- Practitioners guide to MLOps
- 구글은 MLOps의 핵심 기능들을 언급했다.
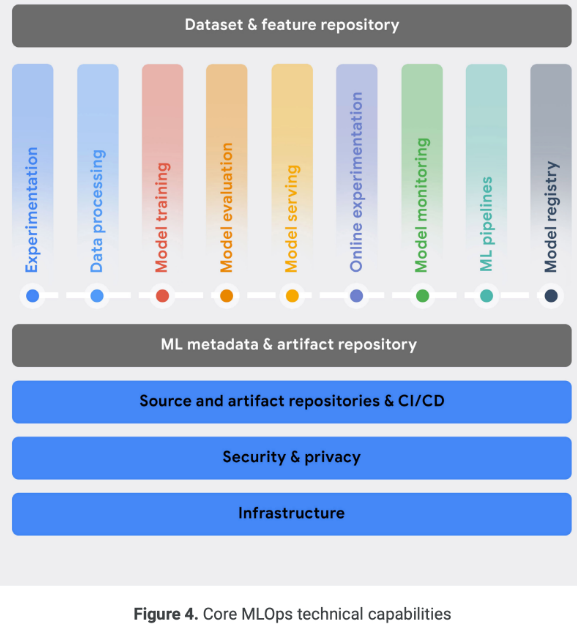
1. Experimentation
- 머신러닝 엔지니어들이 데이터를 분석, 프로토타입 모델을 만들며 학습 기능을 구현할 수 있도록 한다.
- Git과 같은 Version Control 도구, 주피 노트북 등의 환경 제공
- 사용 데이터, 하이퍼 파라미터, 평가 지표를 포함한 실험 추적 기능 제공
- 데이터와 모델에 대한 분석 및 시각화 기능 제공
2. Data Processing
- CT, 머신러닝 모델 개발, API Deployment 단계에서 많은 양의 데이터를 사용할 수 있게 해주는 기능을 제공한다.
- 다양한 데이터 소스, 호환되는 데이터 커넥터 기능 제공
- 다양한 형태의 데이터와 호환되는 데이터 인코더, 디코더 기능 제공
- 다양한 형태의 데이터에 대한 데이터 변환과 피처 엔지니어링 기능 제공
- 학습과 서빙을 위한 확장 가능한 배치, 스트림 데이터 처리 기능 제공
3. Model Training
- ML 프레임 워크 실행을 위한 환경 제공
- 다수 GPU, Distributed 학습을 위한 환경 제공
- 하이퍼 파라미터 튜닝과 최적화 기능 제공
4. Model evaluation
- 평가 데이터에 대한 모델 성능 평가 기능
- 서로 다른 지속 학습, 성능 추적
- 서로 다른 모델의 성능 비교 및 시각화
- 해석할 수 있는 AI 기술을 이용한 모델 출력해석 기능
5. Model serving
- 다양한 ML 모델 서빙 프레임워크 지원 (TF, TorchServe, ... etc)
- 복잡한 형태의 추론 루틴 기능 제공 (preprocessing, postprocessing, multi modal 등)
- 치솟는 추론 요청 처리를 위한 오토 스케일링
- 추론 요청과 추론 결과에 대한 로깅 기능
6. Online experimetnation
- 새로운 모델 생성 시, 배포하면 어느정도 성능을 보일지 검증하는 기능을 제공
- Model Registry와 연동되어야한다.
- canary & shadow 배포 기능 제공
- A/B 테스트 기능 제공
- Multi-armed bandit 테스트 기능 제공
7. Model Monitoring
- 상용 환경에 배포된 모델이 정상적 작동을 하고 있는지를 모니터링하는 기능을 제공
- 모델의 성능이 떨어져 업데이트가 필요한지에 대한 정보 등을 제공
8. ML Pipeline
- 복잡한 ML 학습, 추론 작업을 구성하여 제어하고, 자동화하기 위함
- 다양한 이벤트를 소스를 통한 파이프라인 실행 기능
- 파라미터, 산출물 관리를 위한 추적과 연동 기능
- 서로 다른 실행 환경 제공 기능
9. Model Registry
- 학습된 모델, 배포된 모델에 대한 등록 & 추적 & 버저닝
- 배포를 위해 필요한 데이터, 런타임 패키지들에 대한 정보 저장
10. Dataset & Feature Repository
- 데이터에 대한 공유, 검색, 재사용 및 버전 관리 기능
- 이벤트 스트리밍 및 온라인 추론 작업에 대한 실시간 처리
- 다양한 형태의 데이터 지원 기능 (사진, 텍스트, 테이블 .. 등)
11. ML Metadata & Artifact Tracking
- ML 산출물에 대한 히스토리 관리 기능
- 실험과 파이프라인 파라미터 설정에 대한 추적, 공유
- 산출물에 대한 저장 및 접근, 시각화, 다운로드 기능
- 다른 MLOps 기능과 통합 기능 제공

OnePunchLotto