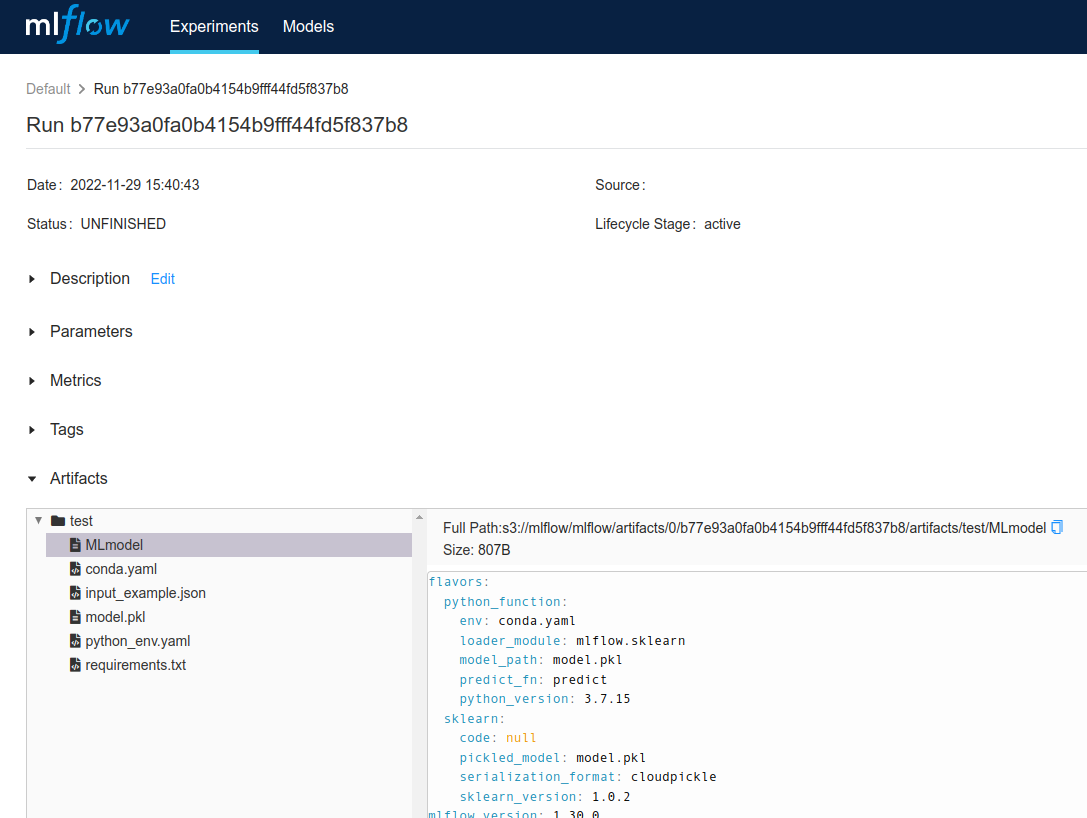
- API Deployment까지 나아가기 위해서는 MLFlow에 모델을 저장해야한다.
MLFlow in Local
- MLflow에서 모델 저장, Serving에서 사용하기 위해서는 아래 항목이 필요하다.
model,signature,input_example,conda_env
mlflow infos
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
input_example = data.sample(1)
signature = infer_signature(data, clf.predict(data))
conda_env = _mlflow_conda_env(additional_pip_deps=["dill", "pandas", "scikit-learn"])
- input_example
inputs:
['sepal length (cm)': double, 'sepal width (cm)': double, 'petal length (cm)': double, 'petal width (cm)': double]
outputs:
[Tensor('int64', (-1,))]- signature
{'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': ['python=3.8.10',
'pip',
{'pip': ['mlflow', 'dill', 'pandas', 'scikit-learn']}]}- conda_env
Save mlflow infos
from mlflow.sklearn import save_model
save_model(
sk_model=clf,
path="svc",
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)- sklearn 모델을 저장하는 코드다.
MLFlow Component
- Kubeflow에서 재사용할 수 있는 Component, 작성하는 방법은 크게 3가지가 있다.
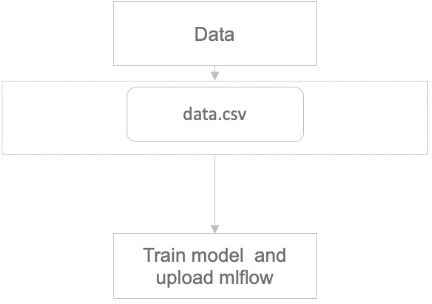
1. 모델을 학습하는 Component에서 필요한 환경 저장 후 MLFlow Component는 upload만 담당
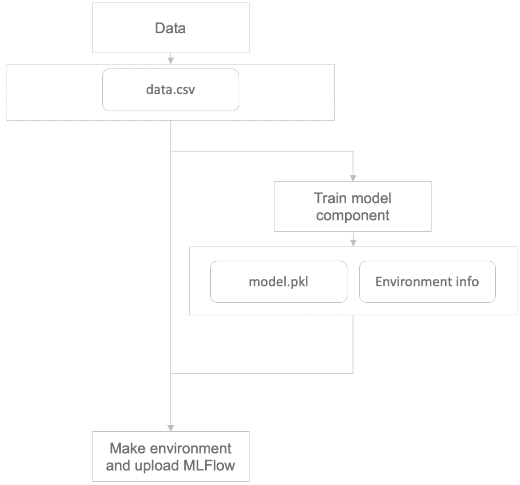
2. 학습 모델과 데이터를 MLflow Component에 전달 후 Component에서 저장과 업로드 담당
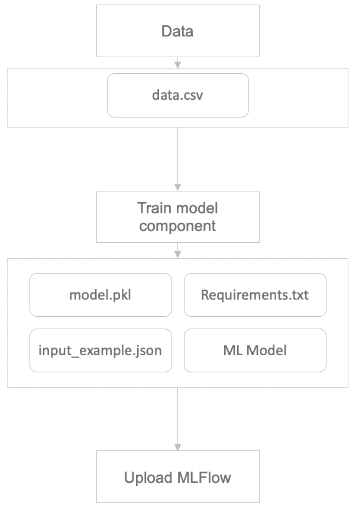
3. 모델 학습하는 컴포넌트에서 자장과 업로드 담당
- 모두의 MLOps 개발자 분들은 1번 방법을 선택했다.
- MLFlow 모델을 업로드하는 코드는 바뀌지 않아 3번 처럼 컴포넌트 작성마다 작성할 필요가 없기 때문이라고 한다.
- Component 재활용 방법은 1, 2번 방법으로 가능하다. 다만, 2번의 경우 모델이 학습된 이미지와 패키지들을 전달해야하므로 결국 컴포넌트에 대한 추가 정보를 전달해야한다.
from functools import partial
from kfp.components import InputPath, OutputPath, create_component_from_func
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow"],
)
def train_from_csv(
train_data_path: InputPath("csv"),
train_target_path: InputPath("csv"),
model_path: OutputPath("dill"),
input_example_path: OutputPath("dill"),
signature_path: OutputPath("dill"),
conda_env_path: OutputPath("dill"),
kernel: str,
):
import dill
import pandas as pd
from sklearn.svm import SVC
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
input_example = train_data.sample(1)
with open(input_example_path, "wb") as file_writer:
dill.dump(input_example, file_writer)
signature = infer_signature(train_data, clf.predict(train_data))
with open(signature_path, "wb") as file_writer:
dill.dump(signature, file_writer)
conda_env = _mlflow_conda_env(
additional_pip_deps=["dill", "pandas", "scikit-learn"]
)
with open(conda_env_path, "wb") as file_writer:
dill.dump(conda_env, file_writer)- 우선, 모델을 저장하는데 필요한 환경들을 저장해주는 코드가 추가되어야 한다.
from functools import partial
from kfp.components import InputPath, create_component_from_func
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow", "boto3"],
)
def upload_sklearn_model_to_mlflow(
model_name: str,
model_path: InputPath("dill"),
input_example_path: InputPath("dill"),
signature_path: InputPath("dill"),
conda_env_path: InputPath("dill"),
):
import os
import dill
from mlflow.sklearn import save_model
from mlflow.tracking.client import MlflowClient
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://minio-service.kubeflow.svc:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio123"
client = MlflowClient("http://mlflow-server-service.mlflow-system.svc:5000")
with open(model_path, mode="rb") as file_reader:
clf = dill.load(file_reader)
with open(input_example_path, "rb") as file_reader:
input_example = dill.load(file_reader)
with open(signature_path, "rb") as file_reader:
signature = dill.load(file_reader)
with open(conda_env_path, "rb") as file_reader:
conda_env = dill.load(file_reader)
save_model(
sk_model=clf,
path=model_name,
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)
run = client.create_run(experiment_id="0")
client.log_artifact(run.info.run_id, model_name)- MLFlow 업로드하는 컴포넌트
- S3 Endpoint 주소는 MLflow Server 설치 당시 설치한 minio의 쿠버네티스 서비스 DNS 네임 활용
http://minio-service.kubeflow.svc:9000
- tracking uri 주소는 mlflow server의 쿠버네티스 서비스 DNS 네임을 활용
http://mlflow-server-service.mlflow-system.svc:5000
MLFlow Pipeline
- 작성한 컴포넌트들을 연결한 파이프라인
Data Component
from functools import partial
from kfp.components import InputPath, OutputPath, create_component_from_func
@partial(
create_component_from_func,
packages_to_install=["pandas", "scikit-learn"],
)
def load_iris_data(
data_path: OutputPath("csv"),
target_path: OutputPath("csv"),
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)- model 학습 시 사용할 데이터를 생성하는 컴포넌트
Pipeline
from kfp.dsl import pipeline
@pipeline(name="mlflow_pipeline")
def mlflow_pipeline(kernel: str, model_name: str):
iris_data = load_iris_data()
model = train_from_csv(
train_data=iris_data.outputs["data"],
train_target=iris_data.outputs["target"],
kernel=kernel,
)
_ = upload_sklearn_model_to_mlflow(
model_name=model_name,
model=model.outputs["model"],
input_example=model.outputs["input_example"],
signature=model.outputs["signature"],
conda_env=model.outputs["conda_env"],
)- pipeline code
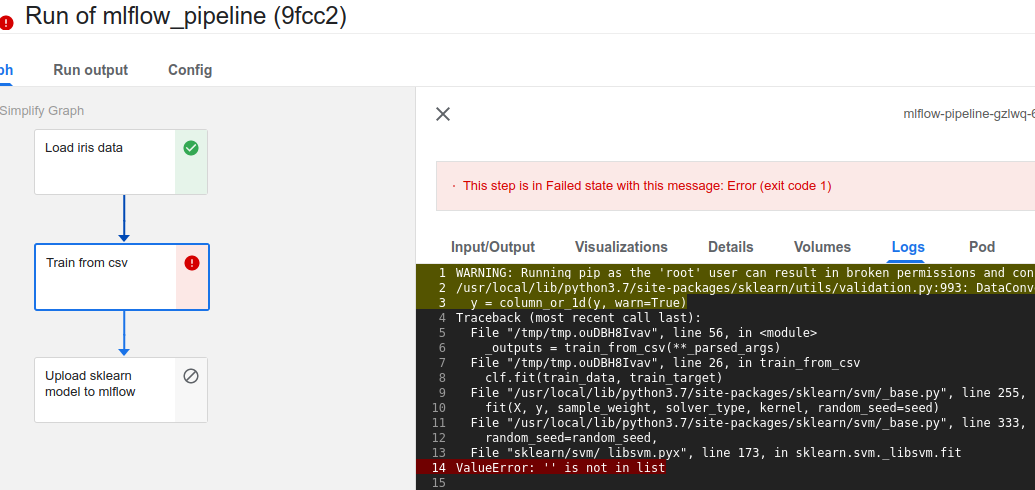
Run
- 컴포넌트, 파이프라인을 하나의 파이썬 파일에 정리
from functools import partial
import kfp
from kfp.components import InputPath, OutputPath, create_component_from_func
from kfp.dsl import pipeline
@partial(
create_component_from_func,
packages_to_install=["pandas", "scikit-learn"],
)
def load_iris_data(
data_path: OutputPath("csv"),
target_path: OutputPath("csv"),
):
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris["data"], columns=iris["feature_names"])
target = pd.DataFrame(iris["target"], columns=["target"])
data.to_csv(data_path, index=False)
target.to_csv(target_path, index=False)
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow"],
)
def train_from_csv(
train_data_path: InputPath("csv"),
train_target_path: InputPath("csv"),
model_path: OutputPath("dill"),
input_example_path: OutputPath("dill"),
signature_path: OutputPath("dill"),
conda_env_path: OutputPath("dill"),
kernel: str,
):
import dill
import pandas as pd
from sklearn.svm import SVC
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
train_data = pd.read_csv(train_data_path)
train_target = pd.read_csv(train_target_path)
clf = SVC(kernel=kernel)
clf.fit(train_data, train_target)
with open(model_path, mode="wb") as file_writer:
dill.dump(clf, file_writer)
input_example = train_data.sample(1)
with open(input_example_path, "wb") as file_writer:
dill.dump(input_example, file_writer)
signature = infer_signature(train_data, clf.predict(train_data))
with open(signature_path, "wb") as file_writer:
dill.dump(signature, file_writer)
conda_env = _mlflow_conda_env(
additional_pip_deps=["dill", "pandas", "scikit-learn"]
)
with open(conda_env_path, "wb") as file_writer:
dill.dump(conda_env, file_writer)
@partial(
create_component_from_func,
packages_to_install=["dill", "pandas", "scikit-learn", "mlflow", "boto3"],
)
def upload_sklearn_model_to_mlflow(
model_name: str,
model_path: InputPath("dill"),
input_example_path: InputPath("dill"),
signature_path: InputPath("dill"),
conda_env_path: InputPath("dill"),
):
import os
import dill
from mlflow.sklearn import save_model
from mlflow.tracking.client import MlflowClient
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://minio-service.kubeflow.svc:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minio123"
client = MlflowClient("http://mlflow-server-service.mlflow-system.svc:5000")
with open(model_path, mode="rb") as file_reader:
clf = dill.load(file_reader)
with open(input_example_path, "rb") as file_reader:
input_example = dill.load(file_reader)
with open(signature_path, "rb") as file_reader:
signature = dill.load(file_reader)
with open(conda_env_path, "rb") as file_reader:
conda_env = dill.load(file_reader)
save_model(
sk_model=clf,
path=model_name,
serialization_format="cloudpickle",
conda_env=conda_env,
signature=signature,
input_example=input_example,
)
run = client.create_run(experiment_id="0")
client.log_artifact(run.info.run_id, model_name)
@pipeline(name="mlflow_pipeline")
def mlflow_pipeline(kernel: str, model_name: str):
iris_data = load_iris_data()
model = train_from_csv(
train_data=iris_data.outputs["data"],
train_target=iris_data.outputs["target"],
kernel=kernel,
)
_ = upload_sklearn_model_to_mlflow(
model_name=model_name,
model=model.outputs["model"],
input_example=model.outputs["input_example"],
signature=model.outputs["signature"],
conda_env=model.outputs["conda_env"],
)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(mlflow_pipeline, "mlflow_pipeline.yaml")kubectl port-forward svc/mlflow-server-service -n mlflow-system 5000:5000- mlflow가 먼저 포트포워딩 되어있어야한다.
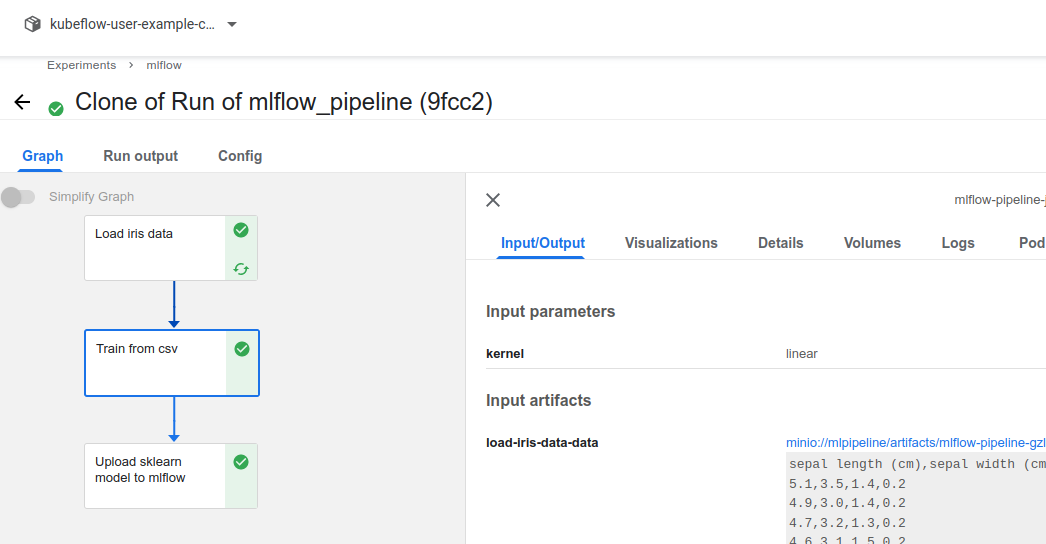
Debugging

OnePunchLotto