
파이썬에서 리스트(List)는 정말 정말 정말 편리하고 장점이 많아 자주 사용된다.
하지만 편리함과 반비례하여 리스트는 여러모로 성능이 좋은편이 아니다.
이번 블로그에서 리스트대신 yield를 사용하여 성능 개선을 이루고자 한다.
리스트가 뭐에요?
리스트란 동적으로 크기가 조정될 수 있는 요소의 컬렉션(Collection)이다.
이 말인 즉슨, 요소를 추가하거나 제거함에 따라 자동으로 크기가 조절되므로 배열(Array)처럼 우리가 크기를 고려하지 않아도 된다는 장점이 있다.
더불어 다양한 타입의 요소들을 저장할 수 있다는 아주 큰 장점도 있다.
파이썬에서는 리스트는 아래 그림처럼 구성되어 있다.
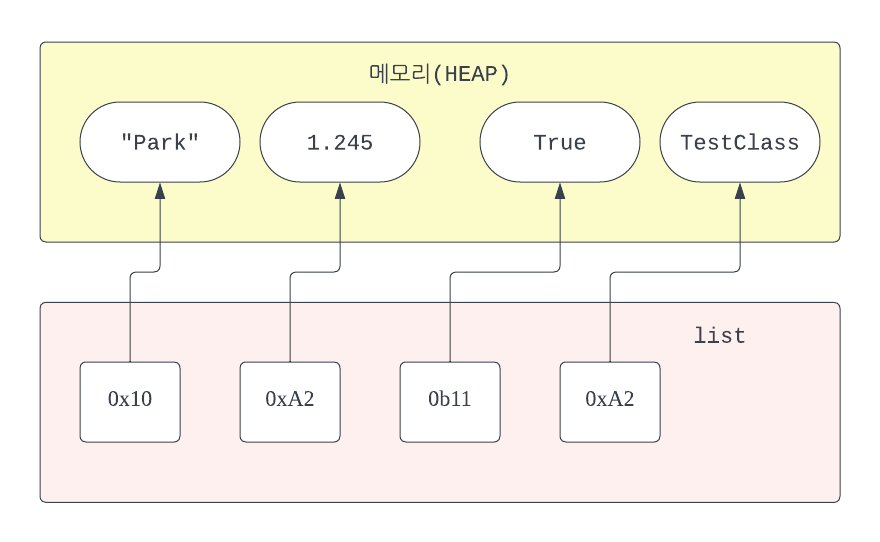
파이썬 리스트의 각 요소들은 각각 메모리에 할당되며 리스트는 해당 요소들의 주소값을 모아놓은 컬렉션이다.(물론 list 인스턴스 자체도 메모리에 할당된다)
파이썬에서의 리스트 구현은 동적 배열(dynamic array)로 구현이 되어있기 때문에, 요소에 대한 인덱스 접근의 시간복잡도가 O(1)으로 굉장히 빠르다는 장점도 있다.
이렇듯 장점이 많아 보이는 리스트이지만 위에서도 말했듯이 리스트의 요소들은 각각 메모리에 할당이 되므로 요소의 크기가 커지거나 많아진다면 메모리 사용량이 급증하는 경우가 발생한다.
메모리 사용량이 임계치를 넘게되면 결국 해당 서버는 뻗게되는 치명적인 상황에 놓일 수 있다.
리스트를 이용하여 순차적으로 작업을 처리하고 싶지만 메모리 사용량이 걱정이 된다면 yield가 아주 좋은 해결책이 될 수 있다.
yield는 또 뭐야?
파이썬에서 yield는 제너레이터(Generator)를 생성하기 위해 사용되는 키워드이다.
제너레이터는 반복자(iterator)의 한 종류로, 데이터를 한번에 메모리에 로드하지 않고 필요할 때마다 데이터를 하나씩 생성하여 반환할 수 있는 큰 장점이 있다.
-
yield의 동작 방식
함수 내에서 yield를 사용하면, 해당 함수는 제너레이터 함수가 된다.
제너레이터 함수가 호출되면, 함수가 실행되는 대신에 제너레이터 객체를 반환한다. 반환된 제너레이터 객체를 통하여 next() 함수를 호출하면 함수의 실행이 yield 표현식까지 진행이 되고, yield의 값이 반환된다.
다음 next()를 호출하면 함수는 마지막으로 실행이 멈췄던 yield 키워드 다음부터 실행을 재개한다.
만약 더 이상 반환할 yield의 값이 없을경우 StopIteration Exception이 발생한다.def test_yield(): for i in range(3): yield i print(f"{i}번째 끝나고 실행됨") return "끝!" gen_ = test_yield() print(next(gen_)) # 첫번째 yield 값(0)이 return print(next(gen_)) # 마지막 yield 다음부분인 print(0번째 끝나고 실행됨)이 실행된 후 다음 yield 값(1)이 return print(next(gen_)) # 마지막 yield 다음부분인 print(1번째 끝나고 실행됨)이 실행된 후 다음 yield 값(2)이 return try: print(next(gen_)) # 마지막 yield 다음부분인 print(2번째 끝나고 실행됨)이 실행된 후 다음 yield값이 없으므로 StopIteration Exception 발생 except StopIteration as e: print(e.value) # return으로 지정한 '끝!' 리턴됨
위의 예제를 보면
- test_yield 함수는 yield 키워드가 있으므로 함수를 실행하면 제너레이터 객체를 반환한다.
- 반환된 제너레이터 클래스의 인스턴스를 이용해 처음으로 next() 함수를 호출하면 yield 전까지 함수가 실행이 되고 yield 값을 return 한다.
- next() 함수를 한번 더 호출하면 yield 다음부분인 print함수가 실행이 되고 다음 yield가 return이 된다.
- 계속 next()를 호출하다 더이상 return할 yield값이 없으면 StopIteration Exception이 발생하고 함수내 return 키워드로 선언한 값이 Exception의 value로 할당된다.
그래서 리스트 대신 yield를 사용하면 뭐가 좋은데?
위에서도 말했듯이 리스트는 요소들마다 메모리에 할당이 되어 메모리 사용량이 상대적으로 많고, yield는 필요시에만 데이터를 하나씩 생성하여 반환하기 때문에 메모리 사용량이 훨씬 적다.
코드로 비교를 해보자!
아래 코드는 정수값 N을 입력받으면 0부터 N-1까지 숫자의 제곱을 계산하여 저장하는 방법을 리스트와 yield로 구현한 함수들이다.
from memory_profiler import profile
def squares_list(N):
squares = [i**2 for i in range(N)]
return squares
def squares_yield(N):
for i in range(N):
yield i**2
@profile()
def check_():
list_ = squares_list(N)
yield_ = squares_yield(N)
for i in range(5):
print(f"list: {list_[i]}, yield: {next(yield_)}")
N = 10000000
if __name__ == "__main__":
check_()함수를 실행 후 메모리 사용량은 다음과 같다.
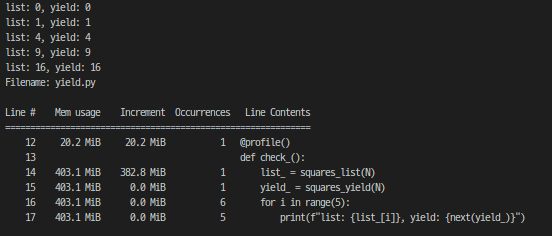
차이가 보이는가?
list방식은 382.8MiB 메모리를 사용하는 반면, yield는 0.0MiB이다!(정확하게는 next()함수에서 정수가 return 되므로 4byte를 사용하긴 한다.)
이처럼 순차적으로 데이터를 처리해야 할 경우 yield를 사용하면 메모리 사용량을 크게 줄일 수 있다.
실제 적용기
입력받은 파일의 byte를 탐색하여 실제 파일의 확장자를 체크하고, 지원하지 않는 확장자는 에러를 응답하는 로직이 있다.
이전에는 입력받은 파일을 전체를 읽고 byte를 탐색하여 메모리도 많이 잡아먹었고, 만약 유효하지 않은 타입의 파일이였다면 불필요하게 파일을 전체 읽는 시간도 낭비가 되었다.
이걸 yield문으로 변경하여 메모리 사용량을 대폭 줄일 수 있었다.
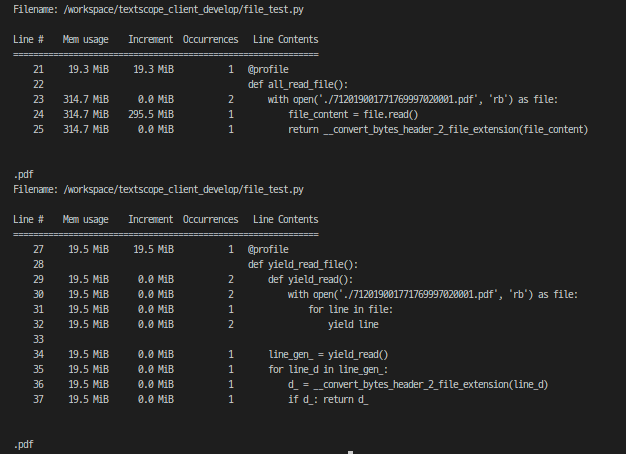
309.7MB 파일을 기준으로 기존 파일을 다 읽는 방식은 295.5MB까지 메모리 사용량이 증가하지만, yield로 메모리 사용량이 0.0이 되었다!
