
반복된 작업은 yield를 사용해보자!에 이어 이번에는 list에 대해 조금 더 자세하게 파보려 한다.
제목에도 말했듯이 파이썬의 list 자료형은 성능이 좋지 않은편이다.
그냥 쉽게 생각해서 편리성과 성능을 등가교환 했다고 생각하자.

추가로, 이전글과 앞으로 파이썬에 관한 글들은 다 CPython을 기준으로 한다.
다른 파이썬 구현체(eg.pypy 등..)은 다를 수 있다는점 명시하자!
64bit 운영체제를 조건으로 한다.
리스트는 어떻게 동작할까?
이전 포스팅에서 리스트는 포인터들의 배열이라고 하였다.
그럼 리스트는 어떻게 동작하길래 포인터들의 배열구조를 가지는 것일까?
파이썬에서 정수형 객체를 담는 리스트를 예시로 이미지와 함께 설명해보겠다.
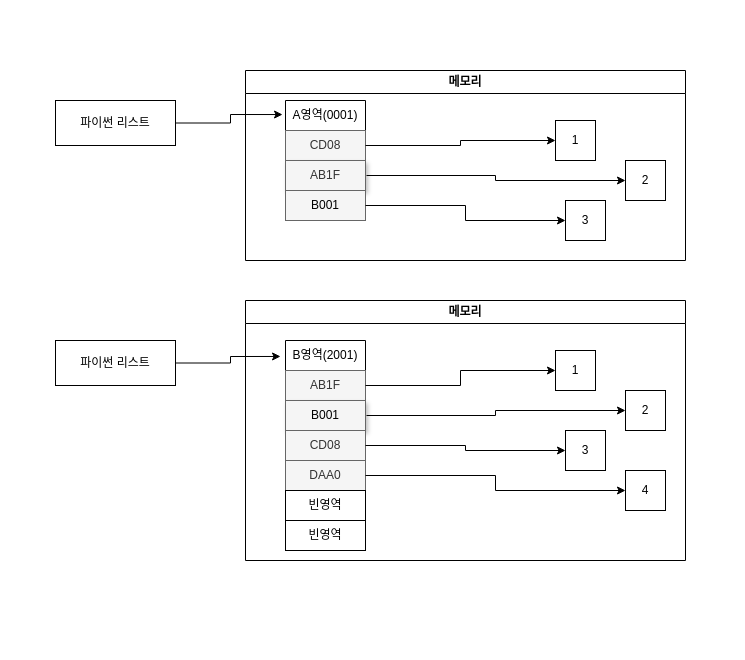
위의 이미지를 토대로 동작 방식을 설명하면 다음과 같다.
- 먼저 파이썬 리스트를 생성하면 포인터들을 담을 메모리(A영역)를 할당 받는다. 이 영역에서 포인터들은 연속된 메모리 주소를 사용한다.
- 정수형 클래스를 생성하면 A영역을 제외한 메모리를 할당 받고 해당 값을 리스트에 append하면 포인터가 A영역의 마지막 index에 추가된다.
- 만약 할당된 메모리의 크기 이상으로 리스트에 요소를 추가하게 된다면 이전 메모리 크기보다 조금 더 큰 새로운 메모리(B영역)를 할당받고, A영역에 있던 요소들을 B영역으로 복사한다. 이 과정에서 오버헤드가 발생한다.
파이썬의 동작 방식을 살펴보았다.
그럼 이런 동작 방식이 어떻게 구현이 되었는지 CPython의 코드로 확인해보자.
먼저 리스트의 구조체인 PyListObject부터 살펴보자
PyListObject
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;먼저 PyObject **ob_item;에 대해 살펴보자.
PyObject타입 데이터의 포인터에 대한 포인터 즉 이중 포인터이다.
주석을 보면 벡터(Vector)라고 하는데, C에서는 벡터 자료구조가 없다.
이후에 볼 수 있겟지만, 벡터를 구현해서 사용을 하였다.
간략하게 벡터의 특징을 살펴보면
- 요소에 대한 접근이 빠르다.(시간복잡도 O(1))
- 메모리 블록(메모리의 연속된 일정 크기의 영역)을 할당받는다.
- 이로 인해 공간적 지역성이 높아진다.
- 자동으로 크기를 늘릴 수 있다
- 할당된 메모리 크기를 초과하면 자동으로 더 큰 메모리 영역을 할당받고 기존 요소들을 새로운 메모리 영역으로 복사한다.
- 위 과정에서 잠시동안 오버헤드가 발생한다.
- 마지막에 요소를 추가, 삭제하는것은 상수 시간이지만, 다른곳에 추가하는것은 O(n)이다.
Py_ssize_t allocated;는 리스트의 할당된 크기를 저장한다. 리스트에 담긴 요소의 수는 ob_size에 저장되므로 ob_size는 allocated보다 클 수 없다.
다음으로 리스트의 append 함수를 살펴보자.
CPython에서는 PyList_Append 함수로 구현을 하였고, 내부에서 app1 함수를 사용한다.
PyList_Append, app1
static int
app1(PyListObject *self, PyObject *v)
{
Py_ssize_t n = PyList_GET_SIZE(self);
assert (v != NULL);
assert((size_t)n + 1 < PY_SSIZE_T_MAX);
if (list_resize(self, n+1) < 0)
return -1;
Py_INCREF(v);
PyList_SET_ITEM(self, n, v);
return 0;
}
int
PyList_Append(PyObject *op, PyObject *newitem)
{
if (PyList_Check(op) && (newitem != NULL))
return app1((PyListObject *)op, newitem);
PyErr_BadInternalCall();
return -1;
}먼저 PyList_Append를 살펴보자.
입력받은 리스트 객체가 PyList가 맞는지 체크 및 요소가 Null값인지 체크 후 app1 함수를 호출한다.
app1 함수를 살펴보자.
PyList_GET_SIZE를 통해 현재 리스트의 사이즈를 가져오고 [현재사이즈 + 1]의 값이 메모리에 할당 가능한 최대 사이즈보다 작을경우 list_resize함수를 실행하여 리스트를 리사이즈 한다.
list_resize함수가 정상적으로 실행되었으면 Py_INCREF를 통해 요소의 참조값을 증가시키고, 마지막으로 PyList_SET_ITEM을 통해 리스트의 마지막에 요소를 추가한다.
이제 마지막으로 리스트의 리사이즈 및 메모리 재할당을 구현한 list_resize함수를 살펴보자
list_resize
static int
list_resize(PyListObject *self, Py_ssize_t newsize)
{
PyObject **items;
size_t new_allocated, num_allocated_bytes;
Py_ssize_t allocated = self->allocated;
/* Bypass realloc() when a previous overallocation is large enough
to accommodate the newsize. If the newsize falls lower than half
the allocated size, then proceed with the realloc() to shrink the list.
*/
if (allocated >= newsize && newsize >= (allocated >> 1)) {
assert(self->ob_item != NULL || newsize == 0);
Py_SET_SIZE(self, newsize);
return 0;
}
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* Add padding to make the allocated size multiple of 4.
* The growth pattern is: 0, 4, 8, 16, 24, 32, 40, 52, 64, 76, ...
* Note: new_allocated won't overflow because the largest possible value
* is PY_SSIZE_T_MAX * (9 / 8) + 6 which always fits in a size_t.
*/
new_allocated = ((size_t)newsize + (newsize >> 3) + 6) & ~(size_t)3;
/* Do not overallocate if the new size is closer to overallocated size
* than to the old size.
*/
if (newsize - Py_SIZE(self) > (Py_ssize_t)(new_allocated - newsize))
new_allocated = ((size_t)newsize + 3) & ~(size_t)3;
if (newsize == 0)
new_allocated = 0;
if (new_allocated <= (size_t)PY_SSIZE_T_MAX / sizeof(PyObject *)) {
num_allocated_bytes = new_allocated * sizeof(PyObject *);
items = (PyObject **)PyMem_Realloc(self->ob_item, num_allocated_bytes);
}
else {
// integer overflow
items = NULL;
}
if (items == NULL) {
PyErr_NoMemory();
return -1;
}
self->ob_item = items;
Py_SET_SIZE(self, newsize);
self->allocated = new_allocated;
return 0;
}천천히 코드를 파악해보자.
들어가기에 앞서 bit연산자에 대한 사전지식이 필요하다.
- 맨처음, 현재 할당된 메모리 크기(allocated)와 리스트의 증가된 크기(newsize)를 비교한다.
if (allocated >= newsize && newsize >= (allocated >> 1))
allocated가 newsize보다 크거나 같고(&&) newsize가 allocated/2의 값보다 클경우assert(self->ob_item != NULL || newsize == 0);
리스트가 이미 어떤 요소를 포함하고 있거나(||) newsize가 0인경우, 즉 리스트가 비어있는 경우를 확인Py_SET_SIZE(self, newsize);
리스트의 사이즈를 조정
- 새로 할당할 메모리를 구한다.
((size_t)newsize + (newsize >> 3) + 6)
newsize와 newsize/8의 값을 더하고 상수 6을 더한다.& ~(size_t)3
위에서 구한 값에 비트 AND연산(&)과 NOT연산(~)을 수행한다.- 3의 비트 반전(NOT 연산)은 1100(2진수)가 되고 AND 연산으로 대상의 하위 2비트를 0으로 만든다.
이 결과로 가장 가까운4의 배수를 만든다.(eg. 34 -> 32)
- 3의 비트 반전(NOT 연산)은 1100(2진수)가 되고 AND 연산으로 대상의 하위 2비트를 0으로 만든다.
- 실제 리스트의 사이즈 증가양과 추가로 할당된 메모리 크기를 비교한다.
if (newsize - Py_SIZE(self) > (Py_ssize_t)(new_allocated - newsize))
newsize에서 현재 리스트 사이즈(Py_SIZE)를 뺀 값이 새로 할당된 크기(new_allocated)에서 newsize를 뺀 값보다 큰지 체크((size_t)newsize + 3) & ~(size_t)3;
newsize에 상수3을 더한값을 가장 가까운 4의 배수로 만든다.
- 메모리 할당 전에, 시스템이 처리할 수 있는 포인터의 최대 갯수 체크 및 메모리 할당
if (new_allocated <= (size_t)PY_SSIZE_T_MAX / sizeof(PyObject *))
시스템에서 처리할 수 있는 최대 메모리 크기(PY_SSIZE_T_MAX)를 포인터 하나의 크기(PyObject *)로 나누어 시스템에서 처리할 수 있는 포인터의 갯수를 구하고 그 값이 new_allocated보다 크거나 같은지 체크num_allocated_bytes = new_allocated * sizeof(PyObject *);
실제 메모리에 적용될 바이트(num_allocated_bytes)크기를 구한다.items = (PyObject **)PyMem_Realloc(self->ob_item, num_allocated_bytes);
PyMem_Realloc함수를 실행해서 실제 메모리를 재할당하고, 할당이 성공하면 새로 할당된 메모리의 주소값을 변수 items에 지정한다.
- 리스트의 주소값을 새로운 주소값으로 변경하고 사이즈를 조정하고 allocated를 증가시킨다.
CPython 대략 이런식으로 리스트를 구현하였다.
그럼 이번에는 Python에서 리스트를 확인해보자.
Python 리스트
import sys
tmp = 0
my_list = []
size = sys.getsizeof(my_list)
print(f"초기 list의 메모리 사이즈: {size}Byte")
for i in range(1000):
my_list.append(i)
tmp = sys.getsizeof(my_list)
plus_size = tmp - size
if plus_size > 0:
print(f"{i+1}번째 append에서 {plus_size}Byte 증가, 이전: {size}Byte, 현재: {tmp}Byte")
size = tmp위 코드는 초기 리스트에 할당된 메모리 사이즈를 체크하고 정수를 append하면서 할당된 메모리 크기를 초과하면 새로 할당된 메모리의 사이즈를 체크한다.
아래는 코드의 실행된 결과이다.
초기 list의 메모리 사이즈: 56Byte
1번째 append에서 32Byte 증가, 이전: 56Byte, 현재: 88Byte
5번째 append에서 32Byte 증가, 이전: 88Byte, 현재: 120Byte
9번째 append에서 64Byte 증가, 이전: 120Byte, 현재: 184Byte
17번째 append에서 64Byte 증가, 이전: 184Byte, 현재: 248Byte
25번째 append에서 64Byte 증가, 이전: 248Byte, 현재: 312Byte
33번째 append에서 64Byte 증가, 이전: 312Byte, 현재: 376Byte
41번째 append에서 96Byte 증가, 이전: 376Byte, 현재: 472Byte
53번째 append에서 96Byte 증가, 이전: 472Byte, 현재: 568Byte
65번째 append에서 96Byte 증가, 이전: 568Byte, 현재: 664Byte
77번째 append에서 128Byte 증가, 이전: 664Byte, 현재: 792Byte
93번째 append에서 128Byte 증가, 이전: 792Byte, 현재: 920Byte
109번째 append에서 160Byte 증가, 이전: 920Byte, 현재: 1080Byte
129번째 append에서 160Byte 증가, 이전: 1080Byte, 현재: 1240Byte
149번째 append에서 192Byte 증가, 이전: 1240Byte, 현재: 1432Byte
173번째 append에서 224Byte 증가, 이전: 1432Byte, 현재: 1656Byte
201번째 append에서 256Byte 증가, 이전: 1656Byte, 현재: 1912Byte
233번째 append에서 288Byte 증가, 이전: 1912Byte, 현재: 2200Byte
269번째 append에서 320Byte 증가, 이전: 2200Byte, 현재: 2520Byte
309번째 append에서 352Byte 증가, 이전: 2520Byte, 현재: 2872Byte
353번째 append에서 384Byte 증가, 이전: 2872Byte, 현재: 3256Byte
401번째 append에서 448Byte 증가, 이전: 3256Byte, 현재: 3704Byte
457번째 append에서 512Byte 증가, 이전: 3704Byte, 현재: 4216Byte
521번째 append에서 576Byte 증가, 이전: 4216Byte, 현재: 4792Byte
593번째 append에서 640Byte 증가, 이전: 4792Byte, 현재: 5432Byte
673번째 append에서 704Byte 증가, 이전: 5432Byte, 현재: 6136Byte
761번째 append에서 800Byte 증가, 이전: 6136Byte, 현재: 6936Byte
861번째 append에서 896Byte 증가, 이전: 6936Byte, 현재: 7832Byte
973번째 append에서 1024Byte 증가, 이전: 7832Byte, 현재: 8856Byte결과를 보면 다음과 같은 결론을 도출할 수 있다.
- 빈 리스트의 사이즈는 56byte이다.
-> 이는 CPython에서 PyObject_HEAD, 리스트의 현재 길이 저장, 메타데이터 저장등에 사용된다. - 요소(메모리 주소, 포인터)의 크기는 8byte이다.
- 메모리가 증가하는 크기가 위에서 살펴본 CPython list_reisze에서 구현한 만큼 증가하고 있다.
그래서 리스트는 왜 느린걸까?
파이썬의 리스트가 느린 이유는 단순하다.
위에서도 계속 말했듯이 리스트는 포인터의 배열이기 때문이다.
일반적으로 배열(Array)이나 벡터 자료구조의 경우 메모리 블록에 연속적으로 할당이 되어서 캐싱 라인이 형성이 된다.
하지만 리스트에 들어가는 요소들은 객체의 포인터이기 때문에, 리스트내 포인터들은 메모리에 연속적으로 할당이 되지만, 실제 객체들은 메모리에 불연속적으로 할당이 되어 캐시미스가 자주 발생하여 상대적으로 속도가 느리다.
느리다고 표현은 했지만, 실제 사용에서는 대규모의 데이터가 아닌이상 체감하기 어렵다.
그럼 어떻게 빠르게 쓸 수 있을까?
리스트가 느리다면 어떻게 하면 조금이라도 빠르게 쓸 순 없을까? 몇가지 방법을 알아보자.
요소에 들어갈 인스턴스들을 메모리에 연속적으로 할당하기
리스트에 들어갈 요소의 인스턴스들을 메모리에 연속적으로 할당할 수 있다면 성능이 올라갈 수 있다.
예를들어 캐싱 라인의 크기가 128byte이고 정수 객체를 3개 만들고 주소값 1000~1083까지 할당을 받았다 가정하고, 리스트의 주소값이 2000이라고 가정하여 정수 객체 3개를 append 한다면 주소값을 2000~2023까지 사용 할 것이다.
이런 가정에서 리스트의 0번째 인덱스에 접근한다면,
1. 리스트의 주소값 2000에 접근을 한다. 이때, CPU는 2000~2023까지 캐싱 라인으로 캐시에 로드될 것이고, 0~3번째 포인터에 접근시 캐시 히트가 발생한다.
2. 0번째 포인터가 바라보는 주소값 1000에 접근을 한다. 이번에도 CPU는 1000~1083까지 캐싱 라인으로 캐시에 로드가 된다. 이후 3개의 인스턴스에 접근시 캐시 히트가 발생한다.
하지만 파이썬에서 객체를 메모리의 특정 주소값에 할당하는건 불가능하다.
만약 같은 타입으로 객체를 연속적으로 생성한다면 연속적인 메모리에 할당이 되기도 하지만, 실제 사용에서는 거의 일어날 수 없는 일이다.
따라서 이 방법은 사용하기에는 옳지 않다.
리스트 컴프리헨션을 사용하기
리스트 컴프리헨션은 CPython에서 실행 속도를 최적화 할 수 있게 구현을 하였다.
메모리 사용을 최적화 하여 여러 메모리 할당과 가비지 컬렉션의 작업을 줄였고, 인터프리터에 대한 특별한 최적화를 수행하여 속도 향상을 기대할 수 있다.
def func1():
list_ = []
for i in range(100000000):
list_.append(i)
return list_
def func2():
return [i for i in range(100000000)]func1은 일반적인 리스트에 append하는 함수, func2는 리스트 컴프리헨션을 사용한 함수이다.
각각의 실행시간은 아래와 같다.
일반 생성 list: 0:00:03.997658
리스트 컴프리헨션: 0:00:03.026040요소가 원시자료형일경우 array, numpy를 사용하자
사실 파이썬에서 원시자료형은 없다. 여기서 말한 원시자료형은 C언어 기준이다.(int, float, bool 등등..)
CPython에서 array의 구조체는 다음과 같다.
typedef struct arrayobject {
PyObject_VAR_HEAD
char *ob_item;
Py_ssize_t allocated;
const struct arraydescr *ob_descr;
PyObject *weakreflist; /* List of weak references */
Py_ssize_t ob_exports; /* Number of exported buffers */
} arrayobject;리스트와 비슷하지만 ob_item이 PyObject였던 것과 다르게 char *로 포인터의 주소값을 가지는게 아니라, 값 자체를 가지게 된다.(원시자료형 한정)
Numpy역시 C로 구현된 파이썬 라이브러리로 array와 비슷한 구조 및 성능을 가진다.
얼마나 빠를까?
0~100000000 까지 리스트에 넣고 더하는 간단한 함수를 리스트, array, numpy를 사용해서 비교해보자.
from datetime import datetime
import array
import numpy
def fun_list():
list_ = [i for i in range(100000000)]
return sum(list_)
def fun_array():
array_ = array.array('i', range(100000000))
return sum(array_)
def fun_numpy():
numpy_ = numpy.arange(100000000)
return sum(numpy_)각각의 결과는 이렇다.
리스트 sum: 4999999950000000 시간: 0:00:05.495154
array sum: 4999999950000000 시간: 0:00:09.464621
numpy sum: 4999999950000000 시간: 0:00:08.114153빠르다고 예상했지만, 거의 2배 정도 더 느려졌다.
이런 결과가 나온 이유는 간단하다.
바로 sum함수가 python객체를 통해 이루어지기 때문이다.
즉, 원시자료형을 담는 array나 numpy의 경우 요소 하나하나 마다 원시자료형 -> Python Object로 변환하는 작업이 추가적으로 진행이 되어 오버헤드가 발생해 오히려 속도가 느려진 것이다.
위의 함수를 아래와 같이 변경하고 다시 진행해보자.
def fun_numpy():
numpy_ = numpy.arange(100000000)
return numpy_.sum()결과는 다음과 같다.
numpy sum: 4999999950000000 시간: 0:00:00.445143정말 엄청난 차이이다. 이는 numpy_.sum함수가 아까와는 다르게 Pyobject로 변환하지 않고 C에서 원시자료형 그대로 연산을 하고, 마지막 최종 결과만 PythonObject로 변환하기 때문이다.
또한 직렬화와 역직렬화에서도 성능의 차이를 보이는데, 이는 이기종 시스템간의 데이터 전달에서 굉장히 중요하다.
from datetime import datetime
import array
import numpy
import pickle
def fun_list():
list_ = [i for i in range(50000000)]
return pickle.dumps(list_)
def fun_array():
array_ = array.array('i', range(50000000))
return pickle.dumps(array_)
def fun_numpy():
numpy_ = numpy.arange(50000000)
return pickle.dumps(numpy_)리스트 직렬화 시간: 0:00:03.585581
array 직렬화 시간: 0:00:03.994695
numpy 직렬화 시간: 0:00:00.593829실무에는 어떻게 적용했어?
멀티페이지 OCR 요청이 들어올경우 추론결과를 리스트에 담고 직렬화 후 후처리 작업을 하는 컨테이너에서 역직렬화 하여 사용하였다. 이 과정에서 리스트를 Numpy로 변경하니 기존 대비 최소 1/3시간이 줄어들게 되었다.

아하! 그래서 제 파이선이 이렇게 구린거였군요! 감사합니다~!!