Intro.
23년 하반기쯤,
알고리즘 풀이의 습관화, 알고리즘 실력 향상, 코드 숙련도 향상을 목표로
연구실 인원을 설득해 1일 1알고리즘 풀이 인증 톡방을 만들어서 현재까지 진행 중이다.
주말, 공휴일을 제외하고 알고리즘 풀고 통화된 화면을 톡방에 인증하면 되는 룰이다!
(벌칙 : 톡방 모두에게 커피 1잔)
문제 난이도에 제한이 없어서 쉬운 문제로 인증해도 되는 규칙이기에
코딩테스트 준비까지는 버거울 수 있어도..!
지속적인 참여를 독려하기엔 괜찮은 방법인 것 같고
구성원들에게도 가벼운 강제성으로 좋은 영향을 주고 있는 것 같다 ㅎㅎ
아무튼!
위와 같은 활동으로 알고리즘 문제를 꾸준히 풀며,
조금이라도 얻은게 있다면 블로그 화를 통해 공유하려 한다.
백준 11123.
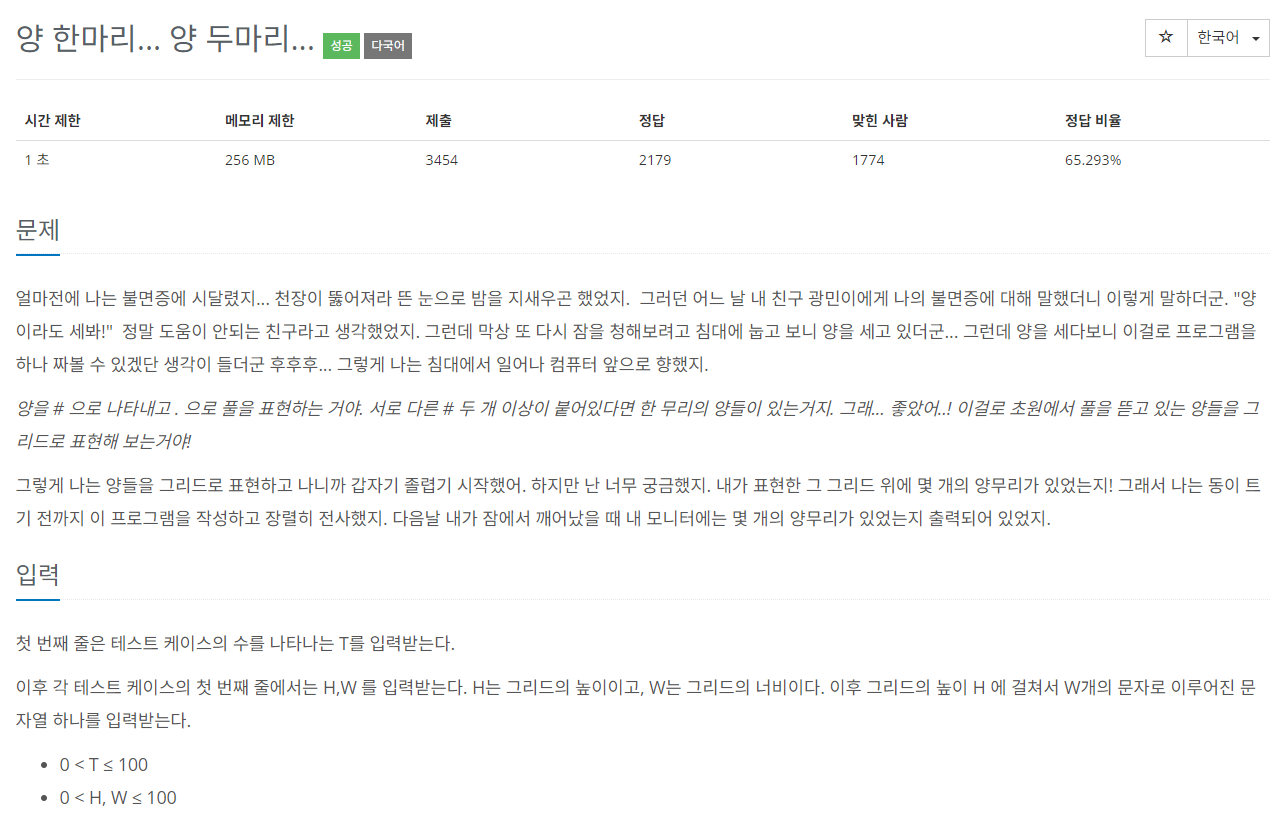
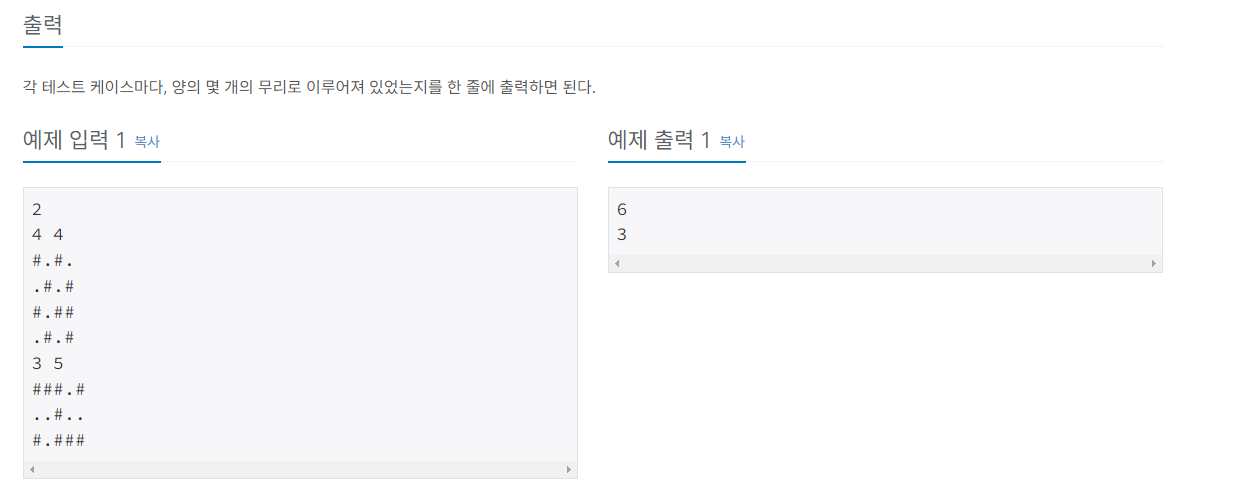
문제 풀이
백준식 BFS, DFS를 많이 푼 사람들은 너무나 쉽게 느껴질 것 같다.
양과 풀 리스트로 구성된 2차원 행렬이 주어질 때,
행렬 첫번째(0,0)부터 마지막까지 탐색하며,
양(#) 발견 시 깊이우선탐색(BFS)으로 방문처리 후 카운팅 하는 과정을 반복하면 되는 문제이다.
첫 번째 풀이
fun main() {
val n = readln().toInt()
repeat(n) {
val (mh, mw) = readln().split(" ").map { it.toInt() }
val arr = Array(mh) { listOf<Char>() }
val vArr = Array(mh) { BooleanArray(mw) }
var cnt = 0
repeat(mh) {
arr[it] = readln().toList()
}
val queue = ArrayDeque<List<Int>>()
fun bfs(){
while (queue.isNotEmpty()) {
val (h, w) = queue.removeLast()
if (h >= mh || h < 0 || w >= mw || w < 0) continue
if (vArr[h][w]) continue
if (arr[h][w] == '.') continue
vArr[h][w] = true
queue.addFirst(listOf(h + 1, w))
queue.addFirst(listOf(h - 1, w))
queue.addFirst(listOf(h, w + 1))
queue.addFirst(listOf(h, w - 1))
}
}
for (i in 0 until mh) {
for (j in 0 until mw) {
if (arr[i][j] == '#' && !vArr[i][j]) {
queue.addFirst(listOf(i, j))
bfs()
cnt++
}
}
}
println(cnt)
}
}코드 설명
-
양, 풀 2차원 행렬 입력 받기
-
행렬 처음부터 끝까지 탐색
-
탐색 중 발견한 양(#) 너비우선탐색 후 방문처리
1) 발견 시 탐색 좌표를 큐에 삽입2) 큐가 빌 때까지 BFS의 While 함수 동작
3) 현 탐색 좌표의 탐색 가능 여부를 체크
4) 동서남북으로 한칸씩 움직이는 네가지 좌표를 큐에 삽입

다음 코드를 제출했고 무사히 통과했다!! 그런데,,
코드 동작 시간이 Kotlin 코드 제출 사람들 중에 꼴지였던 것이다..
자존심이 용납하지 않아 조금 더 고민을 해보았다.
두 번째 풀이
처음 해결한 문제는 ArrayDeque였다.
Queue는 선입선출이고, Deque는 앞뒤에서 삽입 삭제가 가능하며,
이 문제에서 내가 필요한 Queue였다.
1. 코드에서 사용된 Deque로 인해 Queue를 사용할 때 보다 불필요한 과정을 거치게 되어 속도에서 차이가 난다고 생각했다.
또한 이후 발견한 Java의 Queue 라이브러리와 비교했을 때
2. ArrayDeque는 Kotlin 라이브러리기 때문에 컴파일 시 Java 코드로 변환 과정이 추가로 필요하고 이는 속도의 차이를 발생시킨다고 생각했다.
따라서 내가 필요한 선입선출 기능만 가지고있는 Java Queue 라이브러리를 사용해서 다시 구현해보았다.
import java.util.*
fun main() {
val n = readln().toInt()
repeat(n) {
val (mh, mw) = readln().split(" ").map { it.toInt() }
val arr = Array(mh) { listOf<Char>() }
val vArr = Array(mh) { BooleanArray(mw) }
var cnt = 0
repeat(mh) {
arr[it] = readln().toList()
}
val queue: Queue<List<Int>> = LinkedList()
for (i in 0 until mh) {
for (j in 0 until mw) {
if (arr[i][j] == '#' && !vArr[i][j]) {
queue.add(listOf(i, j))
while (queue.isNotEmpty()) {
val (h, w) = queue.remove()
if (h >= mh || h < 0 || w >= mw || w < 0) continue
if (vArr[h][w]) continue
if (arr[h][w] == '.') continue
vArr[h][w] = true
queue.add(listOf(h + 1, w))
queue.add(listOf(h - 1, w))
queue.add(listOf(h, w + 1))
queue.add(listOf(h, w - 1))
}
cnt++
}
}
}
println(cnt)
}
}
속도가 꽤 빨라졌다!!!
근데 순위는 여전히 뒤에서 2등이었다..
무엇이 문제일까?
세 번째 풀이
//첫 번째, 두 번째 BFS 부분
while (queue.isNotEmpty()) {
val (h, w) = queue.remove()
if (h >= mh || h < 0 || w >= mw || w < 0) continue
if (vArr[h][w]) continue
if (arr[h][w] == '.') continue
vArr[h][w] = true
queue.add(listOf(h + 1, w))
queue.add(listOf(h - 1, w))
queue.add(listOf(h, w + 1))
queue.add(listOf(h, w - 1))
}사실 첫 번째, 두 번째의 BFS 코드를 보면,
탐색 가능 여부를 따지기 전에 Queue 삽입이 이루어진다.
나는 탐색 여부를 Queue에서 뺀 후 결정하는게 더 직관적이라 생각했으나,
Queue에 넣기 전 탐색 여부를 파악하는 것이 효율적이라 생각되어 다음과 같이 바꿔보았다.
import java.util.*
fun main() {
val n = readln().toInt()
repeat(n) {
val (mh, mw) = readln().split(" ").map { it.toInt() }
val arr = Array(mh) { listOf<Char>() }
val vArr = Array(mh) { BooleanArray(mw) }
val dh = intArrayOf(-1,1,0,0)
val dw = intArrayOf(0,0,-1,1)
var cnt = 0
repeat(mh) {
arr[it] = readln().toList()
}
val queue: Queue<List<Int>> = LinkedList()
for (i in 0 until mh) {
for (j in 0 until mw) {
if (arr[i][j] == '#' && !vArr[i][j]) {
queue.add(listOf(i, j))
while (queue.isNotEmpty()) {
val (h, w) = queue.remove()
vArr[h][w] = true
for(i in 0 until 4){
val nh = h + dh[i]
val nw = w + dw[i]
if (nh >= mh || nh < 0 || nw >= mw || nw < 0)
continue
if (arr[nh][nw] == '.')
continue
if (vArr[nh][nw])
continue
vArr[nh][nw] = true
queue.add(listOf(nh, nw))
}
}
cnt++
}
}
}
println(cnt)
}
}
처음과 비교하여 엄청 감축시킨 것 같아 뿌듯했다ㅎㅎ
정리.
-
Kotlin ArrayDeque가 Import없이 사용할 수 있기에 편리할 수 있어도, Queue 기능만 사용하고 싶다면 Java Queue를 고려해도 좋다.
-
BFS에서 쓰이는 Queue 삽입에 있어서, 뺀 다음 유효성을 검사하는게 아닌 삽입 전 유효성 검사가 코드상으로 더 효율적이다.

저도 이거 풀어봐야겠어요 !! ㅎㅎㅎㅎ