오늘은 4일차..
화이팅 하자ㅏㅏㅏㅏ
1. 웹사이트 구성의 이해
네이버, 구글, 유튜브 등을 분석해보기
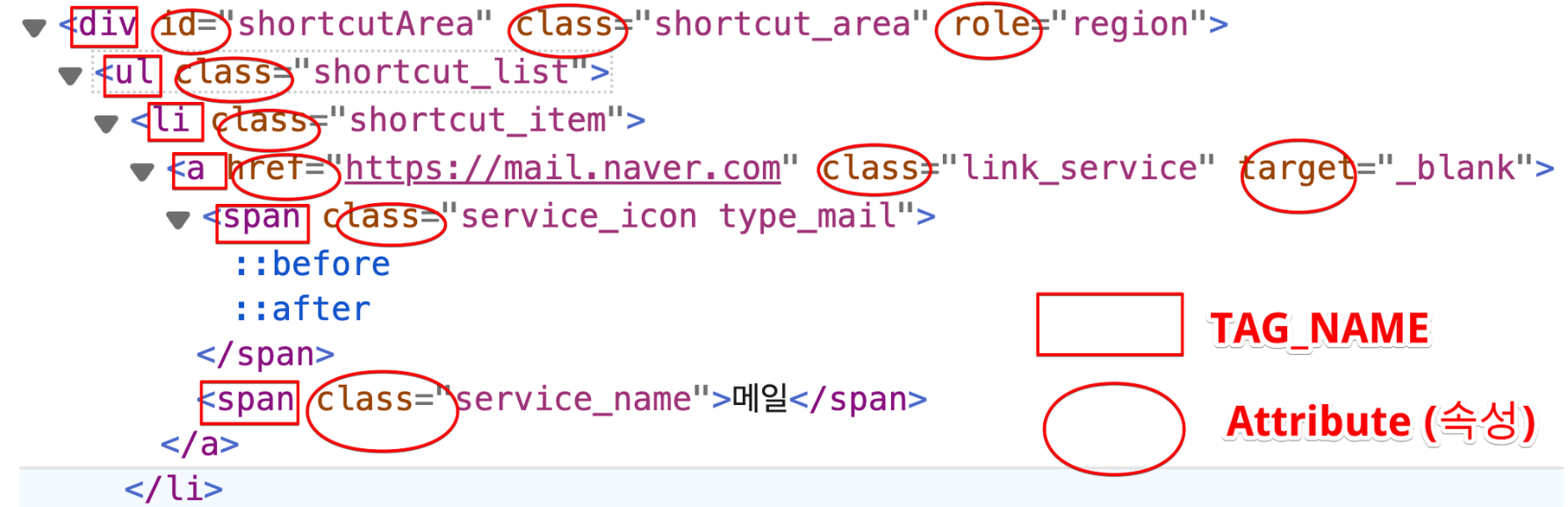
HTML
<!DOCTYPE html> # html 5 버전이라는 뜻
<html lang="ko"> # 문서에서 주로 사용한 언어
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge"> # IE 브라우저 최신버전을 사용하라
<title>Document</title> # 문서 이름
</head>
<body>
</body>
</html>웹페이지의 뼈대
JavaScript
<script>
function login_click() {
alert("로그인 버튼 클릭")
}
</script>홈페이지에 생동감을 주거나 클릭 이벤트 등의 작업 수행
CSS
<style>
body{
font-size: 38px;
color: red;
}
header{
background-color: blue;
}
div {
background-color: aquamarine;
}
</style>디자인 작업
간단한 예제
html
<html>
<head>
<meta charset="utf-8">
<title>홈페이지 제목</title>
</head>
<body>
<input type="text" class="id_class">
<div class="parents">
<input type="text" id="ID" class="id_class">
<input type="password">
</div>
<input type="button" value="로그인">
<a href="https://www.naver.com">네이버 이동하기</a>
</body>
</html>find_elements를 사용해서 password에 접근
browser.find_element(By.CLASS_NAME, 'parents').find_elements(By.TAG_NAME, 'input')[1].click()
parents class -> input tag 순으로 접근
네이버 링크에 접근
browser.find_element(By.TAG_NAME, 'a').get_attribute('href')a tag를 찾아서 get_attribute로 접근
2. 구글 뉴스 크롤링 예제
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Edge()
url = 'https://www.google.com/search?q=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5+%EC%84%9C%EB%B9%84%EC%8A%A4&sca_esv=591053097&tbm=nws&sxsrf=AM9HkKm_rlISK4KN3Z8mVxJ0x9HxtMSZXA:1702604020859&source=lnms&sa=X&ved=2ahUKEwjzr-yeppCDAxWfrlYBHT4XD3gQ_AUoAXoECAEQAw&biw=1859&bih=1093&dpr=1.5'
browser.get(url)- selenium 으로 browser 실행 후 인공지능 서비스에 대한 뉴스 페이지 접근

#첫번째 뉴스의 제목과 내용
title = browser.find_element(By.CLASS_NAME, 'n0jPhd.ynAwRc.MBeuO.nDgy9d').text
print(title)
body = browser.find_element(By.CLASS_NAME, 'GI74Re.nDgy9d').text
print(body)
#언론사, 기사링크, 작성시간
company = browser.find_element(By.CLASS_NAME, 'MgUUmf.NUnG9d').text
print(company)
news_url = browser.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
print(news_url)
uploaded_time = browser.find_element(By.CLASS_NAME, 'OSrXXb.rbYSKb.LfVVr').text
print(uploaded_time)
#첫 페이지의 뉴스 기사와 내용(멀티)
titles = browser.find_elements(By.CLASS_NAME, 'n0jPhd.ynAwRc.MBeuO.nDgy9d')
bodies = browser.find_elements(By.CLASS_NAME, 'GI74Re.nDgy9d')
news_urls = browser.find_elements(By.CLASS_NAME, 'WlydOe')
for title, body, url in zip(titles, bodies, news_urls):
print(title.text)
print(body.text)
print(url.get_attribute('href'))
print()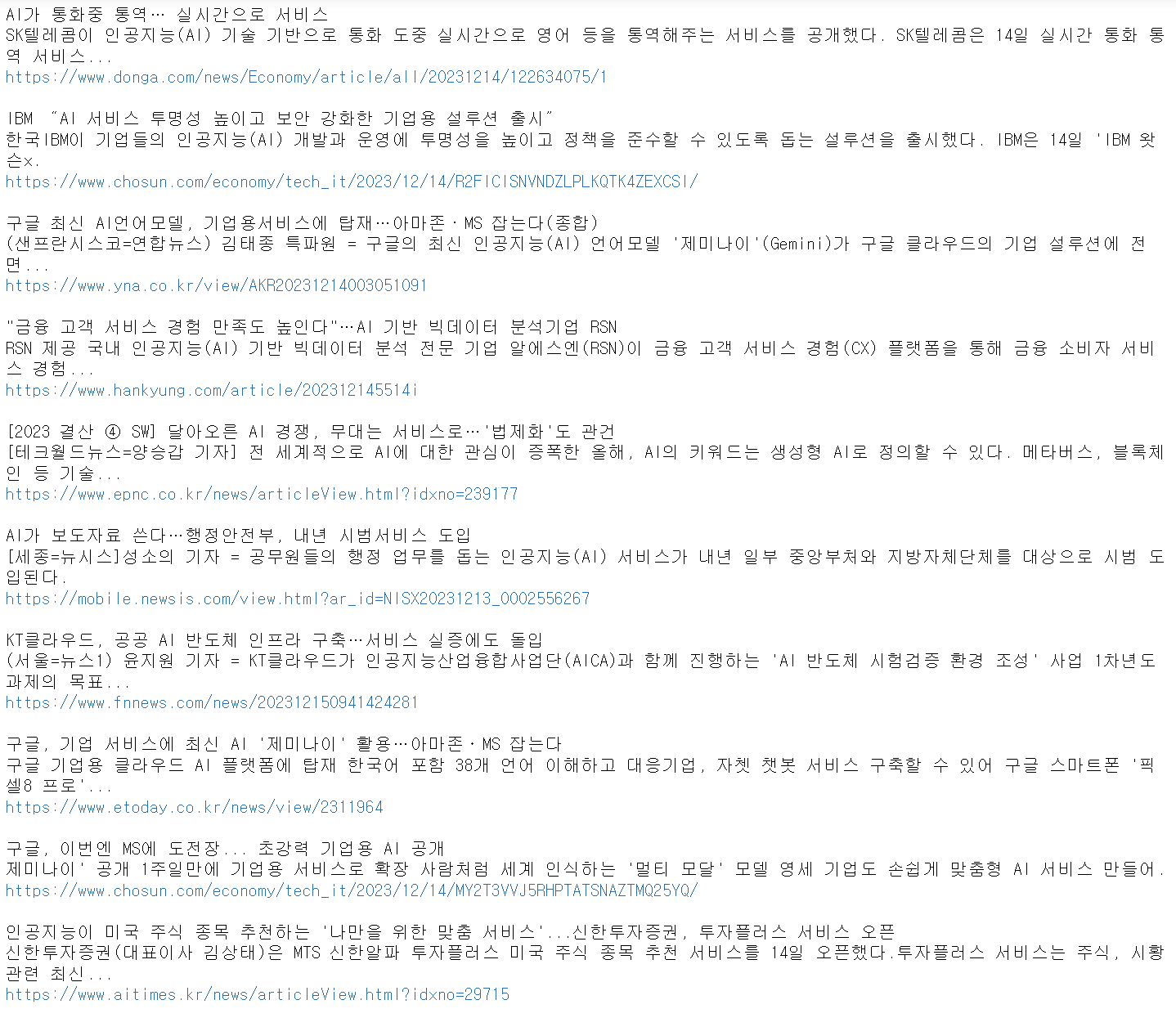
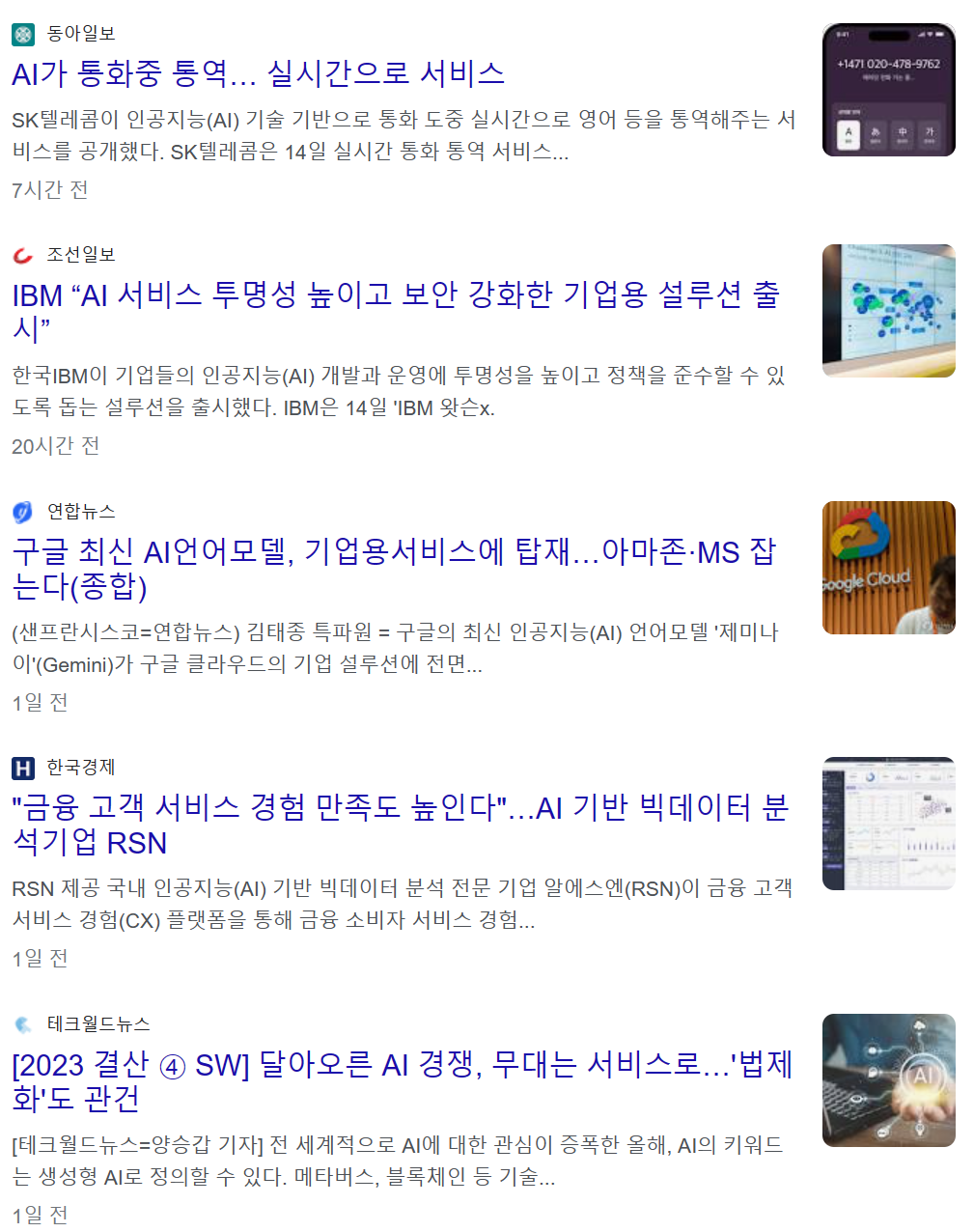
- container 사용
#container
containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
for i in containers:
title = i.find_element(By.CLASS_NAME, 'n0jPhd.ynAwRc.MBeuO.nDgy9d').text
company = i.find_element(By.CLASS_NAME, 'MgUUmf.NUnG9d').text
print(f'({company}){title}')
body = i.find_element(By.CLASS_NAME, 'GI74Re.nDgy9d').text
print(body)
news_url = i.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
print(news_url)
print()- 페이지 이동
#페이지 이동 방법
'''
1. 페이지 버튼 클릭
2. url 변경
1페이지 start=0
2페이지 10
3페이지 20
'''
import time
for i in range(0, 50, 10):
final_url = f'https://www.google.com/search?q=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5+%EC%84%9C%EB%B9%84%EC%8A%A4&sca_esv=591053097&tbm=nws&sxsrf=AM9HkKmBHo51lDVSd7zG-3MdsNd9tyRMNQ:1702604022303&ei=9qx7ZbqOEpbe-Qbv5JLgCw&start={i}&sa=N&ved=2ahUKEwi64cSfppCDAxUWb94KHW-yBLwQ8tMDegQIBRAE&biw=948&bih=1093&dpr=1.5'
browser.get(final_url)
time.sleep(2)3페이지까지 데이터를 크롤링 후 엑셀파일로
import time
import pandas as pd
data_list=[]
for i in range(0, 30, 10):
final_url = f'https://www.google.com/search?q=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5+%EC%84%9C%EB%B9%84%EC%8A%A4&sca_esv=591053097&tbm=nws&sxsrf=AM9HkKmBHo51lDVSd7zG-3MdsNd9tyRMNQ:1702604022303&ei=9qx7ZbqOEpbe-Qbv5JLgCw&start={i}&sa=N&ved=2ahUKEwi64cSfppCDAxUWb94KHW-yBLwQ8tMDegQIBRAE&biw=948&bih=1093&dpr=1.5'
browser.get(final_url)
time.sleep(2)
containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
for i in containers:
title = i.find_element(By.CLASS_NAME, 'n0jPhd.ynAwRc.MBeuO.nDgy9d').text
company = i.find_element(By.CLASS_NAME, 'MgUUmf.NUnG9d').text
body = i.find_element(By.CLASS_NAME, 'GI74Re.nDgy9d').text
news_url = i.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
data = {
'제목':title,
'내용':body,
'언론사':company,
'링크':news_url
}
data_list.append(data)
#파일로 저장
df = pd.DataFrame(data_list)
df.to_csv('google_news.csv', encoding='utf-8-sig')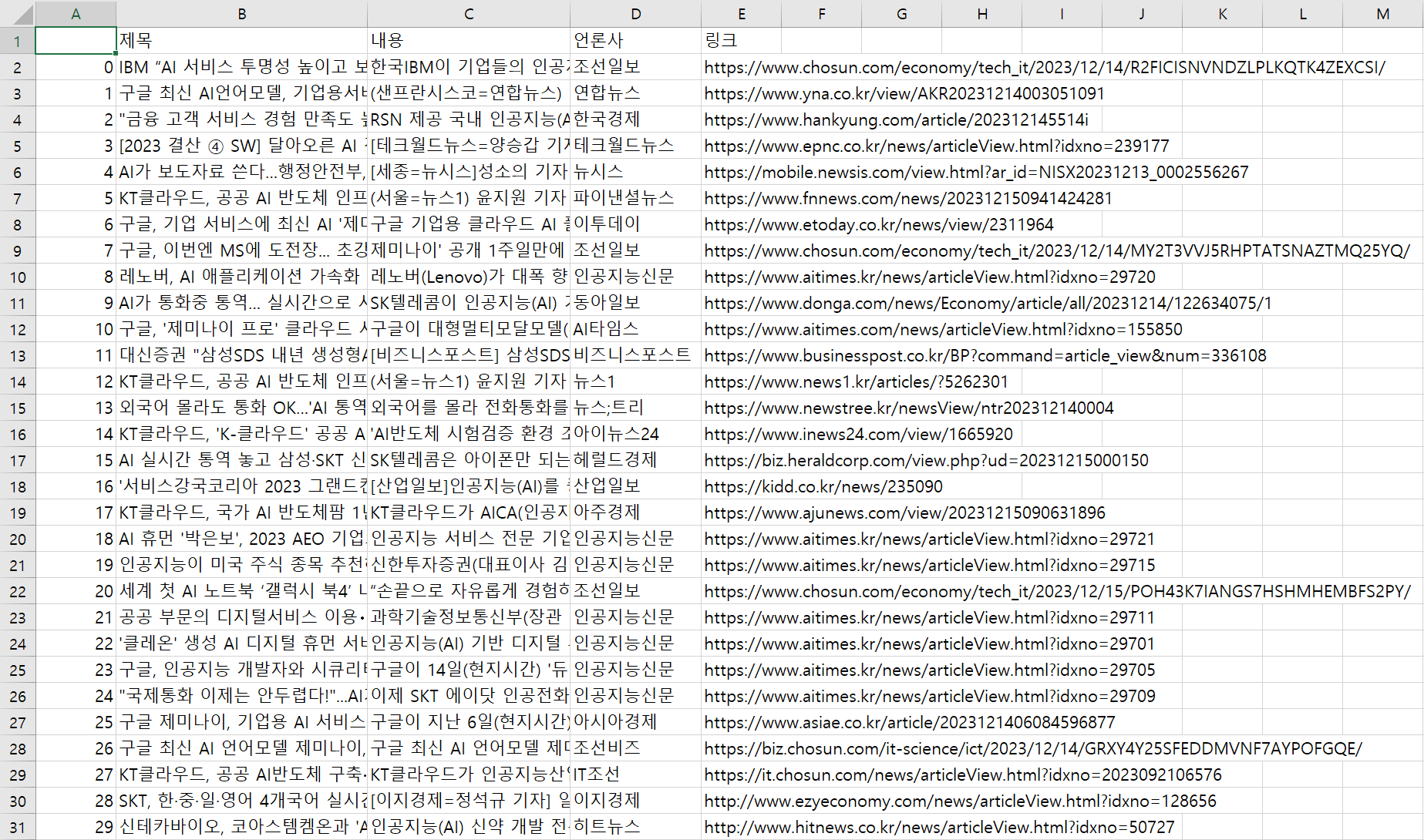
3. DBpia 논문 데이터 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Edge()
word = input("크롤링 하고싶은 논문 주제를 입력해주세요 : ")
url = f'https://www.dbpia.co.kr/search/topSearch?searchOption=all&query={word}'
browser.get(url)원하는 키워드를 입력받아 논문을 조회
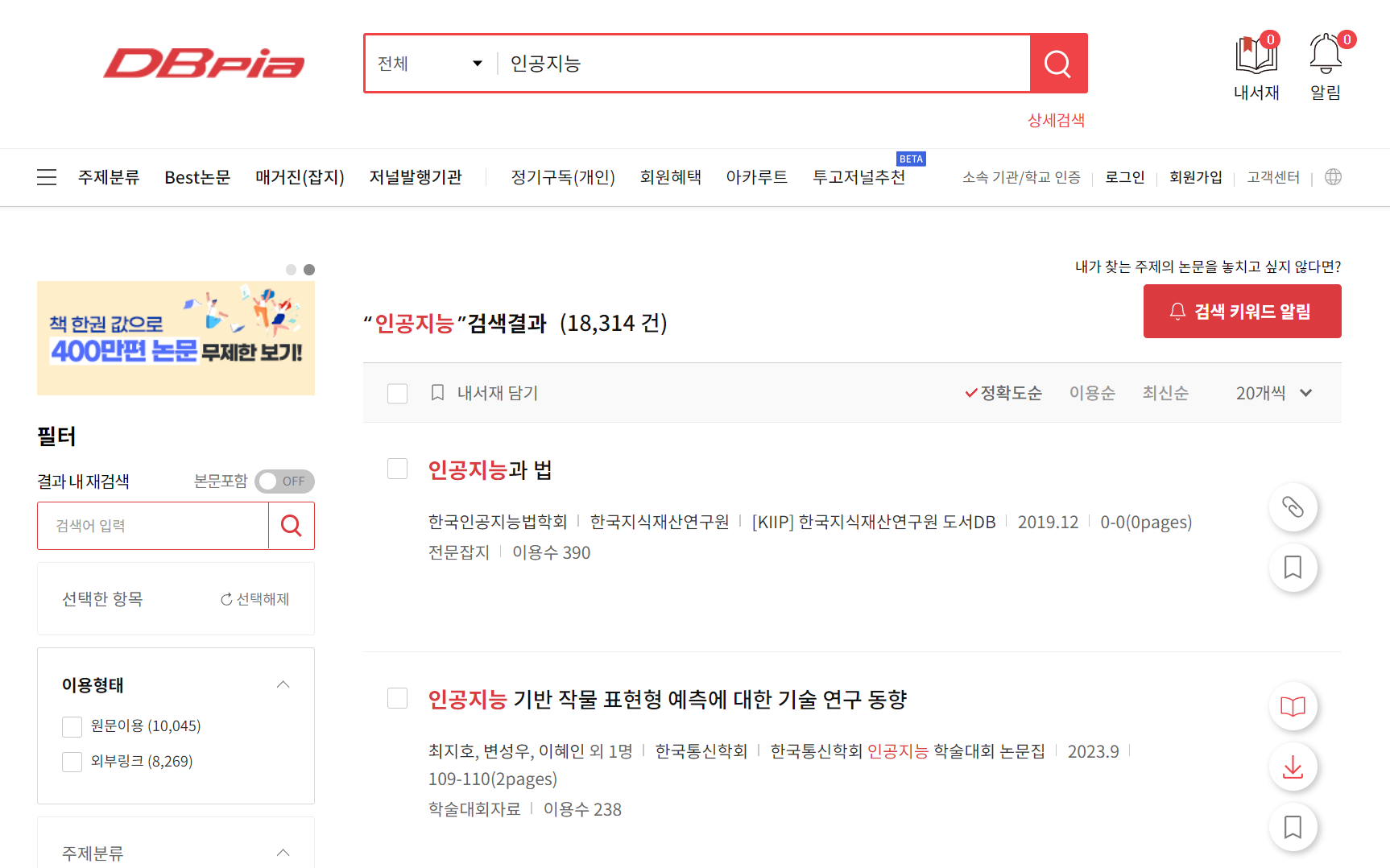
#논문 제목, 학회, 이용수
container = browser.find_elements(By.CLASS_NAME, 'thesis__summary')
data_list=[]
for data in container:
title = data.find_element(By.CLASS_NAME, 'thesis__tit').text
society = data.find_element(By.CLASS_NAME, 'nodeIprd.thesis__item').text
count = data.find_element(By.CLASS_NAME, 'thesis__item.thesis__useCount').text.split()[1]
print(title, society, count)
data = {
'제목' : title,
'학회' : society,
'이용수' : count
}
data_list.append(data)
- 3페이지 까지
#페이지 xpath
#//*[@id="pageList"]/a[2]
import time
data_list=[]
for i in range(1,4):
xpath = f'//*[@id="pageList"]/a[{i}]'
browser.find_element(By.XPATH,xpath).click()
time.sleep(2)
container = browser.find_elements(By.CLASS_NAME, 'thesis__summary')
for data in container:
title = data.find_element(By.CLASS_NAME, 'thesis__tit').text
society = data.find_element(By.CLASS_NAME, 'nodeIprd.thesis__item').text
count = data.find_element(By.CLASS_NAME, 'thesis__item.thesis__useCount').text.split()[1]
print(title, society, count)
data = {
'제목' : title,
'학회' : society,
'이용수' : count
}
data_list.append(data)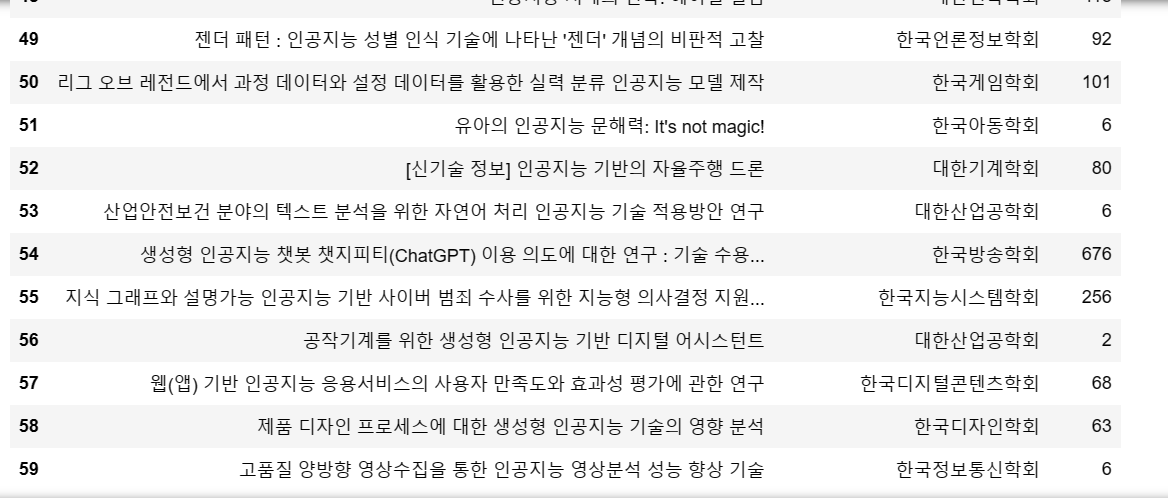
4. 표데이터 크롤링
#표데이터 크롤링
url = 'https://finance.naver.com/'
browser.get(url)
import pandas as pd
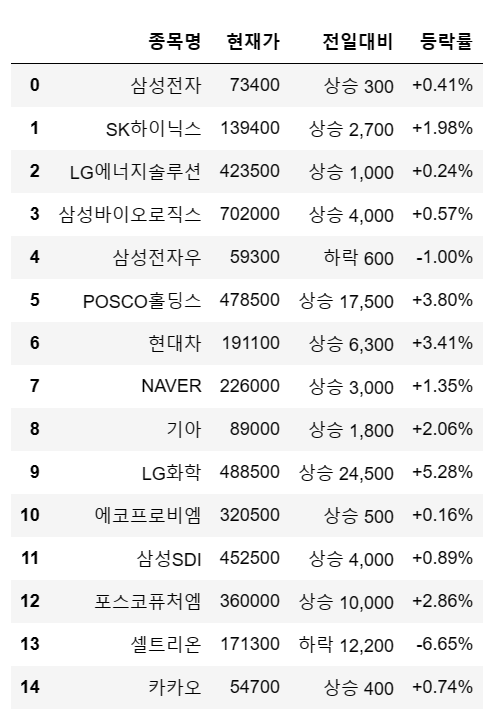
data_list = pd.read_html(url, encoding='euc-kr')
data_list[3]
5. 베스트 셀러 데이터 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Edge()
url = 'https://www.yes24.com/Product/category/bestseller?CategoryNumber=001&sumgb=06'
browser.get(url)베스트 셀러 페이지 표시
#1페이지 베스트셀러 책제목 저자 출판사 판매지수 -> 엑셀
import pandas as pd
book_list = []
container = browser.find_elements(By.CLASS_NAME,'itemUnit')
for book in container:
title = book.find_element(By.CLASS_NAME,'gd_name').text
auth = book.find_element(By.CLASS_NAME,'info_auth').find_element(By.TAG_NAME,'a').text
pub = book.find_element(By.CLASS_NAME, 'info_pub').text
saleNum = book.find_element(By.CLASS_NAME,'saleNum').text.split()[1]
data ={
"제목" : title,
"저자" : auth,
"출판사" : pub,
"판매지수" : saleNum
}
book_list.append(data)
df = pd.DataFrame(book_list)
df.to_csv('best_seller.csv', encoding='utf-8-sig')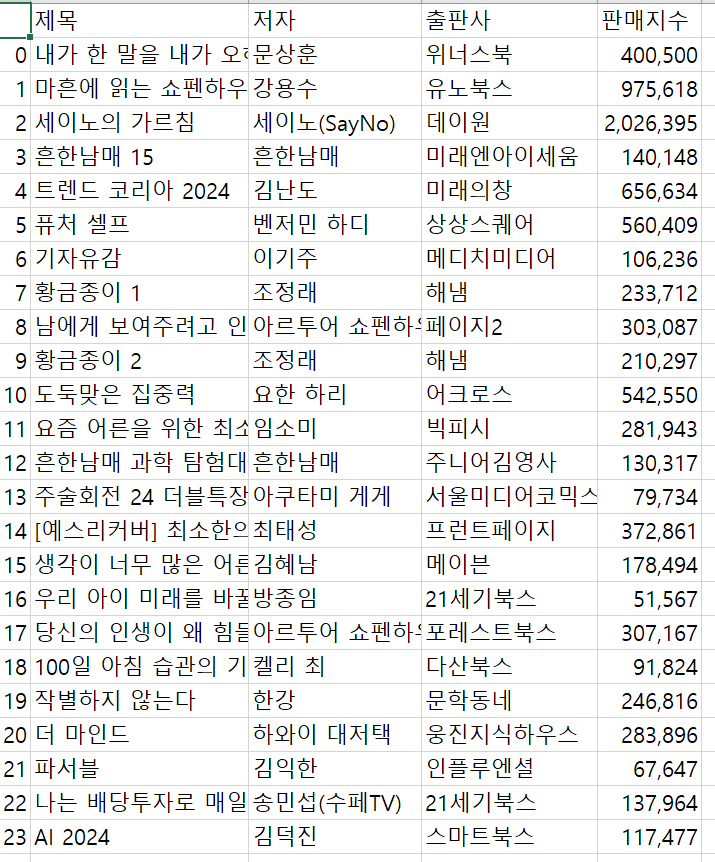
6. SRT 자동 예매
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Edge()
url = 'https://etk.srail.kr/cmc/01/selectLoginForm.do?pageId=TK0701000000'
browser.get(url)srt 로그인 페이지 접근
browser.find_element(By.ID,'srchDvCd3').click()
browser.find_element(By.ID,'srchDvNm03').send_keys('00000000000')
browser.find_element(By.ID,'hmpgPwdCphd03').send_keys('password')
browser.find_element(By.XPATH,'//*[@id="login-form"]/fieldset/div[1]/div[1]/div[4]/div/div[2]/input').click()휴대전화 번호로 로그인
reserve_url = 'https://etk.srail.kr/hpg/hra/01/selectScheduleList.do?pageId=TK0101010000'
browser.get(reserve_url)예매 페이지접근
browser.find_element(By.ID,'dptRsStnCdNm').click()
browser.find_element(By.ID,'dptRsStnCdNm').clear()
browser.find_element(By.ID,'dptRsStnCdNm').send_keys('부산')
browser.find_element(By.ID,'arvRsStnCdNm').click()
browser.find_element(By.ID,'arvRsStnCdNm').clear()
browser.find_element(By.ID,'arvRsStnCdNm').send_keys('수서')
browser.find_element(By.XPATH,'//*[@id="dptTm"]/option[12]').click()
//*[@id="search-form"]/fieldset/div[1]/div/div/div[3]/a
browser.find_element(By.CLASS_NAME,'inquery_btn').click()출발역 도착역 시간 지정 후 조회
import time
for i in range(1000):
browser.implicitly_wait(5)
is_reserve = browser.find_element(By.XPATH,'//*[@id="result-form"]/fieldset/div[6]/table/tbody/tr[1]/td[6]/a')
if is_reserve.text == '매진':
time.sleep(0.3)
browser.refresh()
print(f'{i}번째 시도입니다.')
else:
is_reserve.click()
break예매에 들어갈 수 있을 때 까지 시도
