- Hidden Technical Debt in Machine Learning Systems
- 구글의 ML Product에 대한 생각을 담고 있는 논문이다.
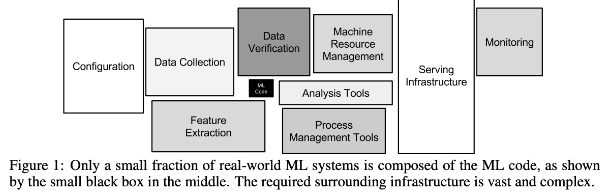
- 위 논문의 핵심은 머신러닝을 이용한 제품을 만드는데 있어 머신러닝 코드는 전체 시스템 구성 중 아주 일부일 뿐이라는 것이다.
- 구글에서는 MLOps의 발전 단계를 총 3단계로 나눴다.
0 : 수동 Process
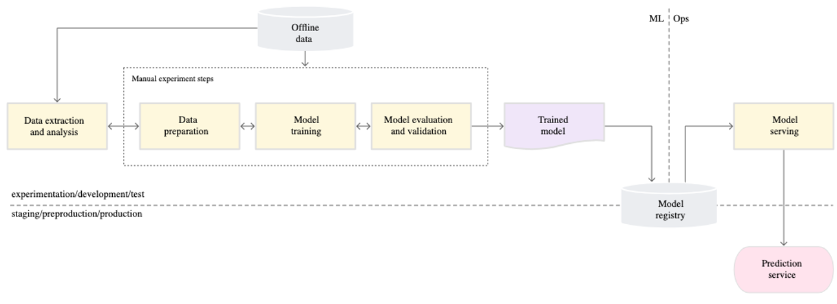

- 머신러닝 & 운영팀은 모델을 통해 소통한다.
- 쌓여있는 데이터로 모델을 학습시키고 학습된 모델을 운영팀에 전달한다. 운영팀은 이렇게 전달받은 모델을 배포한다.
- 이런 배포방식은 여러 문제가 있다.
- Python code
- Trained Weight
- Environments (packages, versions, etc...)
- 머신러닝 시, 다양한 오픈소스를 사욯하는데 버전이 다를 경우 어떤 버전을 쓰냐에 따라 같은 함수라도 결과가 다를 수 있다.
- 이러한 문제는 관리하는 기능이 많아지고 소통에 어려움을 느끼게 된다면 더 좋은 모델을 빠르게 배포할 수 없게 된다.
1 : ML Pipeline 자동화
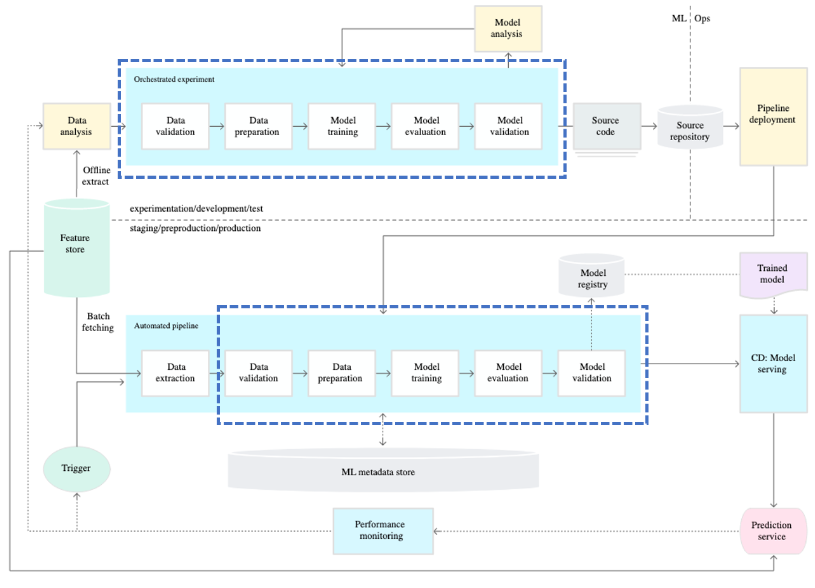
- MLOps에서는 버전 및 환경에 따른 문제를 방지하고자 Docker와 같은 컨테이너 기술을 이용해 머신러닝 엔지니어가 모델 개발에 사용한 것과 동일한 환경으로 동작되는 것을 보장한다.
- Pipeline이란 범용적인 용어로, 다양한 Task에서 사용된다.
- 머신러닝 엔지니어가 작성하는 파이프라인은 학습된 모델을 생산한다.
Continuous Training (CT)
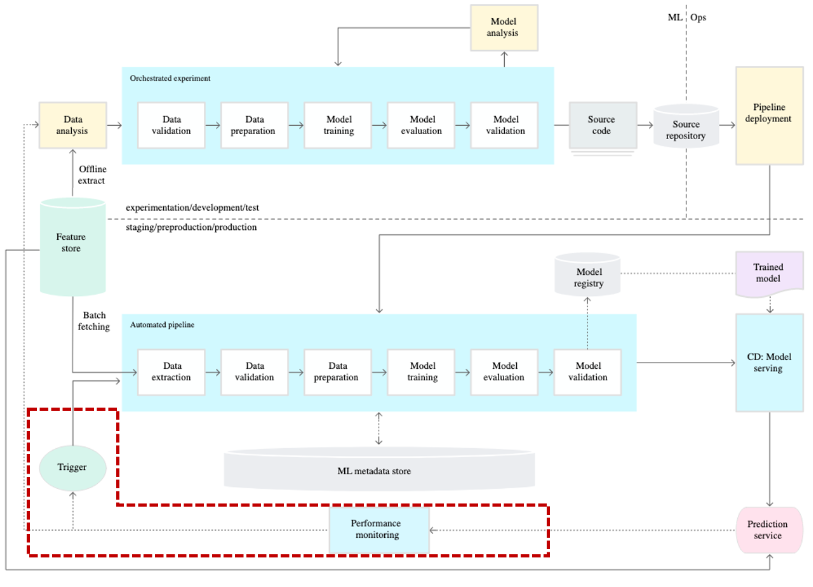
-
CT가 중요한 이유는 2가지가 있다. Auto Retrain, Auto Deploy
-
Auto Retrain
- Real World에서는 Data shift라는 데이터 분포가 계속 변하는 특징이 있다. 그러므로 과거에 학습한 모델이 시간이 지남에 따라 성능이 저하되는 문제가 있다.
- 이를 해결하는 간단한 해결책은 최근 데이터를 이용해 모델을 재학습 하는 것이다.
-
Auto Deploy
- 무조건 재학습하는 것이 좋을까?
- Blind Spot : 데이터를 모으기 위해 모델이 동작하지 않는 구간
- 즉, Rrtrain 규칙만 있으면 기존 모델에 대해 새로운 모델을 학습할 수 있다. 다만, 머신러닝 모델이 충분한 성능을 보이기 위해서는 충분한 양의 데이터가 모여야한다. 기존에 있던 모델을 모델 A, 새로운 모델을 모델 B라고 했을 때, 기존 모델을 통해 A가 처리하던 데이터를 B가 잘 처리하지 못하면 다시 A가 처리하던 데이터를 학습시켜 새로운 Model C를 만들면된다. 하지만 불가피한 이유로 다시 모델 A 로 바뀌면, B, C가 잘 처리하던 데이터에 대해 또 다시 성능 저하가 발생하게 된다.
- Blind Spot을 해결하는 방법은 새로운 모델을 학습하기 보다 이 전 모델을 이용해 다시 예측하는 것이다. 이렇게 모델을 자동으로 변환해주는 것을 Auto Deploy라고 한다.
-
CT를 위해서는 Auto Retrain, Auto Deploy 두가 지 기능이 필요한데, 둘은 서로의 단점을 보완해서 계속해서 모델 성능을 유지할 수 있게 한다.
2 : CI/CD Pipeline 자동화
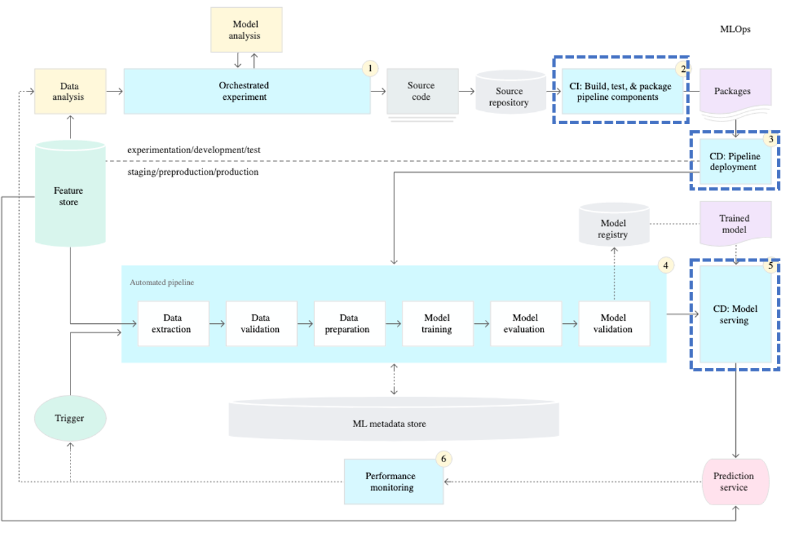
- DevOps에서 CI/CD의 대상은 소스 코드다.
- MLOps에서는 엄밀히 정의하자면 학습 파이프라인이라고 볼 수 있다.
- 모델을 학습하는데 있어서 정상적으로 학습이 되는지 (CI), 학습된 모델이 정상적으로 동작하는지 (CD)를 확인해야 한다.
- 학습하는 코드에 직접적인 수정이 있는 경우에는 CI/CD를 진행해야 한다.
- 코드 외에도 사용하는 패키지 버전, 파이썬 버전 변경도 CI/CD의 대상이다.
- 오픈 소스는 그 특성상 버전이 바뀌었을 때 함수의 내부 로직이 변하는 경우도 있다. 그러므로 패키지 버전이 변하는 경우에도 CI/CD를 통해 정상적으로 모델이 학습, 동작하는지 확인해야한다.

OnePunchLotto