1. 데이터 분석 기초
목표
-
파이썬을 활용한 데이터 분석 입문
-
공공 데이터를 활용해 데이터분석 실습
-
Numpy, Pandas, Matplotlib와 같은 데이터 분석 라이브러리 기초 사용법에 대한 이해
데이터 사이언스 영역
- data analysis or analyst
-
데이터에서 인사이트를 뽑아내는 역할
-
통계 지식이 필요 + 도메인 + 데이터 + 분석스킬
-
ex) pm으로써의 DS or 데이터 분석가
-
성과 측정 지표 정의
-
MECE 기법
-
결제 전환율 개선
-
데이터 로그 설계
-
AB 테스트
-
-
-
리포트 작성
- data engineering
-
데이터를 수집 및 저장한느 역할 (빅데이터 시스템 구축)
-
기존의 백엔드 엔지니어가 hadoop에 대한 인해를 바탕으로 커리어 전환

- data visualization
-
데이터 시각화 작업
-
기존의 프론트엔드 엔지니어가 많이 존재

-
대시보드
- 대표적인 예시 : 자동차 계기판
대표적인 데이터 분석 패키지
- 대화형 파이썬 툴
-
jupyter, colab
- 웹 브라우저 기반에서 파이썬 코드를 작성하고 실행하게 도와주는 툴
- 통계 및 수학적 계산을 도와주는 라이브러리
-
Numpy
- Numarray와 Numeric이라는 기존 파이썬 패키지를 계승해서 나온 수학 및 과학 연산을 위한 파이썬 패키지
- 선형대수, 행렬 또는 다차원 배열을 쉽게 처리할 수 있도록 도와주는 패키지
- 수학적인 연산처리에도 자주 활용됨.
- 데이터 핸들링(엑셀) - 데이터 정제(전처리)
-
Pandas/SQL/테블로
- panda는 panel data와 analysis 줄여서 표현
- 데이터 조작 및 분석을 위한 파이썬 패키지. (원래는 금융 데이터 분석을 위해 만들어짐)
- 레이 달리오 <원칙>
- 테이블 형태의 데이터를 다루는 DataFrame 자료형을 제공
- SQL과 같은 데이터 조회, 분석, 삭제, 수정등의 작업이 가능
- 데이터 시각화
-
Matplotlib -> seaborn -> plotly
-
데이터 시각화를 도와주는 툴로써 그래프와 차트 등을 그릴 수 있게 도와준다.
-
Matplotlib 패키지에서 지원하지 않는 시각화 작업 가능
-
- 머신러닝/딥러닝 -> 미래를 예측하기 위해 활용 & 패턴찾기
-
scikit-learn
-
Tensorflow
데이터 분석이란?
위와 같은 툴들 또는 파이썬을 잘 알아야 한다?
분석툴을 잘 다루면 데이터 분석을 잘 할 수 있을까? → X
⇒
파이썬 잘하고, 툴 잘 다루면 분석에 도움을 받을 수 있으나,
그것이 데이터 분석의 본질은 아니다.
그래서 BI(Business Inteligence)-Samsung이 만든 BrighticsAI 툴들을 마주하면 드는 생각이
“이걸 어디서부터 어떻게 접근해야 하는 거지?”하는 생각이 드실 겁니다.
본질이 비어서 그런 것.
- 본질 : 데이터(석유)를 통해 얻고자 하는 것이 무엇인가?
- 분석의 목적에 맞게 툴을 배워야 할 것이다.
- 마케팅 분석이 목적인가?
- 로그 데이터 분석이 목적인가?
- 분석의 목적에 맞게 툴을 배워야 할 것이다.
데이터 분석 과정
1) 데이터 분석 설계
- 방향성 기획 (⇒데이터를 통해 얻고자 하는 것이 무엇인가?)
- 방법론 검토
- 문제 정의
- 데이터 분석을 통해 무엇을 알고 싶은지, 도출하고자 하는 결론은 무엇인지?
- 가설 설정
- H사 프로젝트
- 보험 영업팀이 고객데이터 100만을 갖고 있어요. 근데 도대체 누구한테 전화를 해야해?
- 금융 자산 금액, 최종 학위, 나이, 차량 운용 여부, 기존 보험 금액, 동네, 자가여부 (컬럼이 수백개) → 보험을 가입할 확률이 높은 고객에게 먼저 전화를 한다.
- 보험 영업팀이 고객데이터 100만을 갖고 있어요. 근데 도대체 누구한테 전화를 해야해?
- H사 프로젝트
데이터 준비 ⇒ SQL, Crawaling, 개발자에게 요청, 공공데이터 API
- 데이터 불러오기
- 형태 파악하기
데이터 가공 (70~80%) ⇒ 파이썬 / SQL
- 추출 및 정제
garbage in garbage out요리 재료(데이터)를 샀으니 바로 요리를 하는 것이 아니라 → 요리 재료를 손질해야겠죠? - 파생 변수(컬럼) 생성
- column1, column2, column3, column4 ⇒ (column1+column2)/2
- 구별 외국인 수 / 구별 인구수
⇒ 해당 구의 외국인 비율
⇒ 인사이트를 얻을 수 있는 컬럼을 생성하셔야 합니다.
- 데이터 구조에 대한 전처리
- 매출 데이터와 상품 데이터를 어떻게 결합할 것인지
- 데이터 내용에 대한 전처리
- 일별 데이터, 월별 또는 연간 데이터로 변환
- 분석에 도움이될만한 새로운 컬럼을 생성
4) 데이터 분석
- 통계 분석
- 데이터의 패턴을 찾아본다. ⇒ 설득을 위해서.
- 그래프 및 시각화
- 어떤 형태로 시각화 했을 때 내가 원하는 방향으로 상대방을 잘 설득할 수 있을지? 에 대한 고민.
5) 결론 도출 ⇒ storytelling, 포인트: 설득 / 납득
- 분석 결과 해석
- 분석 결과 정리
데이터 소스
2. Pandas
- Series
- 1개의 컬럼값으로 구성된 1차원 데이터 셋
import pandas as pd
data = ["A", 'B', 'C', 'D', 'E']
se = pd.Series(data)
print(se)
print(type(se))
print(se.index)
print(se.values)
print(se[0])
print(se[0:3])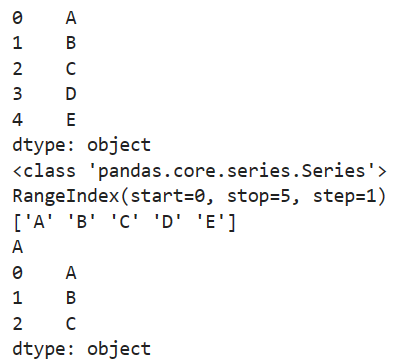
data = ["A", "B", "C", "D"]
se = pd.Series(data, index=['a', 'b', 'c', 'd'])
se.index = [1,2,3,4]
se
- DataFrame
- 2개 이상의 컬럼으로 구성된 2차원 데이터셋
data = {
'country' : ['kor', 'usa', 'china', 'japan'],
'rank' : [1,2,3,4],
'grade' : ['A', 'B', 'C', 'D']
}
df = pd.DataFrame(data)
df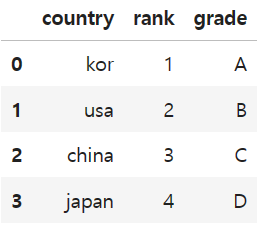
- 데이터 셀랙션 => 데이터를 가져오는 방법
- df.컬럼명 or df['컬럼명']
print(df.country)
print(df['grade'])
# 2개 이상의 컬럼을 가져오는 방법
cols1 = ['country', 'grade']
cols2 = ['country', 'rank']
cols3 = ['rank', 'grade']
print(df[cols1])

- df.loc[인덱스값, 컬럼명]
df.loc[0:3, ['country', 'rank']]
- df.iloc[인덱스, 컬럼인덱스] = location 베이스
#df.loc[0:3]
df.iloc[0:3, [0,3]]
- boolean indexing
# df[df['rank'] < 3]
df.loc[df['rank'] < 3, 'grade']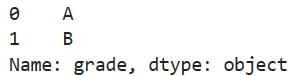
- 데이터 삭제 추가
- 1) 컬럼 데이터 추가
president = ['yoon', 'biden', 'jinping', 'kishida']
df['president'] = president
df- 2) 행 데이터 추가
df.loc[4] = ["singapole", 2, "B", "Tharman"] # 세금: 상속세 0
df
- 3) 행 데이터 삭제
df.drop([3])
- 덮어쓰기
df.drop([3], inplace=True)
df = df.drop([3])- 4) column 삭제
df.drop(columns=['grade'])
df.drop('grade', axis=1)
- 기타
- 합, 평균, 최대, 최소, 요약 등
df.sum()
df.mean()
df.max()
df.min()
df.info()
df.describe()-
NaN 처리
-
Null 체크 : isnull(), isna()
-
- fillna() : 비어있는 데이터를 채운다
-
- dropna() : 비어있는 데이터를 제거한다
-
df.loc[2, 'grade'] = None
df.isna().sum()
df.fillna(value='C')
df
df.dropna()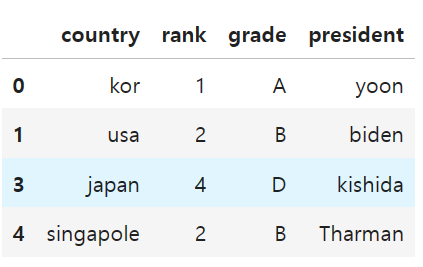
- 예제
import pandas as pd
data = {
'영화' : ['명량', '극한직업', '신과함께-죄와 벌', '국제시장', '괴물', '도둑들', '7번방의 선물', '암살'],
'개봉 연도' : [2014, 2019, 2017, 2014, 2006, 2012, 2013, 2015],
'관객 수' : [1761, 1626, 1441, 1426, 1301, 1298, 1281, 1270], # (단위 : 만 명)
'평점' : [8.88, 9.20, 8.73, 9.16, 8.62, 7.64, 8.83, 9.10]
}
df = pd.DataFrame(data)
df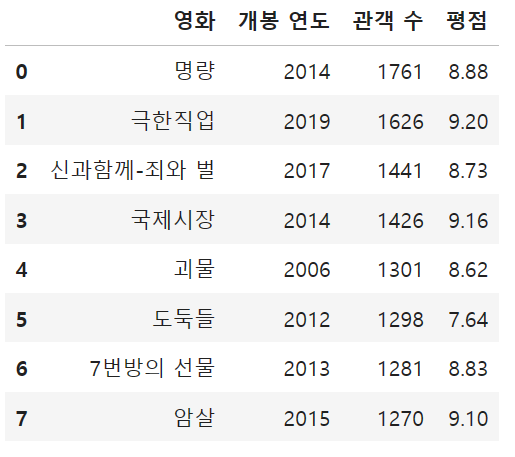
1) 전체 데이터 중에서 '영화' 정보만 출력하시오.
df['영화']2) 전체 데이터 중에서 '영화','평점' 정보를 출력하시오.
cols = ['영화', '평점']
df[cols]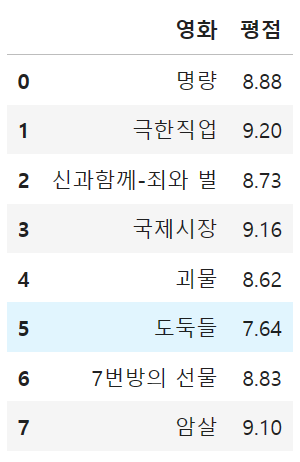
3) 2015년 이후에 개봉한 영화 데이터 중에서 '영화','개봉연도' 정보를 출력하시오.
- (0) 개봉 연도
- (1) 2015년 이후에 개봉한 영화
- (2) 추출한 데이터에서 컬럼값이 '영화', '개봉연도' 인 데이터를 출력한다.
cols = ['영화', '개봉 연도']
df.loc[df['개봉 연도'] >= 2015, cols]
df[df['개봉 연도'] >= 2015][cols]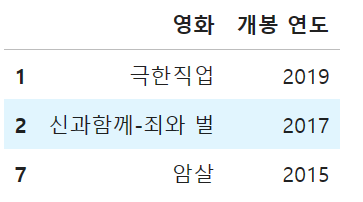
4) 주어진 계산식을 참고하여 '추천 점수' Column을 추가하시오.
- 추천 점수 = (관객수 * 평점) // 100
p = df['관객 수']
v = df['평점']
score = (p*v)//100
df['추천 점수'] = score
df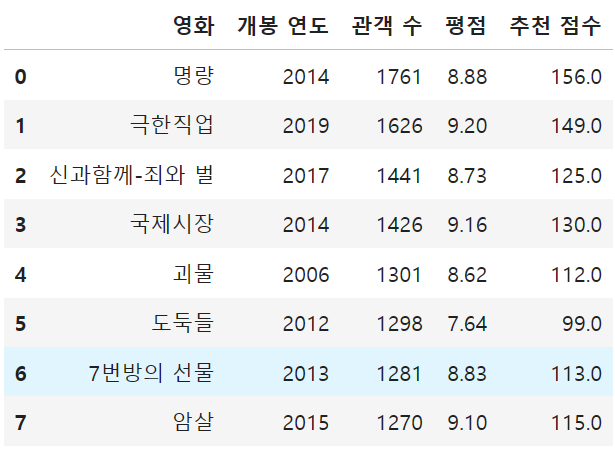
5) 전체 데이터를 '개봉연도' 기준 내림차순으로 출력하시오.
df.sort_values(by=['개봉 연도'], ascending = False)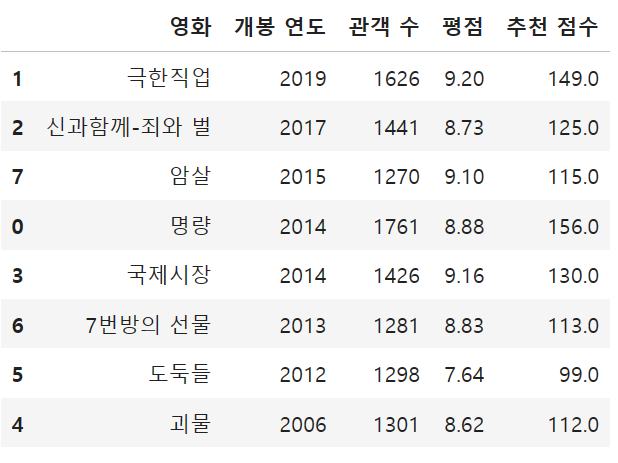
3. 와인 데이터 실습
와인 데이터 불러오기
import pandas as pd
df = pd.read_csv('winequality.csv')
df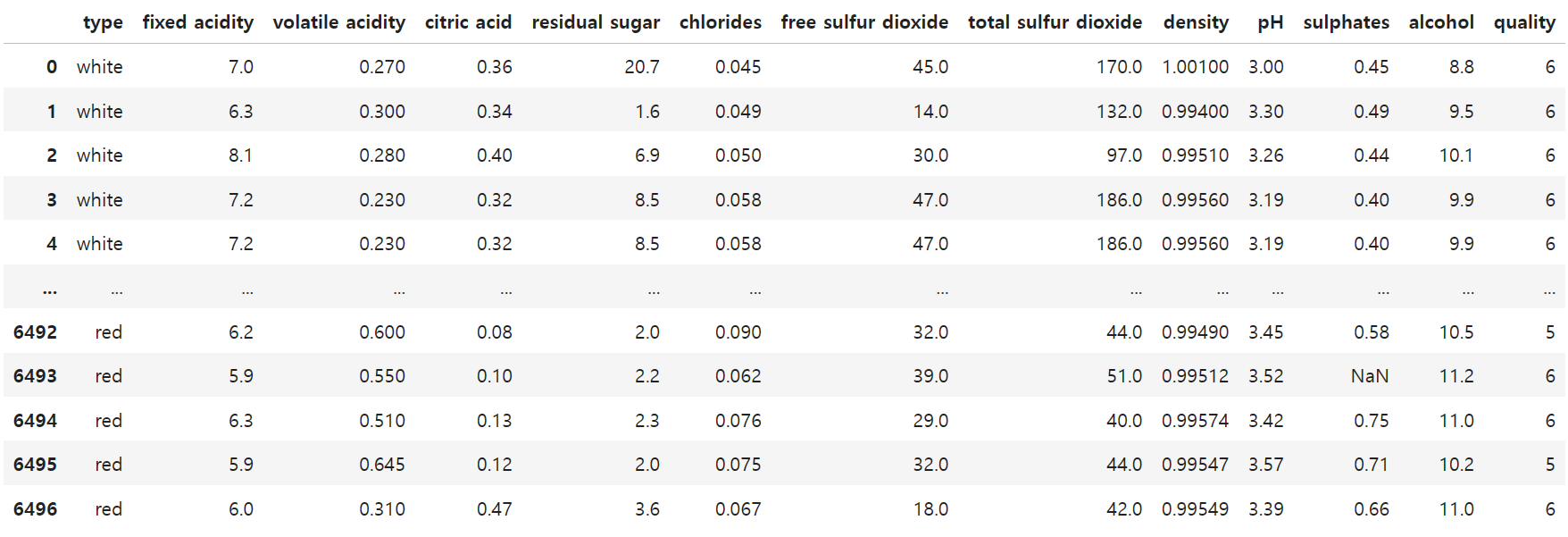
데이터 핸들링
# alcohol 컬럼의 평균 값
df['alcohol'].describe()
# 'residual sugar' 열에서 최대값(max)과 최소값(min)의 차이를 계산하세요.
df['residual sugar'].max() - df['residual sugar'].min()
# 우리가게의 alcohol, qulality, residual sugar의 평균값은 어떻게 되는가?
df[['alcohol', 'quality', 'residual sugar']].mean()
# 우리 가게의 와인의 등급별 구성은 어떻게 되어있지? => quality에 따른 갯수가 어떻게 되지?
df['quality'].value_counts().sort_index().to_frame()
#'fixed acidity' 열과 'pH' 열의 값이 각각 3 이상, 4이상 인 데이터만 추출하여 데이터 프레임을 생성하시오.
df[(df['fixed acidity'] > 3) & (df['pH'] > 4)]
4. NBA 데이터
데이터 불러오기
import pandas as pd
df = pd.read_csv('nba.csv')
df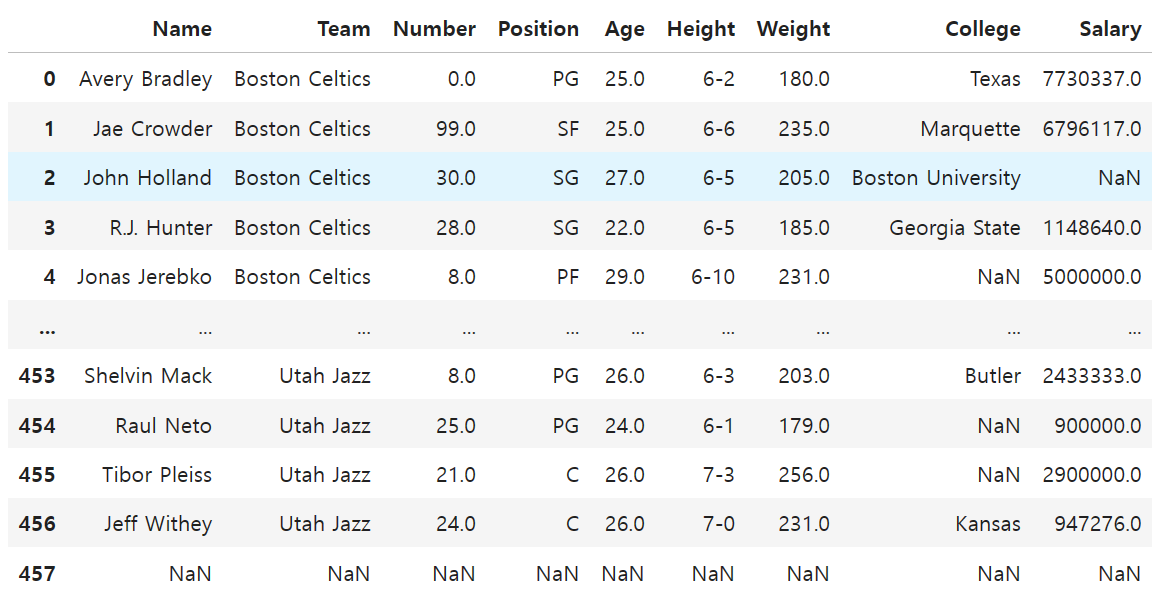
# 현재 각 팀별 선수는 몇 명씩 있나요?
df['Team'].value_counts()
# (1) 팀별 평균 연봉은 어떻게 되나요?
# (2) 평균 연봉이 가장 높은 상위 5개 팀은?
df.groupby('Team')['Salary'].mean().sort_values().tail()
# 포지션 별 연봉과 신장 평균
df.groupby('Position')['Salary'].mean().sort_values()
df.groupby('Position')['Weight'].mean().sort_values()
#소속 대학 별 인원 수
df['College'].value_counts().head(10)
df.groupby('College').size().sort_values(ascending=False)
#NaN 포함 데이터 drop
df.dropna(how = 'any', inplace = True)
#feet to cm
def make_cm(data):
feet = int(data.split('-')[0])
inch = int(data.split('-')[1])
cm = feet * 30.48 + inch * 2.54
return cm
df['Height(cm)'] = df['Height'].apply(make_cm)
df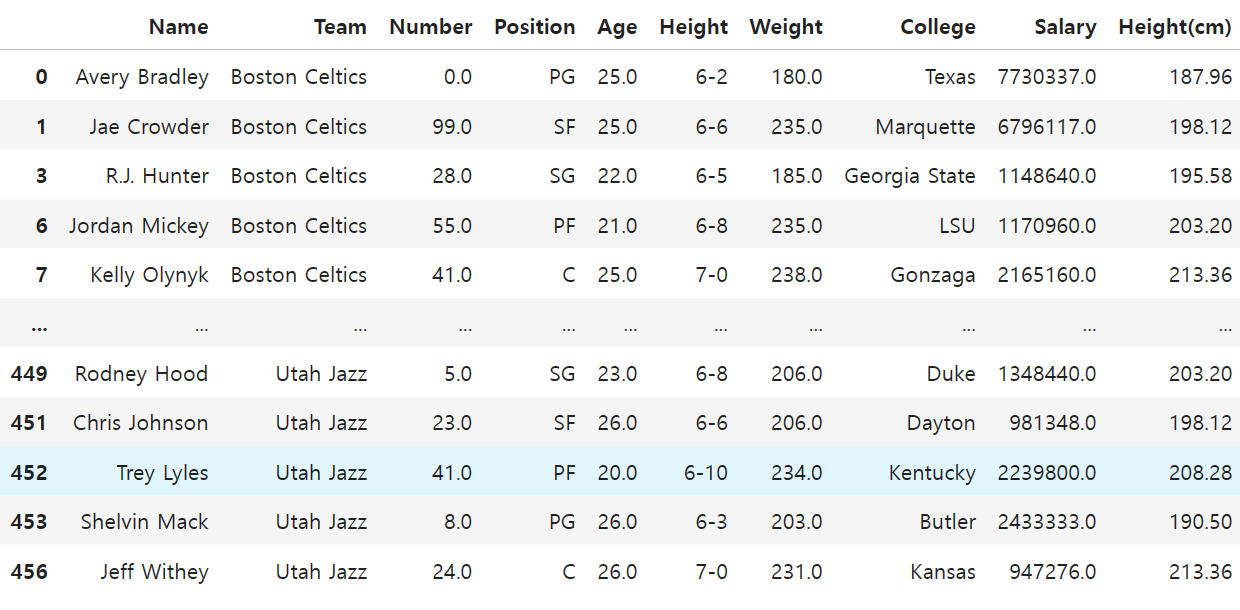
5. 시각화(Matplotlib)
plot
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0,10,1)
y = np.sin(x)
y2 = np.cos(x)
#도화지 변경
plt.figure(facecolor = 'pink', figsize=(12,8), dpi = 400)
plt.title('sin & cos graph')
plt.xlabel('time')
plt.ylabel('amplitude')
plt.plot(x, y, label = 'sin', marker = 'o', markersize = 30, markeredgecolor='red', linestyle='--')
plt.plot(x, y2, label = 'cos', marker = 'x')
plt.grid()
plt.legend(loc = (1, 0.05))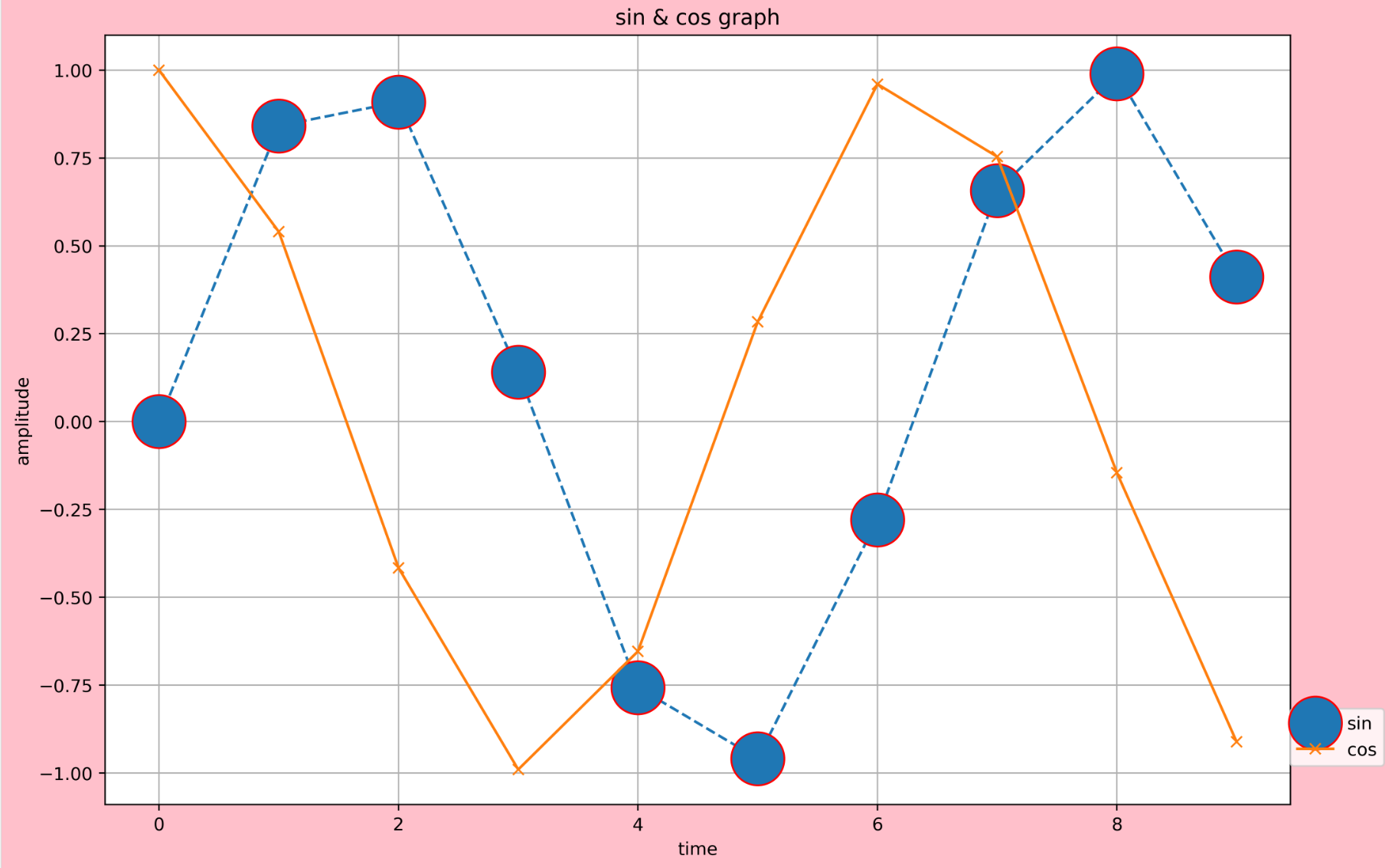
scatter plot
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/KNN_data.csv')
df
large = df[df['Label'] == 'Large']
medium = df[df['Label'] == 'Medium']
small = df[df['Label'] == 'Small']
plt.scatter(large['x'], large['y'], label = 'large')
plt.scatter(medium['x'], medium['y'], label = 'medium')
plt.scatter(small['x'], small['y'], label = 'small')
plt.legend()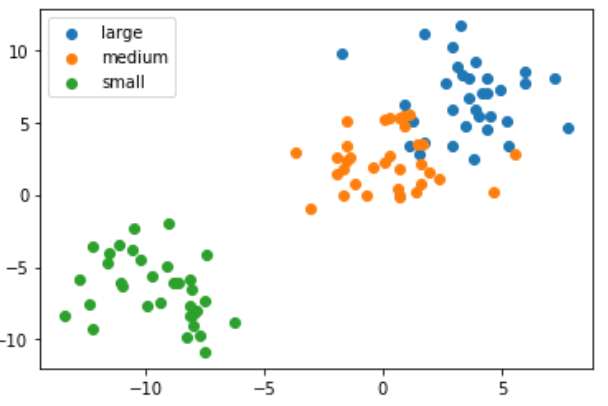
bar chart
labels = ['kor', 'usa', 'china']
values = [100, 130, 150]
colors = ['r', 'g', 'b']
plt.ylim(90, 160)
plt.bar(labels, values, color = colors, alpha = 0.5)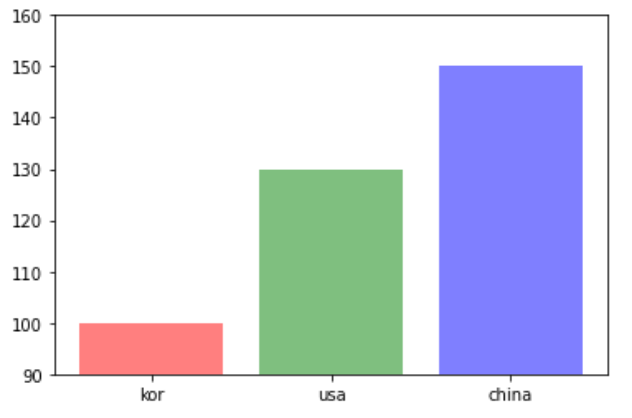
번외 - 한글출력
import matplotlib.font_manager as fm #폰트 매니저를 불러온다.
font_fname = 'C:/Windows/Fonts/NanumGothic.ttf' #적용할 폰트
font_family = fm.FontProperties(fname=font_fname).get_name() #폰트 설정
plt.rcParams["font.family"] = font_family #폰트 적용
plt.rcParams['font.size'] = 15. #상단 제목 폰트 크기
plt.rcParams['xtick.labelsize'] = 11. #x 축 라벨 글씨 크기
plt.rcParams['ytick.labelsize'] = 11. #y 축 라벨 글씨 크기
plt.rcParams['axes.labelsize'] = 15. #하단 라벨 글시 크기예제
import pandas as pd
import matplotlib.pyplot as plt
data = {
'영화' : ['명량', '극한직업', '신과함께-죄와 벌', '국제시장', '괴물', '도둑들', '7번방의 선물', '암살'],
'개봉 연도' : [2014, 2019, 2017, 2014, 2006, 2012, 2013, 2015],
'관객 수' : [1761, 1626, 1441, 1426, 1301, 1298, 1281, 1270], # (단위 : 만 명)
'평점' : [8.88, 9.20, 8.73, 9.16, 8.62, 7.64, 8.83, 9.10]
}
df = pd.DataFrame(data)
df
## 1. 영화 데이터를 활용하여 x 축은 영화, y축은 평점인 막대(bar) 그래프를 만드시오.
## (1) 막대그래프
## (2) x=영화, height=평점
## 2. 앞에서 만든 막대 그래프에 제시된 세부 사항을 적용하시오.
## - 제목: 국내 Top 8 영화 평점 정보
## - x축 label: 영화 (90도 회전)
## - y축 label: 평점
x = df['영화']
y = df['평점'].sort_values()
plt.figure(figsize=(12,4))
plt.bar(x, y)
plt.title('국내 Top 8 영화 평점 정보')
plt.xlabel('영화')
plt.xticks(rotation=45)
plt.ylabel('평점')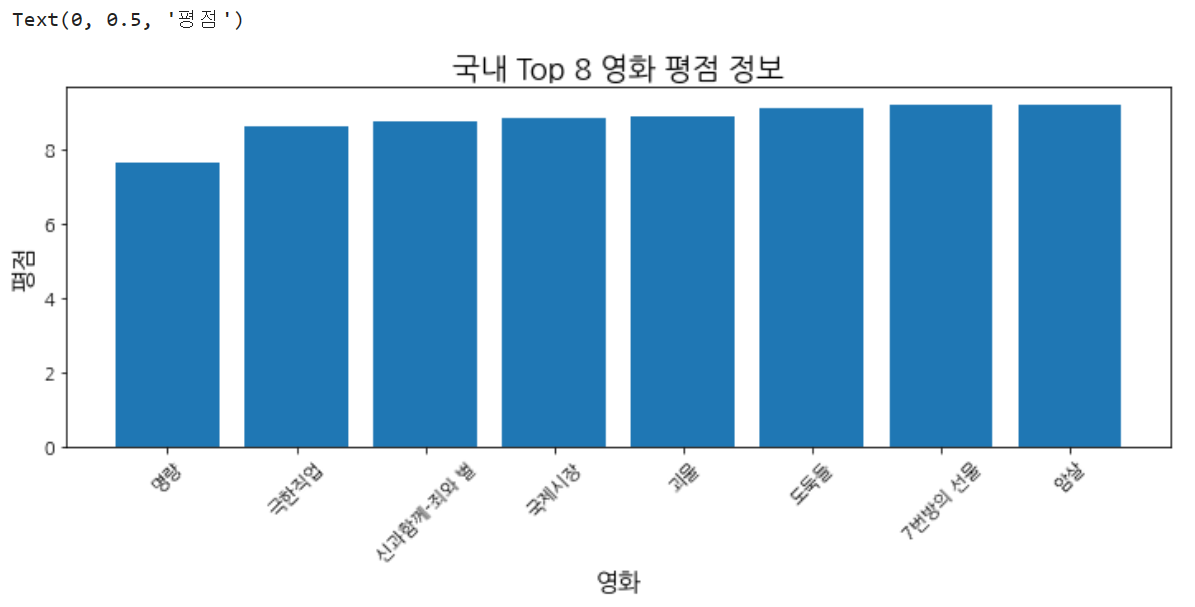
## 3. 개봉 연도별 평점 변화 추이를 꺾은선 그래프(plot)로 그리시오.
## (1) 개봉 연도별 평점
## (2) x축에는 연도 데이터가 들어가야 하고, y축에는 평점 데이터가 들어가면 되겠네요.
## 4) 앞에서 만든 그래프에 제시된 세부 사항을 적용하시오.
## - marker: 'o'
## - x축 눈금: 5년 단위 (2005, 2010, 2015, 2020)
## - y축 범위: 최소 7, 최대 10
year = df.groupby('개봉 연도').mean()
x = year.index
y = year['평점']
plt.plot(x, y, marker='o')
plt.title('국내 Top 8 영화 평점 정보')
plt.xlabel('연도')
plt.xticks([2005, 2010, 2015, 2020])
plt.ylabel('평점')
plt.ylim(7,10)
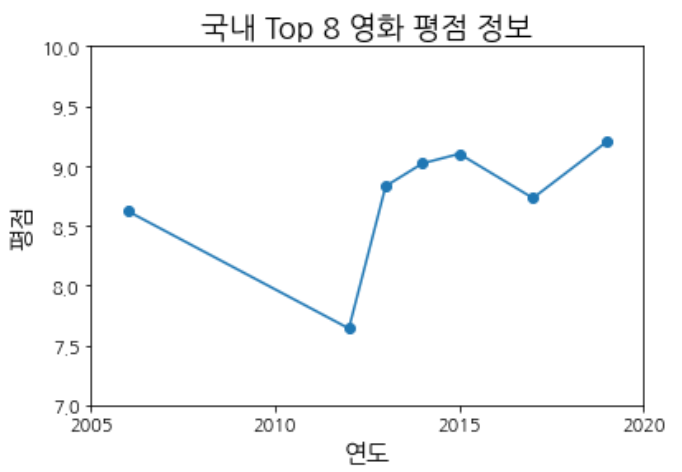
6. seaborn
import seaborn as sns
df = sns.load_dataset('tips')
df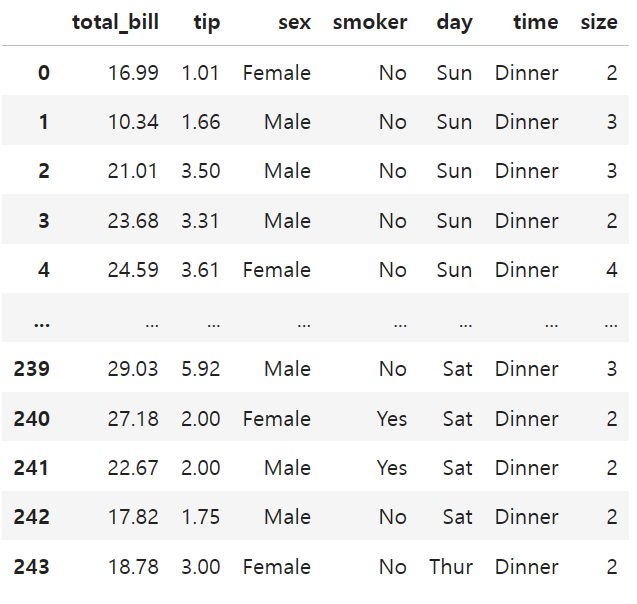
boxplot
sns.boxplot(data=df, x='day', y='tip') # 요일별 팁 데이터
sns.swarmplot(data=df, x='day', y='tip')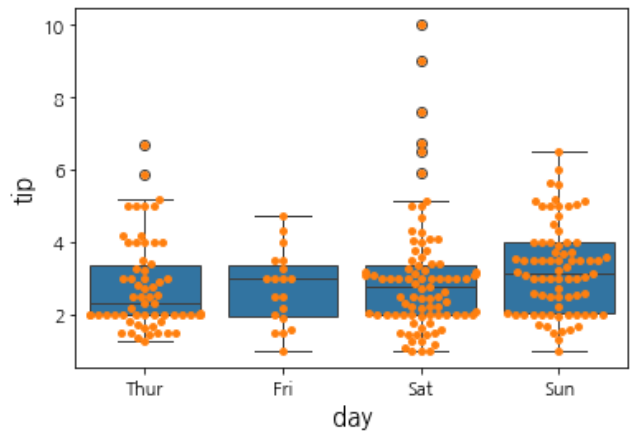
LMplot (Linear Model Plot)
컬럼들간 또는 각 변수들 간의 상관관계
# 전체 계산 금액(total_bill)이 높을수록 -> 팁도 높을 가능성이 높은가?
sns.lmplot(data=df, x='total_bill', y='tip')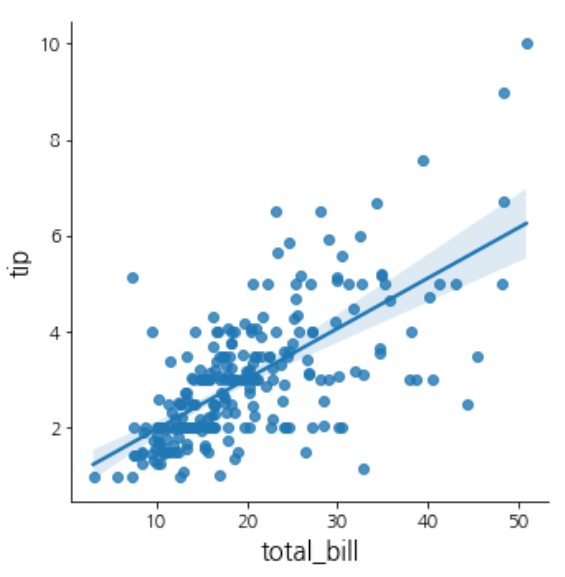
correlation
df.corr()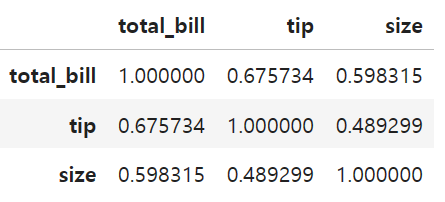
시계열 데이터 시각화(heatmap)
df = sns.load_dataset('flights')
df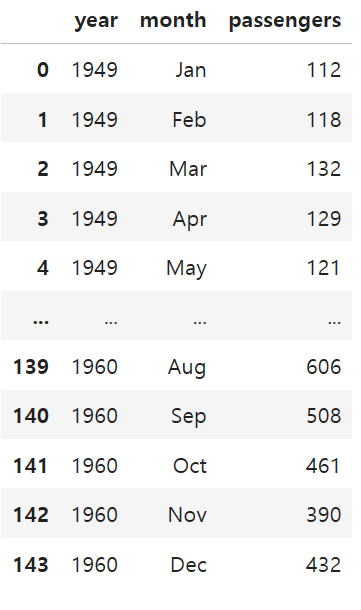
반복되는 데이터를 한눈에
#index=, columns=, values=
df_pivot = df.pivot(index='month', columns='year', values='passengers')
sns.heatmap(data=df_pivot, annot=True, fmt='d')
7. 타이타닉 데이터 분석
- Passengerid: 탑승자 데이터 일련번호
- survived: 생존 여부, 0 = 사망, 1 = 생존
- Pclass: 티켓의 선실 등급, 1 = 일등석, 2 = 이등석, 3 = 삼등석
- sex: 탑승자 성별
- name: 탑승자 이름
- Age: 탑승자 나이
- sibsp: 같이 탑승한 형제자매 또는 배우자 인원수
동반한 Sibling(형제자매)와 Spouse(배우자)의 수- parch: 같이 탑승한 부모님 또는 어린이 인원수
- ticket: 티켓 번호
- fare: 요금
- cabin: 선실 번호
- embarked: 중간 정착 항구 C = Cherbourg, Q = Queenstown, S = Southampton
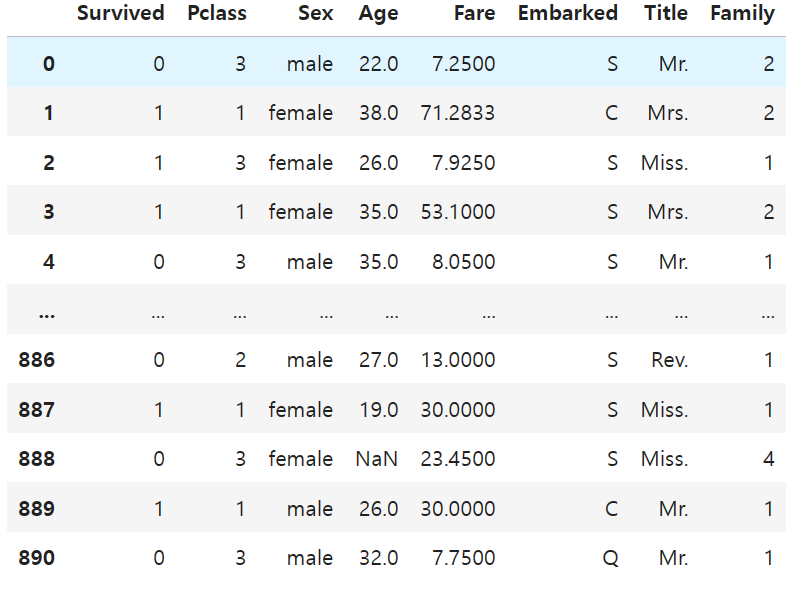
df = pd.read_csv('train.csv')
df

#필요없는 데이터 제거
df = df.drop(columns=['PassengerId', 'Ticket'])
#이름에서 성별, 기혼 여부를 위한 데이터만 추출
df['Title'] = df['Name'].str.extract(' ([A-Za-z]+\.)')
df = df.drop(columns='Name')
#가족 데이터는 합산
df['Family'] = df['SibSp'] + df['Parch'] + 1
df = df.drop(columns=['SibSp', 'Parch'])
#객실 정보 제거
df = df.drop(columns='Cabin')