
회고
오늘부터 과제제출이 시작되었다. 원래 계획은 빨리 강의와 TIL을 마무리하고 과제를 풀려고 했는데 알고리즘 문제를 풀고 힙을 완벽히 이해하는데 시간을 많이 쓰다 보니 벌써 7시가 되었다. 코어타임 이후에 조금씩 시도해봐야겠다. 공부하면서 코드가 이해가지 않을 때, 값들을 넣어가면서 노트에 적으면서 하니 훨씬 재밌고 이해하기도 쉬웠다. 힙 은근 재밌을지도?😁😁 바꾼 방식대로 TIL을 간단하게 작성하는게 블로그 작성 시간을 줄이는데 도움이 많이 된다. 물론 연결리스트를 활용한 이진트리는 과제를 하면서 보충해야할 것 같다. 내일도 화이팅🔥🔥
트리
= 방향 그래프의 일종으로 정점을 가리키는 간선이 하나밖에 없는 구조를 가지고 있다.
예시) 조직도, 컴퓨터 디렉토리 구조
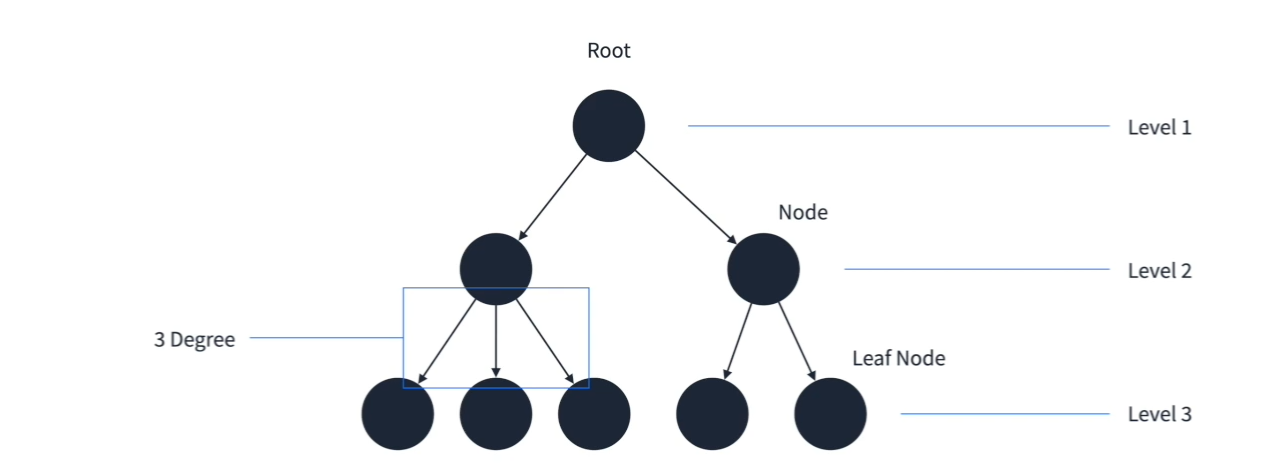
- 루트 = 가장 상위에 존재하는 노드(정점)
- Leaf Node = 더이상 자식이 존재하지 않는 노드
- level = 루트로부터 몇번째 깊이인지 표현하는 것
- degree(차수) = 한정점에서 뻗어나가는 간선의 수
트리의 특징
- 루트 정점을 제외한 모든 정점은 반드시 하나의 부모 정점을 가진다.
- 정점이 N개인 트리는 반드시 N-1개의 간선을 가진다
- 루트에서 특정 정점으로 가는 경로는 유일하다.
이진트리
- 이진트리는 각 정점이 최대 2개의 자식을 가지는 트리를 의미한다.
- 탐색 알고리즘에서 많이 사용된다.
- 완전 이진 트리: 마지막 레벨을 제외하고 모든 정점이 채워져 있는 트리
- 포화 이진 트리: 모든 레벨에서 모든 정점이 채워져 있는 트리
- 편향 트리: 한방향으로만 정점이 이어지는 트리
이진트리의 특징
- 정점이 N개인 이진 트리는 최악의 경우 높이가 N개가 될 수 있다. ⇒ 편향트리
- 정점이 N개인 포화 또는 완전 이진 트리의 높이는 logN이다.
- 높이가 h인 포화 이진트리는 -1개의 정점을 가진다.
- 일반적인 이진트리를 사용하는 경우는 많지 않다. 다음 자료구조에 응용된다.
- 이진 탐색트리
- 힙
- AVL 트리
- 레드 블랙 트리
힙
우선순위 큐
FIFO인 큐와 달리 우선순위가 높은 요소가 먼저 나가는 큐
💡 우선 순위 큐는 자료구조가 아닌 개념이다.
우선순위큐를 구현하는 방법에는 여러가지가 있는데 힙이 가장 적합하다.
힙
= 이진 트리 형태를 가지며 우선순위가 높은 요소가 먼저 나가기 위해 요소가 삽입, 삭제 될 때 바로 정렬되는 특징이 있다.
- 우선순위가 높은 요소가 루트가 되며 먼저 나가는 특징을 가진다.
- 루트가 가장 큰 값이 되는 최대 힙과 루트가 가장 작은 값이 되는 최소 힙이 있다.
- 아쉽게도 JS에선 직접 구현해서 사용해야 한다.
힙 요소 추가 알고리즘
- 요소가 추가될 때는 트리의 가장 마지막에 정점에 위치한다.
- 추가 후 부모 정점보다 우선순위가 높다면 부모 정점과 순서를 바꾼다.
- 이 과정을 반복하면 결국 가장 우선순위가 높은 정점이 루트가 된다.
- 완전 이진 트리의 높이는 logN이기에 힙의 요소 추가 알고리즘은 O(logN) 시간 복잡도를 가진다.
힙 요소 삭제 알고리즘
- 요소 제거는 루트 정점만 가능하다.
- 루트 정점이 제거된 후 가장 마지막 정점이 루트에 위치한다.
- 루트 정점의 두 자식 정점 중 더 우선순위가 높은 정점과 바꾼다.
- 두 자식 정점이 우선순위가 더 낮을 때까지 반복한다.
- 완전 이진 트리의 높이는 logN이기에 힙의 요소 삭제 알고리즘은 O(logN) 시간 복잡도를 가진다.
JS에서 구현하는 방법 - 최대힙 요소 추가 삭제
class MaxHeap {
constructor() {
this.heap = [null];
}
push(value) {
this.heap.push(value);
let currentIndex = this.heap.length - 1;
let parentIndex = Math.floor(currentIndex / 2);
while (parentIndex !== 0 && this.heap[parentIndex] < value) {
const temp = this.heap[parentIndex];
this.heap[parentIndex] = value;
this.heap[currentIndex] = temp;
currentIndex = parentIndex;
parentIndex = Math.floor(currentIndex / 2);
}
}
pop() {
const returnValue = this.heap[1];
this.heap[1] = this.heap.pop(); //가장 마지막 정점이 루트로 올라온다.
let currentIndex = 1;
let leftIndex = 2;
let rightIndex = 3;
//루트 값이 자식 정점보다 작을때
while (this.heap[currentIndex] < this.heap[leftIndex] || this.heap[currentIndex] < this.heap[rightIndex]) {
if (this.heap[leftIndex] < this.heap[rightIndex]) {
//오른쪽 정점이 왼쪽 정점보다 더 클 때
const temp = this.heap[currentIndex]; //루트
this.heap[currentIndex] = this.heap[rightIndex];
this.heap[rightIndex] = temp;
currentIndex = rightIndex;
} else {
//왼쪽 정점이 오른쪽 정점보다 더 클 때
const temp = this.heap[currentIndex];
this.heap[currentIndex] = this.heap[leftIndex];
this.heap[leftIndex] = temp;
currentIndex = leftIndex;
}
leftIndex = currentIndex * 2;
rightIndex = currentIndex * 2 + 1;
}
return returnValue;
}
}
const heap = new MaxHeap();
heap.push(45);
heap.push(36);
heap.push(54);
heap.push(27);
heap.push(63);
console.log(heap.heap); //[null,63,54,45,27,36]
console.log(heap.pop());
console.log(heap.pop());
console.log(heap.pop());
console.log(heap.pop());
console.log(heap.pop());트라이 Trie
문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조
트라이의 특징
- 검색어 자동완성, 사전 찾기 등에 응용될 수 있다.
- 문자열을 탐색할 때 단순하게 비교하는 것보다 효율적으로 찾을 수 있다.
- L이 문자열의 길이일 때 탐색, 삽입은 O(L)만큼 걸린다.
- 대신 각 정점이 자식에 대한 링크를 전부 가지고 있기에 저장 공간을 더 많이 사용한다. ⇒ 단점
트라이 구조
- 루트는 비어있다.
- 각 간선은 추가될 문자를 키로 가진다.
- 각 정점은 이전 정점의 값 + 간선의 키를 값으로 가진다.
- 해시 테이블과 연결 리스트를 이용하여 구현할 수 있다.
JS에서의 사용법
//안접리스트 형태로 구현
class Node {
//트리 구조이므로 노드 필요
constructor(value = "") {
this.value = value;
this.children = new Map();
}
}
class Trie {
//트라이 생성시 루트로 빈 노드 생성
constructor() {
this.root = new Node();
}
insert(string) {
let currentNode = this.root; //탐색을 위해 루트부터 시작
for (const char of string) {
if (!currentNode.children.has(char)) {
//자른 문자열의 값을 간선으로 갖고 있지 않는 경우 새롭게 노드 추가
currentNode.children.set(char, new Node(currentNode.value + char));
}
currentNode = currentNode.children.get(char); // 다음 정점으로 이동
console.log(currentNode);
}
}
has(string) { //문자열이 존재하는지 체크하는 함수
let currentNode = this.root;
for (const char of string) {
if (!currentNode.children.has(char)) {
return false;
}
currentNode = currentNode.children.get(char);
}
return true;
}
}
const trie = new Trie();
trie.insert("cat");
trie.insert("can");
console.log(trie.has("cat"));
console.log(trie.has("can"));
console.log(trie.has("cap"));정렬
= 요소들을 일정한 순서대로 열거하는 알고리즘
정렬의 특징
- 정렬의 기준은 사용자가 정할 수 있다.
- 크게 비교식과 분산식으로 정렬로 나눌 수 있다.
- 대부분의 언어가 빌트인으로 제공해준다
- 삽입,선택,버블,머지,힙,퀵 정렬 등 다양한 정렬 방식이 존재한다.
💡 어떤 정렬이 제일 빠를까? 무엇이 더 좋고 나쁜지 정해져있진 않다.
비교식 정렬
다른 요소와 비교를 통해 정렬하는 방식
버블 정렬
- 서로 인접한 두 요소를 검사하여 정렬하는 알고리즘. O()
- n-1번 순회하여 정렬
선택 정렬
선택한 요소와 가장 우선순위가 높은 요소를 교환하는 정렬 알고리즘. O()
삽입 정렬
선택한 요소를 삽입 할 수 있는 위치를 찾아 삽입하는 방식의 정렬 알고리즘. O()
두번째 요소부터 시작된다. 비교해서 밀어내는 방식
어느정도 정렬되있다는 전제에서는 퀵정렬보다 빠르다
분산식 정렬
요소를 분산하여 정렬하는 방식
💡 분산식 정렬에 핵심적으로 쓰이는 전략: 분할 정복
분할정복
문제를 작은 2개의 문제로 분리하고 더 이상 분리가 불가능 할 때 처리한 후 합치는 전략
합병 정렬
분할 정복 알고리즘을 이용한 최선과 최악이 같은 안정적인 정렬 알고리즘. O(nlogn)
퀵 정렬
-
분할 정복 알고리즘을 이용한 매우 빠르지만 최악의 경우가 존재하는 불안정한 정렬. O(nlogn)
-
pivot을 기준으로 좌측(작은값들의 모임)과 우측(큰값들의 모임)으로 나눈다.
다시 나눈 배열에서 첫번째 요소가 pivot이 된다. 그리고 그 pivot을 기준으로 또 나눈다.
JS에서의 정렬 - sort함수
주의할점 : 그냥 sort()로 정렬할 경우 아스키 문자 순서로 정렬된다!
참고자료
프로그래머스 데브코스 FE 강의
