1. Buffer Pool
2. Change Buffer
3. Adaptive Hash Index
4. Log Buffer
매뉴얼 순서대로 읽어가면서 정리하는 중.
Buffer Pool
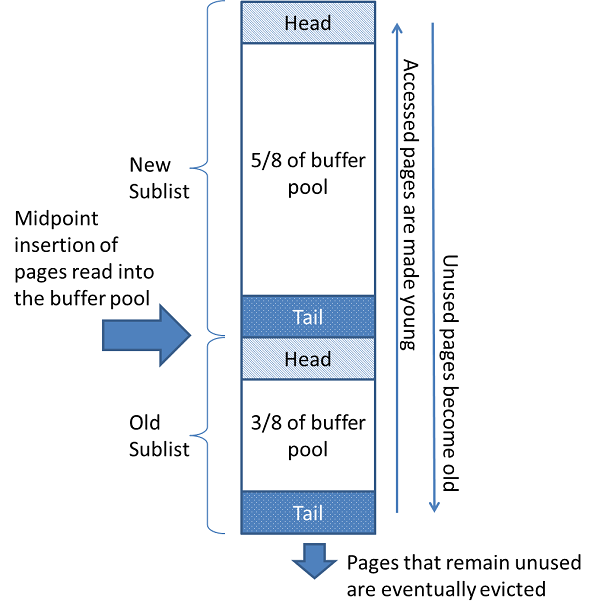
평범하다면 평범할 LRU 알고리즘을 사용하여 캐시 데이터를 관리한다고 한다.
비율은 8로 나눠서 3은 Old Data, 5는 New data로 관리하는데 이 기준은 어디서 나왔는지 궁금하다. 이 비율을 설정하는 프로퍼티가 있을 것 같기도 하고...
Old Sublist의 데이터를 읽으면, New Sublist의 꼬리로 옮겨가며, 이는 Old Sublist 간에도 변경이 발생될 수 있다는 뜻이다. New Sublist는 Buffer Pool에 존재하지 않는 데이터를 읽었을 경우 갱신되는 것으로, 자주 조회가 발생하는 Old Sublist를 유지하여 속도를 개선하는 것이 튜닝의 주안점이 될것이다.
Where 조건 없이 발생하는 full scan SELECT라면, 계속해서 New Sublist가 변경되므로 비효율적인 구조가 된다. 해당 상황을 옵티마이징 하는 방법이 있다고 하니 나중에 체크.
Section 15.8.3.3, “Making the Buffer Pool Scan Resistant”
Section 15.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”
브레인스토밍
- Old Sublist의 비율을 조절할 수 있다면, 업무 구조에 따라 효율성을 극대화할 수 있을 것이다.
- Old Sublist를 fix하여 내가 원하는 부분의 데이터만 넣을 수 있다면 좋겠지만, Old라는 기준은 고정될 수 없으니 다른 개념으로 메모리에 fix할 방법은 있을 것으로 생각함.
여러모로 디스크 DB의 원론적인 얘기인 것 같다.
Configuration
-
이건 매우 당연한 것이지만, Buffer Pool을 이론상 데이터만큼 키운다면 Disk DB라도 In-Memory DB와 비슷하게 작동시킬 수 있다. 일반적으로 In-Memory라고 해서 파일을 사용하지 않는 것은 아니며, Redo log를 이용하여 트랜잭션을 보존하고 일정 주기마다 Data flush를 통해 디스크의 데이터를 동기화하기 때문이다. 물론 그렇다고 해서 In-Memory와 성능이 비슷하냐 하면 그건 아닐 거라고 생각은 하지만...
Section 15.8.3.1, “Configuring InnoDB Buffer Pool Size” -
64비트 시스템이라는 가정 하에 Buffer Pool을 여러 단위로 분산하여 쪼갤 수 있다고 한다.(많은 메모리가 필요하다고 하는데 그 기준은 모르겠다..) Buffer Pool을 쪼갤 경우 메모리 점유 경합으로 인한 성능 저하를 방지할 수 있다고...
개인적인 생각
1) 쪼갠다는 것은 무슨 기준으로 쪼갠다는 것인지? 테이블? 메모리 세그먼트 단위? 테이블스페이스?
2) In-Memory에서 Memory Attach로 인한 문제가 생기는 경우가 종종 있다. 이를 좀비 세션이라고 하는데, 모든 데이터를 메모리에 올려 처리하는 In-Memory DB에서는 해당 상황은 부분 처리가 불가능하므로 DB를 재구동해야되는 문제가 될 수 있는, 굉장히 치명적인 문제이다.
사실 Disk DB인 mysql의 특성상 고려할 부분은 아니지만, 해당 방법을 통해 구역별로 처리함으로서 장애사항을 방지할 수 있는 방법도 생각해 봄 직 하지 않을까...는 희망적인 생각일 뿐이고, 사실 그런 거랑은 별 상관 없을 듯.
Section 15.8.3.2, “Configuring Multiple Buffer Pool Instances” -
주기적으로 읽어들이는 데이터를 메모리에 fix하는 방법이 있다고 한다. 사실 이 부분은 Disk DB라면 튜닝의 가장 기초적인 부분이라 없을 순 없을 것 같다.
Section 15.8.3.3, “Making the Buffer Pool Scan Resistant” -
앞으로 생길 request를 대비하여 page를 fetch하는 시기를 튜닝할 수 있다. 이를 read-ahead라고 함.
개인적인 생각
1) 예를 들자면, 10000건의 full scan을 한다고 치면 3천 건을 읽고 있을 즈음에 후반 레코드를 prefetch한다는 뜻으로 생각할 수 있을까? 그런데 그렇다면 메모리 read 속도가 더 빠를텐데 prefetch가 그보다 더 빠르게 될 것이라는 보장이 가능한 것인가?
2) 그것이 아니라면, 미리 prepare된 plan을 통하여 해당 레코드를 prefetch 하는 형식이라고 가정한다면 설득력이 있다.
Section 15.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)” -
data flush 주기를 설정할 수 있다. 이건 뭐 다른 DB에도 있는 개념인데...작업양에 따라서도 튜닝할 수 있다는 부분은 흥미롭다. disk io에 민감한 Disk DB 다운 설정인 것 같다.
Section 15.8.3.5, “Configuring Buffer Pool Flushing” -
Buffer Pool을 복구할 수 있다! 상당한 장점이라고 생각한다. 한시가 중요한 운영서버에서는 기동 후 몰릴 작업양이 큰 리스크로 떠오를 수 있는데, 초반에 몰릴 데이터 read 때문에 큰 부하를 일으킬 수 있는 Disk의 구조상 상당한 리스크 컨트롤이 될 수 있다.
이 쯤 되면, 모든 데이터를 Memory에 올리는 In-Memory의 형태를 일정 부분 벤치마킹 한 것이 아닐까 싶을 정도.
Section 15.8.3.6, “Saving and Restoring the Buffer Pool State”
모니터링
SHOW ENGINE INNODB STATUS

와 같은 형식으로 보여준다고 함.
위에서 얘기했던 LRU 알고리즘 방식처럼, old data와 new 데이터의 크기가 8:3 비율로 되어있다.
초당 쓰이는 page수, hit rate까지 한번에 볼 수 있어서 꽤 편한 뷰인듯 하다.
딕셔너리 뷰로는 INNODB_BUFFER_POOL_STATS가 있다.

1 row라는 것은 여러 Buffer Pool로 분할했을 경우 row단위로 보여주는 것이 아닐까 하는 생각이 듬.
다음은 Change Buffer인데, 대체 그래서 O_DIRECT가 뭐냐고...
