오늘부터 해양팀에서 SST 예측을 해보기로 하였다. SST는 Sea Surface Temperature의 약자로 해수면 온도를 뜻한다. 내가 맡은 지역은 kuroshio extension(쿠로시오 해류)라는 지역이고 일본 오른쪽의 태평양 바다 구역 중 하나이다. 내가 만들 모델은 몇일 동안의 사진을 입력으로 받아 향후 몇일의 SST를 이미지 형태로 예측하는 Video Prediction 모델이다.
1일차
EDA
데이터는 1995~2021년까지 하루에 이미지 하나씩해서 총 9862개의 이미지가 들어있고 각 이미지는 온도 정보만 담고 있으며 200x200 사이즈이다. 하나의 픽셀은 2km x 2km를 나타낸다고 한다. 산불 팀에서 데이터의 대한 충분한 분석이 이루어지지 않은채로 모델링에 들어가서 고생을 조금 했다보니 이번엔 충분히 데이터 분석을 한 뒤에 구현에 들어가려고 했다.
데이터는 Sentinel(몇인지까먹음)위성의 Level-4 데이터이다. Level-1이 아예 원본, Level-2가 Skin-temperature나 보정이 조금 들어간자료 Level-3는 같은 센서를 사용하는 여러 다른 위성들의 자료를 합쳐서 만든 자료이고 Level-4는 오류나 구름에 가려 측정4되지 않은 지역의 값을 물리식이나 다른 여러 방법을 사용하여 모든 위치의 값을 전부 채운 데이터이다. 물론 어느 정도 오류가 있다고 한다.
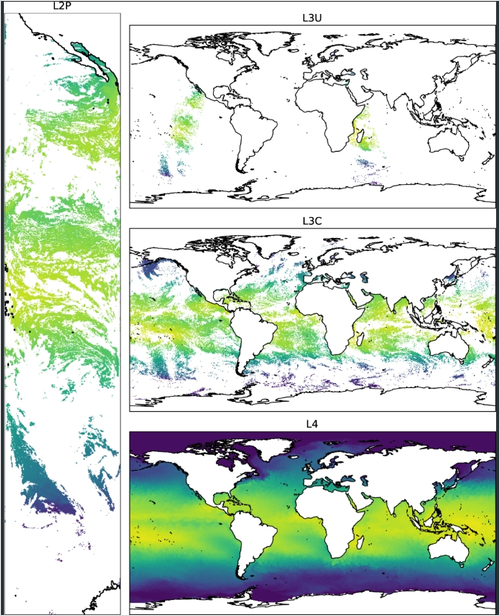
8월 16일 오늘 시훈님에게 위성자료에 대한 추가적인 설명을 들었다. 우선 L2P 사진은 어느 특정 Localtime에 한 위성이 찍은 사진(하나인지 복수인진 모르겠네.) 자료를 말하는 것이다. 위 사진처럼 기다란 이미지 한 장이 L2P 자료이다. L3U 자료는 이 L2P 자료를 전지구 혹은 관심있는 (넓은)지역에 투영시킨 데이터를 말한다고 한다. 그리고 L3C는 이러한 L3U 데이터를 합쳐서 전지구 혹은 관심있는 지역 전체를 커버하는 (결측치가 있지만) 데이터이다. 좀 더 자세히 설명하자면 L3C 데이터에 담겨 있는 값들은 모두 동일한 Local time에서 찍힌 데이터이다. 극궤도 위성이 양 극을 위아래로 도는 동안 지구가 자전하고 자연스럽게 촬영하는 지역이 바뀌게 된다. 이 때 위성은 위 아래로만 움직이고 태양은 고정(물론 지구가 공전해서 보정이 살짝 들어가야할듯)이기 때문에 지구 혼자 서에서 동으로 움직이는 것이기 때문에 위성이 찍는 이미지들의 Localtime이 전지역에 걸쳐 동일하게 되는 것이다. 즉 L3C에 있는 모든 값들은 전부 동일한 Local time에 찍힌 것이라고 보면된다. 한국 주변 바다도 한국시간으로 1시에 찍힌거고 미국 주변 바다도 미국시간으로 1시에 찍힌것이다. 그렇다고 이 모든 값들은 당연히 동시에 측정된 것이 아니라는 것에 주의하자. 그리고 L4 데이터는 각 위성이 가지고 있는 L3C 자료를 취합해서 결과적으로 모든 픽셀이 결측치를 가지지 않도록 만든 데이터이다.
참고로 정지궤도 위성은 넓을 지형을 한방에 찍어버리기 때문에 한장의 사진에서 서로 멀리 떨어져 있는 픽셀들끼린 서로 Localtime이 다르다고 한다. 대신 UTC가 동일.
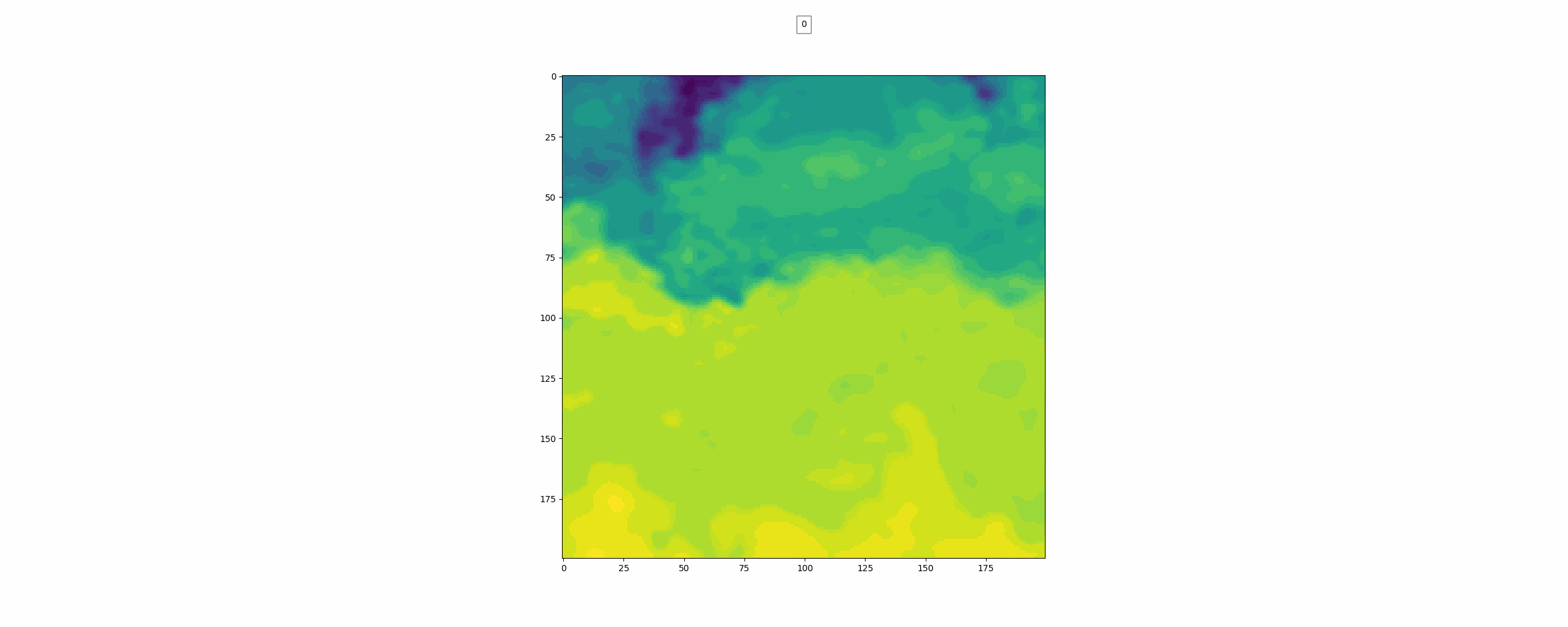
이미지 하나를 불러와봤다.
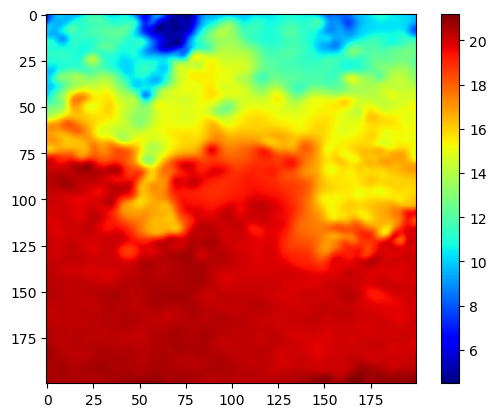
이 지역이 바다의 찬물과 따뜻한 물이 만나는 지역이라고 한다. 다른 사진들도 몇개 살펴봤는데 전부 따뜻한 물이 아래에 있고 찬물이 위에 있는 구조였다. 이것을 보아 아무래도 Data를 로딩할 때 Image Augmentation에서 Flip이나 Rotate는 사용하면 안될 것 같다.
Level-4이기 때문에 nan 값은 없을것이라 예상했는데 역시나 확인해보니 없었다.
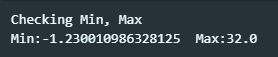
Min, Max 값은 위와 같았다. 온도의 단위는 우리가 흔히 아는 섭씨를 쓴다고 한다.
아무래도 온도는 계절의 영향을 많이 받을 것이라 생각하여 날짜별로 온도의 변화를 보고 싶었다. 200x200이미지를 어떻게 날짜별로 값을 표현할 수 있을지 고민해보다가 그냥 이미지의 픽셀값들을 평균내어 하나의 값으로 만들어보았다.
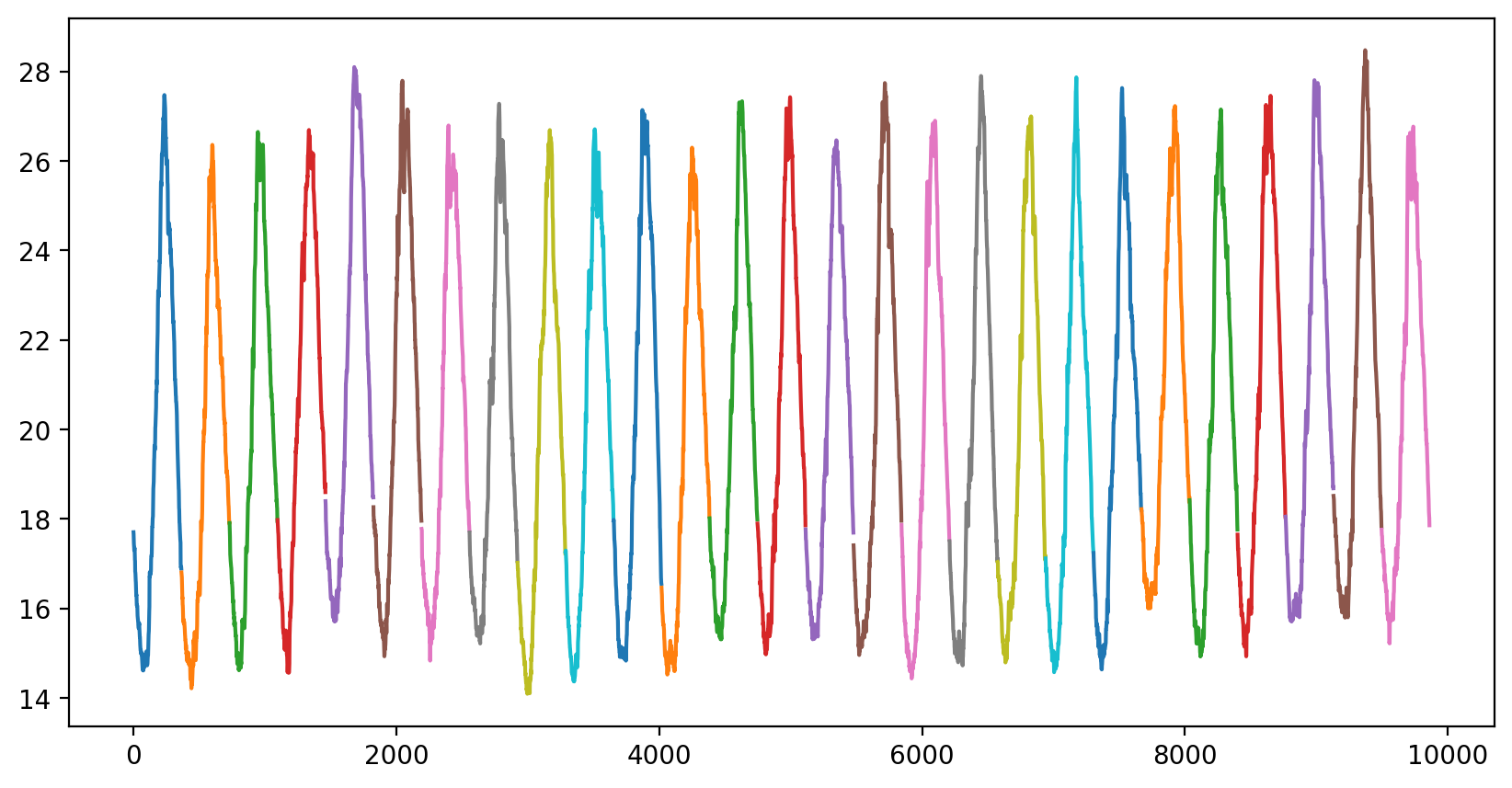
이게 그 결과이고 확실히 주기성을 띈다는 것을 확인할 수 있었다. 각 색깔이 한 년도를 나타낸다. 또한 각 년도의 온도 변화를 하나의 그래프에 그려보았다.
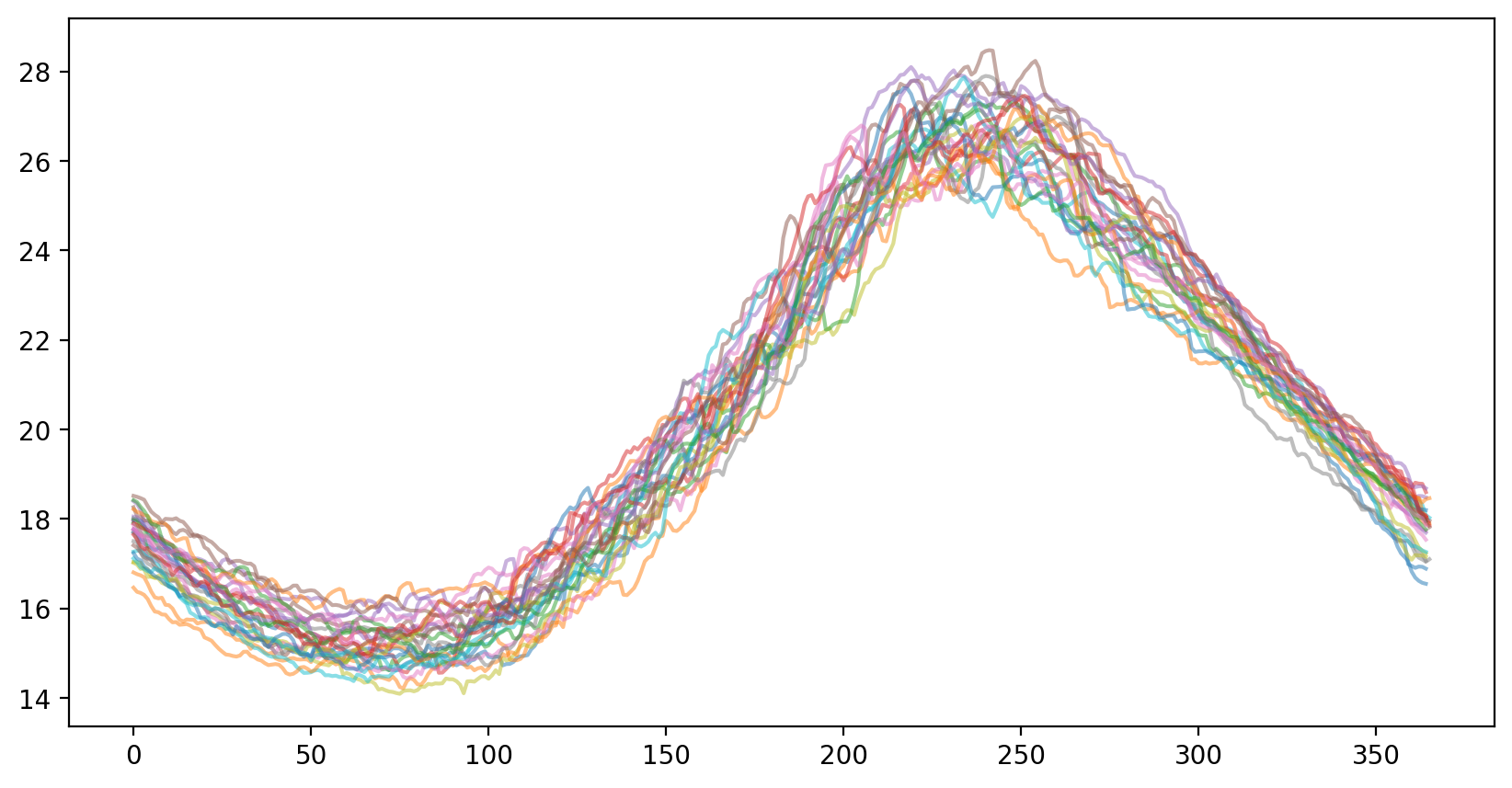
이게 색깔이 종류가 10개라 색깔이 중복되서 사용되긴 했지만 그게 중요한 것은 아니기 때문에 그냥 넘어갔다. 그래프를 보면 확실히 어느 정도 날짜 정보에 따라 일관되게 변하고 있다는 것을 볼 수 있다. 일단은 날짜 정보를 넣지 않고 한번 모델을 학습시켜보고 날짜 정보를 넣어서도 학습을 시켜보아야 할 것 같다.
Data normalize에 대해서도 고민을 좀 해봤는데 Min-Max와 Z-norm 둘 중 아무거나 써도 상관 없을 것 같다. 두 Normalize의 큰 차이점은 이상치가 있을 때 이 값이 전체 normalize 범위에 영향을 끼치는 것이 다르단 것인데 이 데이터엔 딱히 이상치가 없다. 만약에 feature가 즉, 채널이 여러개였다면 이렇게 이상치가 없는 데이터에선 아에 [0,1]로 범위를 제한시켜버리는 Min-Max가 더 좋을 것 같긴하지만 이 데이터는 채널이 하나이기 때문에 이런 경우도 아니다. 나중에 날짜 데이터를 넣을 것이라면 좀 더 고민을 해봐야 할 것 같긴한데 솔직히 아무 상관 없을 것 같다. 데이터를 두가지 방법으로 normalize한 뒤 plot해봤는데 위의 두 그래프와 값의 범위만 서로 다를 뿐 생긴게 내 눈엔 완전히 똑같아 보였다.
내 생각엔 일단 Min-Max를 우선 써보고 나중에 심심하면 바꿔보든지 하면 될 것 같다. 왜냐면 나중에 날짜 데이터를 Min-Max 할 것이기 때문.
EDA가 중요하다는 것을 알았기 때문에 뭔가 좀 더 데이터 분석을 해보고 싶었지만 정말 뭘 하면 좋을지 더 이상 생각이 나지 않았다...
2일차
어제 밤에 시훈님이 쓰신 논문과 학부 수업 때 사용된 Colab 파일을 좀 살펴보고 오늘 이어서 봤다. Vedio Prediction이 처음이라 어떤 정형화된 모델 구조가 있는지 알고 싶었기 때문이다. 일단 그 전에 Convolutional LSTM이란 것이 사용되었기 때문에 이것을 먼저 공부했다.
ConvLSTM은 쉽게 정리하자면 LSTM과 구조가 똑같되 입력이 벡터가 아닌 3D 이미지가 들어오고 출력은 원래 행렬과 벡터의 행렬곱셈이었지만 3D 행렬 Weight와 3D이미지가 합성곱되는 우리가 아는 Conv2D 연산으로 바뀐 것 뿐이다.
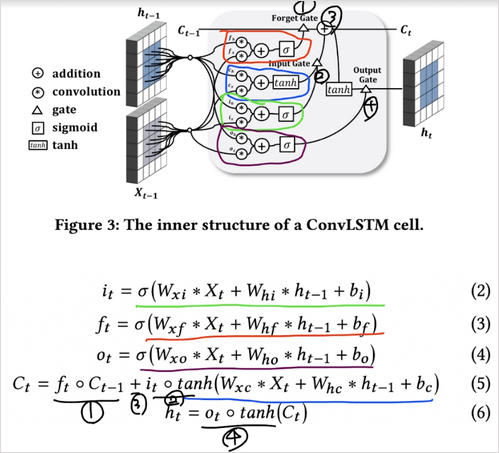
이 사진을 보면 이해가 쉽다. 선의 입력으로 들어가는게 2D 이미지 혹은 3D 이미지라고 생각하기만 하면 된다.
시훈님이 Colab에서 만드신 모델은 ConvLSTM을 각 타임 seqeunce마다 출력하게 만들어 2개 정도 layer를 쌓고 이렇게 하면 출력이 (Batch, Time sequence, H, W, C) 이렇게 나오는데 이것을 Conv3D에 통과시켰다. Conv3D는 https://leeejihyun.tistory.com/37 이 링크를 참조하면 된다. 3D 이미지를 하나의 필터에 Conv2D하면 원래 2D가 나오는데 3D는 합성곱을 3D로 하기 때문에 output이 3D로 나오고 필터가 여러개면 총 4차원 output이 나온다. 각 축별로 kernel size와 stride를 설정해줄 수 있다. 이 때 각 축은 Time sequence, H, W를 담당하는 것에 주의해야한다. C가 10이면 하나의 필터가 3D weight를 10개 가지고 있고 총 10개의 3D 아웃풋을 다 더해서 하나의 3D 아웃풋이 나오는 것이다. 근데 시훈님이 (1,3,3) 커널 사이즈를 사용해서 Time sequence 정보를 서로 독립적으로 다루었다. 이 부분은 왜 그렇게 했는지 한번 물어봐야 할 것 같다.아마 데이터셋의 형태가 1,2,3,4,5일의 이미지를 넣으면 2,3,4,5,6 이미지를 출력하도록 만들어서 그런 것 같긴하다. 실제로 검증할 땐 2,3,4,5,6 출력에서 6을 때서 기존 2,3,4,5뒤에 6을 붙여서 7을 예측하는 방식으로 검증하셨다고 한다.
여기까지 공부한 뒤 민기님이 알려주신 Paper with code 사이트에서 Video Prediction 분야의 SOTA 모델을 한번 살펴보았다. 첫 랩미팅 때 봤던 SimVP 모델이 SOTA 모델이었다. 한번 논문을 읽어보았는데 세상에 영어인데도 불구하고 모델이 간단하게 생겨서 그런가 이해가 너무 잘되었다. 애초에 논문에 수식이 거의 없었다. 그리고 모델도 기존 모델 구조들에서 몇가지만 추가한 것이 다였고 새로운 연산을 만들어 낸 것도 없었다. 이해가 잘되서 너무 좋았고 이 논문은 심지어 이미 위성자료를 이용한 Benchmark dataset을 사용해 온도예측을 해서 다른 모델들과 비교까지 해놓았었다. 그리고 제일 좋았다. 이 모델을 사용하지 않을 이유가 없었다. 이 모델의 위의 모델과 다른 점은 모델구조도 물론 있지만 예측 방식이 좀 다르다. 오히려 좀 더 간단하다고 할 수 있는데 과거 T time sequence 데이터를 받으면 향후 T time sequence를 예측하는 구조이다. 내가 푸는 문제에 적용해서 설명하면 이전 5일의 데이터를 입력으로 받으면 향후 5일의 이미지를 출력하는 구조이다.
논문 링크: https://arxiv.org/pdf/2211.12509v3.pdf
일단 SimVP로 모델을 만들어보고 나중에 ConvLSTM을 앙상블 해보던가 하면 될 듯?
3~5일차
사실 오늘 5일차인데 이틀을 까먹고 안썼다. 우선 내가 읽은 논문이 SimVP ver.2란 것을 알았고 github를 찾아보니 친절히 구현되어있는 공식 repo를 찾았다. 항상 남의 코드 사용하는게 제일 어려운 것 같다. 코드가 실행이 안되서 되게 고생했는데 anaconda를 최신 버전으로 바꾸고 torch를 지웠다가 다시 깔으니 되었다. github에서 시키는대로 하니까 torch가 cpu버전으로 깔렸다. 다른 서버에서 torch만 지우고 다시 깔아봤는데 안되는걸로 봐선 anaconda도 최신으로 바꾸는게 맞는 것 같다. 그 뒤 SST Data를 torch 모델에 사용하기 위해 Dataset 클래스를 만들어 주었다. 데이터가 간단해서 산불 때보다 구현은 훨씬 덜 복잡하였다. 그래도 이미지 데이터를 Sequence 데이터로 바꿔주어야했기 때문에 구현에 약간 시간이 걸렸다.
이렇게 하고 SimVP ver.2를 학습시켜보았다. (여기까지 이틀이 걸렸다.) 100에폭 학습시켰는데 결과는 MSE는 낮았지만 눈으로 결봐를 보니 썩 좋지 않았다.
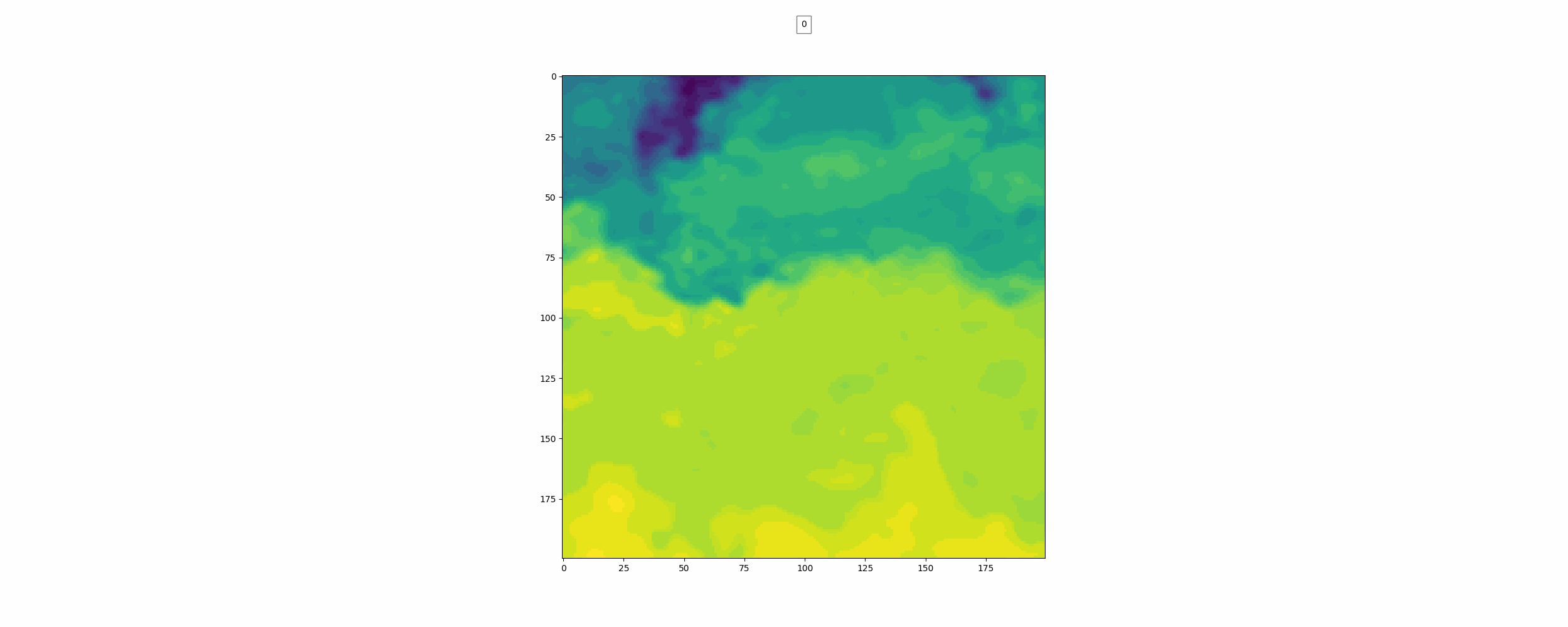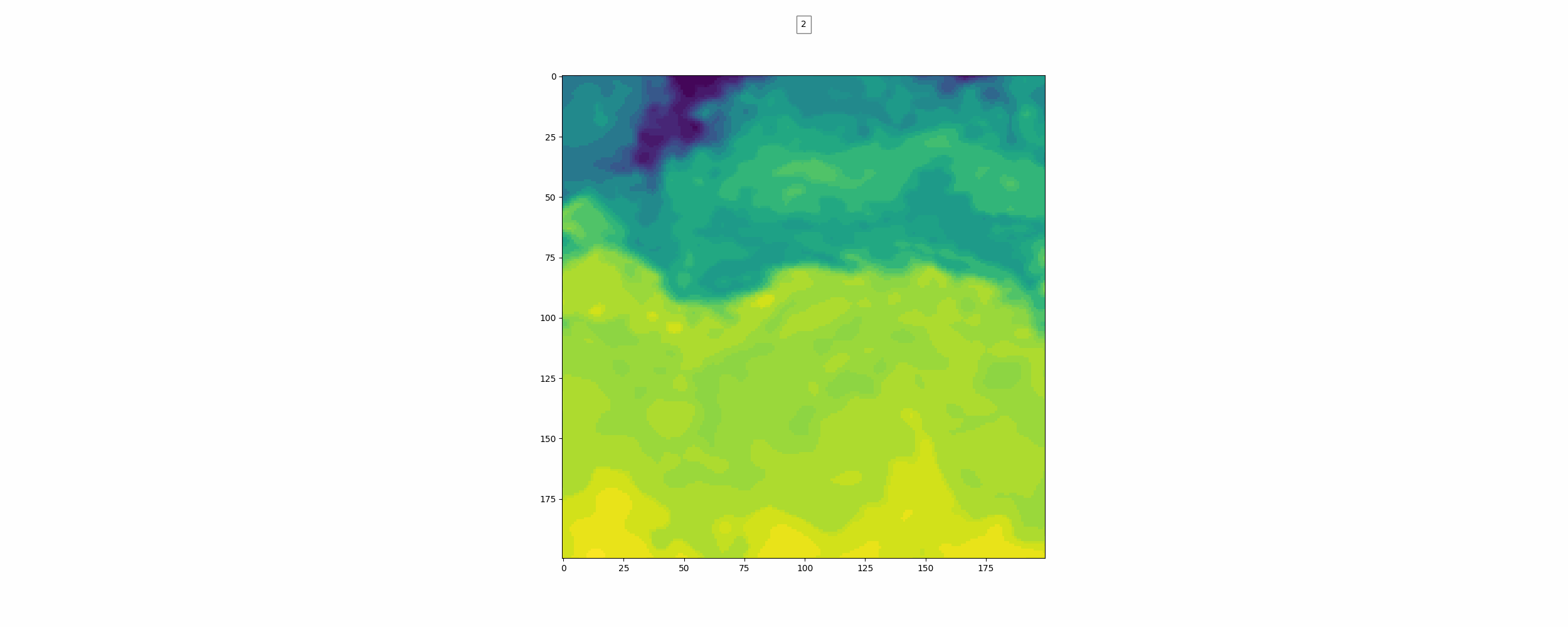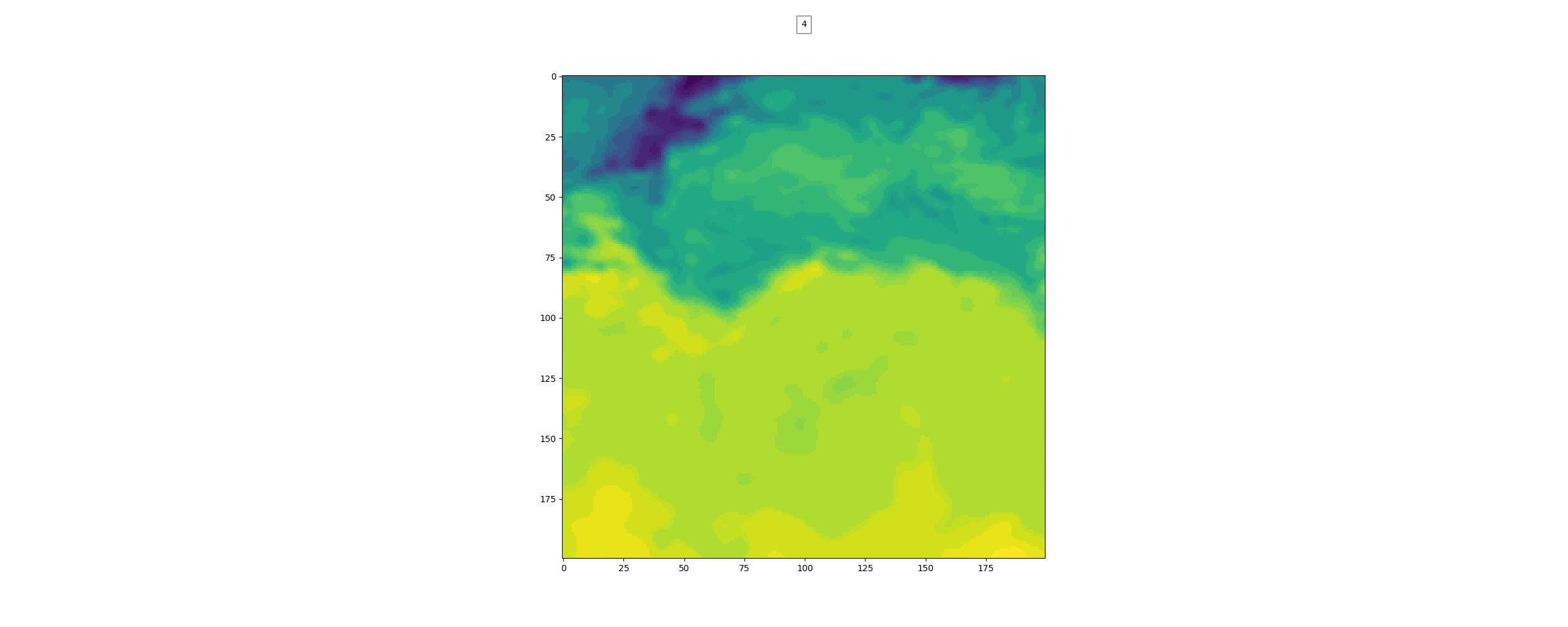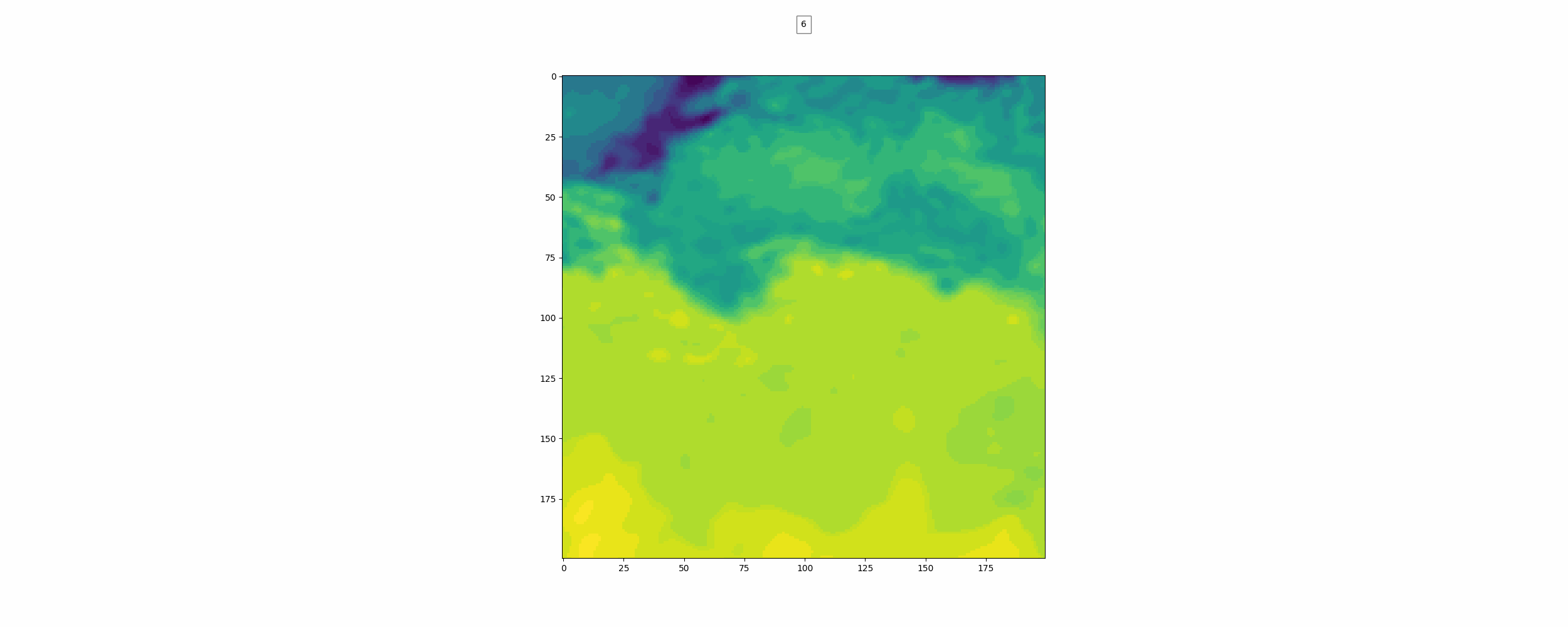
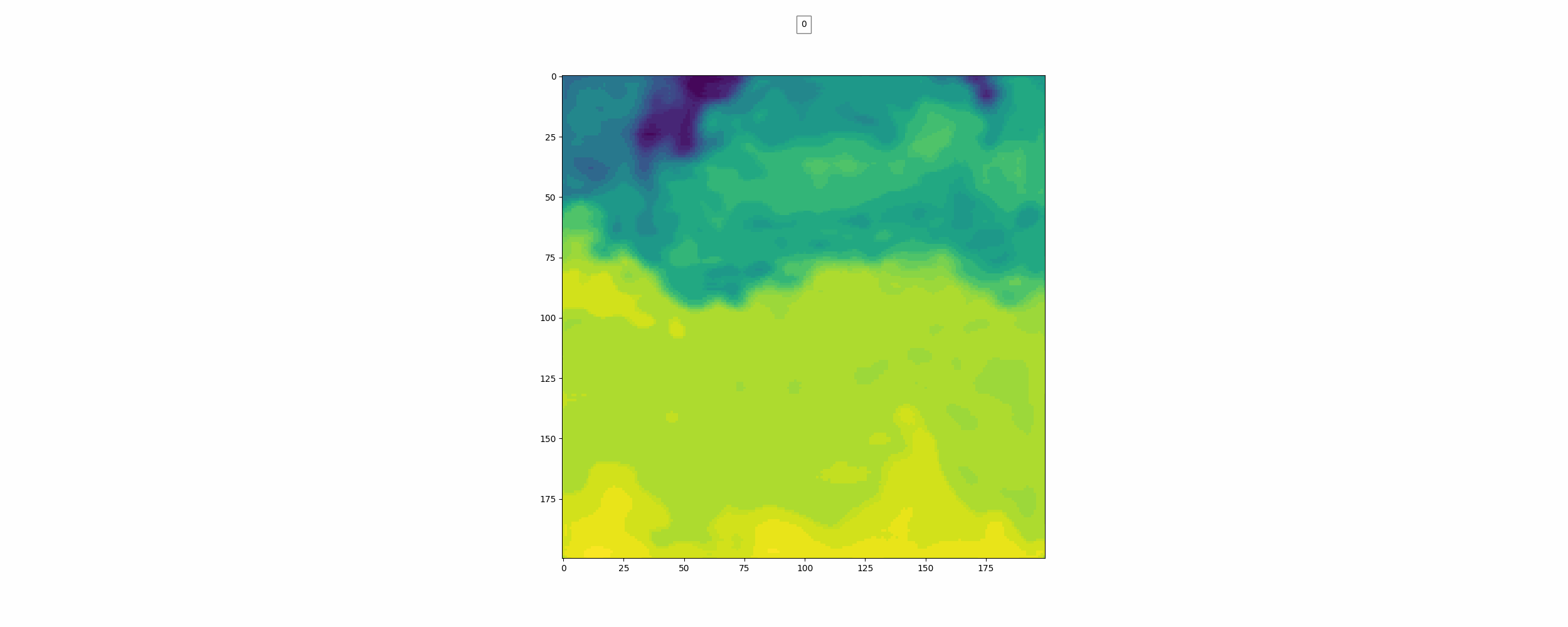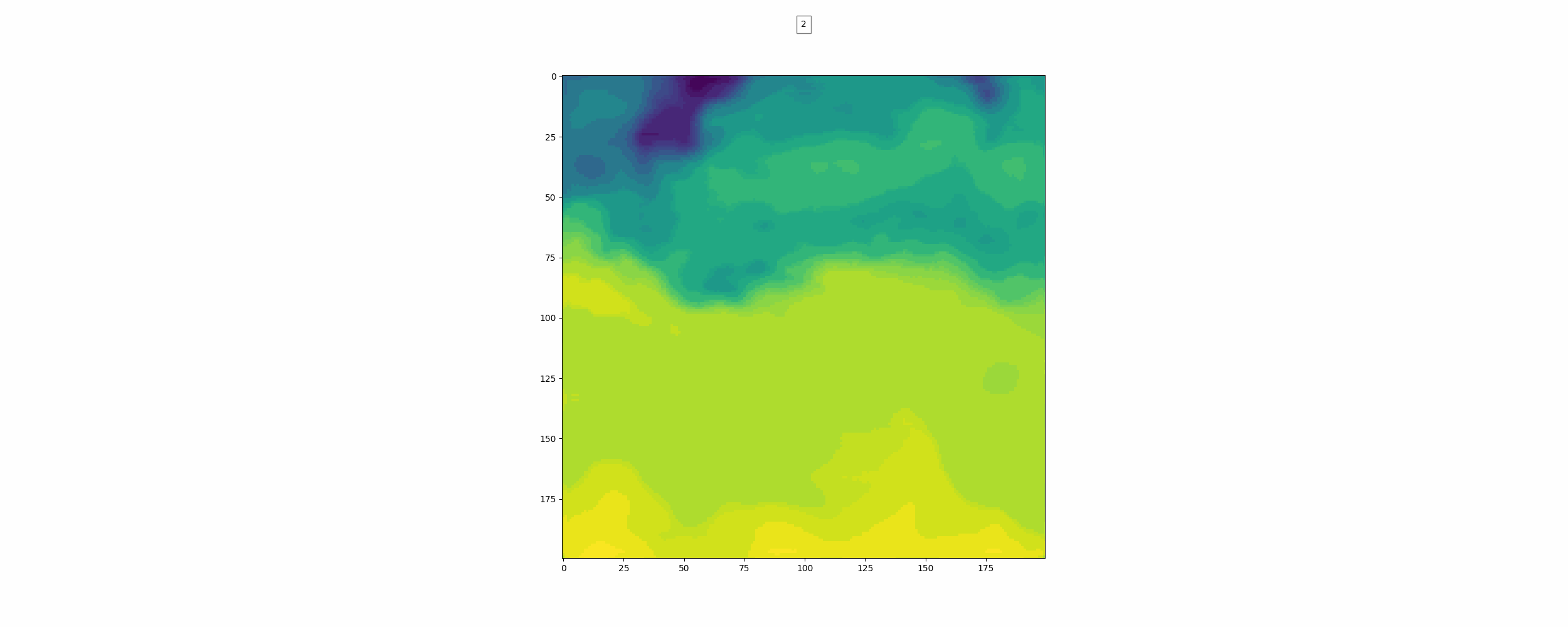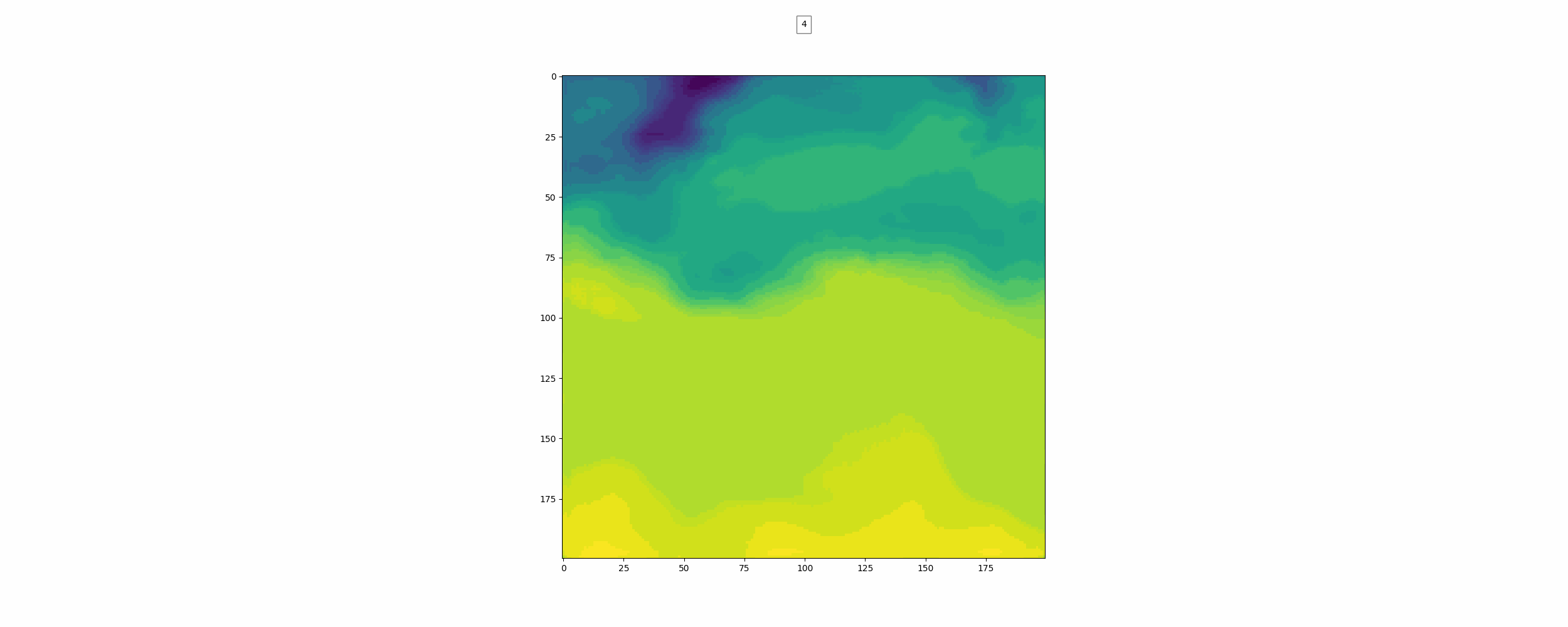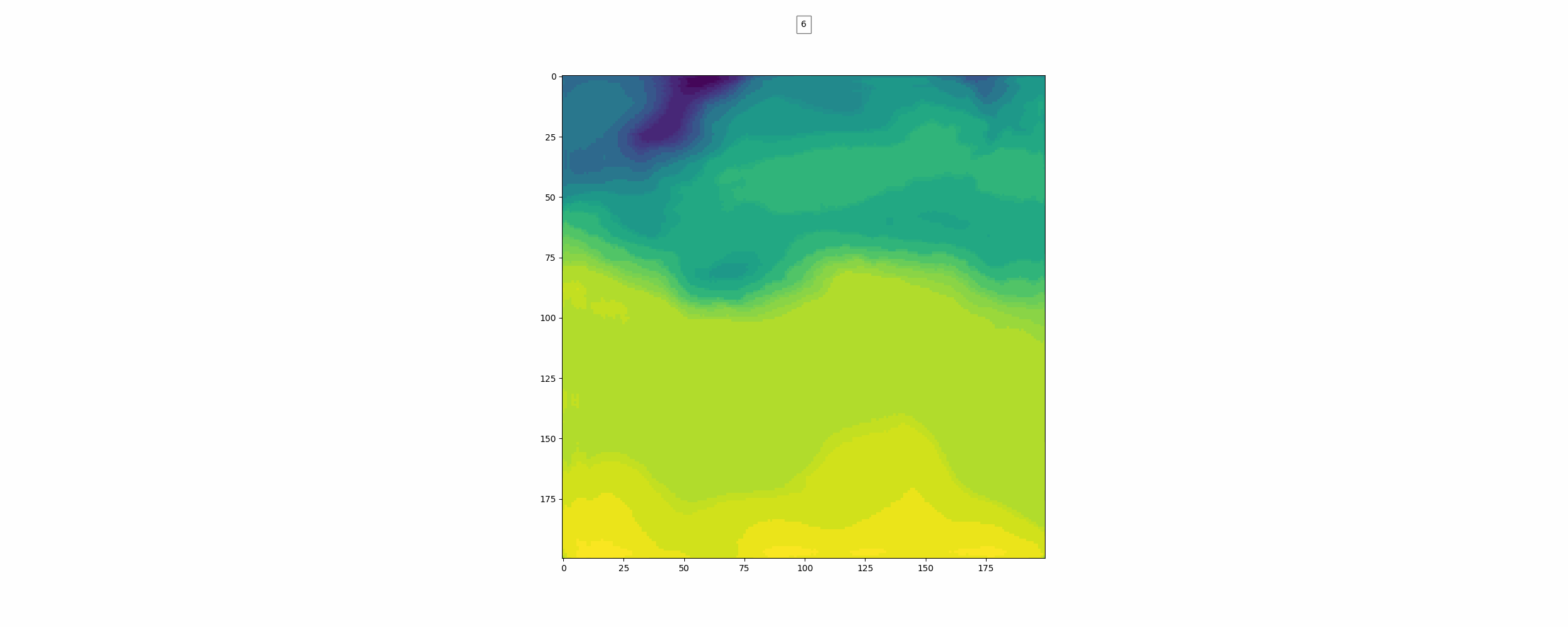
위가 label이고 밑이 pred인데 뭔가 썩 좋아보이진 않는다.
시훈님이 일주일 간격으로 이미지를 묶으면 좀 더 역동적인 모습을 학습할 수 있을 것 같다고 해서 일주일 간격으로 이미지를 묶고 400에폭을 학습시켜보았다.

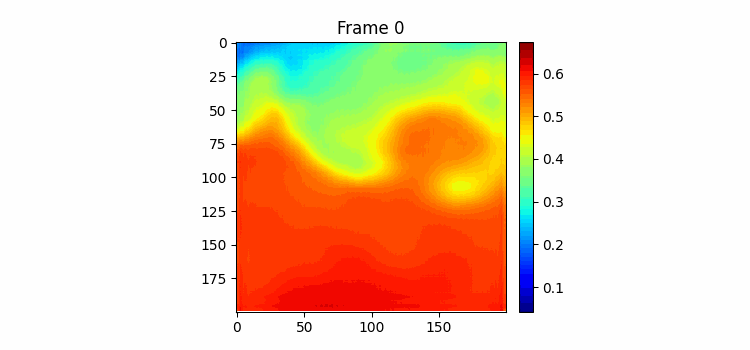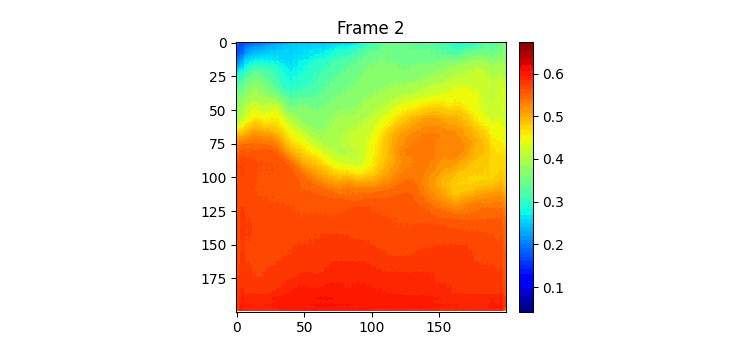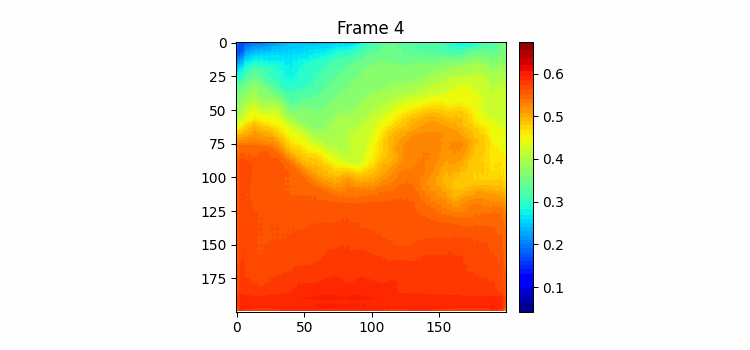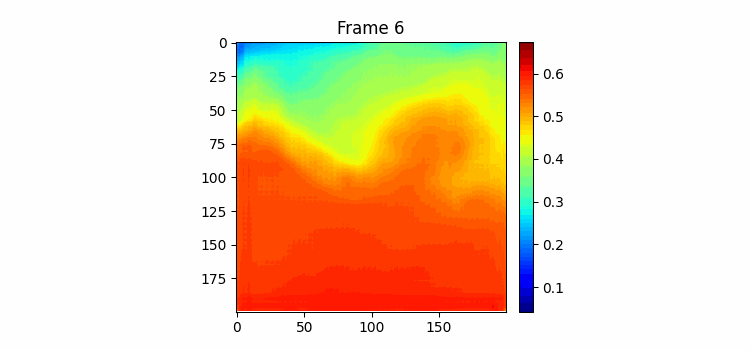
400 에폭 학습하는 동안 시각화 코드를 조금 수정했는데 우선 color map을 jet로 바꿨고 color bar를 만들었다 color bar의 범위는 두 이미지의 최대값과 최소값이다. 결과를 보면 음... 별로인 것을 볼 수 있다. 자세히보면 Frame-0의 형태에서 크게 벗어나고 있지 못한다는 걸 알 수 있다.
MSE는 굉장히 작은데 직접 눈으로 보면 별로라는 것이 좀 아이러니했다. 내 생각엔 겉으로 보이는 MSE는 모든 픽셀 오차의 평균이라 그런 것 같다. 어제 MSE Loss에 대해 생각해봤는데 혹시나 다른 픽셀들이 잘 학습되어서 낮게 측정된 MSE가 다른 오차가 큰 픽셀의 학습을 방해할수도 있나 생각이 들었는데 아니라는 결론에 이르렀다. 왜냐하면 MSE의 식을 뜯어보면 모든 픽셀 값의 합의 제곱이 들어있기 때문에 이걸 미분하면 결국 특정 위치의 픽셀값과 그 위치의 정답 픽셀값의 차이가 기울기로 들어가게되고 이게 결국 각 픽셀은 자신의 위치에 해당하는 정답 픽셀에 대해서만 학습한다는 뜻이 된다. 이건 Softmax도 마찬가지이다. 정답 원핫벡터에서 logits은 자신의 위치에 해당하는 label과의 오차만 고려된다. y_i - a_i
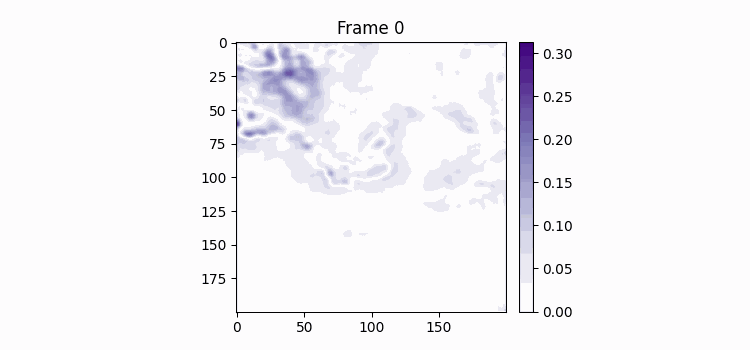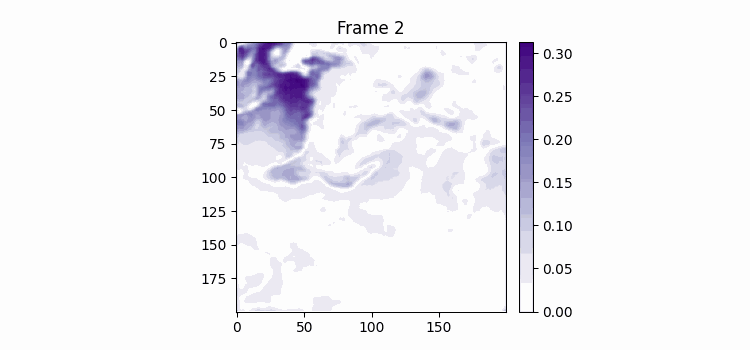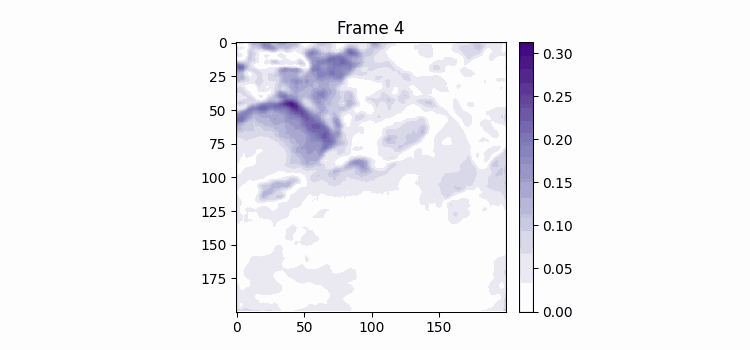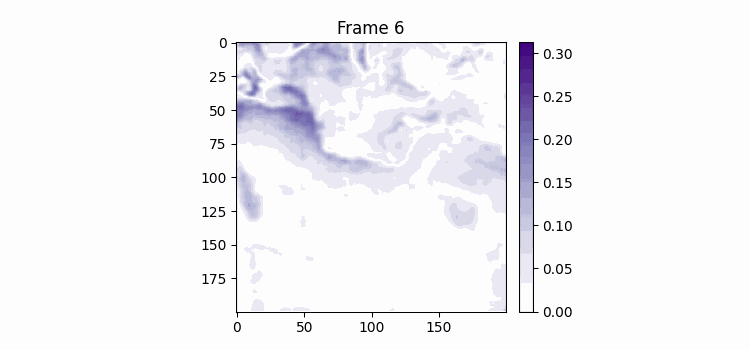
두 이미지 값의 차이의 절대값을 한번 시각화 해봤다. 뭔가 상당하다는 것을 알 수 있다. 생각해보면 사실상 이게 해수면 온도를 빙자한 해류의 이동과도 연관있는 것 같은데 이것을 과거 이미지만 보고 예측한다는 것은 쉽지않은 것 같다. (아마도?) 민기님이 좋은 정보를 주셨는데 다른 연구에선 이런 이미지의 윤곽선을 따서 윤곽선 차이 값을 모델의 Loss에 추가하는 시도가 있었다고 해주셨고 github 링크까지 주셨다. 그래서 오늘 저녁에 이것을 계속 시도해보았고 일단 어느정도 구현을 해놓았다. 그리고 생각해봤는데 날짜 정보가 그렇게 유용할 것 같지가 않다. 왜냐면 온도 값 하나를 띡 예측하는거면 유용하겠지만 지금 모델에 들어오는 정보가 과거 7일 혹은 7주치 데이터이고 여기에 온도 정보가 이미 들어있다. 그리고 모델이 예측해야하는 것은 각 픽셀의 해수면 온도와 그 흐름이기 때문에 그 정보를 날짜가 대변해줄 수 있을 것 같지 않다. 물론 아닐 수도 있음 ㅋㅋ 이미지 한 픽셀이 2km이기 때문에 총 400km x 400km인데 대충 남한크기랑 비슷한데 뭔가 훨씬 더 예측하는 사이즈가 크면 어떤 흐름을 날짜 정보가 말해줄수도 있을 것 같은데 이건 뭔가 애매한 것 같다.
그리고 생각을 좀 해봤는데 물론 이 모델은 CNN 기반이라 불가능하지만 Transformer 같은 경우엔 학습을 할 땐 문장 전체를 통으로 학습하고 실제로 사용할 땐 한 단어씩 예측해서 그 다음 단어를 예측한다. Transformer는 sequence 길이가 바뀌면 그에 따른 출력 길이도 바뀌지만 SimVP는 sequence길이가 무조건 고정되어 있어야한다. 그래도 예측 단계에서 SimVP가 출력하는 첫번째 출력을 사용해 다음 입력으로 사용해보는건 어떨지 궁금해졌다. 내일해봐야지
일단 지금 해야할 것은 윤곽선 정보를 이용한 loss를 넣어보는 것이다.
6일차
어제 퇴근하기 전에 2일간격으로 이미지를 묶어 학습시킨 모델을 400에폭 돌리고 갔고 오늘 확인해봤는데 기대도 안했지만 딱히 나아진건 없었다. 어제 궁금했던 모델 예측의 첫번째 이미지를 그 다음 입력으로 활용하는 방법으로도 gif를 만들어보았는데 한번에 예측하는 것과 거의 차이가 없었다. 일단 윤곽선 정보를 loss로 활용하는 방법을 써보기로 했으니까 이것을 해보고 그래도 안되면 생각을 좀 해봐야 할 것 같다.
이런 식으로 모델을 만든건 처음이라 좀 낯설면서 재밌었다. 지금 100에폭 학습 돌리고 있는데 심심하니까 내가 짠 코드 리뷰를 여기에 적도록 하겠다. 사실 핵심부분은 다 github에서 가져왔다.ㅋㅋ
class Gradient_img(torch.nn.Module):
def __init__(self):
super(Gradient_img, self).__init__()
a = np.array([[1., 0., -1.], [2., 0., -2.], [1., 0., -1.]])
self.conv_gx = torch.nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=0, bias=False)
self.conv_gx.weight = torch.nn.Parameter(torch.from_numpy(a).float().unsqueeze(0).unsqueeze(0),
requires_grad=False)
b = np.array([[1., 2., 1.], [0., 0., 0.], [-1., -2., -1.]])
self.conv_gy = torch.nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=0, bias=False)
self.conv_gy.weight = torch.nn.Parameter(torch.from_numpy(b).float().unsqueeze(0).unsqueeze(0),
requires_grad=False)
self.eps=10**-3
# self.eps=0.
def forward(self, im):
B,T,C,H,W = im.shape
im = im.view(B*T, C, H, W)
p2d = (1,1,1,1)
if im.size(1) == 1:
g_x = self.conv_gx(im)
g_y = self.conv_gy(im)
g = torch.sqrt(torch.pow(0.5 * g_x, 2) + torch.pow(0.5 * g_y, 2) + self.eps)
g = torch.nn.functional.pad(g, p2d, "constant", 0)
else:
for kk in range(0, im.size(1)):
g_x = self.conv_gx(im[:, kk, :, :].view(-1, 1, im.size(2), im.size(3)))
g_y = self.conv_gy(im[:, kk, :, :].view(-1, 1, im.size(2), im.size(3)))
ng = torch.sqrt(torch.pow(0.5 * g_x, 2) + torch.pow(0.5 * g_y, 2)+ self.eps)
print(ng.shape)
ng = torch.nn.functional.pad(ng, p2d, "constant", 0)
print(ng.shape)
if kk == 0:
g = ng
else:
g = torch.cat((g, ng), dim=1)
g = g.view(B,T,C,H,W)
return g이게 이미지에서 edge를 찾아주는 클래스이다. 비전 분야를 공부할 때 수직선과 수평선을 검출할 수 있는 전통적인 필터를 봤었는데 정확히 그것을 사용하고 있는 것을 볼 수 있다. 깃허브 코드가 조금 오류가 있어서 내가 수정했다. 우선 padding=0인 이유는 처음에 1로 해서 실제로 시각화하니까 이미지 모서리 부분들이 다 굉장히 높은 값들을 가지고 있었다. 그 이유는 conv 연산을 하기 전에 pad를 붙여놓았기 때문이다. conv 연산에 padding을 빼고 결과로 나온 이미지에 pad를 붙여주었다. 또한 내 데이터는 5차원이고 기존 코드는 4차원 데이터를 가정하고 구현되어 있어서 차원을 바꿔주었다. 다만 아직 이해가 안되는 부분은 가로 엣지와 세로 엣지를 더할 때 나누기 2한 뒤 제곱해서 더하고 루트를 씌우는데 왜 이렇게 하는지는 모르겠다. 이 클래스를 통과한 이미지를 보면 아래와 같다.

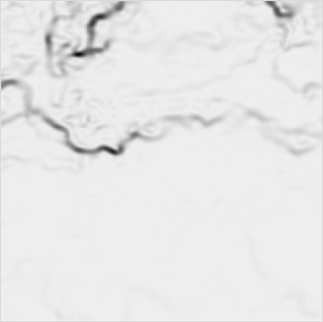
엣지를 아주 잘 딴 것을 볼 수 있다. 내가 만든 GSimVP는 SimVP를 통과해 나온 output을 해당 클래스에 통과시켜 edge를 검출하고 output과 edge를 모델이 반환한다. 그리고 label와 label의 edge 이미지를 각각 모델의 output과 edge와 함께 MSE loss를 구하고 backward하는 방식으로 구현하였다.
아래가 그 모델의 구조이다.
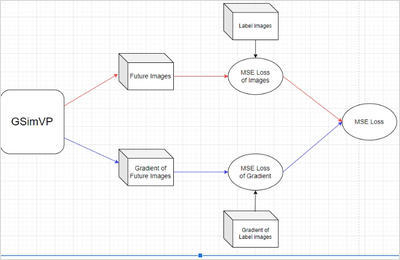
100에폭을 학습시킨 GSimVP 모델의 결과를 확인하였다. 결과는 암담했다. 위의 결과와 별로 다를바가 없었다. 내가 코드를 잘못짠 것일까? 한번 1,2,3,5를 받으면 2,3,4,5,6을 예측하는 식으로도 학습해봤는데 이건 CNN 기반이라 모델이 2,3,4,5를 이미 보고 있기 때문에 학습이 잘 안될것같긴했는데 역시나 안됐다. 뭔가 여러 시도를 했는데 기록을 안하고 그냥 중구난방으로해서 까먹었다.
7일차
내가 혹시 뭔가 실수를 했나해서 데이터 샘플 1개를 40에폭 학습시켜 잘 학습하는지 확인해보았다. 확인해보니 학습은 잘 되었다. 샘플이 1개라 그런지 뒤로 갈수록 나타났던 블러현상이 하나도 없었다. 웃긴건 이 모델을 valid와 test 셋에 확인해봤는데 블러 현상이 없어서 그런지 확실히 더 예측을 잘 하는 것처럼 보였다. 시간이 지날수록 이미지가 흐려지는 현상이 MNIST에서도 발생하나해서 기존 SimVP 모델에 Moving MNINST 데이터를 학습시켜보았는데 정말로 갈수록 흐려지는게 발생하였다. 다만 숫자가 흐려지는 것이고 숫자가 이동하는 방향은 올바르게 예측하였다. 모델 코드도 이미 만들어져 있는 것이고 데이터도 유명한 것이기 때문에 딱히 내 코드가 잘못된 것 같진 않은 것 같다.
MSE Loss가 과도하게 작은 것 같아 한번 L1 loss를 사용해보았지만 결과는 비슷했다. 물론 빠르게 확인하려고 10에폭만 돌리긴 했다. 그리고 호기심에 직접 Loss function을 만들어 현재로부터 멀리 떨어져있는 시간의 예측 이미지의 loss를 증폭시켜보았다. 40에폭 학습시켜봤는데 결과는 비슷했다. 둘 사진을 비교해봤는데 정말 사실상 거의 똑같게 예측했다. valid set과 train set 둘 다 비교를 해보았는데 첫 프레임은 선명하게 예측하고 그 뒤는 점점 흐려지는 꼴이었다. 이 현상을 해석해보면 입력의 끝 프레임과 label의 첫 프레임은 상당히 닮아있기 때문에 모델 입장에서 예측을 하기 쉽지만 그 이후 프레임은 입력과 연관성이 떨어지기 때문에 첫 예측 프레임에서 형태가 크게 벗어나지 않으면서 여러 샘플에서 MSE를 낮추기 위해 이미지가 흐려지는 것이라 생각해 볼 수 있다. 또한 이것이 말해주는 것은 label 이미지 끝으로 갈수록 입력과의 연관성이 없다는 것 뜻한다고 생각한다.
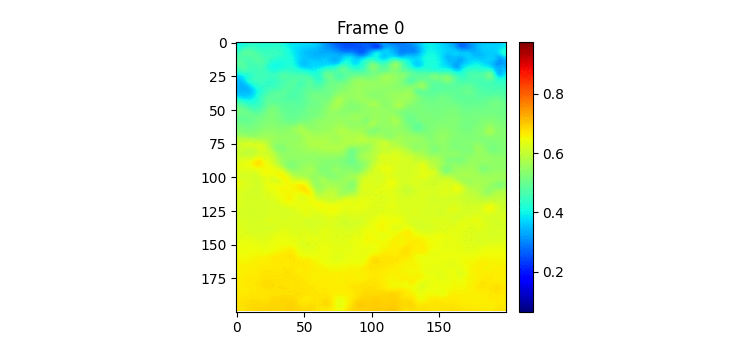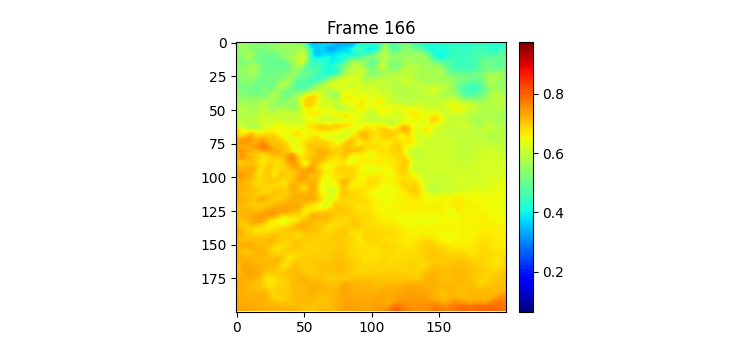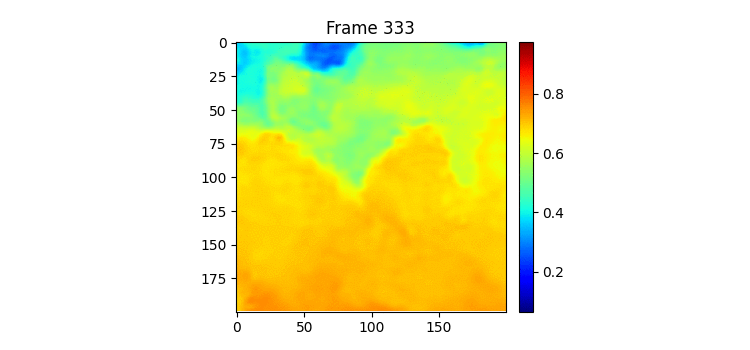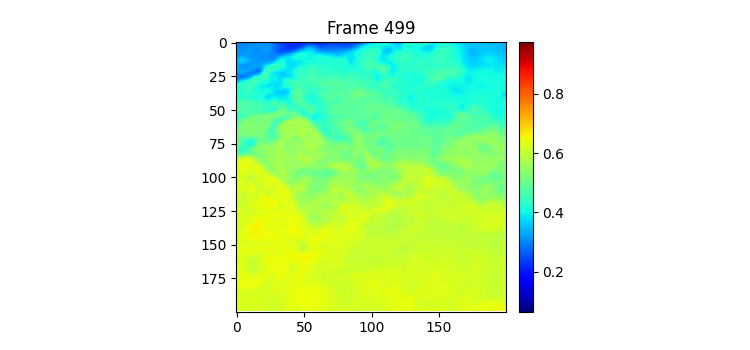
실제로 500일치 이미지를 한번 gif로 만들어서 살펴보았는데 사람인 내가 보아도 총 500일 중 특징이라고 정의할만한 것이 여름에 뜨거운 물이 남쪽에서 올라온 뒤 겨울이 다가오면서 내려간다는 것 밖에 모르겠다. 모델이 7일을 받아서 7일 뒤를 예측하는데 7일씩 잘린 연속된 이미지에서 모델이 input과 label 사이에 무슨 연관성이 있는지 알기란 힘들 것이라고 생각된다. 그리고 분 단위의 연속적인 이미지라면 모를까 뭔가 하루 단위의 이미지에선 그 다음날 물의 형태가 어떻게 될지 내가봐도 모르겠다. Moving MNIST처럼 몇 프레임 사이에 급격하게 일관된 움직임이 존재하는 데이터셋이라면 모를까 이런 느리게 변하는 그리고 무작위성이 작은 시간 단위에서 큰 데이터셋에서 잘 안되는 것은 당연한 것 같다. (합리화 아님) 아니면 사진 이외에 물의 흐름을 예측할만한 정보가 추가로 있던가.
날짜 정보를 주면 차가운물이 내려올지 뜨거운 물이 내려갈지 정도는 알 수 있을 것 같긴하다.
일단 모델에게 해수면 온도 변화 흐름이 매우 느리다는 것과 날짜를 통해 언제 뜨거운 물이 올라오고 내려가는지 정보를 주면 좋을 것 같다. 흐름이 느리다는 정보는 입력 시퀀스의 길이를 늘리는 방법 밖엔 없는데 이렇게하면 모델의 복잡도가 기하급수적으(은 아니고 선형적으로 계산량이 기하급수적으로 증가)로 증가하기 때문에 RNN 계열을 쓸 수 밖에 없다. 일단 SimVP해보고 오바나면 Swin Transformer를 써볼까? -> 생각해보니 RNN을 써도 GRAM을 줄일 수는 없는 것 같다. 어차피 layer마다 텐서를 저장해놔야하기 때문. RNN이 좋은 점은 그냥 Time sequence 길이에 유연하다는 것 밖에 없는듯.
8일차
어제 Loss에 Peanlty를 추가한 코드에서 실수로 함수를 만들어 놓고 적용을 안시키고 학습했단걸 발견했다. 그래서 다시 적용한 600에폭을 학습시켰는데 어제 퇴근 전에 돌리고 갔는데 1에폭에 2분이 걸려서 총 1200분이 필요했다. 아직도 학습 중인데 다행히 중간에 좋은 모델이 발견되면 저장되게 해놔서 테스트는 바로 해볼 수 있었다. 결과를 봤는데 여태까지 계속 발생했던 이미지 스무딩 현상이 많이 사라졌다! 물의 흐름을 잘 파악하는진 모르겠지만 어쨌든 흐려지는 현상이 없어졌단 것만으로도 기뻤다.
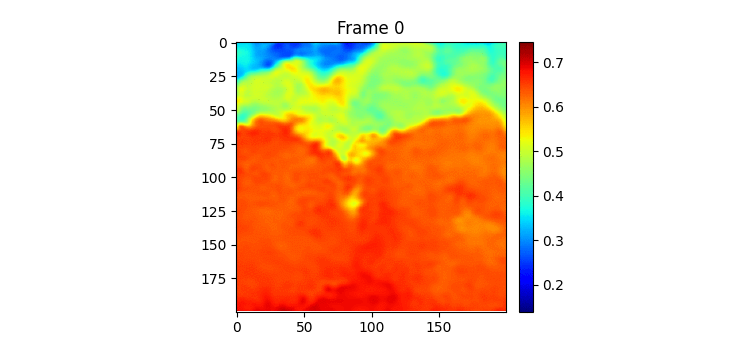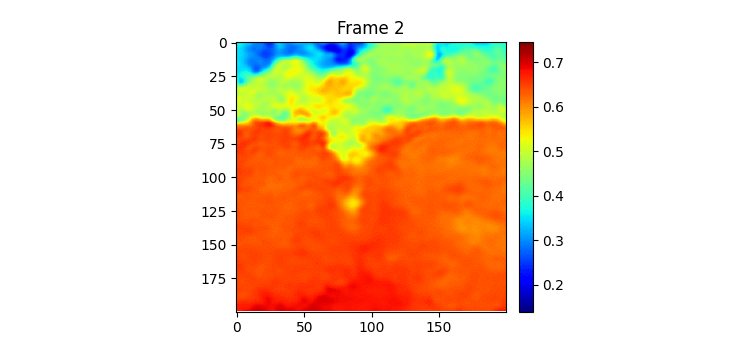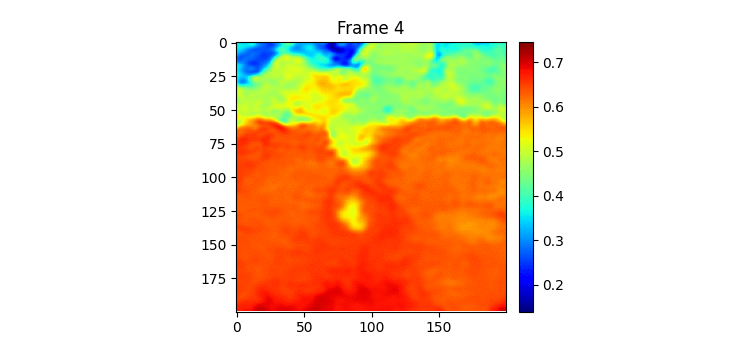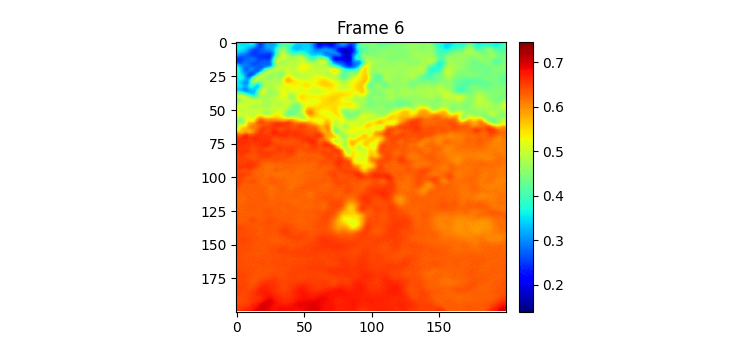
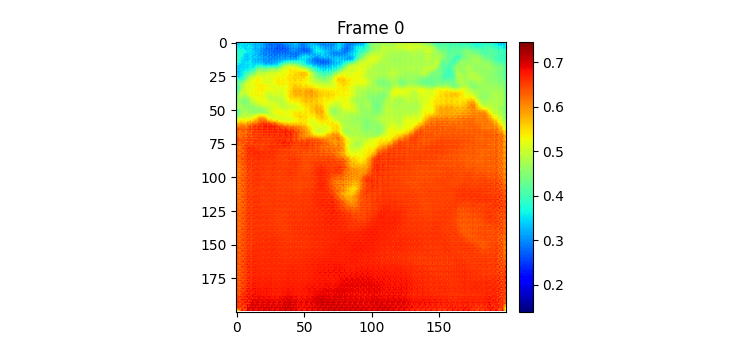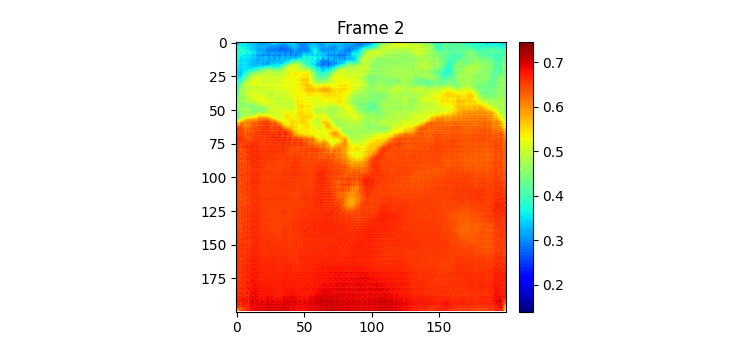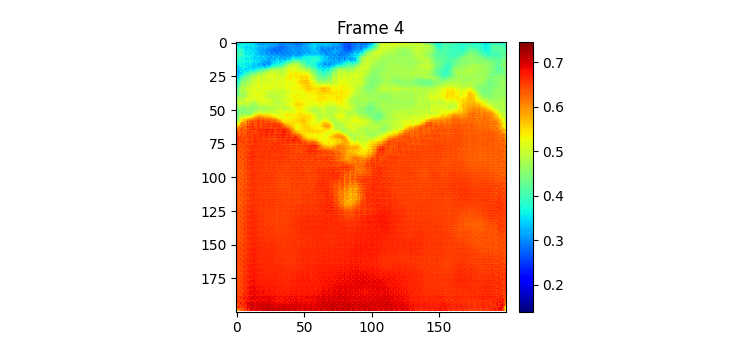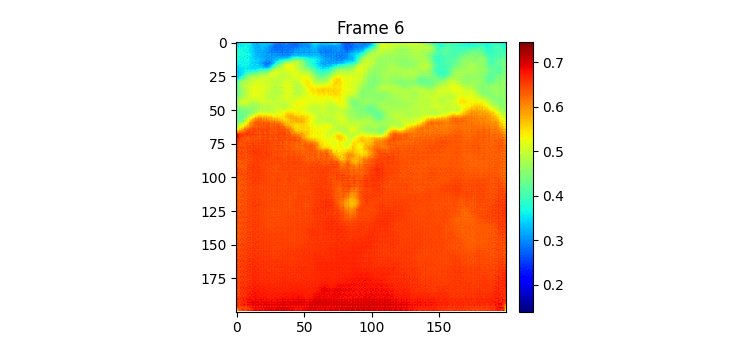
위가 label이고 밑이 pred인데 이전에 비하면 흐려지는게 거의 없다시피하다.
9일차
365일치는 모델에 담지 못해도 180치는 어찌어찌 가능해서 한번 180일을 받아서 향후 180일을 예측하는 모델을 만들어 보았다. 이번엔 Cumtom Cosine Annealing Warm Restart를 사용했는데 이게 약간 만능인게 기존 cosine annealing warm restart에서 한 사이클마다 max lr을 맘대로 줄일 수 있는 기능까지 있어서 lr에 관한 하이퍼파라미터 서칭이 거의 필요없게 할 수 있다. 결과는 여름에 뜨거운 물이 올라가고 겨울에 찬물이 내려오는 추세만 학습했고 디테일한 모양은 하나도 닮은 모습은 아니었다. 이 모델을 그대로 냅두고 엣지 정보로만 loss를 구해서 학습해볼까 생각도 해봤는데 이게 내 생각엔 그냥 input과 label 간의 디테일한 물의 모양은 별로 연관이 없어서 학습이 그냥 안될 것 같다.
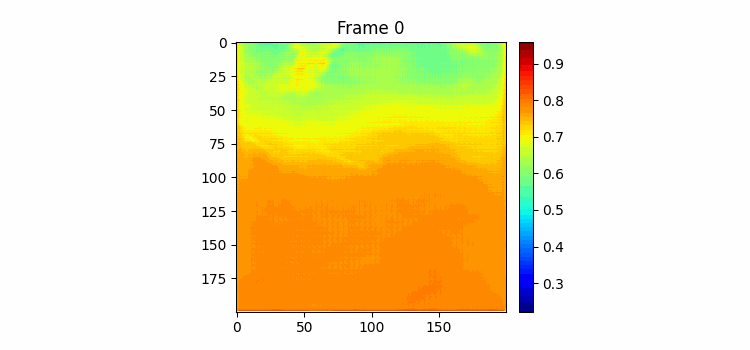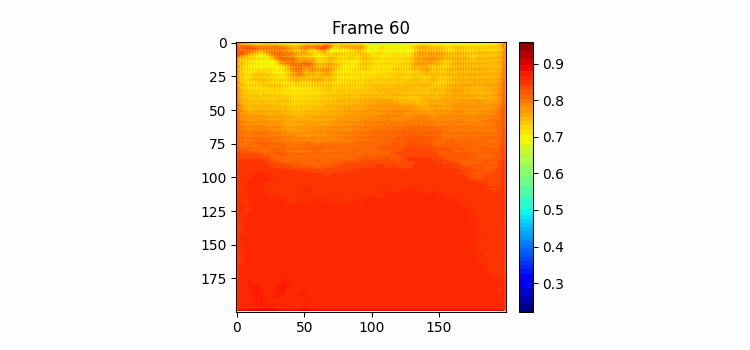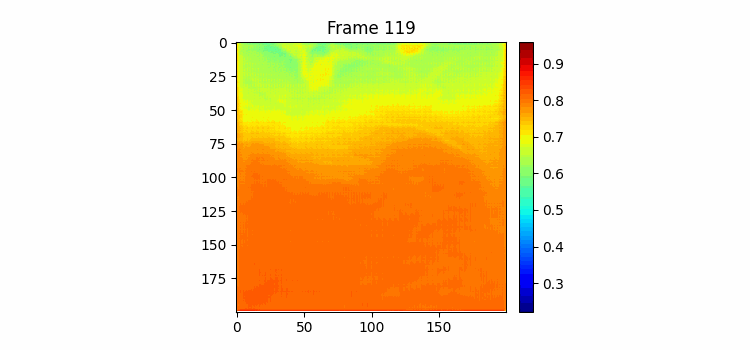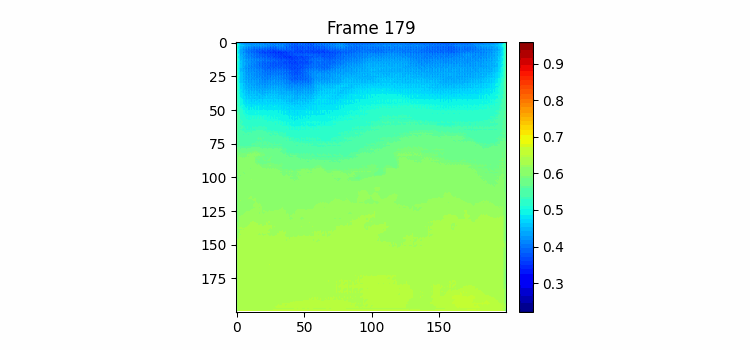
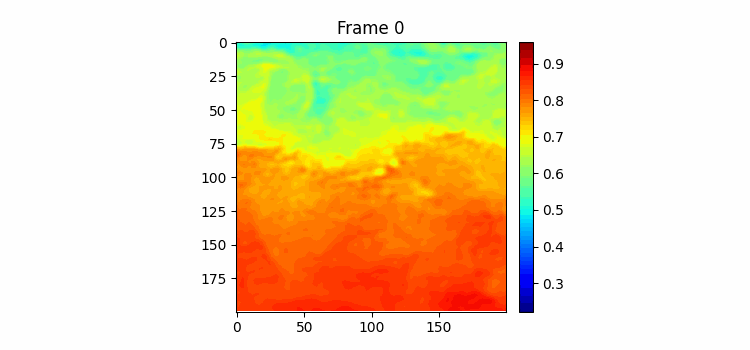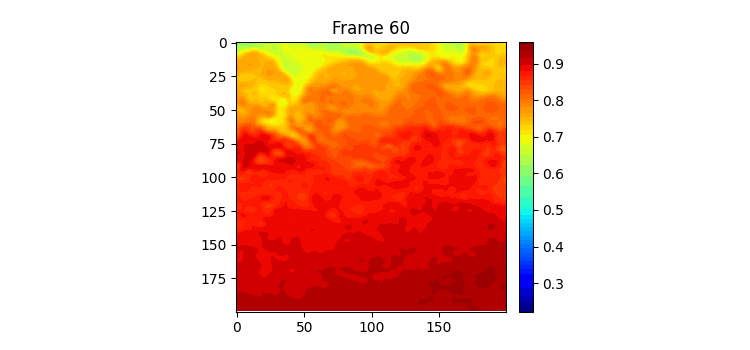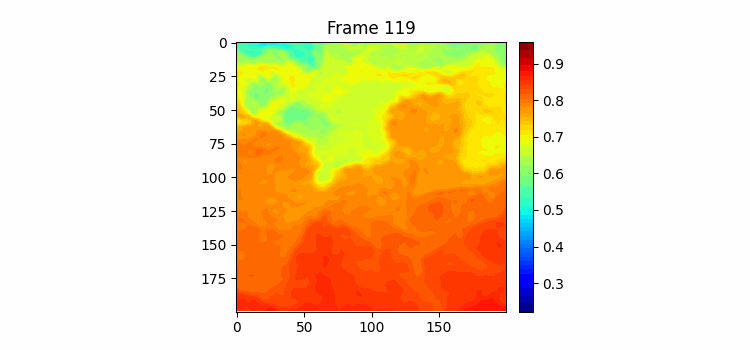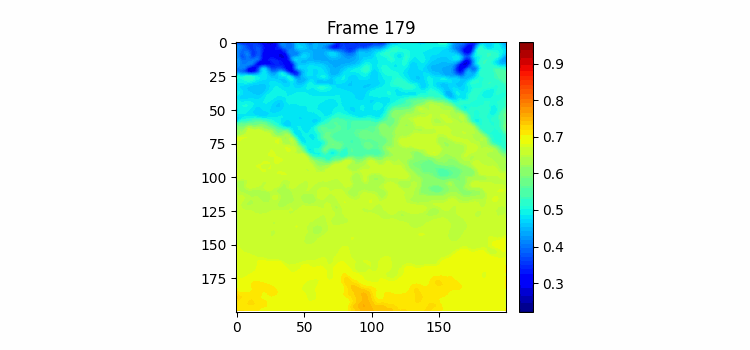
180일치 학습결과이다. 위가 예측이고 아래가 정답이다. 쭉 보면 긴 시간을 예측해도 예측 gif에서 물의 흐름이 빠르게 변하지 않고 천천히 변하고 있다. 그리고 여름이 오는 시즌에 물이 올라가고 가을이 오면서 뜨거운 물이 내려가는 것을 볼 수 있다. 하지만 역시나 물의 경계면 모양을 잘 표현하진 못하고 있는 것을 볼 수 있다.
8월 17일
그 동안 글을 안써서 오늘이 몇 일차인지 까먹었다. 그 동안 딱히 한게 없다. ㅋㅋ 한가지 추가한 것은 시훈님에게 어떻게 그렇게 결과 좋은 모델을 만드셨냐고 물어봤는데 하루 뒤 예측만을 하는 모델이어서 그렇다고 해주셨다. 그래서 나도 그냥 7일 예측 중 맨 처음 예측을 빼고 그 다음 인풋으로 모델 예측이 아닌 실제 이전 7일치를 넣어서 또 그 다음날을 예측하는 방식으로 결과 이미지를 만들어보았다.
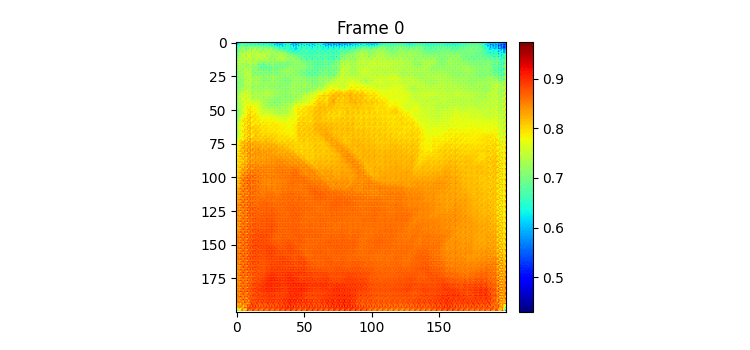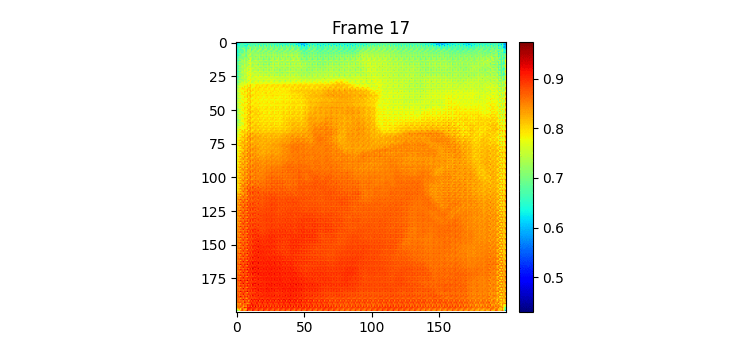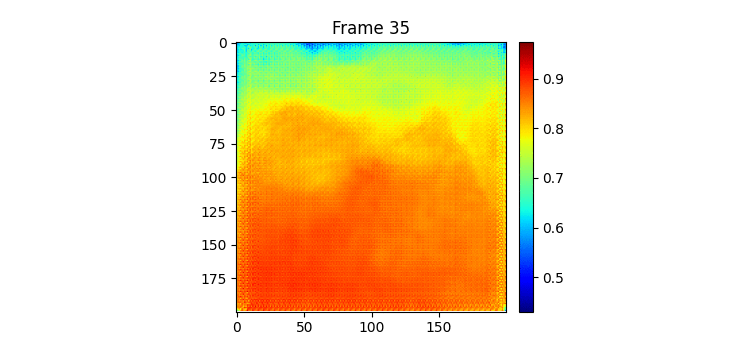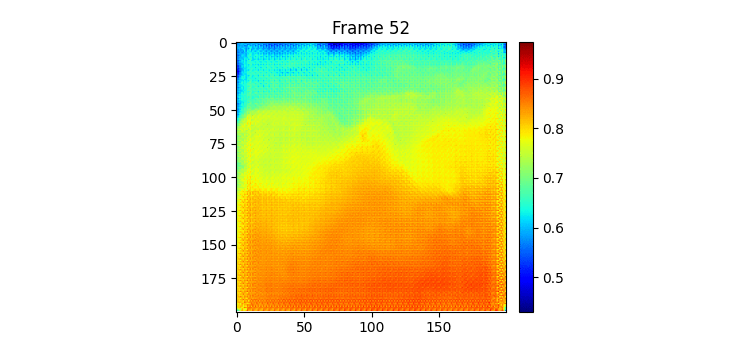
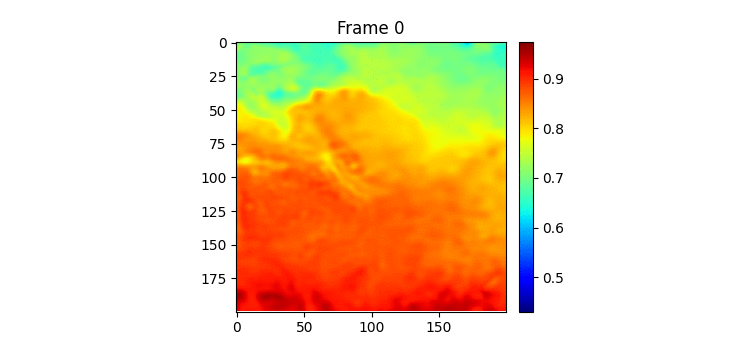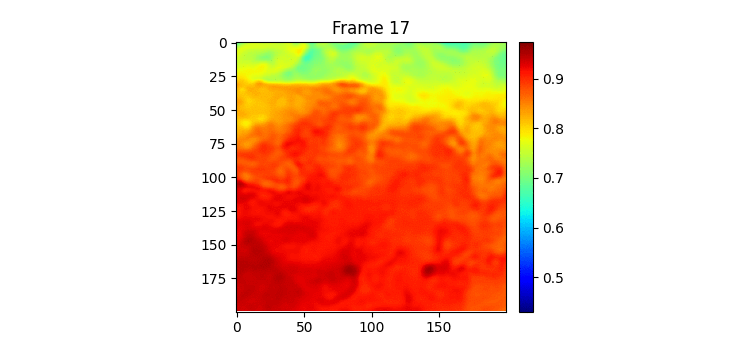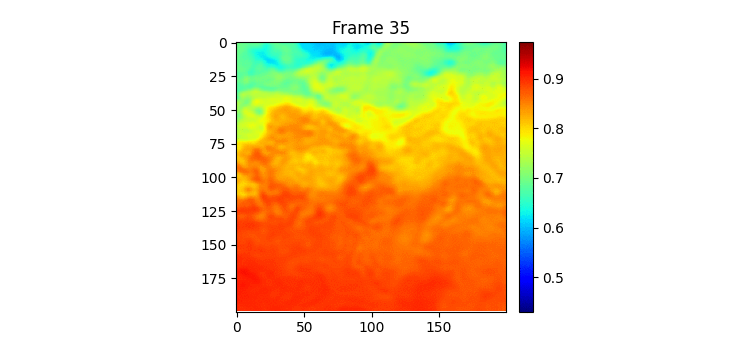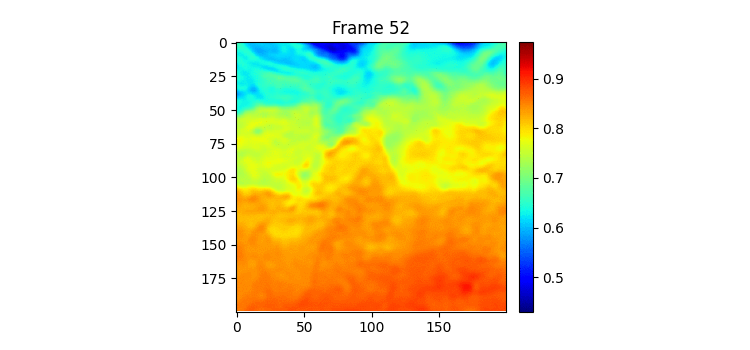
7일 받아서 7일을 예측하는 GSimVP를 이용해 만든 결과이다. 보면 여태까지 결과 중 가장 좋은 것을 볼 수 있다. 하지만 자세히보면 모델의 예측이 하루 정도 느리게 변하는 것 같은 모습을 볼 수 있는데 (아닌가?) 이는 모델이 그냥 바로 전날 사진을 거의 배꼈다는 것으로 추측해 볼 수 있다.

정보 감사합니다.