
"이론으로만 듣던 알고리즘들이 게임 속에서 살아 움직인다면?"
로봇알고리즘 수업에서 배운 Path-Planning 알고리즘들을 적 AI로 구현한 교육용 액션 게임을 만들었습니다.
📌 목차
1. 왜 이 게임을 만들었나
로봇알고리즘 수업에서 Path-Planning 알고리즘들(Bug, APF, PRM, RRT 등)을 배우면서 항상 궁금했습니다.
"이 알고리즘들이 실제로는 어떻게 움직이는 거지?"
슬라이드 속 점선 화살표와 수식들을 보면서도, 실제 로봇의 움직임이 머릿속에 그려지지 않았습니다. 특히 APF의 Local Minimum, PRM의 그래프 구축, Belief Filter의 확률 분포 같은 개념들은 이론만으로는 체감이 어려웠죠.
그러다 문득 이런 생각이 들었습니다:
"이 알고리즘들이 적 AI로 나오는 게임을 만들면 어떨까?"
각 알고리즘의 강점과 약점을 직접 체험할 수 있고, 게임을 플레이하면서 자연스럽게 학습할 수 있을 것 같았습니다. 처음엔 Bug1/Bug2 정도만 구현하려고 했는데, 하다 보니 욕심이 생겨서 결국 7가지 알고리즘을 전부 넣게 되었습니다.
그리고 단순히 움직이기만 하는 게 아니라, PRM의 그래프, RRT의 트리, Belief의 확률 분포까지 실시간으로 시각화하면서 진짜 "알고리즘이 어떻게 생각하는지" 볼 수 있는 게임이 완성되었습니다.
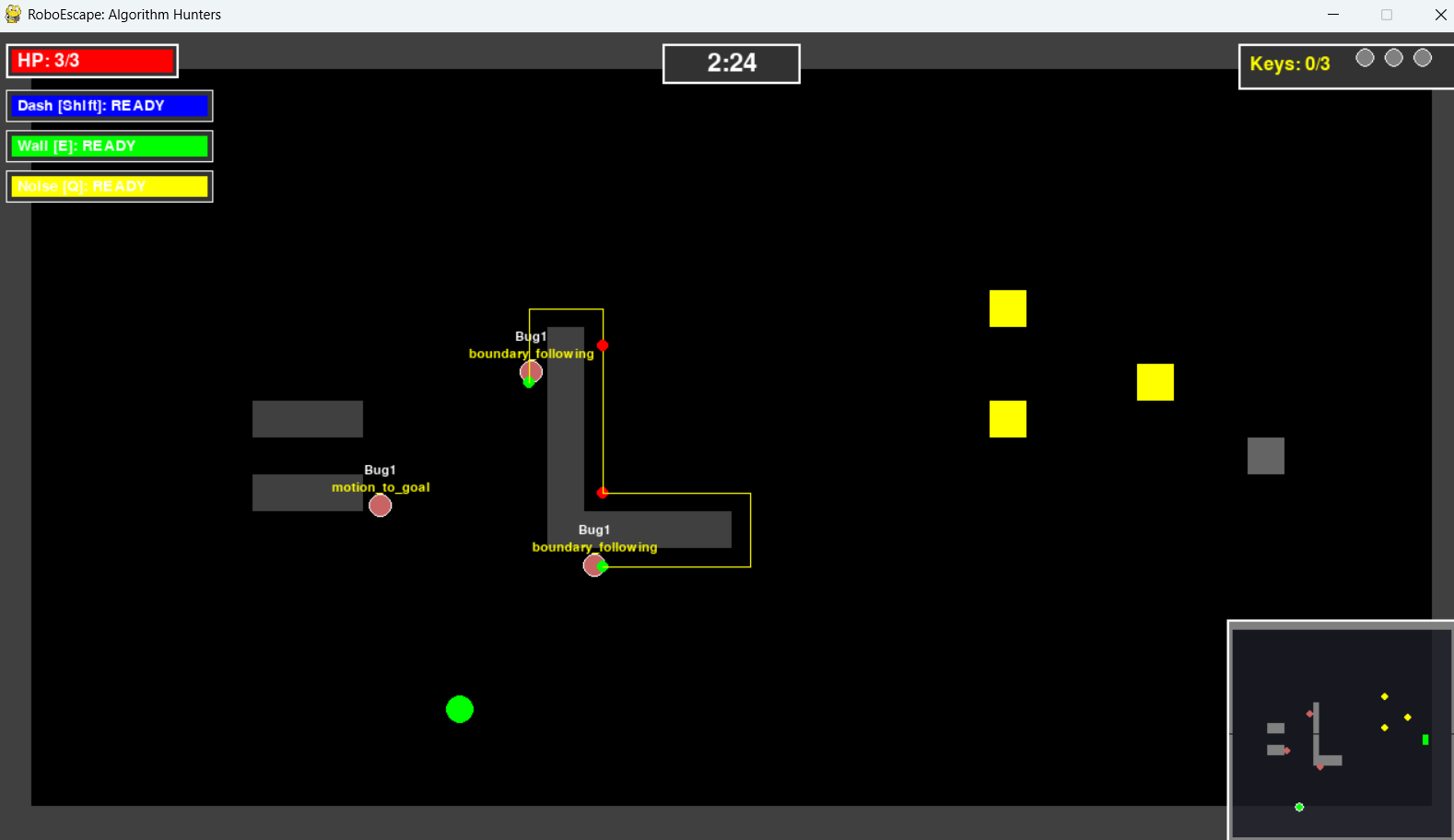
Stage 1: 튜토리얼 - Bug1 알고리즘
2. 해결하고자 한 문제
Path-Planning을 공부하는 학생들이 흔히 겪는 문제들을 정리해봤습니다:
🎯 문제 인식
| 문제 | 설명 |
|---|---|
| 이론과 실제의 괴리 | 슬라이드 속 알고리즘과 실제 동작이 연결되지 않음 |
| 약점 체감 불가 | APF가 왜 Local Minimum에 빠지는지 말로만 들어서는 와닿지 않음 |
| 비교 어려움 | Bug1 vs Bug2 vs Tangent Bug의 차이를 직접 비교하기 어려움 |
| 지루한 학습 | 논문과 교과서만으로는 흥미 유지가 힘듦 |
🎮 솔루션
목표: 7가지 Path-Planning 알고리즘이 적 AI로 등장하고, 플레이어가 각 알고리즘의 약점을 이용해 생존하는 게임을 만들기. 단순한 게임이 아니라, 알고리즘의 내부 상태를 실시간으로 시각화해서 학습 효과를 극대화하는 것이 핵심이었습니다.
3. 기술 스택과 아키텍처
🛠 기술 스택 선택
게임 엔진: Pygame 2.5.0
- Python 기반이라 알고리즘 구현과 통합이 쉬움
- 2D 게임에 최적화되어 있고 러닝 커브가 낮음
- 실시간 렌더링, 이벤트 처리, 충돌 감지 기능 내장
수치 연산: NumPy 1.24.0 + SciPy 1.10.0
- 그리드맵 연산 (장애물 체크, 경로 탐색)
- Belief Filter의 확률 분포 계산
- 벡터 연산 최적화 및 거리 계산 (KDTree)
💡 왜 Unity/Unreal이 아니라 Pygame인가?
이 프로젝트에서는 알고리즘 구현이 메인이고 게임은 시각화 수단입니다. Python으로 알고리즘을 짜고 바로 게임에 통합할 수 있다는 점이 가장 큰 장점이었습니다.
🏗 아키텍처 설계
주요 디자인 패턴:
├── Entity-Component System
│ └── 모든 적은 EnemyBase 클래스 상속
│
├── Strategy Pattern
│ └── 각 알고리즘은 독립된 Planner 클래스로 분리
│
├── State Machine
│ └── MENU → PLAYING → STAGE_CLEAR → GAME_OVER
│
└── Observer Pattern
└── 파티클 시스템이 게임 이벤트에 반응4. 구현 여정
4.1 Bug Algorithms – 첫 번째 적 구현
가장 먼저 Bug1을 구현했습니다. "벽을 만나면 한 바퀴 돌면서 목표에 가장 가까운 점을 찾는다"는 원리는 간단했지만, 막상 코드로 옮기니 상태 관리가 생각보다 복잡했습니다.
버전별 개선 과정:
- V1.0: 벽을 따라가다가 목표 방향으로 바로 돌아감 → 로직 오류 발견
- V1.1: 한 바퀴 완전히 돌 때까지 leave 포인트를 기록하지 않음 → 제대로 동작
- V1.2: 같은 벽을 계속 도는 무한루프 발생 → hit point 기록으로 해결
# algos/bug.py - Bug1Planner 핵심 로직
class Bug1Planner:
def __init__(self):
self.state = 'motion_to_goal'
self.hit_point = None
self.leave_point = None
self.min_distance = float('inf')
def plan_step(self, current, goal, grid_map):
if self.state == 'motion_to_goal':
# 목표로 직진
next_pos = self._move_towards(current, goal)
if self._is_collision(next_pos, grid_map):
self.hit_point = current
self.state = 'boundary_following'
self.min_distance = distance(current, goal)
elif self.state == 'boundary_following':
next_pos = self._follow_wall(current, goal, grid_map)
dist = distance(next_pos, goal)
if dist < self.min_distance:
self.min_distance = dist
self.leave_point = next_pos
# 한 바퀴 완전히 돌고 목표로 복귀 가능하면
if self._circumnavigation_complete():
self.state = 'motion_to_goal'
return self.leave_pointBug2와 Tangent Bug도 유사한 구조로 구현했습니다:
- Bug2: M-line(시작-목표 직선) 거리 기반 의사결정
- Tangent Bug: 센서 범위 내 장애물의 접선 방향 활용
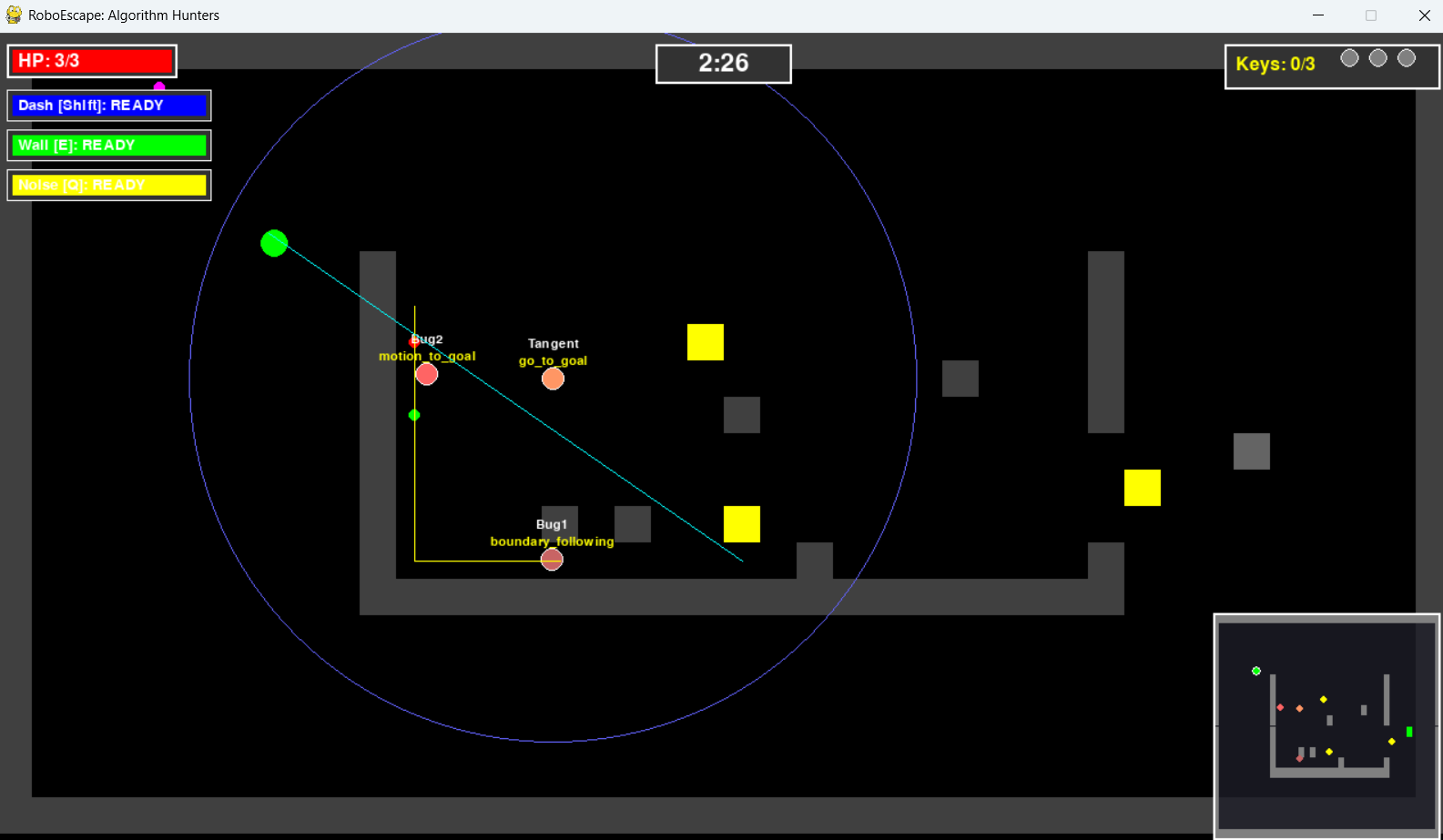
Stage 2: Bug1, Bug2, Tangent Bug의 서로 다른 움직임 패턴 비교
4.2 APF와 Local Minimum의 시각화
APF(Artificial Potential Field)는 원리가 직관적합니다. 목표는 자석처럼 끌어당기고, 장애물은 밀어냅니다. 하지만 U자나 O자 구조에서는 힘의 합이 0이 되어 꼼짝 못 하게 됩니다.
처음엔 단순히 force만 계산했는데, 게임에서 APF 적이 갇혀도 플레이어가 그걸 모르면 의미가 없었습니다. 그래서 Local Minimum 감지 기능을 추가했습니다.
# algos/apf.py - Local Minimum 감지
class APFPlanner:
def __init__(self):
self.force_history = []
self.stuck_counter = 0
def detect_local_minimum(self, window=5, threshold=10.0):
"""최근 5 스텝의 force 크기가 모두 작으면 갇힌 것"""
if len(self.force_history) < window:
return False
recent_forces = self.force_history[-window:]
avg_force = sum(np.linalg.norm(f) for f in recent_forces) / window
return avg_force < threshold
def plan_step(self, current, goal, grid_map):
# 인력 계산
attractive_force = self.k_att * (goal - current)
# 척력 계산 (주변 장애물에서)
repulsive_force = np.zeros(2)
for obstacle in self._get_nearby_obstacles(current, grid_map):
dist = distance(current, obstacle)
if dist < self.d_influence:
direction = (current - obstacle) / dist
repulsive_force += self.k_rep * (1/dist - 1/self.d_influence) * (1/dist**2) * direction
total_force = attractive_force + repulsive_force
self.force_history.append(total_force)
# Local Minimum 감지
if self.detect_local_minimum():
self.stuck_counter += 1
# 랜덤 워크로 탈출 시도
return current + random_direction() * 0.5
return current + total_force * dt게임에서 APF 적이 U자 구조에 갇히면 적이 제자리에서 떨거나 느린 속도로 움직이는 모습이 보입니다. 이것이 바로 Local Minimum이 발생한 순간이고, 플레이어는 이 타이밍을 노려서 안전하게 다른 열쇠를 수집할 수 있습니다.
💡 핵심 인사이트
"이론으로만 듣던 Local Minimum을 게임에서 직접 만들고 활용하니까, 알고리즘의 약점이 체감으로 와닿았습니다."
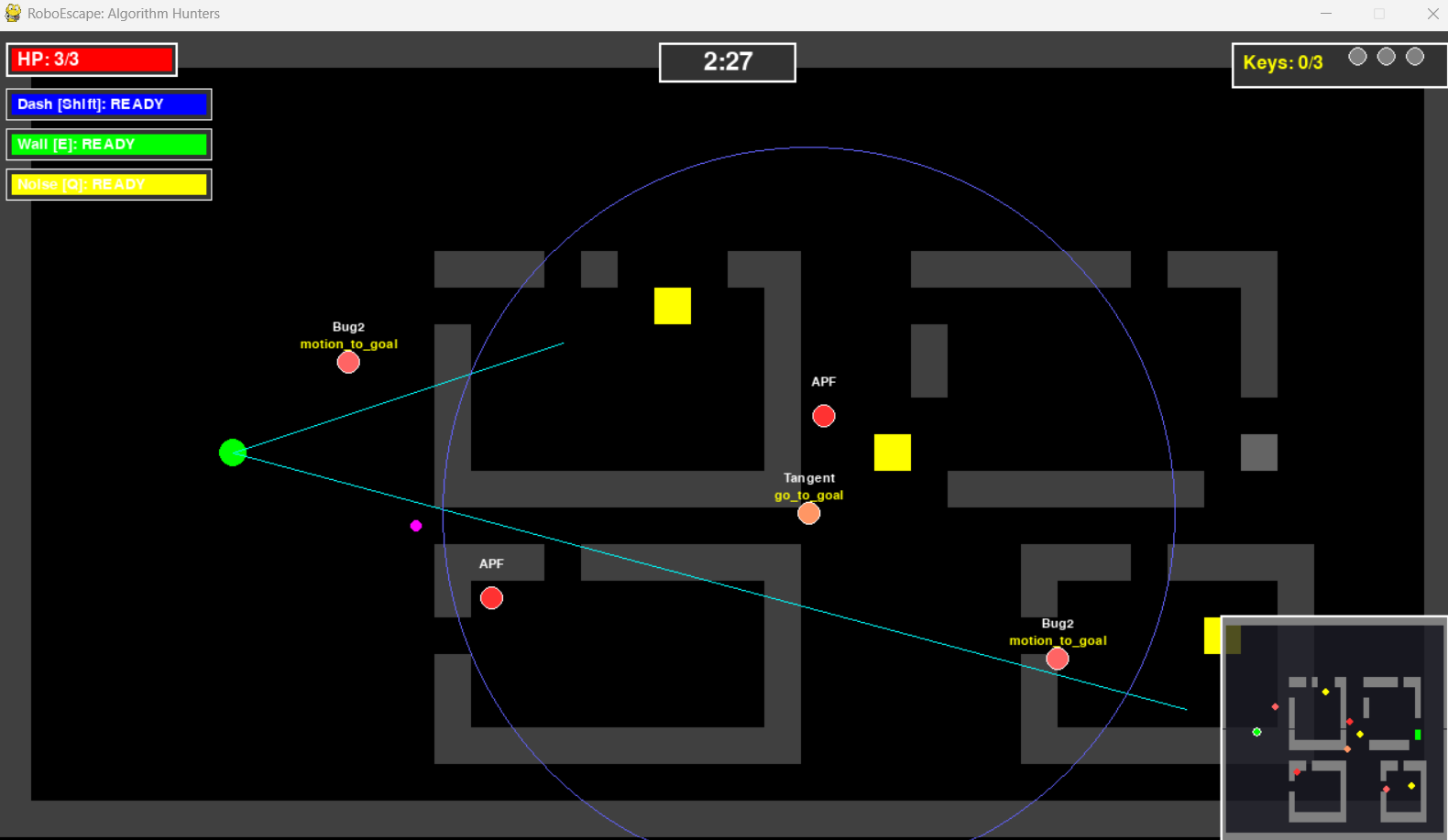
Stage 3: APF 적들을 U자 함정에 가두는 전략
4.3 PRM과 RRT의 실시간 시각화
PRM(Probabilistic Roadmap)과 RRT(Rapidly-exploring Random Tree)는 샘플링 기반 알고리즘입니다. 단순히 "점 찍고 경로 찾기"로만 구현하면 재미가 없습니다. 그래프와 트리가 어떻게 생성되는지 보여줘야 합니다.
PRM 구현 과정:
- 맵 전체에 150개 랜덤 노드 샘플링
- 각 노드에서 반경 10 타일 이내의 노드들과 연결 시도
- 충돌 체크 (직선 경로에 장애물 없는지 확인)
- A* 알고리즘으로 최단 경로 탐색
# algos/prm.py - PRM Planner
class PRMPlanner:
def __init__(self, num_samples=150, radius=10.0):
self.nodes = []
self.edges = []
self.graph = {}
self.is_built = False
def build_roadmap(self, grid_map):
"""로드맵 사전 구축"""
# 1. 랜덤 샘플링 (장애물 제외)
grid_h, grid_w = grid_map.shape
while len(self.nodes) < self.num_samples:
x = random.randint(1, grid_w - 2)
y = random.randint(1, grid_h - 2)
if grid_map[y][x] == 0: # 빈 공간
self.nodes.append((x, y))
# 2. 엣지 연결 (KDTree로 가까운 노드 찾기)
from scipy.spatial import KDTree
tree = KDTree(self.nodes)
for node in self.nodes:
# 반경 내 이웃 노드 찾기
indices = tree.query_ball_point(node, self.radius)
for idx in indices:
neighbor = self.nodes[idx]
if self._is_collision_free(node, neighbor, grid_map):
self.edges.append((node, neighbor))
if node not in self.graph:
self.graph[node] = []
self.graph[node].append(neighbor)
self.is_built = TrueRRT는 다릅니다. PRM은 사전에 맵을 구축하지만, RRT는 매번 새로운 트리를 성장시킵니다. 시작점에서 출발해서 랜덤하게 가지를 뻗어나가면서 목표에 도달하는 방식입니다.
시각화의 핵심: game/enemies/prm_rrt.py에서 그래프와 트리를 실시간으로 그려줍니다. 처음엔 밝은 색으로 했더니 눈이 아파서, 어두운 회색 + 낮은 투명도로 변경해서 배경처럼 은은하게 보이도록 했습니다.
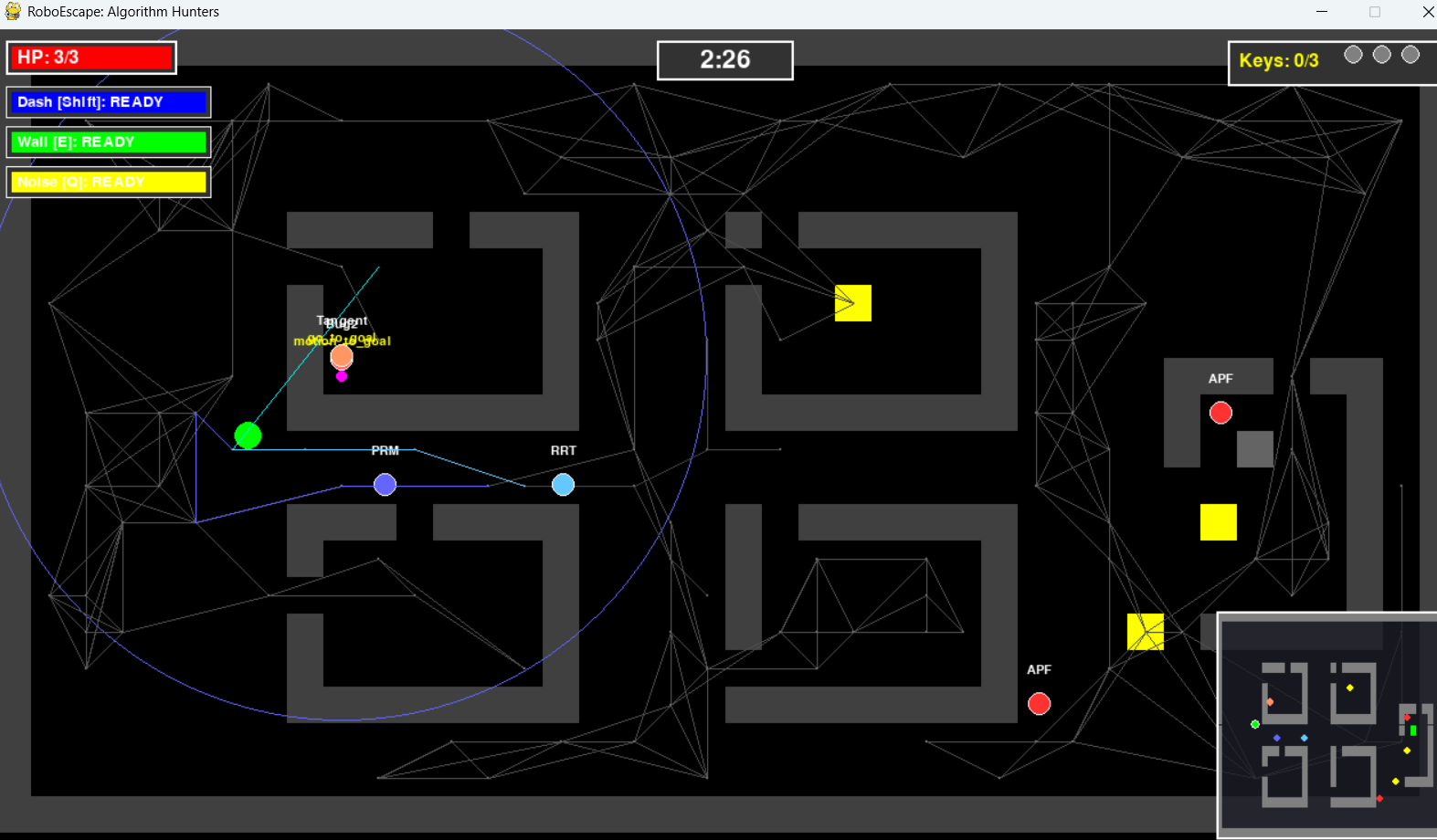
Stage 4: PRM의 파란 그래프와 RRT의 하늘색 트리가 실시간으로 보입니다
4.4 Belief Filter와 확률 분포 히트맵
Belief Filter는 센서 노이즈 속에서 플레이어의 위치를 추정하는 알고리즘입니다. Prediction (모션 모델) + Update (센서 관측)을 반복합니다.
처음엔 Kalman Filter를 사용하려 했으나, 비선형 환경에서는 Particle Filter나 Histogram Filter가 더 적합하다는 것을 알게 되어 Grid-based Belief Filter로 구현했습니다.
# algos/belief.py - Belief Filter
class BeliefPlanner:
def __init__(self, grid_resolution=4, sensor_range=300.0):
self.resolution = grid_resolution # 4x4 타일당 1개 belief cell
self.belief = None # 확률 분포 (2D numpy array)
self.sensor_range = sensor_range
def initialize_belief(self, grid_map):
"""uniform 분포로 초기화"""
h, w = grid_map.shape
belief_h = h // self.resolution
belief_w = w // self.resolution
self.belief = np.ones((belief_h, belief_w)) / (belief_h * belief_w)
def predict(self, motion):
"""Prediction step - 이전 위치 기반 확률 전파"""
from scipy.ndimage import gaussian_filter
self.belief = gaussian_filter(self.belief, sigma=1.0)
self.belief /= np.sum(self.belief) # 정규화
def update(self, measurement, grid_map, enemy_pos):
"""Update step - 센서 관측으로 belief 갱신"""
h, w = self.belief.shape
for y in range(h):
for x in range(w):
cell_world = self._belief_to_world(x, y)
# 센서 관측과의 거리
dist = distance(cell_world, measurement)
# 가우시안 likelihood
likelihood = np.exp(-dist**2 / (2 * self.sensor_noise**2))
# Belief 업데이트
self.belief[y, x] *= likelihood
# 정규화
total = np.sum(self.belief)
if total > 0:
self.belief /= total노이즈 폭탄 스킬: 플레이어가 Q키를 누르면 Belief 적의 센서에 큰 노이즈를 추가합니다. 그러면 belief 분포가 엉뚱한 곳으로 퍼지면서 적이 잘못된 위치로 이동합니다.
히트맵 시각화: Belief 적 뒤에 확률 분포를 색상으로 표현합니다. 확률이 높은 곳은 더 진하게, 낮은 곳은 투명하게 표시됩니다.
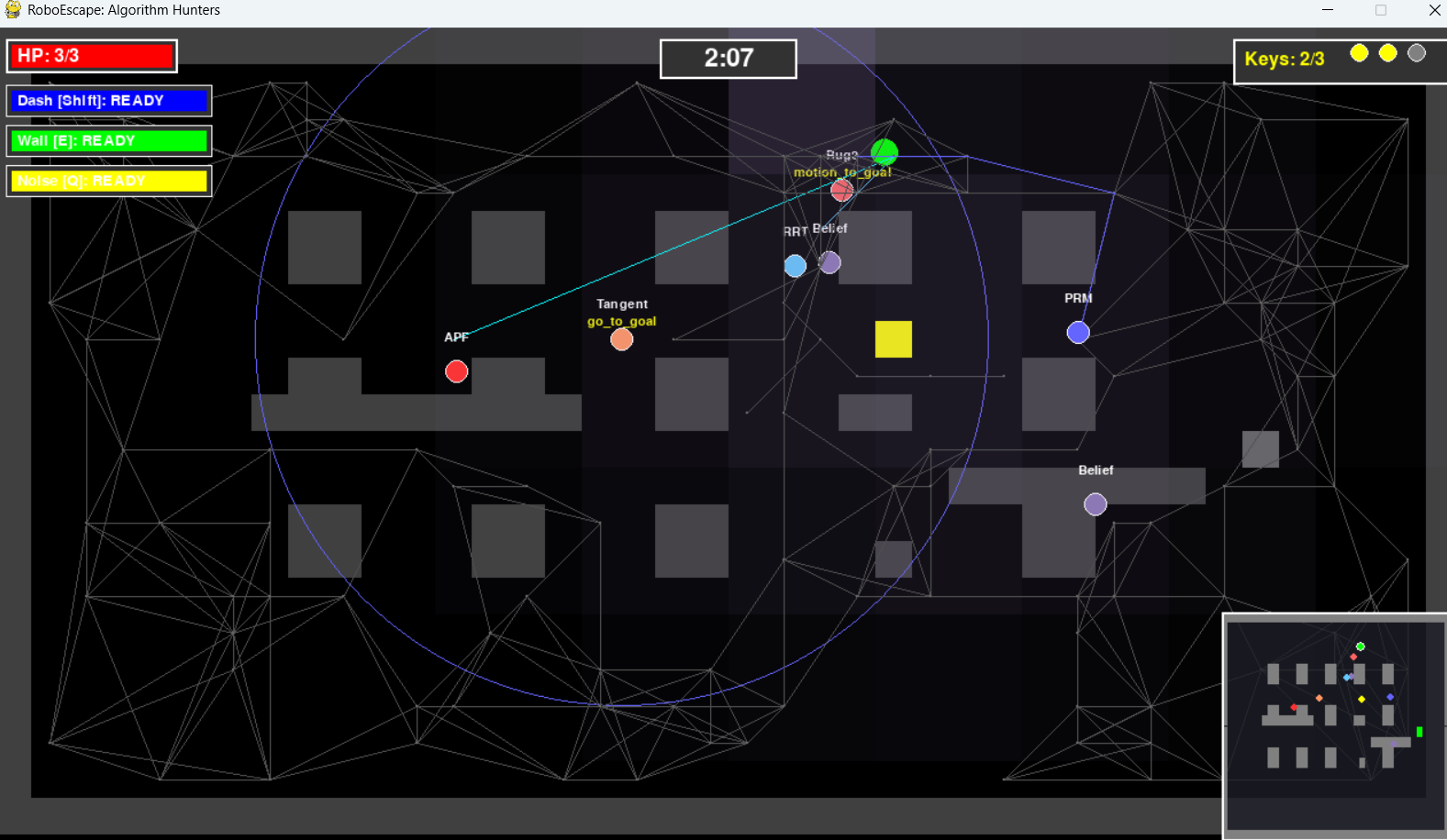
Stage 5: Belief 적의 확률 분포 히트맵 - 청보라색 영역이 플레이어를 추적하는 모습
4.5 스테이지 설계와 난이도 밸런싱
7가지 알고리즘을 모두 구현했으니, 이제 각 알고리즘의 특성을 살린 스테이지를 만들어야 했습니다.
🎮 스테이지 구성 전략
| Stage | 테마 | 등장 알고리즘 | 학습 목표 | 난이도 |
|---|---|---|---|---|
| 1 | 튜토리얼 | Bug1 × 3 | 기본 조작과 Bug1 패턴 학습 | ⭐ |
| 2 | 패턴 학습 | Bug1, Bug2, Tangent | 각 Bug 알고리즘의 차이 비교 | ⭐⭐ |
| 3 | Local Minimum | Bug2, APF × 2, Tangent | APF의 약점 활용 (U자 함정) | ⭐⭐⭐ |
| 4 | 그래프 차단 | Tangent, PRM, RRT, APF × 2 | 샘플링 알고리즘 대응 | ⭐⭐⭐⭐ |
| 5 | 확률 전쟁 | Bug2, Tangent, APF, Belief × 2, RRT, PRM | Belief Filter 교란 전략 | ⭐⭐⭐⭐⭐ |
| 6 | 보스전 | 전 알고리즘 8마리 | 모든 스킬 총동원 | ⭐⭐⭐⭐⭐⭐ |
난이도 밸런싱 패치
처음엔 적 속도를 낮게 설정했더니 너무 쉬웠습니다. 여러 차례 플레이테스트를 거쳐 다음과 같이 조정했습니다:
- 플레이어 속도: 200 → 180
- APF 속도: 120 → 135
- 스킬 쿨타임: 전부 20% 증가
- 타임 리밋: 180초 → 150초
4.6 UI/UX 디테일과 파티클 시스템
게임의 완성도를 높이기 위해 다양한 시각적 요소들을 추가했습니다.
화면 구성:
- HUD (좌상단): HP, 스킬 쿨타임, 타이머, 열쇠 개수
- 미니맵 (우하단): 전체 맵과 적 위치 표시
- 파티클 효과: 대시, 충돌, 열쇠 획득 시 이펙트
- 알고리즘 시각화: PRM 그래프, RRT 트리, Belief 히트맵
개선 과정:
- 시각화 색상 문제: 샘플링 시각화가 너무 눈에 띄어서 게임플레이를 방해 → 색상을 어두운 회색으로, 투명도를 40~60으로 낮춤
- 동적 맵 변화: 벽을 세우면 PRM/RRT가 오작동 → 임시 벽 개수 변화 감지해서 자동 재계획
- 아이템 접근성: 열쇠가 벽 안에 갇혀 있는 경우 → 열쇠/출구 주변 3×3 영역 강제 클리어
5. 마주했던 기술적 도전들
5.1 PRM 로드맵 재구축 타이밍
문제: 처음엔 PRM이 맵을 한 번만 구축하고 끝이었습니다. 플레이어가 벽을 설치해도(E키 스킬) 그래프가 업데이트되지 않아 벽을 통과하는 경로를 찾는 문제가 발생했습니다.
해결: 임시 벽 개수 변화를 감지하여 자동으로 재구축하도록 구현했습니다.
# game/enemies/prm_rrt.py
def check_map_changed(self, level):
"""맵 변경 감지"""
current_count = len(level.temp_walls)
if current_count != self.last_temp_wall_count:
self.last_temp_wall_count = current_count
return True
return False5.2 Belief 히트맵 색상 최적화
문제: 처음엔 밝은 보라색 (200, 100, 255)로 했는데, 확률 분포가 넓게 퍼지면 화면 전체가 보라색이 되어 눈이 아팠습니다.
해결:
- 색상: (200, 100, 255) → (140, 120, 180) 부드러운 청보라색
- 투명도: 150 → 50 (1/3로 감소)
5.3 스폰 위치 갇힘 문제
문제: Stage 3에서 시작하자마자 플레이어가 벽에 갇혀 있는 경우가 발생했습니다. 맵 생성 시 스폰 위치를 고려하지 않았던 것이 원인이었습니다.
해결: 스폰 위치 주변 3×3 영역을 강제로 비워줬습니다.
# game/level.py
self.spawn_pos = (5, GRID_HEIGHT // 2)
# 스폰 지역 주변 클리어
for dy in range(-1, 2):
for dx in range(-1, 2):
sx, sy = self.spawn_pos[0] + dx, self.spawn_pos[1] + dy
if 0 < sx < GRID_WIDTH - 1 and 0 < sy < GRID_HEIGHT - 1:
self.grid_map[sy][sx] = TILE_EMPTY5.4 대각선 이동 속도 문제
문제: WASD로 대각선 이동하면 √2배 빨라지는 문제가 있었습니다. 벡터를 정규화하지 않았던 것이 원인이었습니다.
해결:
# game/player.py
velocity = np.array([dx, dy])
if np.linalg.norm(velocity) > 0:
velocity = velocity / np.linalg.norm(velocity) * PLAYER_SPEED6. 결과와 배운 점
✨ 완성된 기능
- ✅ 7가지 알고리즘 (Bug1/2/Tangent, APF, PRM, RRT, Belief)
- ✅ 6개 스테이지 + 보스전 + 무한 모드
- ✅ 실시간 시각화 (PRM 그래프, RRT 트리, Belief 히트맵)
- ✅ 스킬 시스템 (대시, 벽, 노이즈, 슬로우모션)
- ✅ 파티클 효과 (대시 잔상, 충돌 이펙트)
- ✅ 사운드 시스템 (효과음, 옵션)
- ✅ 완전한 UI (HUD, 미니맵, 게임오버 화면)
- ✅ 5종 문서화 (README, QUICKSTART, GAME, STAGE, DEVELOPMENT)
🚀 향후 개선 방향
현재 프로젝트에서 아쉬운 부분들과 향후 추가하고 싶은 기능들입니다:
- 알고리즘 확장:
D* Lite,Hybrid A*같은 고급 알고리즘 추가 - 멀티플레이어: 협동 모드로 함께 플레이
- 커스텀 맵: 사용자가 직접 맵 에디터로 스테이지 제작
- 애니메이션 개선: 스프라이트 아트로 더 세련된 비주얼
- 모바일 포팅: 터치 조작 지원
- 강화학습 AI: 기존 알고리즘 외에 학습된 AI 적 추가
📚 배운 것들
이론을 게임으로 만들면, 학습이 놀이가 된다.
이 프로젝트를 통해 얻은 인사이트들입니다:
- 알고리즘 구현의 실제: 논문 속 수식과 실제 코드 사이의 간극을 메우는 과정
- 시각화의 힘: 그래프와 트리를 보여주니 알고리즘이 "무슨 생각"을 하는지 직관적으로 이해됨
- 밸런싱의 중요성: 게임이 너무 쉬우면 학습 효과가 없고, 너무 어려우면 포기하게 됨
- UX 디테일: 눈 피로도, 색상, 투명도 같은 작은 요소가 전체 경험을 좌우함
- 교육용 게임 설계: 재미와 학습의 균형, 점진적 난이도 증가, 실패에서 배우기
다음에는 이 경험을 바탕으로 다른 CS 주제(정렬 알고리즘, 그래프 탐색, 동적 프로그래밍)도 게임으로 만들어보고 싶습니다.
📎 프로젝트 정보
GitHub: RoboEscape: Algorithm Hunters
Tech Stack: Pygame, NumPy, SciPy, Python 3.8+
Play Time: 스테이지 1-6 클리어까지 약 5~10분
License: MIT
Made with 💜 for Robotics & Game Development Education
긴 글 읽어주셔서 감사합니다! 궁금한 점이나 피드백이 있으시다면 댓글로 남겨주세요. 🙏
