Pipeline
- 컴포넌트는 독립적으로 실행되지 않고, Pipeline의 구성 요소로써 실행된다.
- 즉, 컴포넌트 실행을 위해서는 Pipeline을 작성해야 한다.
- Pipeline 작성을 위해서는 컴포넌트의 집합 & 실행 순서가 필요하다.
- 숫자를 입력하고, 출력하는 컴포넌트와 두 개의 컴포넌트로부터 숫자를 받아 합을 출력하는 컴포넌트가 있는 파이프라인을 예시로 진행한다.
Write
Component Set
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return numberprint_and_return_number컴포넌트- 입력받은 숫자를 출력하고 반환하는 컴포넌트
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int) -> int:
sum_num = number_1 + number_2
print(sum_num)
return sum_numsum_and_print_numbers- 두 숫자의 합을 반환하는 컴포넌트
Component Order
Define Order
- 컴포넌트 셋을 만들었으면 이들의 순서를 정해야한다.
Single Output
def example_pipeline():
number_1_result = print_and_return_number(number_1)
number_2_result = print_and_return_number(number_2)- 컴포넌트 실행 시
number_*_result에 반환 값이 저장된다.- 저장된 값은
number_*_result.output을 통해 사용할 수 있다.
- 저장된 값은
Multi Output
def multi_pipeline():
divided_result = divde_and_return_number(number)
num_1_result = print_and_return_number(divided_result.outputs["quotient"])
num_2_result = print_and_return_number(divided_result.outputs["remainder"])divde_and_return_number의 return 값은 quotient, remainder가 있다고 해보자.- 여러 반환 값인 경우 outputs에 저장되며 dict type이다.
Write to python code
def example_pipeline(number_1: int, number_2:int):
number_1_result = print_and_return_number(number_1)
number_2_result = print_and_return_number(number_2)
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
)- 두 수를 받아서 합치는 컴포넌트를 추가하면 위 처럼 Pipeline을 만들어 볼 수 있다.
- 각 컴포넌트에 필요한 config를 모아 Pipeline config로 정의 한다.
Convert to Kubeflow Format
from kfp.dsl import pipeline
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1)
number_2_result = print_and_return_number(number_2)
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
)kfp.dsl.pipeline함수를 이용해 kubeflow에서 사용할 형식으로 변환한다.
if __name__ == "__main__":
import kfp
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")- kubeflow에서 파이프라인을 실행하기 위해서는 yaml 형식으로만 가능하므로 생성한 파이프라인을 정해진 yaml 형식으로 Compile 해줘야 한다.
- Compile은 위 명령어를 통해 생성할 수 있다.
Conclusion
import kfp
from kfp.components import create_component_from_func
from kfp.dsl import pipeline
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return number
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int):
print(number_1 + number_2)
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1)
number_2_result = print_and_return_number(number_2)
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")- 컴파일 시 결과는 아래와 같다.
Upload
- kubeflow에 자신이 만든 pipeline을 업로드하는 과정이다.
- 파이프라인 업로드는 kubeflow 대시보드 UI를 통해 진행할 수 있다.
kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80- 대시보드 배포 후
http://localhost:8080에 접속
PipelinesTab 클릭

- 우측상단 upload pipeline 클릭 후 Pipeline 이름 설정 후 yaml 파일 업로드
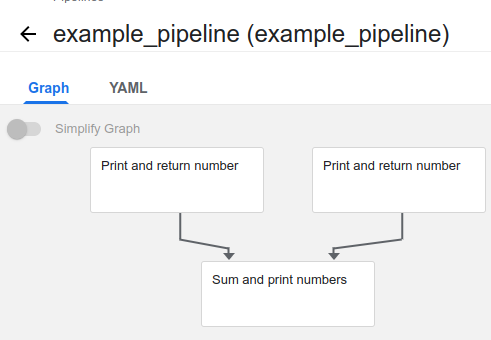
- pipeline이 create 되는 것을 확인할 수 있다.
Upload Pipeline Version
- Pipeline은 Upload를 통해 Version 관리가 이뤄진다.
- Code 차원에서의 버전 관리가 아니라 같은 이름에 대한 파이프라인을 모아서 보여주는 역할을 한다.

- 버전업을 하고자하는 파이프라인을 누르고, Upload version을 클릭하면 된다.
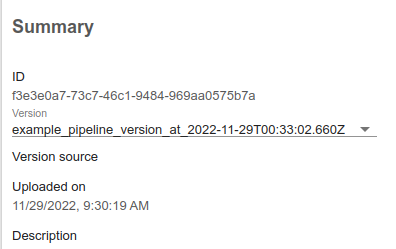
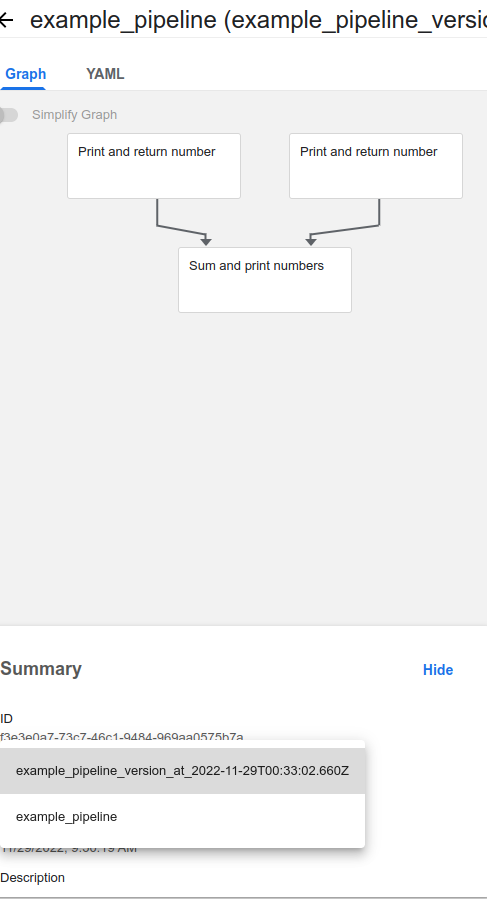
- 왼쪽 하단 Summary에서 버전별로 확인이 가능하다.
Run
- 업로드한 파이프라인을 실행시켜보는 단계이다.
Create Experiment

- Experiment : Kubeflow에서 실행되는 Run을 논리적으로 관리하는 단위이다.
- 파이프라인 실행 전에 미리 Experiment를 만들어 두어야 한다.
- 만약, experiment가 있으면 위 과정은 필요없다.
- 파이프라인에서
Create experiment버튼을 눌러 Experiment를 생성한다.
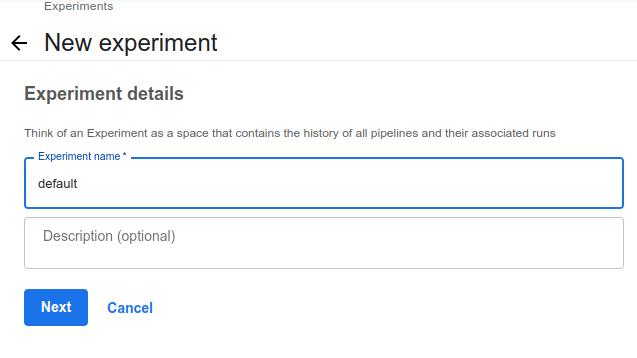
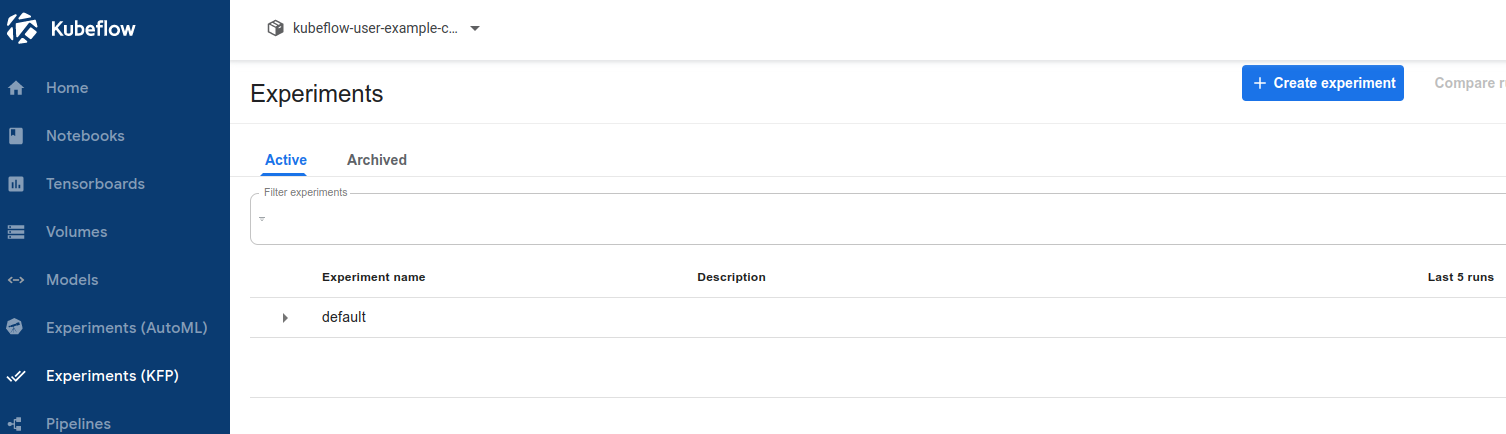
- 생성 완료
Run Pipeline
Create run버튼 클릭
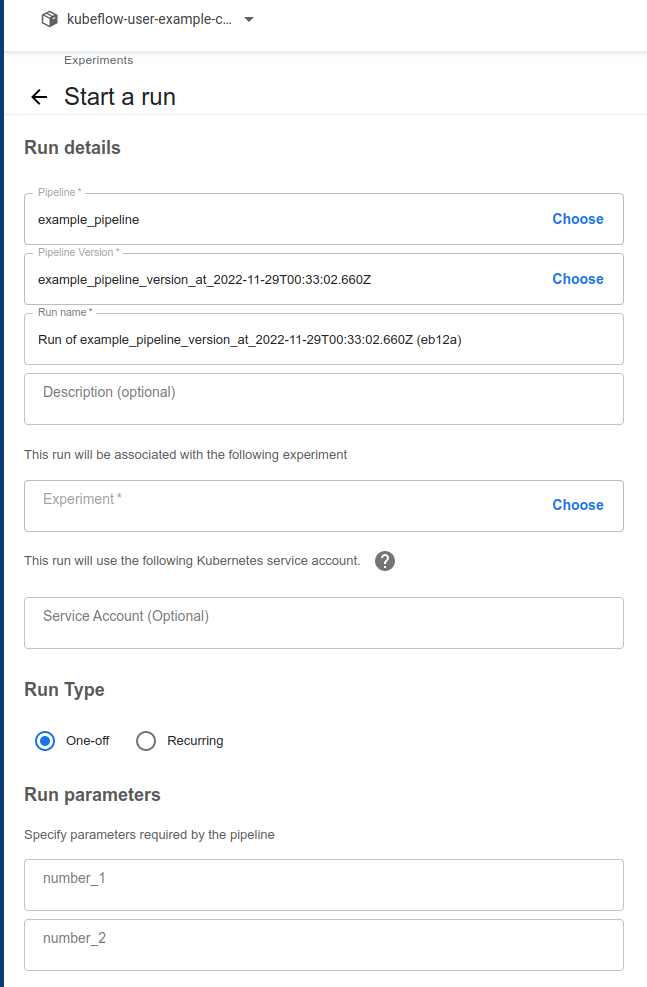
- 가운데 Experiment의
Choose클릭
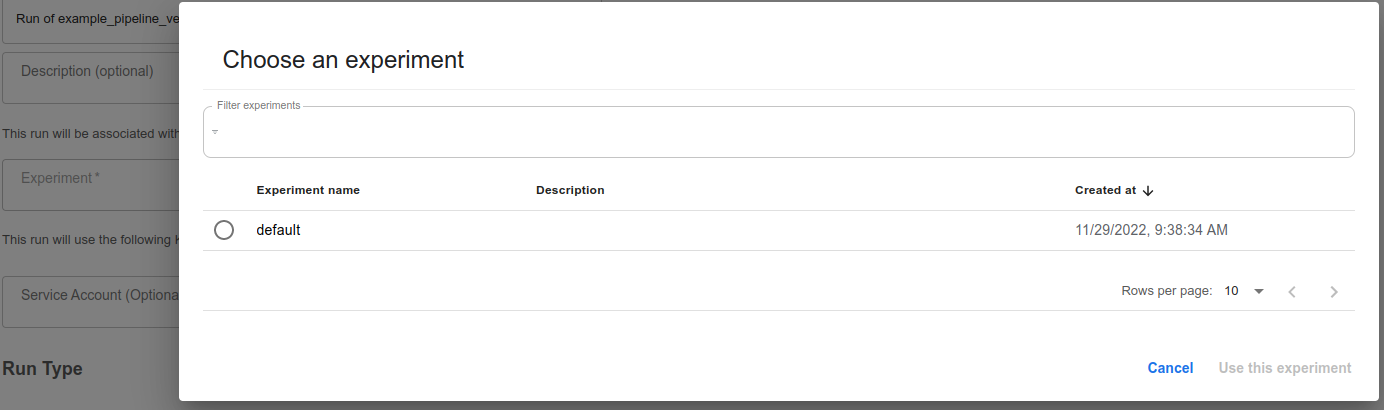
- experiment name 선택
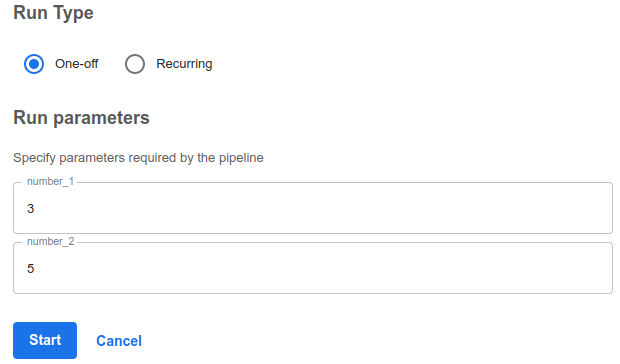
- 하단의 Pipeline Config 입력 후 Start
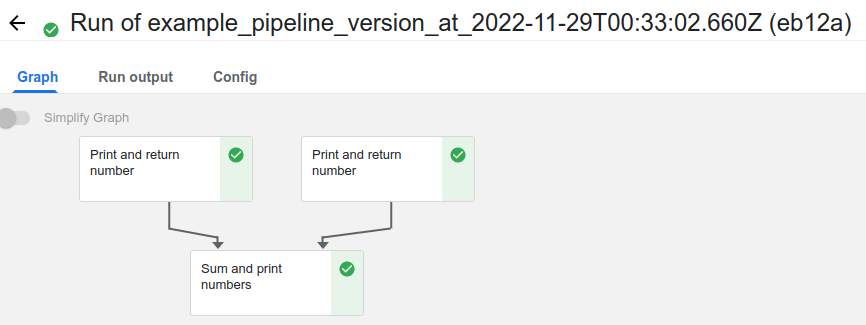
- Runs를 확인해보면, 위와 같은 화면이 나오는데 아직 실행되지 않은 컴포넌트는 위처럼 회색 표시로 나온다.
- 실행 완료 시 초록 체크 표시가 나온다.
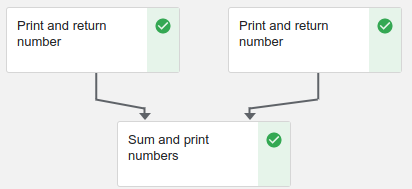
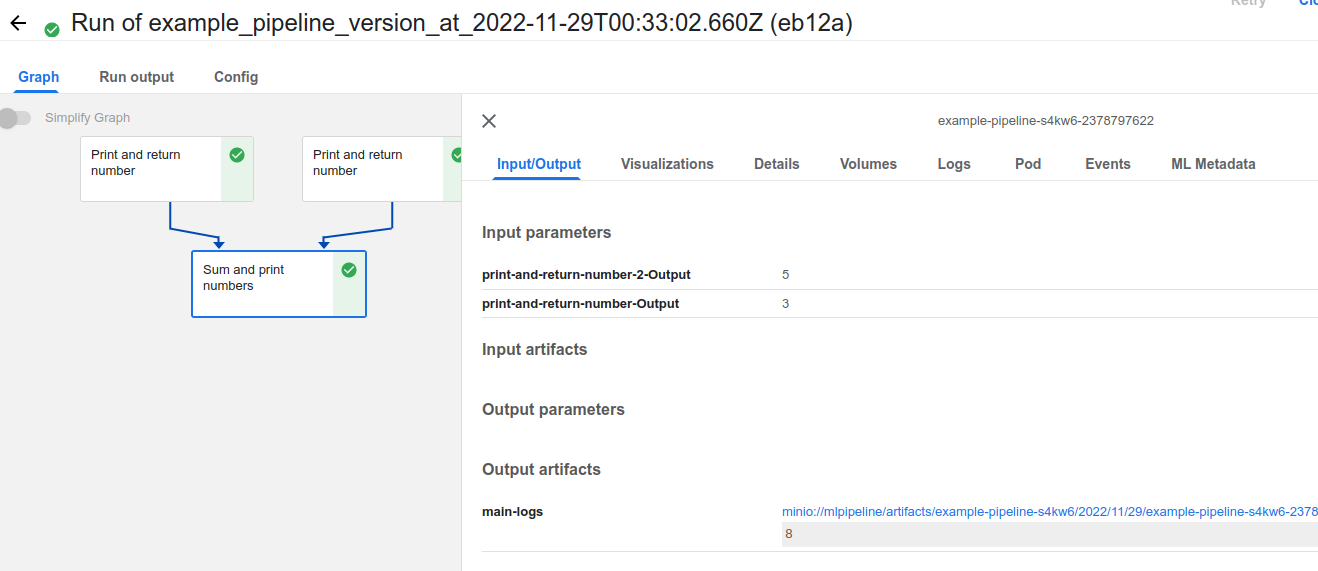
Sum and print numbersComponent를 눌러보면 입력한 Config와 결과를 볼 수 있다.
Setting
- Pipeline에서 설정할 수 있는 값들
Display Name
- 파이프라인 내에서 컴포넌트는 두 개의 이름을 갖는다.
- task_name : Component 작성 시 작성한 함수 이름
- display_name : kubeflow UI상 보이는 이름
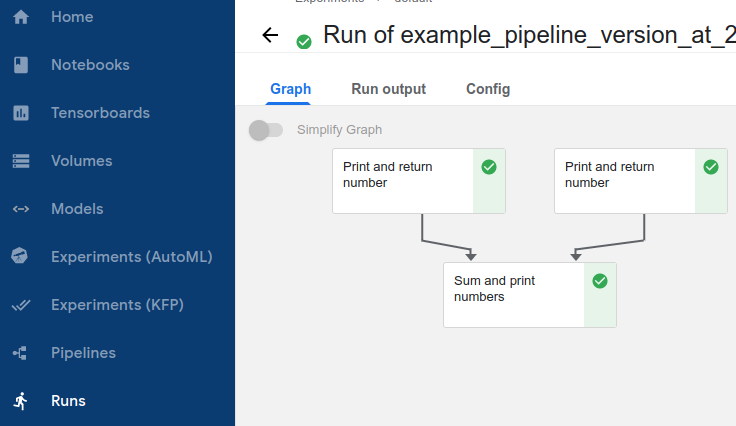
Print and return number컴포넌트를 보면 두 컴포넌트 모두 이름이 같으므로 뭐가 1번이고, 2번인지 확인하기 어렵다. 이 때 display_name을 이용하면 된다.
set_display_name
import kfp
from kfp.components import create_component_from_func
from kfp.dsl import pipeline
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return number
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int):
print(number_1 + number_2)
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1).set_display_name("This is number 1")
number_2_result = print_and_return_number(number_2).set_display_name("This is number 2")
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
).set_display_name("This is sum of number 1 and number 2")
if __name__ == "__main__":
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")- Component에서
set_display_nameattribute를 이용하면 된다.- 생성된 pipeline yaml을 보면, 새로운 key가 생성되었음을 확인할 수 있다.
Resources
GPU
- 특별한 설정이 없으면 Pipeline은 Component를 쿠버네티스 Pod으로 실행할 때, 기본 Resource spec으로 실행하게 된다.
- GPU를 사용한 학습 시, 쿠버네티스 상에서 GPU 할당을 받지 못해 제대로 학습이 이뤄지지 않는다.
import kfp
from kfp.components import create_component_from_func
from kfp.dsl import pipeline
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return number
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int):
print(number_1 + number_2)
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1).set_display_name("This is number 1")
number_2_result = print_and_return_number(number_2).set_display_name("This is number 2")
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
).set_display_name("This is sum of number 1 and number 2").set_gpu_limit(1)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")set_gpu_limit()attribute를 이용하자.- 위 스크립트 실행 후 yaml 파일을 보면 resources에
{nvidia.com/gpu: 1}가 추가된 것을 확인할 수 있다. GPU가 할당된 것이다.
CPU
import kfp
from kfp.components import create_component_from_func
from kfp.dsl import pipeline
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return number
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int):
print(number_1 + number_2)
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1).set_display_name("This is number 1")
number_2_result = print_and_return_number(number_2).set_display_name("This is number 2")
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
).set_display_name("This is sum of number 1 and number 2").set_gpu_limit(1).set_cpu_limit("16")
if __name__ == "__main__":
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")set_cpu_limit()attribute를 통해 cpu 개수도 설정할 수 있다.- gpu와 다르게 int가 아니라 string으로 입력해야한다.
resources:
limits: {nvidia.com/gpu: 1, cpu: '16'}- 스크립트 실행 시 resource가 부여될 것이다.
Memory
import kfp
from kfp.components import create_component_from_func
from kfp.dsl import pipeline
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return number
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int):
print(number_1 + number_2)
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1).set_display_name("This is number 1")
number_2_result = print_and_return_number(number_2).set_display_name("This is number 2")
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
).set_display_name("This is sum of number 1 and number 2").set_gpu_limit(1).set_memory_limit("1G")
if __name__ == "__main__":
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")set_memory_limit()attribute를 이용해 설정할 수 있다. cpu와 마찬가지로 string이다.
resources:
limits: {nvidia.com/gpu: 1, memory: 1G}Run Result
- Run 실행 결과를 보면 3개의 Tab(Graph, Run output, Config)가 존재한다.
Graph
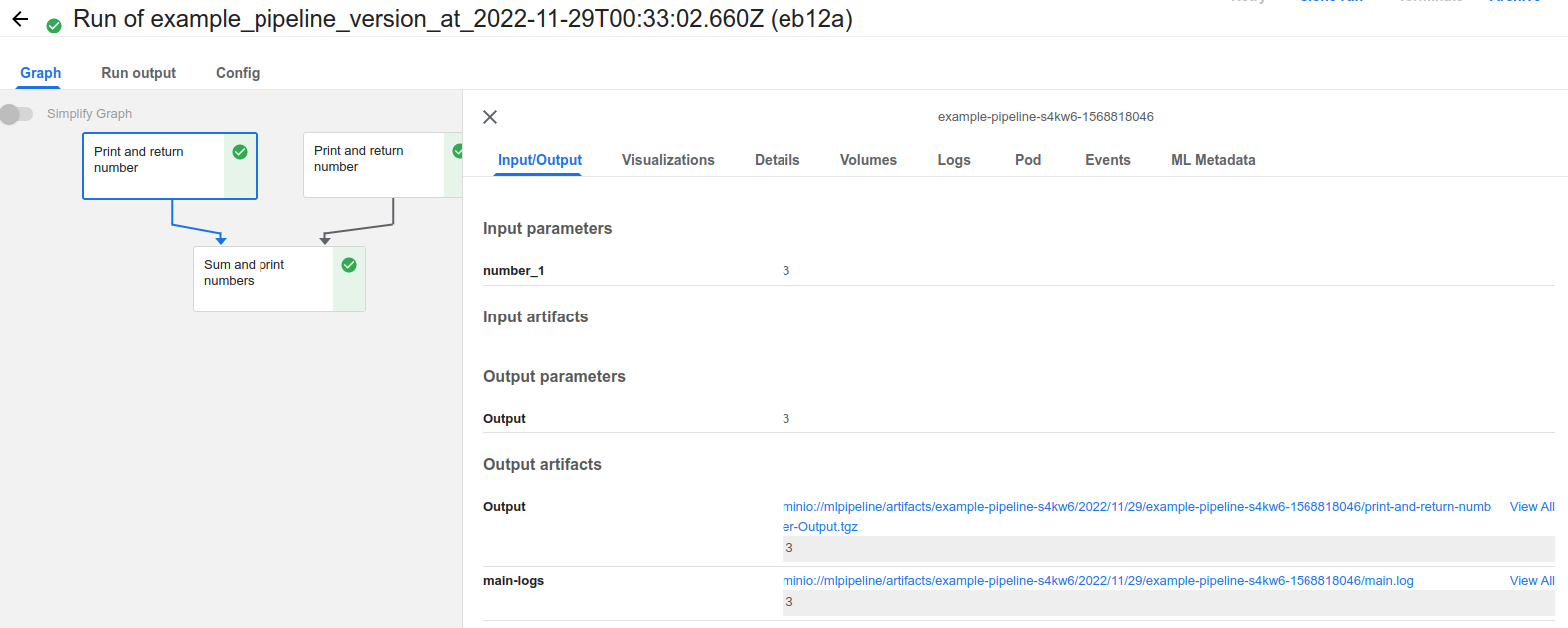
- 그래프에서는 실행된 Component를 누르면 실행 정보를 확인할 수 있다.
Input/Output
- Component에서 사용한 config들과 Output Artifacts를 확인하고 다운로드 받을 수 있다.
Logs
- Python code 실행 중 나오는 모든 stdout을 확인할 수 있다.
- pod은 일정 시간 지난 후 지워지므로 일정 시간 지나면 이 Tab에서는 확인할 수 없으며 Output artifacts의 main-logs에서 확인할 수 있다.
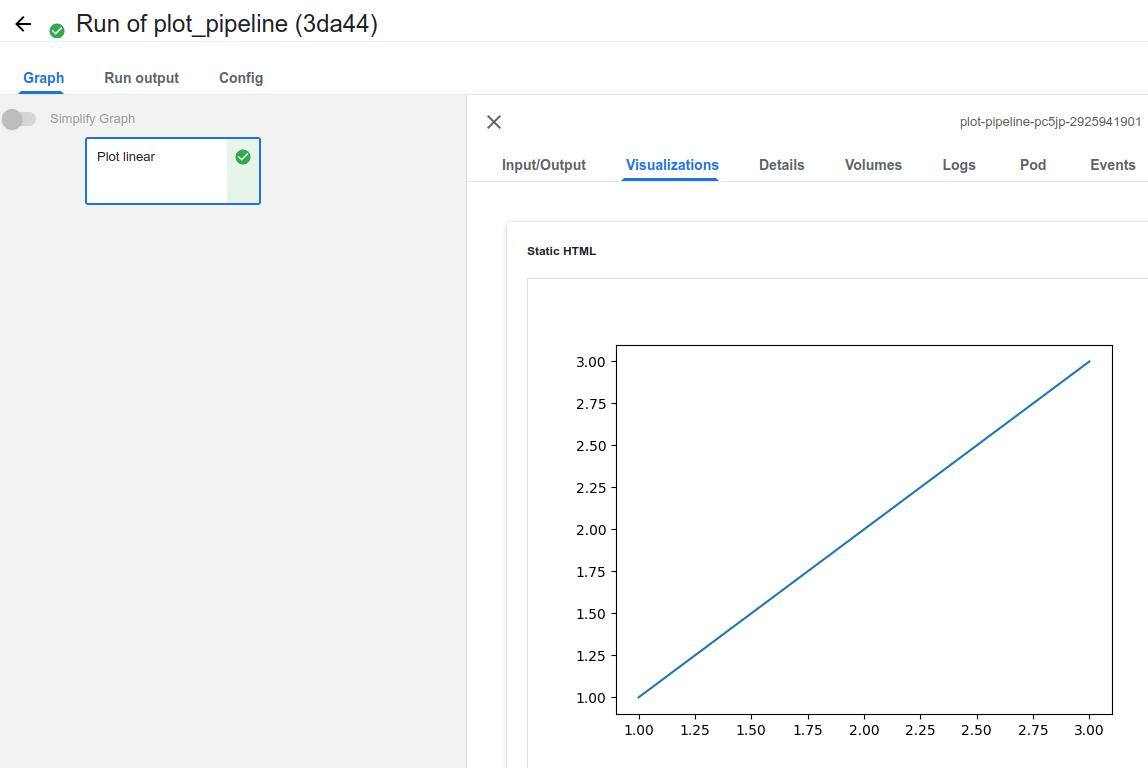
Visualizations
- Component에서 생성된 Plot을 보여준다.
@partial(
create_component_from_func,
packages_to_install=["matplotlib"],
)
def plot_linear(
mlpipeline_ui_metadata: OutputPath("UI_Metadata")
):
import base64
import json
from io import BytesIO
import matplotlib.pyplot as plt
plt.plot(x=[1, 2, 3], y=[1, 2,3])
tmpfile = BytesIO()
plt.savefig(tmpfile, format="png")
encoded = base64.b64encode(tmpfile.getvalue()).decode("utf-8")
html = f"<img src='data:image/png;base64,{encoded}'>"
metadata = {
"outputs": [
{
"type": "web-app",
"storage": "inline",
"source": html,
},
],
}
with open(mlpipeline_ui_metadata, "w") as html_writer:
json.dump(metadata, html_writer)- plot 생성을 위해서는
mlpipeline_ui_metadata: OutputPath("UIMetadata")argument로 보여주고 싶은 값을 저장하면 된다.- 저장되는 Plot은 HTML Format이어야 한다.
from functools import partial
import kfp
from kfp.components import create_component_from_func, OutputPath
from kfp.dsl import pipeline
@partial(
create_component_from_func,
packages_to_install=["matplotlib"],
)
def plot_linear(mlpipeline_ui_metadata: OutputPath("UI_Metadata")):
import base64
import json
from io import BytesIO
import matplotlib.pyplot as plt
plt.plot([1, 2, 3], [1, 2, 3])
tmpfile = BytesIO()
plt.savefig(tmpfile, format="png")
encoded = base64.b64encode(tmpfile.getvalue()).decode("utf-8")
html = f"<img src='data:image/png;base64,{encoded}'>"
metadata = {
"outputs": [
{
"type": "web-app",
"storage": "inline",
"source": html,
},
],
}
with open(mlpipeline_ui_metadata, "w") as html_writer:
json.dump(metadata, html_writer)
@pipeline(name="plot_pipeline")
def plot_pipeline():
plot_linear()
if __name__ == "__main__":
kfp.compiler.Compiler().compile(plot_pipeline, "plot_pipeline.yaml")- Pipeline 작성 시 위와 같다.
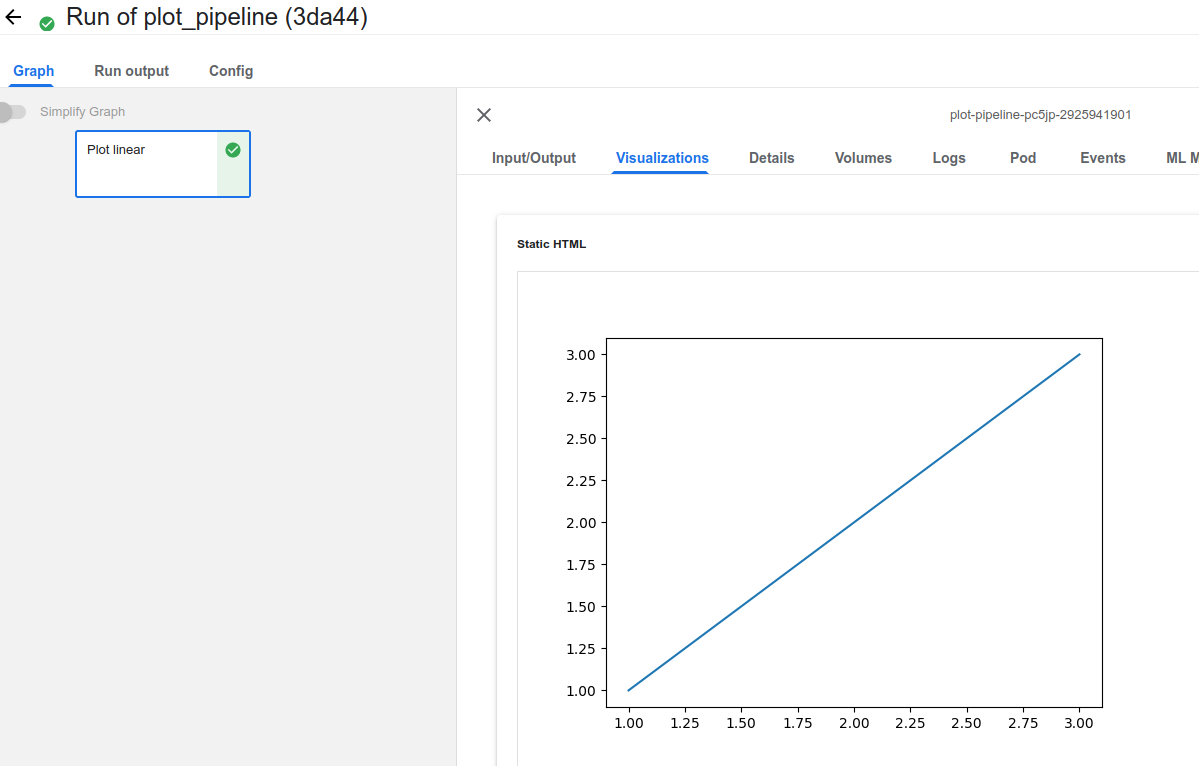
- 빌드 후 Pipeline run 이후 Visualization 결과다.
Run Output
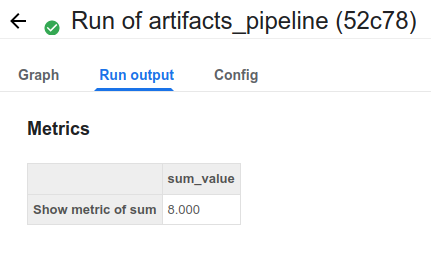
- kubeflow에서 지정한 형태로 생긴 Artifacts를 모아서 보여주는 곳이며 Metric을 보여준다.
@create_component_from_func
def show_metric_of_sum(
number: int,
mlpipeline_metrics_path: OutputPath("Metrics"),
):
import json
metrics = {
"metrics": [
{
"name": "sum_value",
"numberValue": number,
},
],
}
with open(mlpipeline_metrics_path, "w") as f:
json.dump(metrics, f)mlpipeline_metrics_path: OutputPath("Metrics")argument에 보여주고 싶은 이름과 값을 json 형태로 저장하면 된다.
import kfp
from kfp.components import create_component_from_func, OutputPath
from kfp.dsl import pipeline
@create_component_from_func
def print_and_return_number(number: int) -> int:
print(number)
return number
@create_component_from_func
def sum_and_print_numbers(number_1: int, number_2: int) -> int:
sum_number = number_1 + number_2
print(sum_number)
return sum_number
@create_component_from_func
def show_metric_of_sum(
number: int,
mlpipeline_metrics_path: OutputPath("Metrics"),
):
import json
metrics = {
"metrics": [
{
"name": "sum_value",
"numberValue": number,
},
],
}
with open(mlpipeline_metrics_path, "w") as f:
json.dump(metrics, f)
@pipeline(name="example_pipeline")
def example_pipeline(number_1: int, number_2: int):
number_1_result = print_and_return_number(number_1)
number_2_result = print_and_return_number(number_2)
sum_result = sum_and_print_numbers(
number_1=number_1_result.output, number_2=number_2_result.output
)
show_metric_of_sum(sum_result.output)
if __name__ == "__main__":
kfp.compiler.Compiler().compile(example_pipeline, "example_pipeline.yaml")- Pipeline에 적용한 코드다.
- 실행 후 Run output에 정상적으로 출력되는 것을 확인할 수 있다.
Config
- Config에서는 Pipeline Config로 입력 받은 모든 값을 확인할 수 있다.

OnePunchLotto