Rerference
Abstract
- Lidar, Camera를 이용한 객체 검출 후 각 센서에서 검출된 객체를 late fusion 방식으로 융합하여 성능을 향상시킨다.
- 해당 논문에서는 Camera(YoLov3), 거리 추정은 Perspective Matrix, Lidar 객체 검출은 K-means Clustering 기반 객체 검출을 이용했다.
- Camera - Lidar 간 Calibration은 PnP - RANSAC을 이용하여 변환 행렬을 구한다.
- Sensor Fusion은 검출된 객체를 이미지 평면에 옮겨 IoU를 계산하고, 카메라에서 검출된 객체를 월드 좌표에 옮겨 거리, 각도를 계산해 IoU, 거리, 각도 세 가지 속성을 Logistic Regression을 이용해 Fusion 하였다.
- 성능이 약 5% 증가했다고한다.
Intro
- 각 센서에서 객체 검출을 한 뒤 융합하는 방법을 late fusion이라고 한다.
- CNN을 통해 이미지 상 객체 검출, SVM을 통해 Lidar에서 객체를 검출하여 각도, 거리, score 정보를 fuzzy logic을 통해 검출된 결과를 융합했다.
- fuzzy logic 이란 애매함을 다루는 논리다. 가령, 이진 논리는 80점 이상은 우수한 성적 그 미만은 저조한 성적으로 나눌 수 있다. 79점은 우수한 성적이 아닌가 ? 퍼지 논리는 매우 우수, 약간 우수 등으로 0.0 ~ 1.0 사이 값으로 score를 나누는 방식을 취한다.
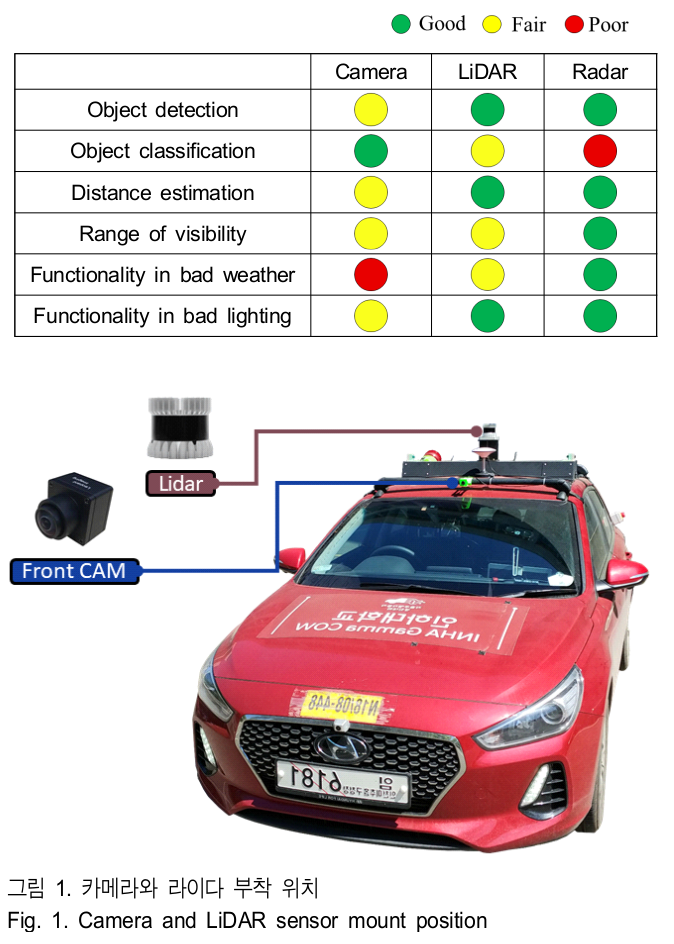
- 주변 환경별 센서의 성능을 비교한 표이다.
- 카메라는 객체의 분류, 검출에는 강하지만 날씨와 조도 영향을 많이 받는다.
- 반면, 레이더는 날씨와 조도에 강인하고 객체 분류는 낮은 성능을 보여주고 있다.
- 센서 융합을 통해 각 센서의 약점을 보완해주고자한다.
- 센서 융합을 하기 위해서는 각 센서가 가지고 있는 각기 다른 좌표계를 하나의 좌표계로 이동시킨 후 알고리즘을 이용해 융합해야 한다.
- 본 논문에서는 최적의 성능을 낼 수 있는 위치에 센서를 장착 한 후 각 센서에서 객체 검출 뒤 카메라 픽셀 좌표를 라이다의 월드 좌표, 라이다의 월드 좌표를 카메라의 픽셀 좌표로 각각 변환해 융합할 수 있는 방법을 제안하고 있다.
Theory
1. 카메라 객체 검출 및 Tracking
- OneStage 방식으로 YOLO, SSD, RetinaNet, TwoStage 방식으로 R-CNN 계열 등이 있다. 보통 속도 때문에 OneStage 방식을 사용하는데 이는 객체 검출 성능은 TwoStage 방식보다는 객체 검출 성능이 떨어지는 단점을 갖고 있다.
- YOLO : 이미지 feature를 sparse grid 분할 후 그리드별 분류 및 bbox 회귀를 동시 진행
- SSD : 미리 정의된 다양한 크기의 anchor box를 사용해 다양한 객체 및 모양 검출
- RetinaNet : 클래스 불균형 해소를 위해 Focal Loss 사용 (클래스 불균형 문제를 해소하면 OneStage가 TwoStage 보다 좋은 성능을 낼 수 있음을 보여줬음)
- Two Stage 방식은 두 단계로 나누어 객체 검출을 수행한다.
- 첫번째 단계에서 region proposal을 추출
- 두번째 단계에서 객체 분류 및 bbox regression 수행
- R-CNN : 초기단계 모델로 프레임당 제안된 영역을 모두 CNN을 통하므로 처리 속도가 느리다.
- Fast-RCNN : RoIPool을 이용해 이미지 sub region에 대한 foward pass 값을 공유한다. Selective Search를 사용하여 Region Proposal을 진행하여 속도가 느려 Bottleneck이 있다.
- Fatster-RCNN : Selective Search를 region proposal로 바꿔 위 병목 문제를 해결했고, forward pass를 통해 얻은 featur에 기반해 영역을 제안한다. sliding widnow를 feature map에서 anchor box를 구해 bbox와 score를 계산한다.
- Two stage는 OneStage에 비하면 현저히 느려 실시간 시스템에 사용하기는 역부족이다.
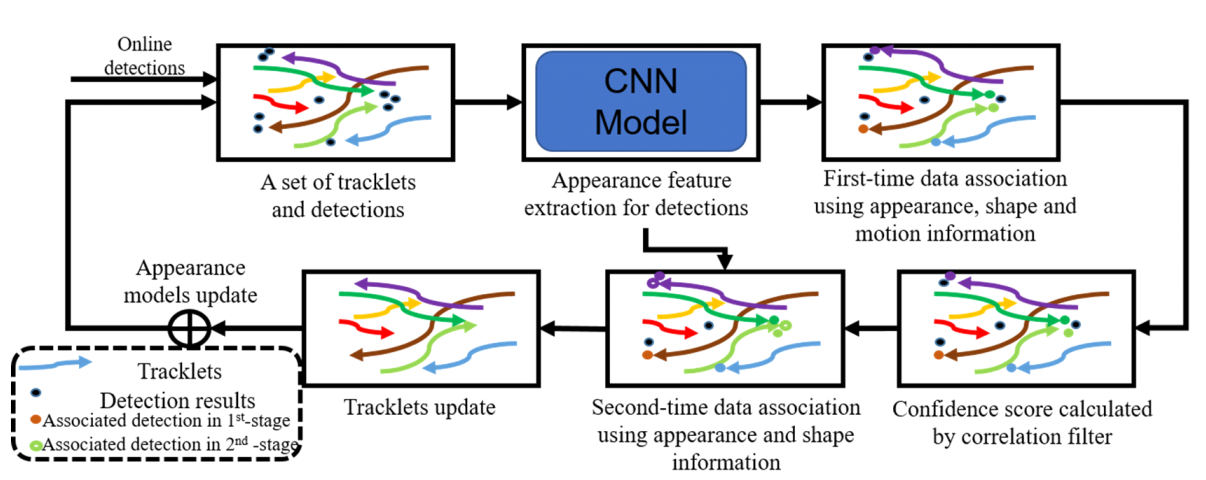
- CNN, Hungarian을 이용한 객체 추적 과정을 보여주는 그림이다.
- Object Tracking은 영상에서 특정 대상의 위치 변화를 추적하는 것이다.
- 각 frame에서 객체 검출 후 입력값으로 객체의 위치를 얻는다. 객체 형상, 위치 및 외관을 포함하는 다양한 종류의 특징 정보가 각각 검출된 객체에 융합된다. 그 이후 트랙렛-검출 쌍에 대해 신뢰 점수가 계산된다.
- 기존 트랙렛-검출

OnePunchLotto