- SVM은 logistic regression과 유사하게 범주형 결과(Categorical outcomes)를 예측하기 위한 분류 기법으로 사용된다.
- SVM은 지도학습에서 복잡한 데이터를 분석하고 특이치의 영향을 무시한다.
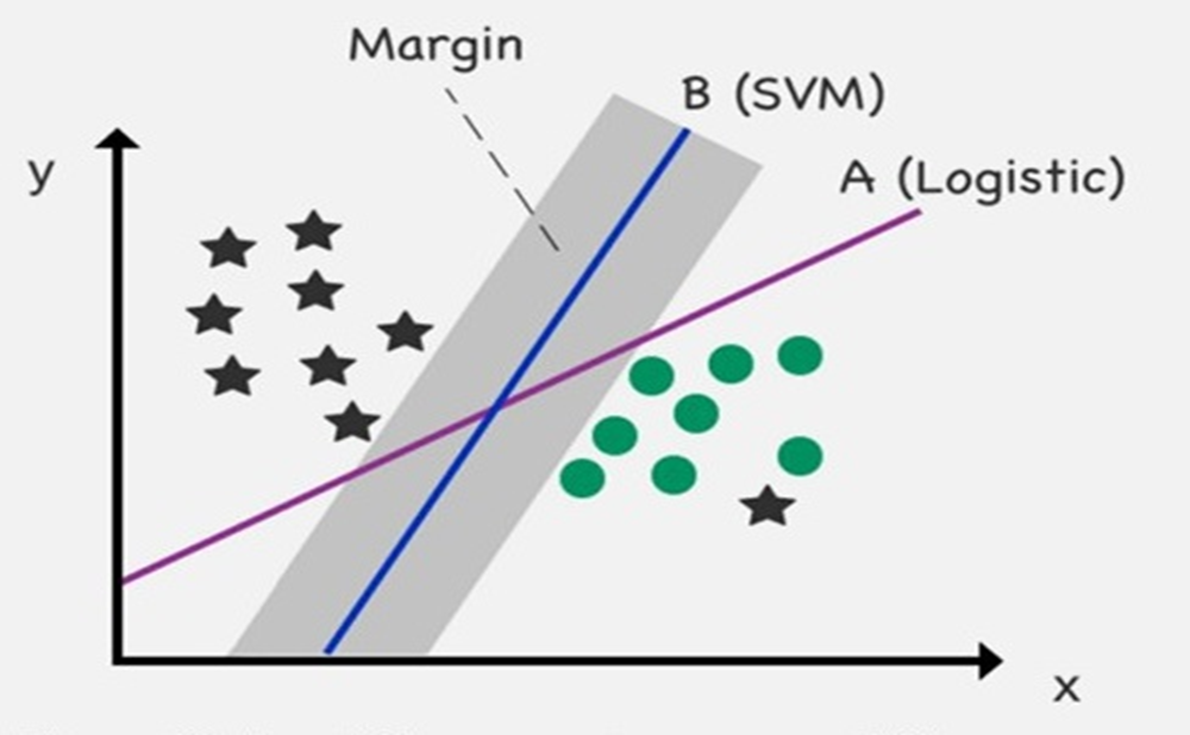
- Logistic Regression 분석과 달리 SVM은 자신과 분할된 데이터 점 사이의 최대 거리 위치에서 데이터 클래스를 분리하려고 시도합니다.
- 주요 특징 : 경계선과 가장 가까운 데이터 점 사이의 거리에 2를 곱한 margin
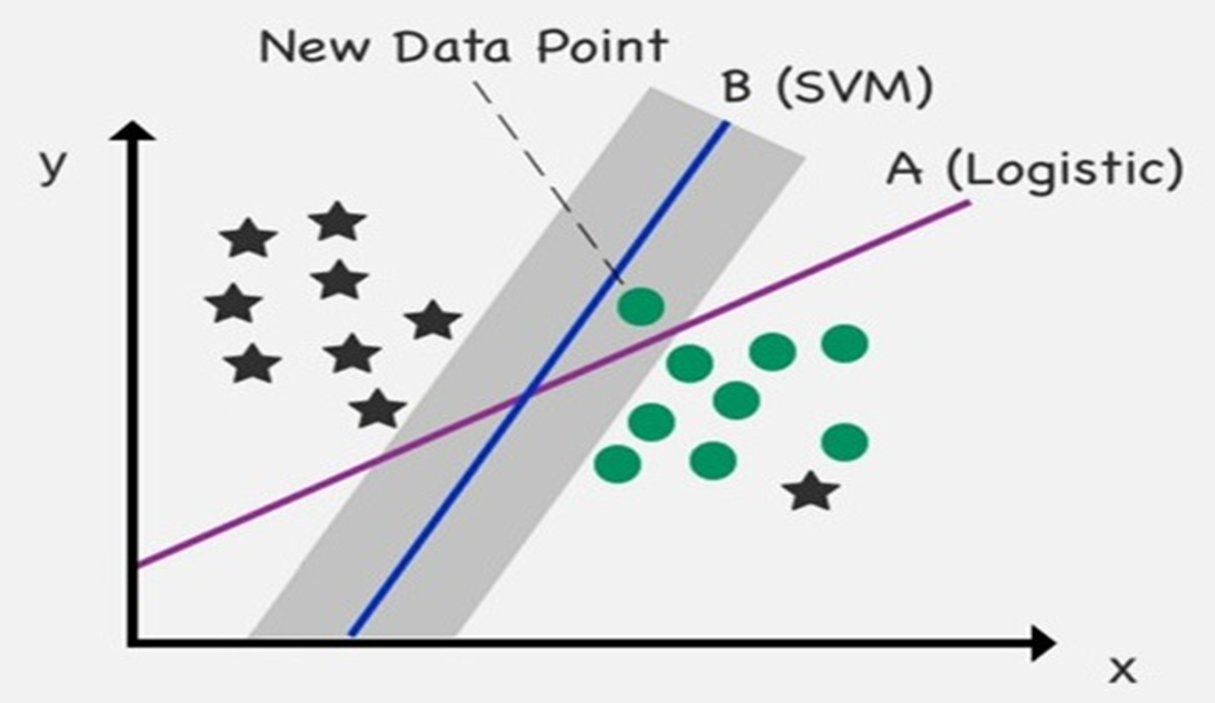
새로운 data point가 scatterplot에 추가가 된다.
margin을 기준으로 두 개의 그룹으로 데이터가 분리된다.
- Margin을 사용하면 logistic regression 경계선을 위반하는 새 data point 및 특이치를 처리할 수 있다.
- Import libraries
- Import dataset
- Remove variables
- Convert non-numeric variables
- Set X and y variables
- Set algorithm
- Confusion matrix
- Grid Search
Grid search
이 알고리즘에 대한 최적의 하이퍼 파라미터를 찾는 데 도움이 되는 "그리드 검색"이라는 특수 기술을 사용하여 모델의 정확도를 향상시킬 수 있다. SVC에 속하는 많은 하이퍼 파라미터가 있지만, 이 알고리즘을 사용하여 일반적으로 예측 정확도에 가장 큰 영향을 미치는 C와 gamma에 초점을 맞출 것이다.
Hyperparameter C는 잘못 분류된 사례(margin의 잘못된 쪽에 배치됨)가 무시되는 정도를 조절한다. 모델의 이러한 유연성을 "Soft Margin"이라고 하며, Soft margin을 교차하는 경우를 무시하면 더 잘 맞을 수 있다.
C가 낮을수록 Soft margin이 무시할 수 있는 오류가 더 많다.
C 값이 '0'이면 잘못 분류된 사례에 대한 패널티가 없다.
Gamma는 Gaussian radial basis 함수와 support 벡터의 영향을 의미한다. 일반적으로 gamma 값이 작으면 높은 편향(high bias)과 낮은 분산(low variance) 모델을 생성한다. 반대로, gamma 값이 크면 모델에서 낮은 편향(low bias)과 높은 분산(high variance)을 초래한다.
그리드 검색을 통해 각 하이퍼 파라미터에 대해 테스트할 값의 범위를 나열할 수 있다. C와 감마에 제공된 각각의 가능한 순열을 테스트한 후, 그리드 검색은 C=50과 gamma = 0.0001이 이 모델에 이상적인 hyperparameter라는 것을 발견했다.
Grid Search Predict
그리드 검색에 의해 제공된 새로운 하이퍼 파라미터를 사용하여 테스트 데이터를 모델과 연결하고, 새로운 셀 내부의 예측 결과를 검토해 보자.
Confusion Matrix와 Classification Report에서 입증된 바와 같이, 새로운 hyperparameter는 이 모델의 예측 성능을 향상시켰으며, false-positive(17)와 false-negative(15)의 수가 거의 균등하게 나뉘었고, 정밀도(precision), recall 및 f1-score의 경우 0.89가 나왔다.
