배열이란?
여러개의 값을 순차적으로 나열한 구조로 객체 타입에 속한다.
배열의 문법
배열이름 = [ 요소1, 요소2, ...];
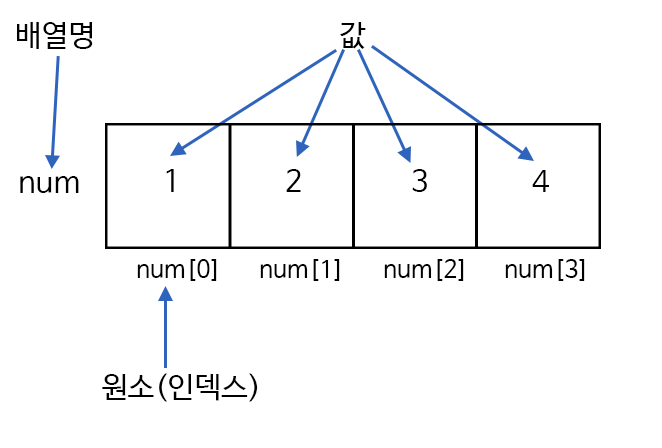
요소 : 배열이 가지고 있는 값
인덱스 : 배열에서 자신의 위치를 나타내는 0 이상의 정수
length : 배열의 길이를 나타내는 프로퍼티
인덱스로 배열의 항목에 접근하기
let fruits = ['사과', '바나나']
console.log(fruits[0]) // 사과
console.log(fruits[fruits.length - 1]) // 바나나
값의 순서와 length 프로퍼티는 배열이 반복문을 통해 순차적으로 값에 접근하기 적합한 자료구조로 만들어준다.
자바스크립트 배열은 배열이 아니다?!
일반적인 자료구조에서 말하는 배열은 동일한 크기의 메모리 공간에 연속적으로 나열되어 있어서 offset으로 접근 가능하며 이를 밀집 배열이라 한다.
또한 연속적으로 이어져 있지 않을 수 있는 배열 구조는 희소 배열이라고 한다.
JS 배열은 요소를 위한 각각의 메모리 공간이 동일한 크기를 갖지 않아도 되며, 일반적인 배열의 동작을 흉내 낸 특수한 객체이다.
JS배열은 인덱스를 나타내는 문자열을 키로 가지면 length 프로퍼티를 가지는데 이는 일반 객체와 비슷해 보일 순 있지만 최신 JS 엔진은 배열을 이와 구별하여 최적화하여 구현하여 성능에서 약 2배 이상 차이가 난다.
일반적인 배열과 JS 배열의 장단점
-
일반적인 배열은 인덱스로 요소에 빠르게 접근이 가능하지만 요소를 삽입, 삭제하는 경우 효율적이지 않다.
-
JS 배열은 해시 테이블로 구현된 객체여서 인덱스로 요소 접근시 일반적인 배열보다 성능적인 면에서 느리다. 그러나 특정 요소를 검색하거나 요소를 삽입, 삭제하는 경우 일반적인 배열 보다 빠른 성능을 기대할 수 있다.
length 프로퍼티와 희소 배열
length 프로퍼티는 요소의 개수로 배열의 길이를 나타내는 0 이상의 정수를 값으로 가지며 요소를 추가하거나 삭제할 때마다 자동 갱신된다.
length에 명시적으로 값을 할당할 수 있는데 요소보다 작은 숫자 값을 할당하면 배열 길이가 줄어들고 큰 숫자를 할당하면 length 프로퍼티 값이 변경되지만 길이가 늘어나지는 않는다.(빈 값으로 채워져있으며, 메모리 공간도 확보하지 않는다.)
일반적인 배열의 length는 배열 요소의 개수(배열의 길이)와 일치한다.
하지만, 희소 배열은 length와 배열 요소의 개수가 일치하지 않고 희소 배열의 length 가 실제 요소의 개수보다 언제나 크다.
희소 배열을 생성하지 않도록 주의하고, 배열에는 같은 타입의 요소를 연속적으로 위치시키는 것이 가장 좋다!
배열 생성 방법
1. 배열 리터럴
const arr = [];
const arr2 = [1, , 3]; // 희소 배열
console.log(arr[1]); // undefined
2. Array 생성자 함수
Array 생성자 함수는 안에서 new.target을 확인하기 때문에 new 연산자를 붙이지 않아도 배열을 생성하는 생성자 함수처럼 동작한다.
- 인수가 없으면 빈 배열을 생성한다.
- 인수가 1개이면 그 인수만큼 length를 갖는 배열을 생성한다.
- 전달된 인수가 2개 이상이거나 숫자가 아닌 경우 인수를 요소로 갖는 배열을 생성한다.
요소를 2^32 -1 개 만큼 가질 수 있다.
new Array(4, 6, 8); // [4, 6, 8]
// new 연산자와 함께 호출하지 않아도 동일하다.
Array(4, 6, 8); // [4, 6, 8]
const myArr = Array(4); // myArr.length = 43. Array.of
전달된 인수를 요소로 갖는 배열을 생성한다.
// 전달된 숫자가 1개여도 인수를 요소로 갖는 배열을 생성한다.
Array.of(3); // [3]
Array.of(3, 6, 9); // [3, 6, 9]
Array.of('Java'); // ['Java']4. Array.from
유사 배열 객체 또는 이터러블 객체를 인수로 전달받아 배열로 변환하여 반환한다
// ["a", "b", "c"]
Array.from( {length: 3, 0: 'a', 1: 'b', 2: 'c'} );
// ["J", "a", "v", "a"]
Array.from('Java');유사 배열 객체
배열처럼 인덱스로 프로퍼티 값에 접근할 수 있고 length 프로퍼티를 갖는 객체로 for문으로 순회 가능하다.
이터러블 객체
배열을 일반화한 객체로 for...of문으로 순회 가능하고 스프레드 문법과 배열 디스트럭처링 할당의 대상으로 사용할 수 있는 객체를 말한다.
arguments(유사배열 객체이면서 이터러블 객체)와 같은 유사 배열 객체를 배열로 변환하는 방법
- Array.from(arguments) // Array.from 사용
- [ ...arguments ] // 스프레드 연산자 사용
배열 요소의 추가와 갱신
존재하지 않는 인덱스를 사용해 값을 할당하면 새로운 요소가 추가된다. 이때 length 프로퍼티 값은 자동 갱신된다.
length 값보다 큰 인덱스로 새로운 요소 추가 시 희소배열이 된다.
정수 이외의 값을 인덱스 처럼 사용하면 프로퍼티가 생성되고 이는 length 값에 영향을 주지 않는다.
1. Array.prototype.push
배열의 마지막 요소에 인수로 전달받은 모든 값을 추가하고 변경된 length 값을 반환한다.
const fruits = ['사과', '바나나']
const newLength = fruits.push('오렌지');
// ["사과", "바나나", "오렌지"]추가해야할 요소가 1개라면 arr[arr.length] = 인수;
이렇게 직접 추가하는 것이 더 성능적인 면에선 좋다.
const fruits = ['사과', '바나나'];
const newFruits = [...fruits, '오렌지'];
// ["사과", "바나나", "오렌지"]2. Array.prototype.unshift
원본 배열의 선두에 요소로 인수를 추가하고 push처럼 변경된 length 값을 반환한다.
let newLength = fruits.push('오렌지')
// ["사과", "바나나", "오렌지"]push ,unshift는 부수효과가 있어 스프레드 문법 사용을 권장한다.
3. Array.prototype.concat
배열과 배열/값 매개변수를 이어붙인 새로운 배열을 반환한다.
const fruits = ['사과', '바나나']
const fruits2 = ['수박', '오렌지']
const newfruits = fruits.concat(fruits2);
//["사과", "바나나", "수박", "오렌지"]
console.log(newfruits) push, unshift와 concat의 차이점
인수로 전달받은 것이 배열인 경우 push와 unshift는 그대로 요소를 추가하지만 concat 메서드는 배열을 해체하여 새로운 배열의 마지막 요소로 추가한다.
배열 요소의 삭제
배열은 사실 객체여서 delete 연산자를 사용할 수 있다.
const fruits = ["사과", "바나나", "오렌지"];
delete fruits[1];
console.log(fruits); // ["사과", , "오렌지"]
console.log(fruits.length); // 3그러나 이렇게 삭제하면 희소 배열이 되기 때문에 length 프로퍼티 값은 변하지 않아서 사용하지 않는 것이 좋다.
그 외의 다른 매서드를 알아보자
1. Array.prototype.shift
원본 배열에서 첫 번째 요소를 제거한다.
빈 배열이면 undefined 반환한다.
const fruits = ["사과", "바나나", "오렌지"];
let first = fruits.shift() // ["바나나", "오렌지"]2. Array.prototype.pop
원본 배열에서 마지막 요소를 제거한다.
const fruits = ["사과", "바나나", "오렌지"];
let first = fruits.pop() // ["사과","바나나"]3. Array.prototype.splice
splice(start, n, items);
// start 인덱스부터 n 항목을 제거함
// items: 제거한 위치에 삽입할 요소들의 목록원본배열을 직접 변경한다.
let vegetables = ['양배추', '순무', '무', '당근']
let removedItems = vegetables.splice(1, 2)
console.log(removedItems)
// ["순무", "무"]
console.log(vegetables)
// ["양배추", "당근"] (원 배열 vegetables의 값이 변함)
4. Array.prototype.slice
배열의 일부를 추출한 새 배열을 반환한다.
slice(start, end);
//start : 복사를 시작하는 인덱스이며 음수인 경우 배열의 끝에서의 인덱스를 나타냄
//end : 복사를 종료할 인덱스이며 생략 시 기본값은 length 프로퍼티 값이다.원본배열은 변경하지 않는다.
모든 인수 생략시 원본 배열의 복사본을 생성해서 반환하고 이는 얕은 복사이다.
나머지 배열 메서드
1. Array.isArray
전달된 인수가 배열이면 true, 아니면 false 반환
2. Array.prototype.indexOf
원본 배열에서 인수로 전달된 요소를 검색하여 인덱스를 반환한다.
const fruits = ["사과", "바나나", "오렌지"];
let pos = fruits.indexOf("바나나") // 1두 번째 인수는 검색을 시작할 인덱스를 말한다.
중복되는 요소가 여러개 있다면 처음 요소의 인덱스를 반환하며
요소가 존재하지 않으면 -1을 반환한다.
const fruits = ["사과", "바나나", "오렌지", "바나나"];
console.log(fruits.indexOf('바나나', 2)); // 3
console.log(fruits.indexOf("딸기")) // -1
3. Array.prototype.includes
특정 요소가 있는지 확인하여 true 또는 false를 반환한다.
두 번째 인수는 검색을 시작할 인덱스를 말한다.
[1, 2, 3].includes(3, 3); // false
[1, 2, NaN].includes(NaN); // true
indexOf와 차이점은 includes는 NaN이 포함되어있는지 확인이 가능하다.
4. Array.prototype.join
원본 배열의 모든 요소를 문자열로 변환한 후, 인수로 전달받은 문자열로 연결한 문자열을 반환한다. (인수 생략 시 기본 구분자는 콤마(,)다.)
let board = ['R','N','B','Q','K','B']
console.log(board.join('')); // RNBQKB
console.log(board.join()); // R,N,B,Q,K,B'
5. Array.prototype.reverse
원본 배열의 순서를 반대로 뒤집어 반환한다.
즉, 첫 번째 요소가 마지막이 되고 마지막 요소가 첫 번째가 된다.
let board = ['A','B','C','D'];
// ['D','C','B','A']
console.log(board.reverse());6. Array.prototype.some
배열의 어떤 요소가 주어진 판별 함수를 만족할 경우 true를 반환한다.
반환값이 단 한번이라도 참이면 true를 반환한다.
let board = ['A','B','C','D']
console.log(board.some( c => c=='F' )); //false
console.log(board.some( c => c=='A' )); //true화살표 함수를 사용한 배열의 요소 테스트
[2, 5, 8, 1, 4].some((x) => x > 10); // false [12, 5, 8, 1, 4].some((x) => x > 10); // true
7. Array.prototype.sort
배열의 요소를 정렬하고 그 배열을 반환한다.
복사본이 만들어지는 것이 아니라 원본 배열이 정렬된다.
매개변수 compareFunction
정렬 순서를 정의하는 함수로 생략하면 각 문자의 유니 코드 코드 포인트 값에 따라 정렬된다. 예를 들어 "바나나"는 "체리"앞에 온다. 숫자 정렬에서는 30이 10000보다 앞에 오지만 숫자는 문자열로 변환되기 때문에 "10000"은 유니 코드 순서에서 "30"앞에 오는 것이다.
const months = ['D','B','C','A'];
console.log(months.sort());
// Array ["A", "B", "C", "D"]
const array1 = [1, 30, 9, 21, 10000];
console.log(array1.sort());
// Array [1, 100000, 21, 30, 9]compareFunction이 제공되면 배열 요소는 compare 함수의 반환 값에 따라 정렬된다.
a와 b가 비교되는 두 요소라면,
- compareFunction(a, b)이 0보다 작은 경우 a를 b보다 낮은 색인으로 정렬한다. 즉, a가 먼저온다.
- compareFunction(a, b)이 0을 반환하면 a와 b를 서로에 대해 변경하지 않고 모든 다른 요소에 대해 정렬한다.
- compareFunction(a, b)이 0보다 큰 경우, b를 a보다 낮은 인덱스로 정렬한다. 즉, b가 먼저온다.
따라서 sort메소드는 함수식과 함께 사용할 수 있다.
var numbers = [4, 2, 5, 1, 3];
numbers.sort(function(a, b) {
return a - b;
});
console.log(numbers);
// [1, 2, 3, 4, 5]또한 객체의 속성 중 하나의 값을 기준으로 정렬 할 수도 있다.
var items = [
{ name: 'Edward', value: 21 },
{ name: 'Sharpe', value: 37 },
{ name: 'And', value: 45 },
{ name: 'The', value: -12 }
];
// value 기준으로 정렬
items.sort(function (a, b) {
if (a.value > b.value) { return 1 }
if (a.value < b.value) { return -1 }
return 0;
});
// name 기준으로 정렬
items.sort(function(a, b) {
var nameA = a.name.toUpperCase();
var nameB = b.name.toUpperCase();
if (nameA < nameB) { return -1 }
if (nameA > nameB) { return 1 }
// 이름이 같을 경우
return 0;
});8. Array.prototype.fill
인수로 전달받은 값을 배열의 처음부터 끝까지 요소로 채운다.
첫 번째 요소는 배열을 채울 값, 두 번째 요소는 시작할 인덱스, 세 번째 요소는 종료할 인덱스
const array1 = [1, 2, 3, 4];
// 0으로 2번 인덱스부터 4번까지 채운다.
console.log(array1.fill(0, 2, 4));
// Array [1, 2, 0, 0]
// 1번 인덱스부터 5로 채운다.
console.log(array1.fill(5, 1));
// Array [1, 5, 5, 5]
// 6으로 채운다.
console.log(array1.fill(6));
// Array [6, 6, 6, 6]9. Array.prototype.forEach
배열의 모든 요소를 순회하며 콜백함수를 반복 호출한다.
['A', 'B', 'C'].forEach((item, index, arr) => {
console.log(item , index);
});
// 'A' , 0
// 'B' , 1
// 'C' , 2요소값, 인덱스, this의 인수를 전달하며 여기서 this는 호출한 배열을 의미한다.
forEach((item.index,arr) => {arr[index] = item * 2; });
와 같은 방법으로 원본배열을 변경할 수 있다.
forEach 메서드는 break, continue 문을 사용할 수 없고, 희소 배열의 경우 존재하지 않는 요소는 순회대상에서 제외된다.
for문 보다 성능이 좋지는 않지만 가독성이 좋기 때문에 높은 성능이 필요한 경우가 아니라면 forEach를 사용하는 것이 좋다.
10. Array.prototype.map
콜백 함수의 반환값들로 구성된 새로운 배열을 반환한다.
원본 배열은 변경되지 않는다.
map 메서드가 생성하여 반환하는 새로운 배열의 length 프로퍼티 값은 map 메서드를 호출한 배열의 length 프로퍼티 값과 반드시 일치한다. 즉 map 메서드를 호출한 배열과 map 메서드가 생성하여 반환한 배열은 1:1 매핑한다.
두 번째 인수로 콜백함수 내부에서 this로 사용할 객체를 전달 가능하다.
11. Array.prototype.filter
콜백 함수의 반환 값이 true인 요소로만 구성된 새로운 배열 반환이다.
const words = ['spray', 'elite', 'exuberant', 'destruction'];
const result = words.filter(word => word.length > 6);
console.log(result);
// Expected output: Array ["exuberant", "destruction"]다음과 같이 배열 내용을 조건에 따라 검색하기 위해 filter() 를 사용할 수도 있다.
var fruit = ['apple', 'banana', 'grapes', 'mango'];
function filterItems(query,Array) {
return Array.filter((element)=> {
return element.indexOf(query) > -1;
})
}
console.log(filterItems('ap',fruit)); // ['apple', 'grapes']
console.log(filterItems('an',fruit)); // ['banana', 'mango']12. Array.prototype.reduce
자신을 호출한 배열의 모든 요소를 순회하며 인수로 전달받은 콜백 함수를 반복호출한다.
그러면서 콜백 함수의 반환값을 다음 순회시에 콜백함수의 첫 번째 인자로 전달하면서 함수를 호출하여 하나의 결과 값을 만들어 반환한다.
리듀서 함수는 네 개의 인자를 가진다.
- 누산기 (accumulator)
- 현재 값 (currentValue)
- 현재 인덱스 (index)
- 원본 배열 (array)
const sum = [1,2,3,4].reduce((accumulator, currentValue, index, array) => accumulator + currentValue, 0);
console.log(sum); // 10reduce 메서드의 다양한 활용법
- 평균 구하기
- 최대값 구하기 --> Math.max가 더 직관적
- 요소의 중복 횟수 구하기
- 중첩 배열 평탄화 --> flat 메서드가 더 직관적
- 중복 요소 제거 ---> filter나 Set이 더 직관적이다.
reduce 메서드의 두 번째 인수로 전달하는 초기값은 옵션인데 언제나 초기값을 전달하는 것이 안전하다. (객체의 특정 프로퍼티 값을 합산하는 경우에는 반드시 초기값 전달해주어야 함)
13.Array.prototype.find
자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백 함수를 호출하여 반환 값이 true인 첫 번째 요소를 반환한다.
결과 값은 배열이 아닌 요소값 이다.
14. Array.prototype.findIndex
반환값이 true 인 첫번째 요소의 인덱스를 반환한다.
배열 고차 함수
고차함수는 함수를 인수로 전달받거나 함수를 반환하는 함수를 말한다. (외부 상태의 변경이나 가변 데이터를 피하고 불변성을 지향하는 함수형 프로그래밍에 기반을 둔다.)
함수형 프로그래밍
조건문과 반복문을 제거하여 복잡성을 해결하고 변수의 사용을 억제하여 상태변경을 피하며 순수 함수를 통해 부수효과를 최대한 억제한다.
