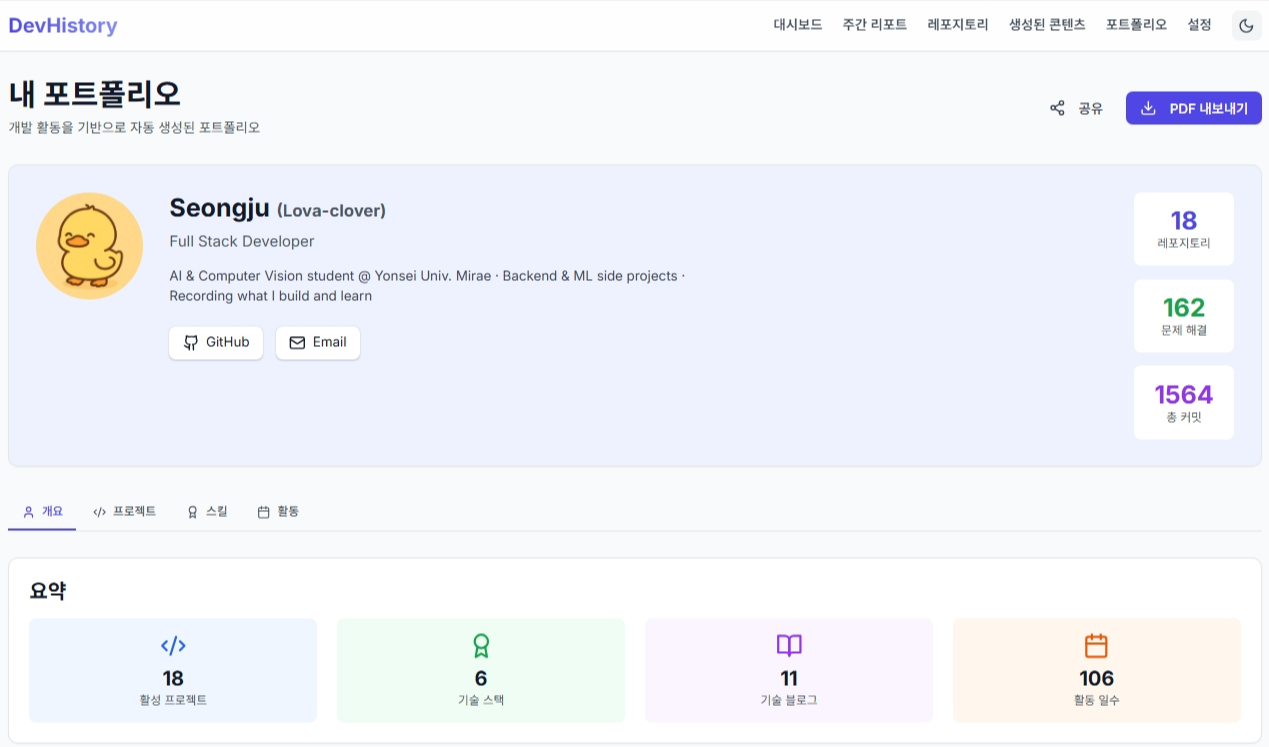
0. 배경 – 왜 만들었나
개발하다 보면 GitHub에 수십 개의 레포지토리가 쌓이고, 백준이나 Velog에도 활동 기록이 남는다. 근데 막상 포트폴리오 만들려고 하면 이걸 일일이 정리하는 게 너무 귀찮았다. "자동으로 수집해서 정리해주고, LLM으로 블로그 글까지 써주면 얼마나 좋을까?" 하는 생각에서 시작했다.
그러다가 "아예 플랫폼으로 만들면 괜찮겠는데?"라는 생각이 들어서 본격적으로 개발하게 됐다.
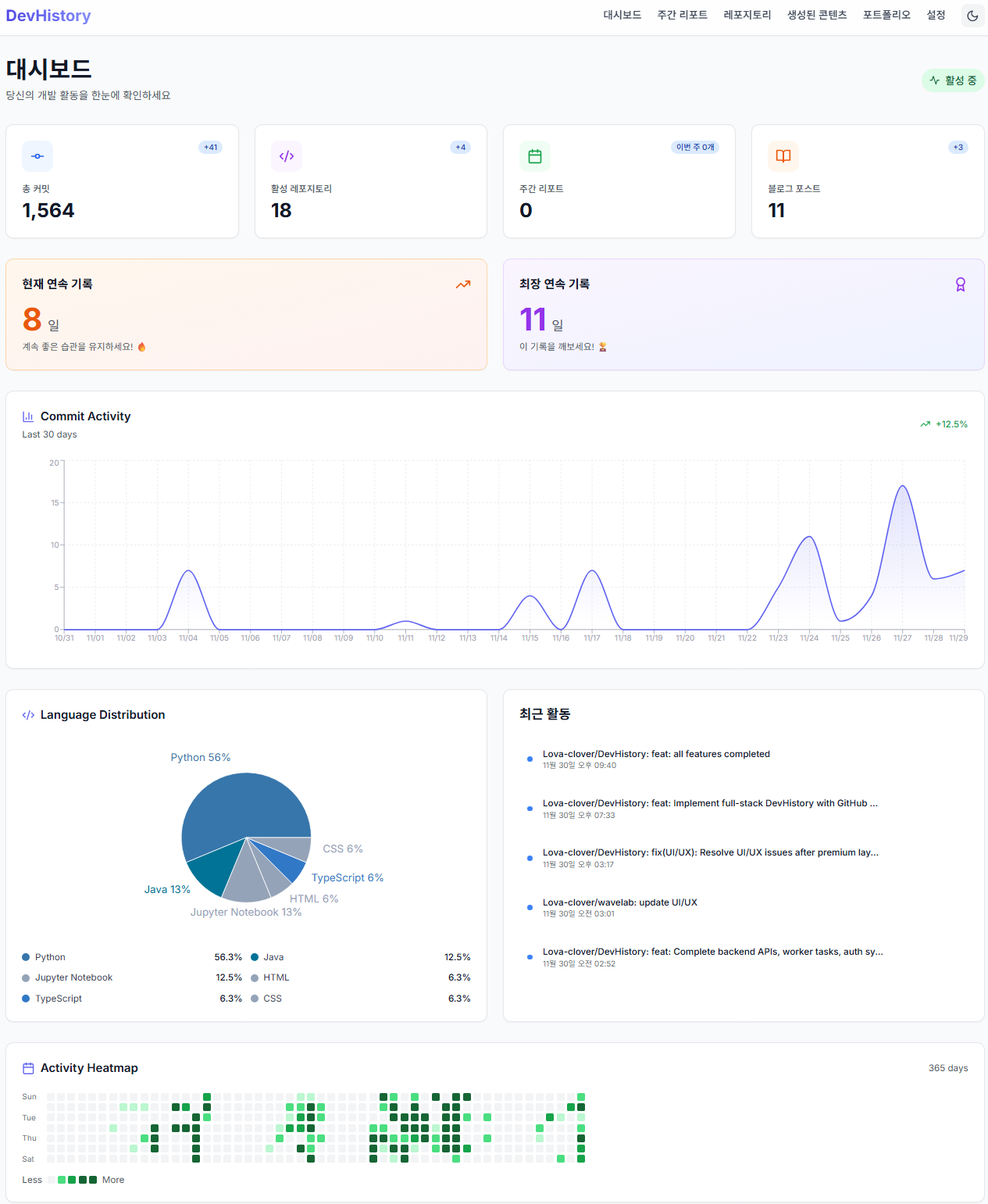
대시보드에서 한눈에 볼 수 있는 개발 활동 통계
1. 문제 정의
개발자들이 겪는 문제:
- GitHub, Velog, Solved.ac 등 여러 플랫폼에 흩어진 활동 기록
- 포트폴리오 만들 때마다 수작업으로 정리해야 함
- 프로젝트마다 블로그 글 쓰기 귀찮음
- 주간 회고나 활동 리포트를 자동으로 받고 싶음
목표: 모든 개발 활동을 자동으로 수집해서 대시보드로 보여주고, LLM이 블로그 글과 주간 리포트까지 작성해주는 서비스
2. 기술 스택 선택
백엔드
-
FastAPI (Python 3.11)
- 비동기 처리로 외부 API 호출 최적화
- Pydantic으로 타입 안정성 확보
- 자동 API 문서 생성 (Swagger)
-
PostgreSQL
- 관계형 데이터로 레포-커밋-블로그 연결
- SQLAlchemy ORM으로 쿼리 관리
-
Celery + Redis
- 백그라운드 작업 (GitHub/Velog 동기화, LLM 생성)
- 주간 리포트 스케줄링
-
Alembic
- 데이터베이스 마이그레이션 관리
프론트엔드
-
Next.js 14 (App Router)
- Server Components로 초기 로딩 최적화
- TailwindCSS로 빠른 UI 구성
- Framer Motion으로 부드러운 애니메이션
-
Recharts
- 커밋 트렌드, 언어 분포 시각화
LLM
- OpenAI API (gpt-4o-mini)
- 레포지토리 README + 커밋 히스토리 → 기술 블로그 자동 생성
- 주간 활동 → 회고 리포트 자동 생성
- 스타일 프로필로 사용자별 말투 학습
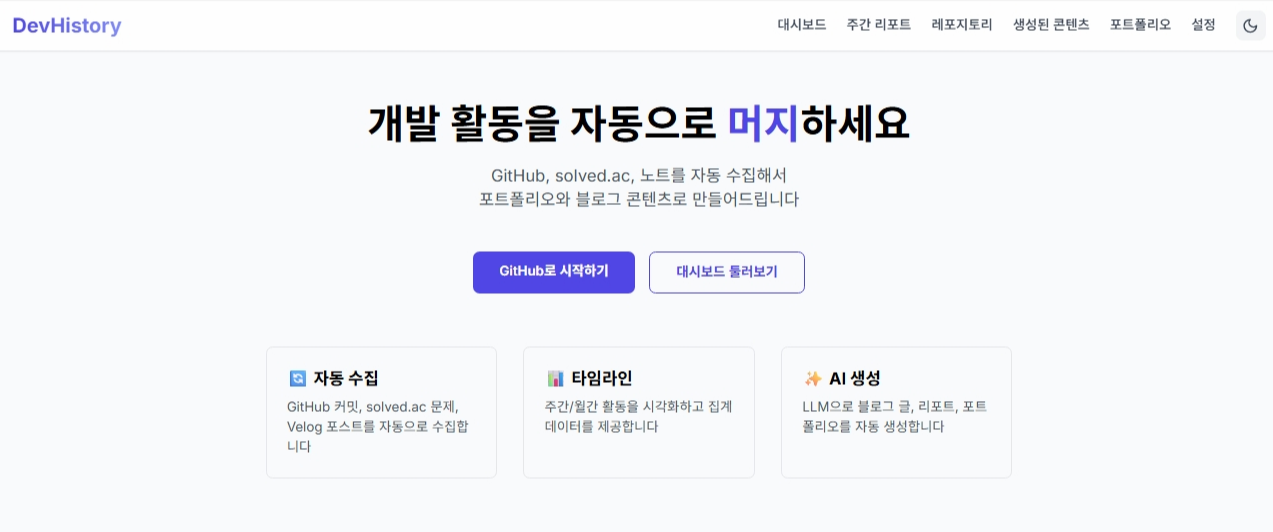
DevHistory 랜딩 페이지 - "개발 활동을 자동으로 머지하세요"
💡 사용 흐름
DevHistory를 실제로 어떻게 사용하는지 단계별로 정리했다.
1️⃣ GitHub 계정으로 시작하기
- 홈페이지에서 "GitHub로 시작하기" 버튼 클릭
- GitHub OAuth 화면에서 권한 허용 (레포지토리 읽기, 사용자 정보)
- 자동으로 로그인되고 대시보드로 이동
2️⃣ 추가 계정 연동 (선택)
- 설정 페이지에서 Velog ID와 Solved.ac 핸들 입력
- 포트폴리오 정보 설정 (이름, 이메일, 자기소개, 표시할 레포 개수)
- 저장하면 모든 플랫폼의 데이터를 수집할 준비 완료
3️⃣ 활동 데이터 자동 수집
- 대시보드에서 "GitHub 동기화", "Velog 동기화", "Solved.ac 동기화" 버튼 클릭
- Celery 워커가 백그라운드에서 비동기로 데이터 수집:
- GitHub: 본인 소유 레포지토리, 커밋 히스토리 (contributor 레포 제외)
- Velog: 블로그 포스트 메타데이터 (제목, URL, 날짜)
- Solved.ac: 푼 문제 목록, 난이도, 티어
- 새로운 활동이 생기면 언제든 다시 동기화 가능
4️⃣ 대시보드에서 활동 확인
- 전체 통계: 총 커밋 수, 레포지토리 개수, 문제 풀이 수, 블로그 글 수
- 주간 트렌드: 이번 주 vs 지난주 증감 (+13, +2 같은 절대값)
- 커밋 트렌드 그래프: 날짜별 활동량 시각화
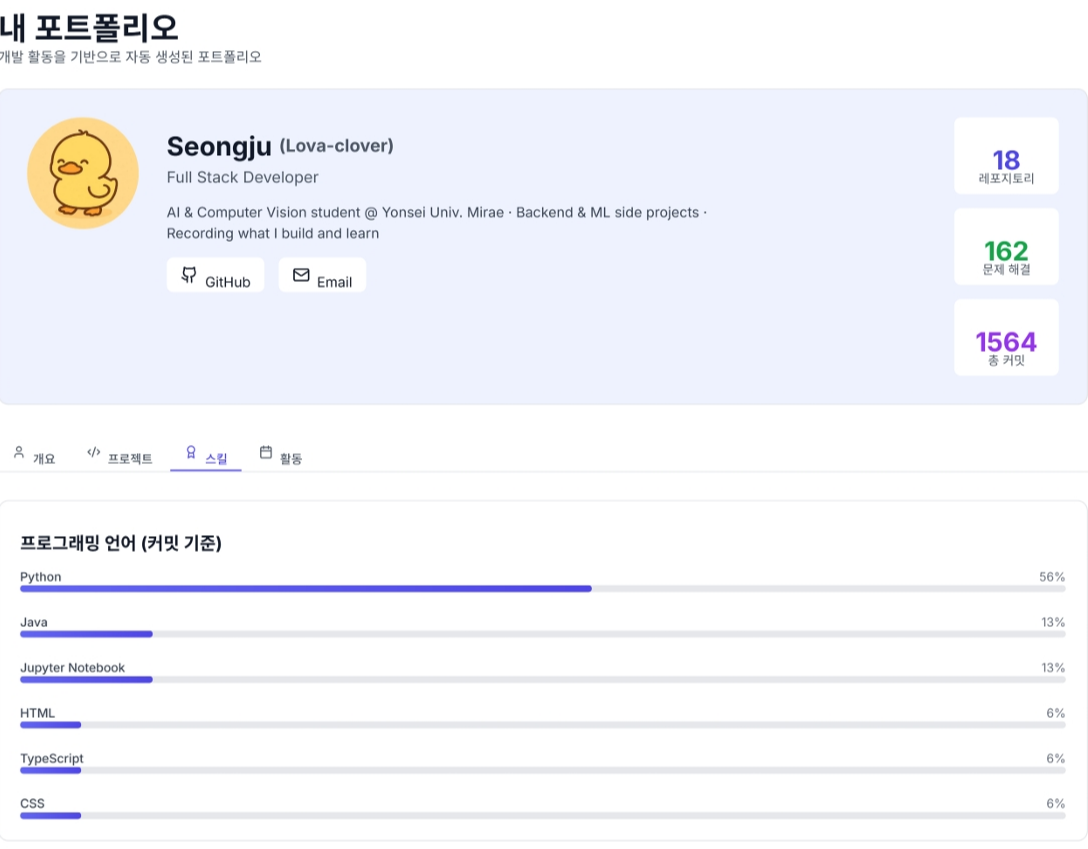
- 언어 분포: 레포지토리 개수 기준 프로그래밍 언어 비율
5️⃣ 레포지토리 블로그 글 생성
- 레포지토리 메뉴에서 프로젝트 선택
- "블로그 글 생성" 버튼 클릭
- OpenAI가 다음 정보를 바탕으로 기술 블로그 초안 작성:
- README 내용 (최대 3000자)
- 최근 커밋 히스토리 요약
- 레포지토리 생성 날짜, 사용 언어
- 사용자의 Velog 스타일 학습 (반말, 친근한 톤)
- 생성된 글은 생성된 콘텐츠 메뉴에서 확인/수정/삭제 가능
6️⃣ 주간 회고 리포트
- 주간 리포트 메뉴에서 최근 활동 기반 회고 글 확인
- 이번 주 커밋, 레포, 문제 풀이 통계를 자연스러운 문장으로 정리
- Velog나 노션에 바로 복사해서 사용 가능
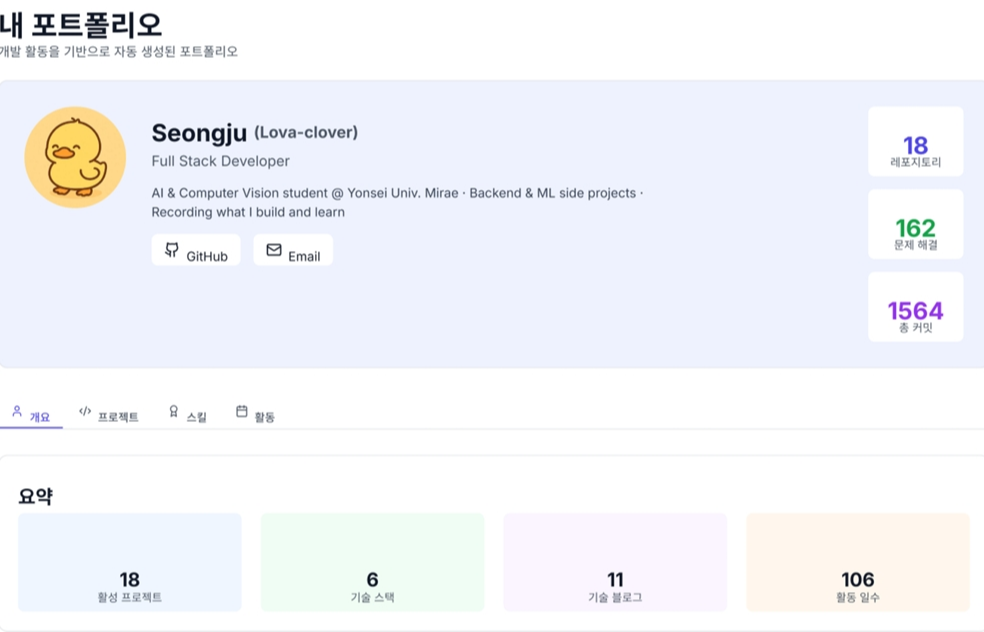
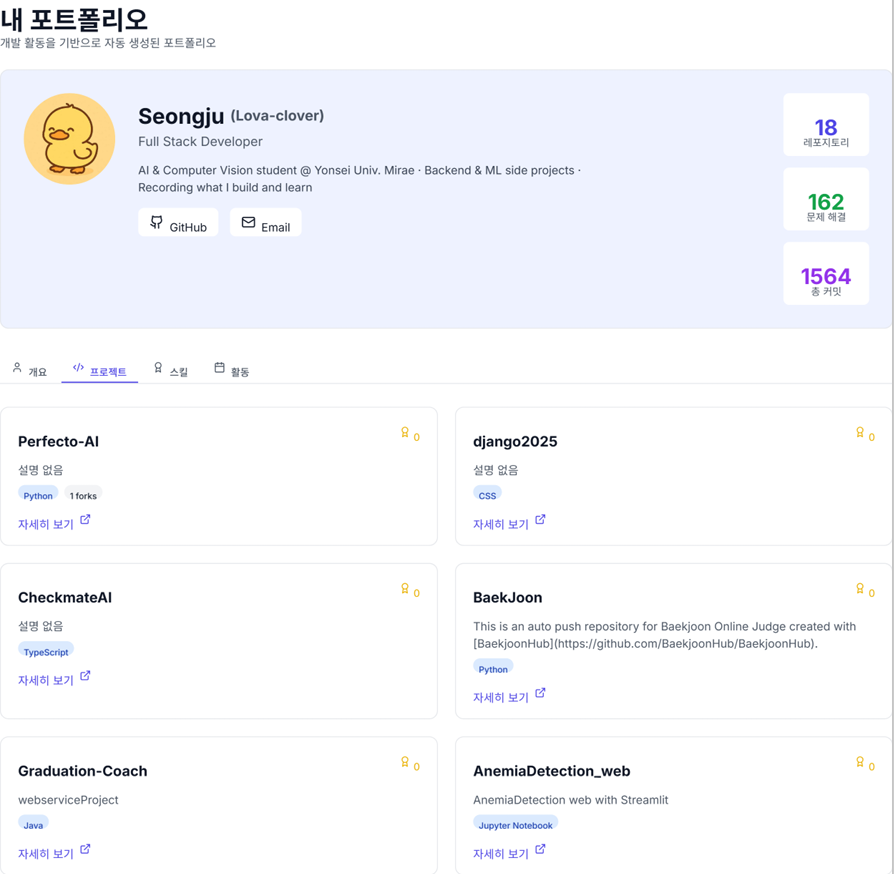
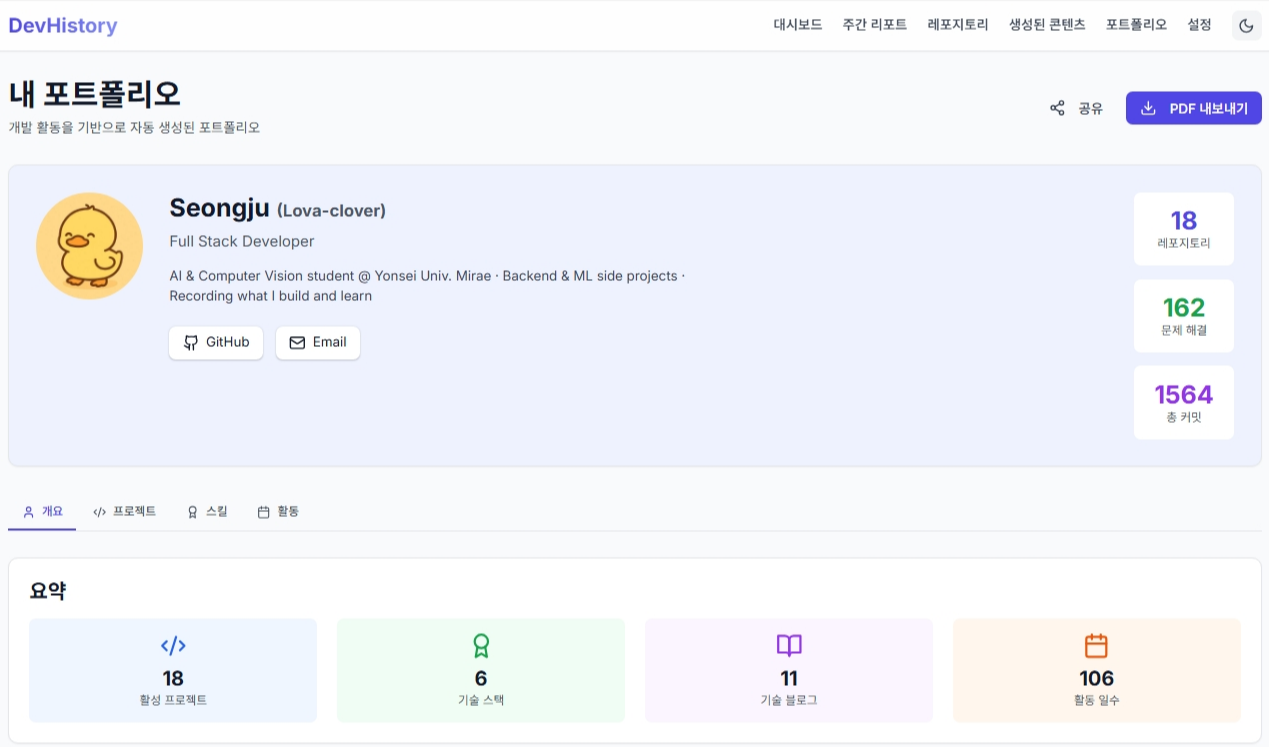
7️⃣ 포트폴리오 생성 및 내보내기
- 포트폴리오 메뉴에서 자동 생성된 포트폴리오 확인:
- 프로필 카드 (아바타, 이름, 소개, GitHub 링크)
- 활동 통계 (레포, 문제, 커밋, 블로그)
- 커밋 수 기준 상위 프로젝트
- 레포 개수 기준 기술 스택
- "PDF 내보내기" 버튼으로 포트폴리오를 PDF로 다운로드:
- 개요, 프로젝트, 스킬 탭이 모두 포함
- 각 탭마다 별도 페이지로 생성
- 파일명:
{이름}_{날짜}.pdf
8️⃣ 생성된 콘텐츠 관리
- 생성된 콘텐츠 메뉴에서 모든 AI 생성 글 관리
- 글 클릭 시 Markdown 프리뷰 확인
- 수정 버튼으로 내용 편집
- 삭제 버튼으로 불필요한 글 제거
핵심 포인트:
- 한 번 연동하면 → 버튼 클릭만으로 데이터 업데이트
- AI가 알아서 → Velog 스타일로 블로그 글 작성
- 포트폴리오 → 클릭 한 번에 PDF로 내보내기
- 모든 활동 → 한곳에서 타임라인으로 확인
더 이상 수작업 없이, 개발만 하면 포트폴리오가 쌓입니다. ✨
3. 구현 과정
3.1 OAuth 인증 플로우
처음엔 세션 기반으로 하려다가 JWT로 전환했다. 프론트와 백엔드가 분리되어 있어서 토큰 방식이 더 깔끔했다.
# apps/api/app/routers/auth.py
@router.get("/github")
async def github_login():
"""GitHub OAuth 시작"""
return {
"url": f"https://github.com/login/oauth/authorize?client_id={GITHUB_CLIENT_ID}&scope=repo,user"
}
@router.get("/github/callback")
async def github_callback(code: str, db: Session = Depends(get_db)):
"""GitHub OAuth 콜백 처리"""
# 1. GitHub에서 access_token 받기
token_data = await exchange_code_for_token(code)
# 2. 사용자 정보 가져오기
user_info = await get_github_user(token_data["access_token"])
# 3. DB에 사용자 생성 또는 업데이트
user = upsert_user(db, user_info)
# 4. JWT 토큰 발급
access_token = create_access_token({"sub": str(user.id)})
return {"access_token": access_token, "token_type": "bearer"}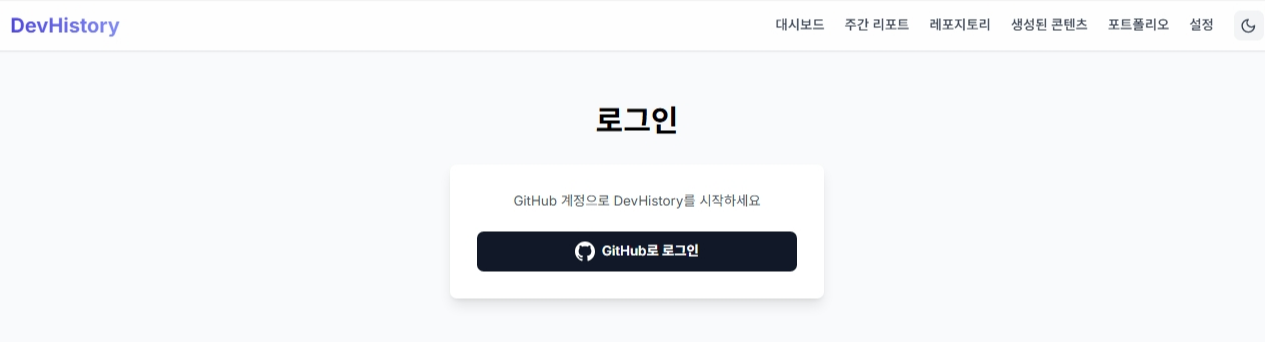
GitHub OAuth 로그인 화면
3.2 데이터 수집 파이프라인
GitHub API, Velog RSS, Solved.ac API를 통해 데이터를 수집한다. 처음엔 동기적으로 구현했는데 너무 느려서 httpx의 비동기로 전환했다.
중요한 발견: GitHub API의 /user/repos는 본인 소유가 아닌 레포도 가져온다. affiliation=owner 파라미터를 꼭 넣어야 한다.
# packages/merge_collector/merge_collector/github.py
async def sync_repos(user_id: str, access_token: str, db: Session):
"""GitHub 레포지토리 동기화"""
async with httpx.AsyncClient(timeout=30.0) as client:
response = await client.get(
"https://api.github.com/user/repos",
headers={"Authorization": f"Bearer {access_token}"},
params={
"affiliation": "owner", # 본인 소유만!
"sort": "updated",
"per_page": 100,
}
)
repos = response.json()
# DB에 저장 (Upsert 패턴)
for repo_data in repos:
existing = db.query(Repo).filter_by(
user_id=user_id,
provider_repo_id=str(repo_data["id"])
).first()
if existing:
# 기존 레포 업데이트
existing.stars = repo_data["stargazers_count"]
existing.language = repo_data["language"]
else:
# 새 레포 생성
db.add(Repo(...))
db.commit()3.3 대시보드 통계 계산
처음엔 단순히 COUNT(*)만 했는데, 증감 트렌드를 보여주려다가 삽질을 좀 했다.
문제: "지난주 대비 +657%" 같은 말도 안 되는 숫자가 나왔다.
원인: 전체 커밋을 일주일 데이터로 나눠서 비율 계산하는 바람에 퍼센트가 엄청나게 나온 것.
해결: 절대값 차이로 변경하고, API를 range=year(전체)와 range=week(트렌드) 두 개로 분리했다.
# apps/api/app/routers/dashboard.py
@router.get("/summary")
async def get_summary(
range: str = "year", # "week" or "year"
current_user: User = Depends(get_current_user),
db: Session = Depends(get_db)
):
if range == "week":
# 이번 주 vs 지난주
this_week = get_week_stats(db, current_user.id, weeks_ago=0)
last_week = get_week_stats(db, current_user.id, weeks_ago=1)
return {
"commit_count": this_week["commits"],
"commit_diff": this_week["commits"] - last_week["commits"], # 지난주 대비 증감 (개수)
"repo_count": this_week["repos"],
"repo_diff": this_week["repos"] - last_week["repos"],
}
else:
# 전체 통계
return {
"total_commits": db.query(Commit).filter_by(user_id=current_user.id).count(),
"total_repos": db.query(Repo).filter_by(user_id=current_user.id).count(),
}
올바르게 수정된 통계 (절대값 차이)
3.4 LLM 블로그 생성
가장 중요한 부분. OpenAI API로 레포지토리 정보를 주고 기술 블로그를 작성하게 했다.
V1.0 – README만 넣어줬더니 너무 형식적인 글이 나왔다.
V1.1 – 커밋 히스토리를 요약해서 추가. 훨씬 구체적인 글이 나왔다.
V1.2 – 사용자의 Velog 글을 분석해서 말투를 학습시켰다. "~했습니다" 대신 "~했다" 반말 톤으로 변경.
# packages/merge_forge/merge_forge/repo_blog.py
def generate_repo_blog(user, repo, style_profile, readme_content, commit_summary):
"""레포지토리 → 기술 블로그 자동 생성"""
# 실제 코드에서는 style_profile을 기반으로 톤/구조를 system_prompt에 반영한다.
system_prompt = f"""
당신은 기술 블로그를 작성하는 개발자입니다.
반말 사용 (~다, ~했다, ~같다)
친근하고 솔직한 톤: '막상 해보니', '생각보다', '근데'
과정과 시행착오 중심: 완벽한 결과보다는 배운 것
"""
user_prompt = f"""
# 프로젝트: {repo.full_name}
생성 날짜: {repo.created_at.strftime('%Y년 %m월')}
## README 내용
{readme_content[:3000]} # 처음엔 1500자였는데 짤려서 3000으로 증가
## 최근 커밋 히스토리
{commit_summary} # 최근 50개 커밋 요약
작성 가이드:
- 제목: "EfficientNet-B0로 과일 신선도 판별 모델 만들기" 스타일
- 구조: 배경 → 문제정의 → 기술선택 → 구현과정 → 겪은 문제 → 결과 → 배운 것
- 구체적인 기술명과 수치 포함
- 중요한 깨달음은 인용구(> )로 강조
"""
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
max_tokens=4000,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
return response.choices[0].message.content
LLM이 자동 생성한 기술 블로그
3.5 포트폴리오 PDF 내보내기
html2canvas로 화면을 캡처하고 jsPDF로 PDF 생성. 근데 처음엔 페이지가 잘려서 나왔다.
문제: 렌더링이 완료되기 전에 캡처해서 빈 공간이나 잘린 이미지가 나왔다.
해결:
1. 탭 전환 후 1초 대기 (setTimeout(1000))
2. 첫 페이지도 0.8초 대기 추가
3. windowWidth, windowHeight 옵션으로 전체 영역 캡처
// apps/web/app/portfolio/page.tsx
const handleExport = async () => {
const tabsToCapture = ['overview', 'projects', 'skills'];
for (let i = 0; i < tabsToCapture.length; i++) {
setActiveTab(tabsToCapture[i]);
await new Promise(resolve => setTimeout(resolve, 1000)); // 충분히 대기!
const canvas = await html2canvas(portfolioRef.current, {
scale: 2,
useCORS: true,
backgroundColor: '#ffffff',
windowWidth: portfolioRef.current.scrollWidth,
windowHeight: portfolioRef.current.scrollHeight,
});
// PDF에 페이지 추가
if (i > 0) pdf.addPage();
pdf.addImage(canvas.toDataURL('image/png'), 'PNG', 0, 0, pdfWidth, scaledHeight);
}
pdf.save(`${user.name}_${date}.pdf`);
};
개요, 프로젝트, 스킬 탭이 모두 포함된 PDF
4. 겪은 문제들
4.1 다크모드 텍스트 가시성
다크모드로 전환하니까 GitHub/Email 버튼의 텍스트가 안 보였다. 배경색만 변경하고 텍스트 색은 그대로 둔 실수.
// Before
className="flex items-center gap-2 px-4 py-2 bg-white dark:bg-gray-800"
// After
className="flex items-center gap-2 px-4 py-2 bg-white dark:bg-gray-800 text-gray-900 dark:text-white"4.2 언어 통계 불일치
대시보드의 "Language Distribution"과 포트폴리오의 "스킬" 비율이 달랐다. 하나는 커밋 수 기준, 다른 하나는 레포 수 기준이었던 것.
통일: 모두 레포지토리 개수 기준으로 변경.
4.3 레포지토리 생성 날짜 오류
모든 레포의 created_at이 오늘 날짜로 나왔다. GitHub에서 가져온 실제 생성 날짜를 무시하고 동기화 시점을 넣고 있었던 것.
# Fix: GitHub의 created_at 사용
if repo_data.get("created_at"):
created_at = datetime.fromisoformat(repo_data["created_at"].replace("Z", "+00:00"))
else:
created_at = datetime.utcnow()4.4 남의 레포지토리 포함
Contributor로 참여한 다른 사람 레포(rabadu/webservice)가 내 통계에 들어왔다. GitHub API의 기본 동작이 그런 거였다.
Fix: affiliation=owner 파라미터 추가로 본인 소유 레포만 가져오기.
5. 결과
- 백엔드: FastAPI + PostgreSQL + Celery로 안정적인 비동기 처리
- 프론트엔드: Next.js 14로 부드러운 UX
- 자동화: GitHub/Velog/Solved.ac 원클릭 동기화
- LLM 생성: 레포지토리 → 기술 블로그 자동 작성
- 포트폴리오: PDF 내보내기, 다크모드 지원
- 주간 리포트: Celery Beat로 매주 자동 생성
실제 활용
이 DevHistory 회고 글도 DevHistory가 생성한 초안을 기반으로 썼다.
- DevHistory에서 DevHistory 레포지토리를 선택하고 블로그 생성 버튼을 누르면, README와 최근 커밋 히스토리를 기반으로 기술 블로그 초안이 만들어진다.
- 나는 그 초안 위에 구현하면서 겪은 시행착오, 느낀 점, 세부 구조를 덧붙이고 문장을 다듬었다.
결국 AI가 뼈대를 만들고, 내가 살을 붙이는 방식이 가장 효율적이었다.
완성된 DevHistory 플랫폼
6. 한계와 개선점
아직 부족한 부분들:
- GitHub 외 Git 호스팅: GitLab, Bitbucket 지원 필요
- 실시간 동기화: Webhook으로 자동 업데이트
- 팀 포트폴리오: 개인뿐만 아니라 팀 단위 리포트
- LLM 비용: OpenAI API 사용량이 많아지면 비용 문제
- 커밋 분석 고도화: 코드 품질, 기여도 분석 추가
7. 배운 것
"자동화가 답이다. 귀찮은 일은 코드가 대신하게 만들자."
- 비동기 처리의 중요성:
httpx+async/await로 API 호출 속도 10배 향상 - LLM 프롬프트 엔지니어링: README만으론 부족하고, 커밋 히스토리 + 사용자 스타일까지 학습시켜야 퀄리티 나옴
- 데이터 일관성: 같은 지표를 여러 곳에서 보여줄 때는 계산 로직을 통일해야 함
- 외부 API의 함정: 문서만 보지 말고 실제 응답을 확인해야 함 (GitHub의
affiliation파라미터처럼) - UX 디테일: 다크모드, PDF 내보내기 같은 작은 기능이 사용자 경험을 크게 바꿈
다음엔 이 경험을 바탕으로 더 많은 플랫폼을 지원하고, 팀 단위 리포트까지 만들어보고 싶다. 일단 이 정도면 개인 포트폴리오 자동화는 완성이다.
GitHub: DevHistory
Tech Stack: FastAPI, Next.js, PostgreSQL, Celery+Redis, OpenAI API, Docker
