됨
- 정규화된 구조라면 이런 NULL이 발생하지 않음
실제 실행
2. 갱신 이상 (Update Anomaly)
정의
- 중복된 데이터 중 일부만 수정되어 데이터 모순(불일치)이 생기는 현상
예시 상황
-
김현수(학번 1013)가 전화번호를 변경했을 때,
-
하나의 튜플(행)만 수정하면 데이터가 불일치하게 됨
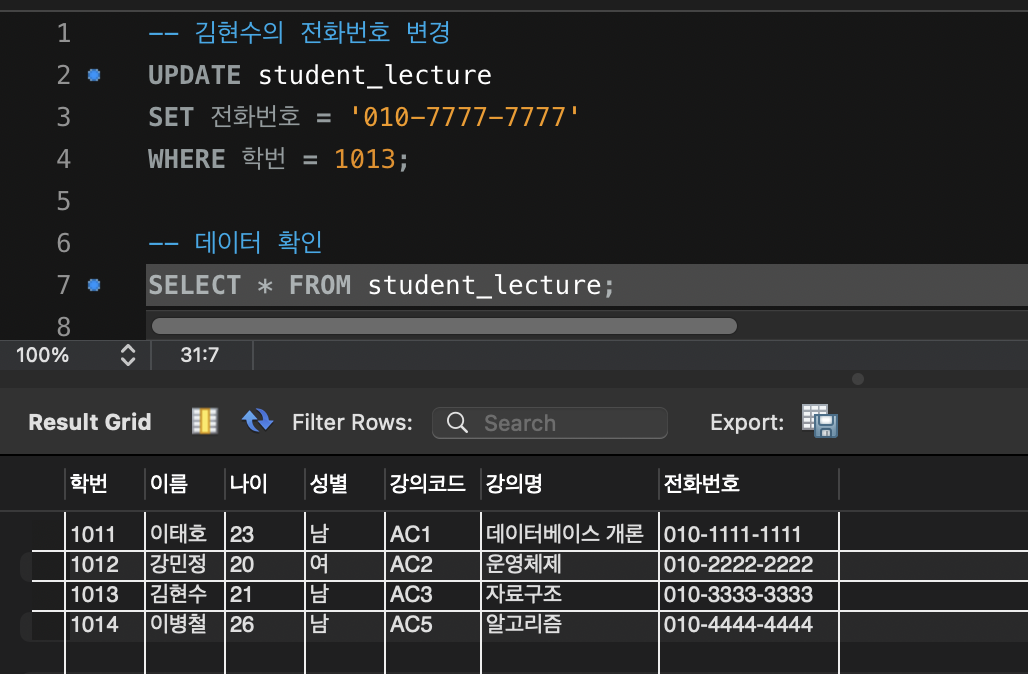
실험 쿼리
-- 김현수(자료구조 수강)의 전화번호만 수정
UPDATE student_lecture
SET 전화번호 = '010-9999-9999'
WHERE 학번 = 1013 AND 강의코드 = 'AC3';- 이렇게 하면 ‘AC3’은 바뀌지만,
‘AC4’는 여전히 3333-3333으로 남아 데이터 불일치가 발생!
실제 실행
3. 삭제 이상 (Deletion Anomaly)
정의
- 어떤 정보를 삭제할 때 의도하지 않은 다른 정보까지 함께 사라지는 현상
예시 상황
-
이태호(1011) 학생이 듣던 “데이터베이스 개론(AC1)” 강의를 더 이상 개설하지 않아 해당 행을 삭제
-
이태호 학생 정보 자체도 사라지게 됨
실험 쿼리
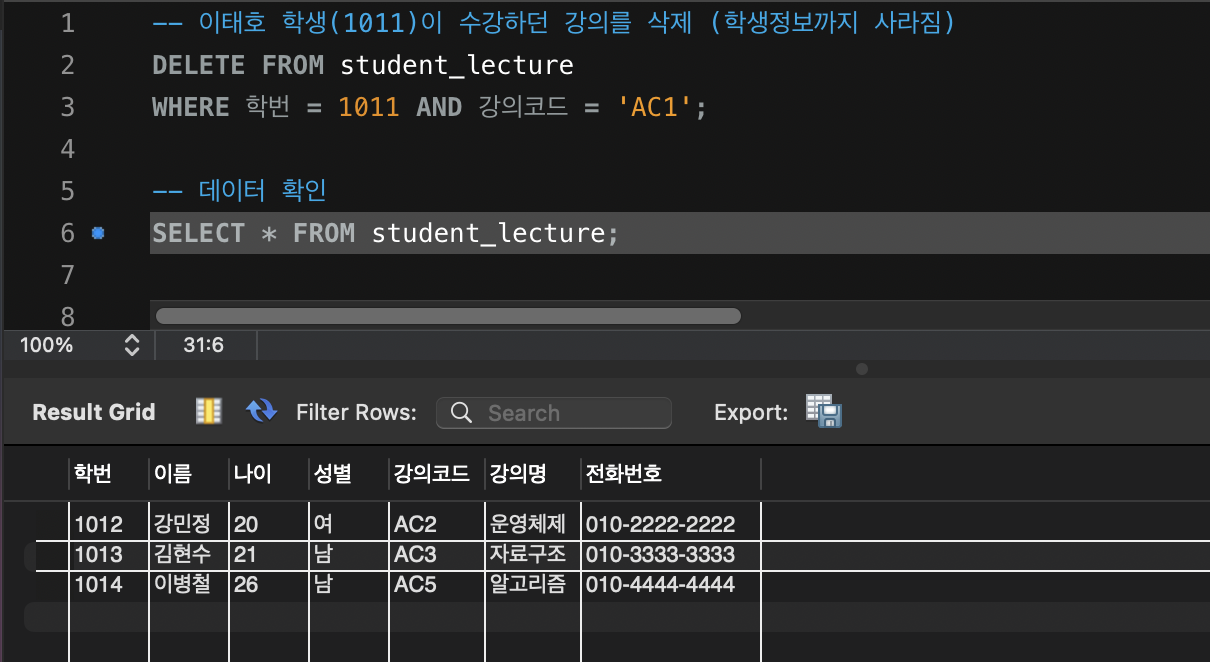
-- AC1 강의를 테이블에서 삭제
DELETE FROM student_lecture WHERE 강의코드 = 'AC1';이태호의 모든 정보(학생 정보)까지 함께 삭제됨
- 학생/강의 정보를 따로 관리하면 이런 문제를 피할 수 있음
실제 실행
📌 정리
삽입 이상: 학생만 추가하고 싶어도 강의 정보가 없으면 NULL이 들어가야 함
갱신 이상: 한 학생의 정보가 여러 줄에 중복되어, 일부만 바뀌면 데이터 불일치
삭제 이상: 한 강의(혹은 학생)의 정보를 삭제하다가, 연관된 다른 정보까지 한꺼번에 사라짐
이런 문제는 테이블을 정규화(학생/강의/수강 테이블 분리)하면 해결할 수 있다.
정규화의 단계와 종류
글에서는 실무에서 가장 많이 쓰이는 1정규화부터 BCNF단계까지만 다루도록 하겠다.
- 모든 컬럼이 원자값(Atomic Value)만 갖도록 테이블을 설계
- 예시: 컬럼에 배열/리스트 대신, 단일 값만
제1정규형(1NF)( 아직 정규화가 안된 테이블)
| 학번 | 이름 | 학과 | 교수 | 강의실 |
|---|---|---|---|---|
| 1001 | 홍길동 | 컴퓨터공학과,화학과 | 김철수,박지민 | 101호,102호 |
제1정규형(1NF)(정규화 완료)
| 학번 | 이름 | 학과 | 교수 | 강의실 |
|---|---|---|---|---|
| 1001 | 홍길동 | 컴퓨터공학과 | 김철수 | 101호 |
| 1001 | 홍길동 | 화학과 | 박지민 | 102호 |
| 1002 | 이영희 | 화학과 | 박지민 | 102호 |
제2정규형(2NF)
-제2정규형(2NF)은 제1정규형을 만족하면서,
기본키의 "부분 집합"에만 종속된 부분 함수 종속(Partial Dependency)을 제거하는 것입니다.
- 즉, 복합 기본키를 사용하는 테이블에서,
기본키의 일부 컬럼에만 종속된 속성이 있다면 그것을 별도의 테이블로 분리해야 합니다.
2정규형(2NF)( 아직 정규화가 안된 테이블)
| 학번 | 학과 | 교수 | 강의실 |
|---|---|---|---|
| 1001 | 컴퓨터공학과 | 김철수 | 101호 |
| 1001 | 화학과 | 박지민 | 102호 |
| 1002 | 화학과 | 박지민 | 102호 |
제2정규형(2NF)(정규화 완료)
| 학번 | 학과 |
|---|---|
| 1001 | 컴퓨터공학과 |
| 1001 | 화학과 |
| 1002 | 화학과 |
| 학과 | 교수 | 강의실 |
|---|---|---|
| 컴퓨터공학과 | 김철수 | 101호 |
| 화학과 | 박지민 | 102호 |
2개로 분리
제3정규형(3NF)
- 2NF를 만족하면서,
이행적 종속(Transitive Dependency) 제거
(키가 아닌 속성에 종속된 속성을 분리)
제3정규형(3NF)( 아직 정규화가 안된 테이블)
| 학번 | 이름 | 학과 | 교수 | 강의실 |
|---|---|---|---|---|
| 1001 | 홍길동 | 컴퓨터공학과 | 김철수 | 101호 |
| 1002 | 이영희 | 화학과 | 박지민 | 102호 |
제3정규형(3NF)(정규화 완료)
| 학번 | 이름 | 학과 |
|---|---|---|
| 1001 | 홍길동 | 컴퓨터공학과 |
| 1002 | 이영희 | 화학과 |
| 학과 | 교수 | 강의실 |
|---|---|---|
| 컴퓨터공학과 | 김철수 | 101호 |
| 화학과 | 박지민 | 102호 |
BCNF (보이스-코드 정규형)
BCNF(보이스-코드 정규형)( 아직 정규화가 안된 테이블)
- 3NF보다 더 엄격한 조건,
모든 결정자가 후보키가 되도록 설계
| 강의명 | 담당교수 | 교실 |
|---|---|---|
| DB | 홍교수 | 301 |
| DB | 이교수 | 302 |
| OS | 박교수 | 303 |
BCNF(보이스-코드 정규형)(정규화 완료)
| 강의명 | 담당교수 |
|---|---|
| DB | 홍교수 |
| DB | 이교수 |
| OS | 박교수 |
| 담당교수 | 교실 |
|---|---|
| 홍교수 | 301 |
| 이교수 | 302 |
| 박교수 | 303 |
역정규화(Denormalization)
정규화를 진행하면,
중복은 최소화되고 데이터 무결성은 높아지지만
쿼리가 복잡해지고 성능이 저하될 수 있다.
역정규화의 필요성과 적용 예시
- 정규화를 일부 해제하여
쿼리 성능, 응답 속도, 집계 효율을 높임 - 일부러 중복을 허용하거나,
테이블을 합치거나,
자주 조회되는 데이터로 컬럼을 분리하는 등의 실무적 테크닉
정규화의 장점과 단점
- 장점
- 데이터 중복 최소화,
무결성(Integrity) 보장,
이상(Anomaly) 방지
- 데이터 중복 최소화,
- 단점
- 테이블/관계가 많아져 쿼리가 복잡해지고,
Join 성능 저하 발생 가능
- 테이블/관계가 많아져 쿼리가 복잡해지고,
정규화가 적합한 상황
- 트랜잭션 무결성이 무엇보다 중요한 서비스
- 데이터 변경(INSERT/UPDATE/DELETE)이 잦은 환경
반정규화가 필요한 상황
- 대용량 조회가 많고, 응답 속도가 중요한 환경
- 집계/통계/리포트 쿼리가 자주 발생하는 환경
마무리 및 실무 Tip
정규화와 역정규화는
‘어떤 상황에서, 왜 적용할지’
실제 서비스/시스템 구조를 고려해서 유연하게 사용해야 합니다.
실제로는 정규화를 기본으로 설계하되,
필요에 따라 역정규화로 성능을 최적화하는 사례가 많다고 합니다.
참고 자료
이상 현상(Anomaly)이란?
