시리즈 6까지가 캐나다 정부에서 만든 튜토리얼의 2챕터까지였고 3챕터부터 Radar를 이용한 센싱인데 그것을 들어가기 전에 임정호 교수님이 학부 수업 때 사용한 자료들을 먼저 공부하려고 한다.
Supervised Learning을 이용한 Remote Sensing
land cover classification을 할 때 두 종류가 있다.
1. Pixel by Pixel
2. Object-based
말 그대로이고 Object-based classification을 할 땐 높은 spatial resolution 이미지가 주로 사요오딘다고 한다.
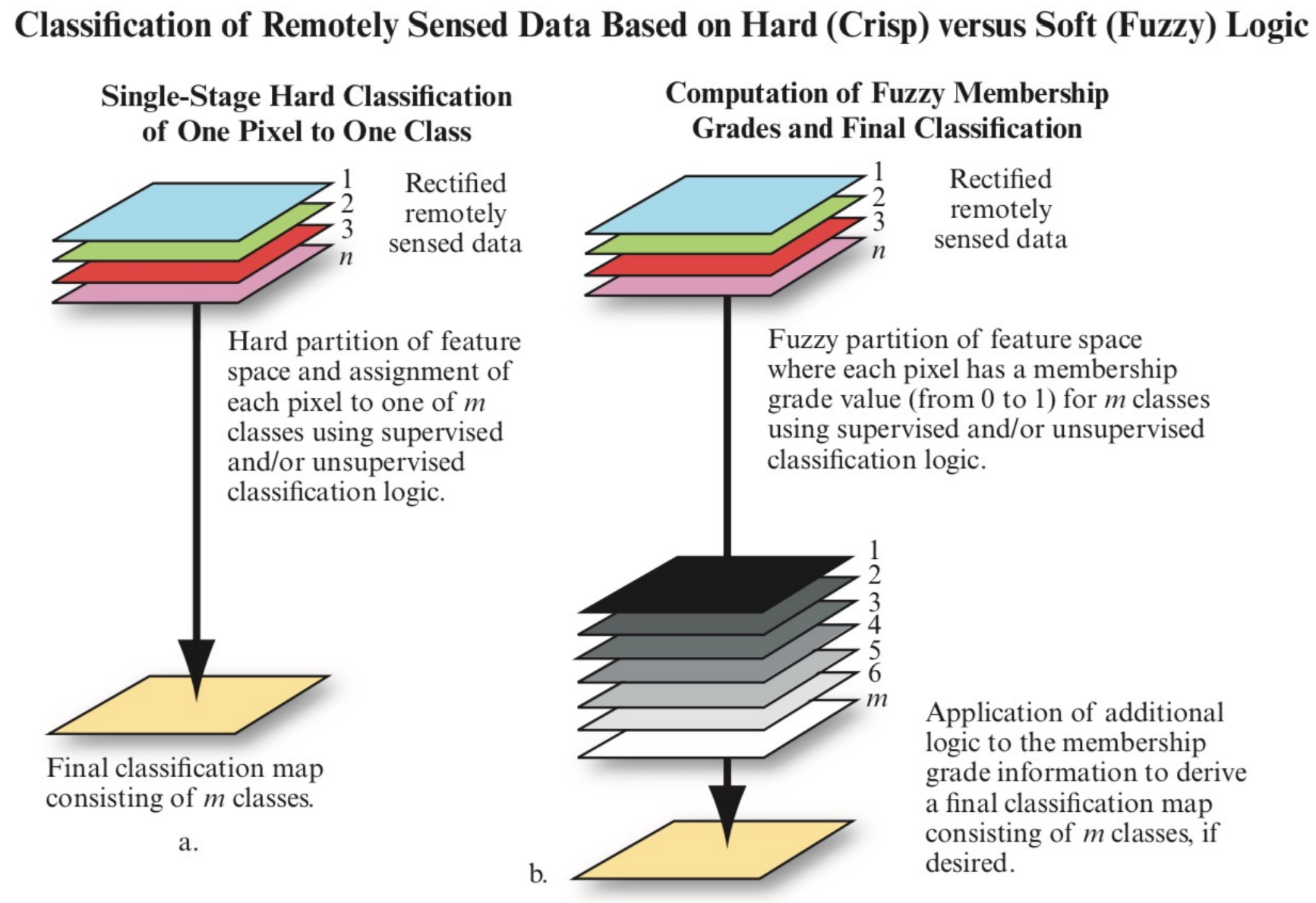
왼쪽이 hard classfication의 경우이고 오른쪽이 fuzzy classification(soft하게 분류하는 것)인 경우이다. fuzzy만 설명하자면 n개의 band를 가진 이미지를 m개의 클래스로 soft하게 분류하고 이것을 추가적인 처리를 거쳐 최종적인 하나의 이미지를 출력하게 된다.
Land Cover는 해당 지역이 무슨 물질로 이루어져있는지를 말하는 것이다. (water, sand, crop, forest, wetland(습지대), asphalt 같은 인간이 만든것들)
Land use는 해당 지형에서 사람들이 뭘 하는가를 의미한다. (agriculture, commerce(상업), settlement(거주지역))
Land cover나 Land use classification에서 모든 지역은 unknown이 아닌 하나의 클래스에 할당되야한다. (흠..)

각 픽셀은 k개의 밴드에 대해 각각 값을 하나씩 갖고 있다. 근데 사진을 보면 측정 클래스 c의 대한 k개의 밴드 값이라는데 이건 무슨 말인지 잘 모르겠다. -> 교과서를 보니 이미 클래스가 분류된 상태에서 해당 클래스에 관련된 픽셀 하나의 대한 벡터를 보여주고 있는 것이다.

저 평균 값이 무엇을 평균한 건진 모르겠는데 어쨌든 클래스 C를 위한 K개의 밴드의 대한 평균 값이라고 한다. -> 사진에서 클래스 C에 해당하는 픽셀들을 다 모아서 각 밴드마다의 값의 평균을 구한 것이다.

클래스 c를 위한 k~l까지의 밴드들의 공분산행렬을 표시한 것이다. V_ckl이라고 표기하고 Vc라고 표현하기도 한다고 한다.
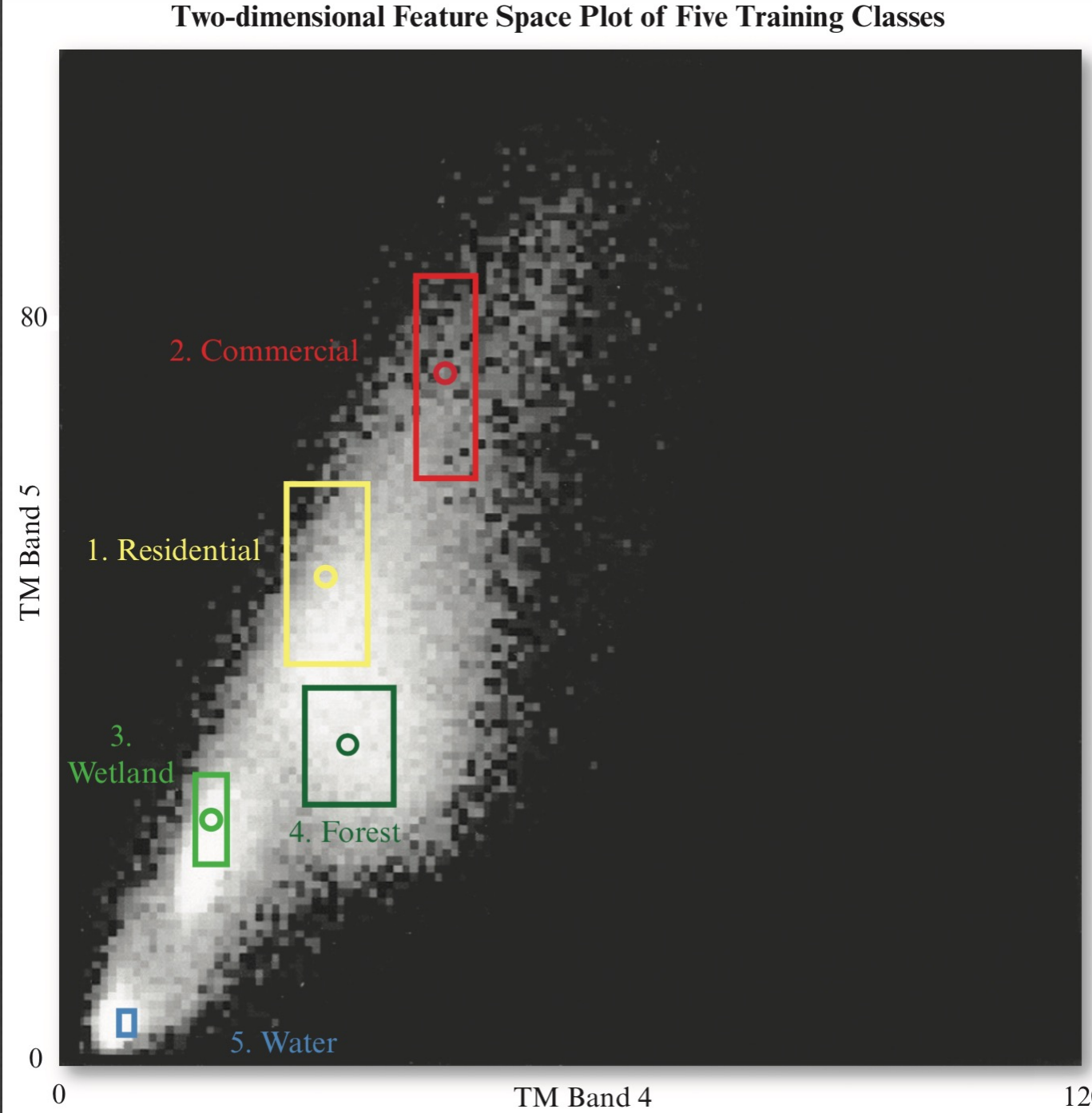
이 그래프는 cospectral mean vector plot(공동분광 평균벡터 도표)라고 하는데 위 사진은 4번 밴드와 5번 밴드의 값만을 표시한 것이다. 만약 어떤 픽셀 값이 예를 들어 4번 밴드는 30, 5번 밴드는 50이라면 그 위치좌표에 해당하는 픽셀의 밝기가 조금 올라간다. 만약 해당 좌표가 여러 픽셀에 걸쳐서 동일하게 나타나면 위 그래프에서 픽셀의 밝기가 점점 밝아진다. 위 사진의 경우 각 클래스 별로 밝기가 잘 나뉘어서 보이는 것을 볼 수 있고 직사각형은 각 밴드의 평균에서 표준편차만큼을 더하고 빼서 만든 영역을 표시한 것이다. 해당 영역에서 각 클래스들은 겹치지 않는다.
trispectral parallelepiped(삼중분광 평행육면체)라는 것이 있는데 축을 3개써서 데이터를 시각화하고 싶을 때 바라보는 방향을 조금 비스듬히 봐야하기 때문에 원래 데이터의 좌표를 조금 회전시켜서 보여주는 걸 말하는 것 같다. 근데 요즘에 이런거 다 알아서 해주지 않나?

위 식은 두 클래스가 가지는 공분산 행렬을 이용해 두 클래스를 가장 잘 구분할 수 있는 밴드셋을 찾을 때 사용되는 divergence(발산)을 구하는 식이다. 가장 큰 값을 가지는 밴드셋을 선택하면 된다.

위 식도 발산과 똑같은 목적으로 쓰이는 다른 방식의 값이다. m개의 클래스를 구분하고자 할 때 쓰이고 값이 클때가 좋은거임-> 아 암튼 그럼
Maximum liklihood classficaitoin
옛날에 배운 MLE랑 똑같은 것 같다. 근데 사실 그 때도 잘 이해 못했다. 이 방법은 각 밴드의 분포가 정규분포 모양으로 나타날 때 사용할 수 있다.
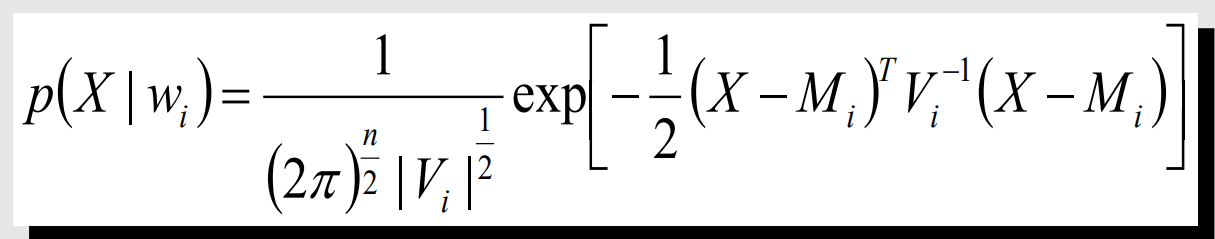
M하고 V는 위에 나온 평균과 공분산 행렬이다. 결과는 벡터로 나오고 거기서 argmax하면 된다.
Unsupervised Classification in Remote Sensing
위에 있는 지도학습 방법들은 내 생각엔 잘 안쓰일 것 같다. (딥러닝짱) 이젠 비지도 학습 방법을 알아보자
land cover에서 기본적으로 쓰이는 알고리즘은 K-means clustering이다. 내가 너무 잘 알고있기 때문에 설명은 생략.자료엔 시각화를 위해 2개의 밴드만을 이용해 데이터를 만들고 클러스터링을 해주고 있는데 n개의 밴드를 통해 클러스터링을 해도 시각화만 못할 뿐 충분히 가능하다고 생각한다.
ISODATA
ISODATA(Iterative Self-Organizing Data Analysis Technique)알고리즘은 K-means의 좀 더 업그레이드 버전이다. 하지만 하이퍼파라미터가 훨씬 많다. 열심히 공부해보았는데 일단 K-means만큼 완벽하게 이해하진 못했다. 그래도 단계별로 설명해보겠다.
-
초기 위치 할당 (각 밴드의 평균과 분산을 이용한다. 모든 차원에 대해 평균-분산과 평균+분산의 좌표를 구해 벡터를 만들고 공평하게 k등분하게 각 클러스터 중심의 초기 좌표를 구한다.)
-
각 데이터를 가장 가까운 클러스터에 할당 -> 이건 K-means와 똑같다.
-
각 클러스터의 중심을 재계산 후 각 클러스터 중심간의 거리 측정 (L1 혹은 L2)하여 임계값(C, 하이퍼파라미터)보다 작으면 두 클러스터를 합치고 중심은 두 중심의 평균으로 설정
-
샘플 수가 일정 임계값(하이퍼파라미터)이하인 클러스터 삭제
-
모든 클러스터에 대해 클러스터 중심과 그 클러스터에 속해 있는 데이터들 간의 거리의 표준편차를 구해 임계치(split separation vlauem, 하이퍼파라미터)이상이면 두 클러스터를 분리하고 분리된 클러스터의 중심은 이전 클러스터 중심에서 +-1표준편차만큼 떨어진 곳에 위치시킨다.
2~5를 T(반복과정 동안 클러스터가 바뀌는 데이터의 비율)보다 작거나 M번 반복
사실 각 과정의 순서나 정확한 계산 방식이 자료마다 달랐고 가져가야될 핵심은 클러스터가 삭제, 병합, 분리된다는 것 같다.
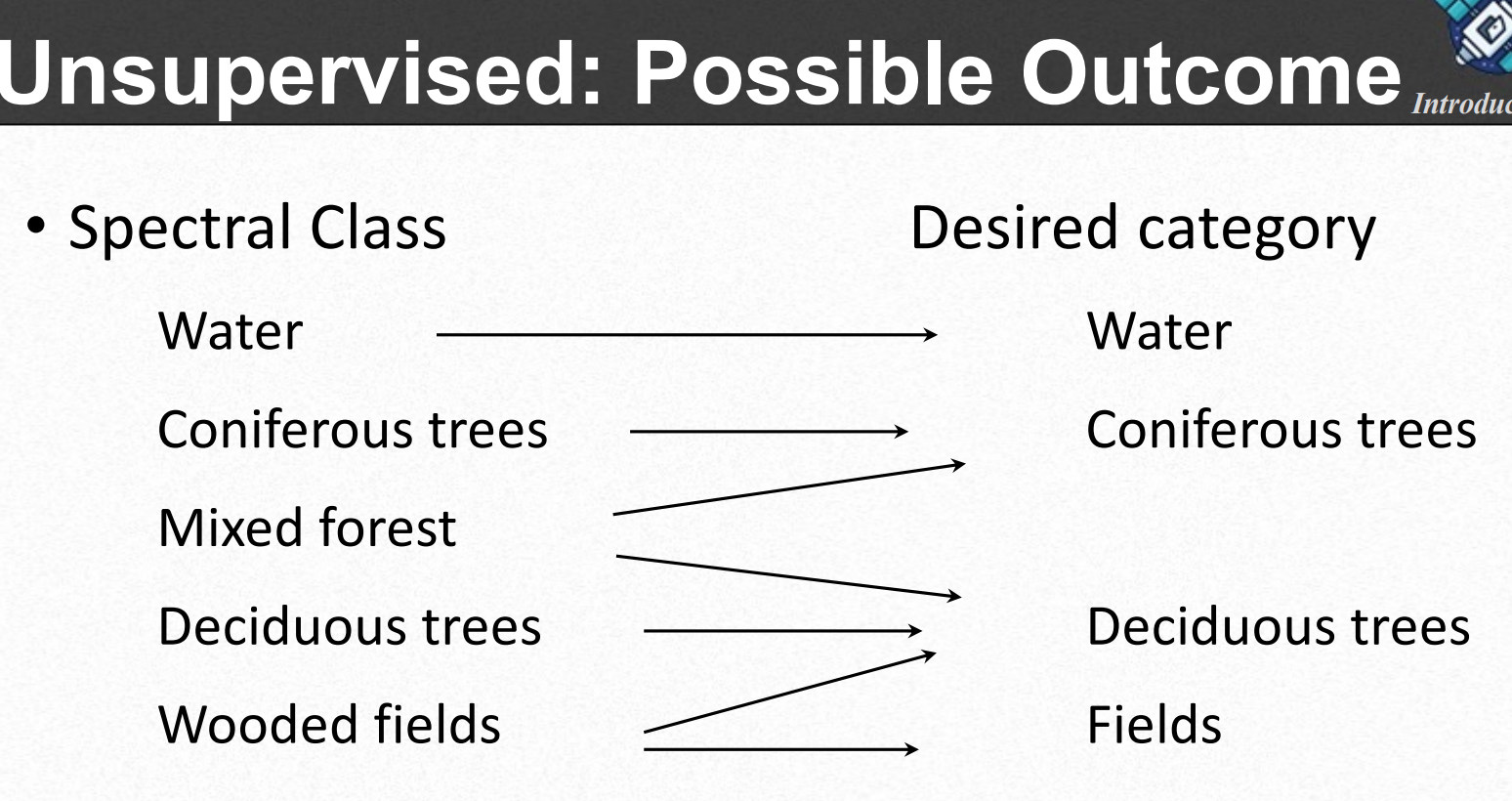
비지도 클러스터링을 통해 주어진 데이터를 잘 분리하는 n개의 클러스터를 만들어도 이것을 우리가 원하는 최종 q개의 Desired category에 잘 매칭시키는 것이 쉽지 않다.
SAM 기법
Spectral Angle Mapper(SAM)은 각도를 이용해 유사도를 비교한다고 한다. 사실 이해가 잘 안된다.
이미 분석이 끝난 hyperspectral image를 기준으로 삼은 뒤 같은 수의 band를 가진 이미지에 한해 적용할 수 있다.
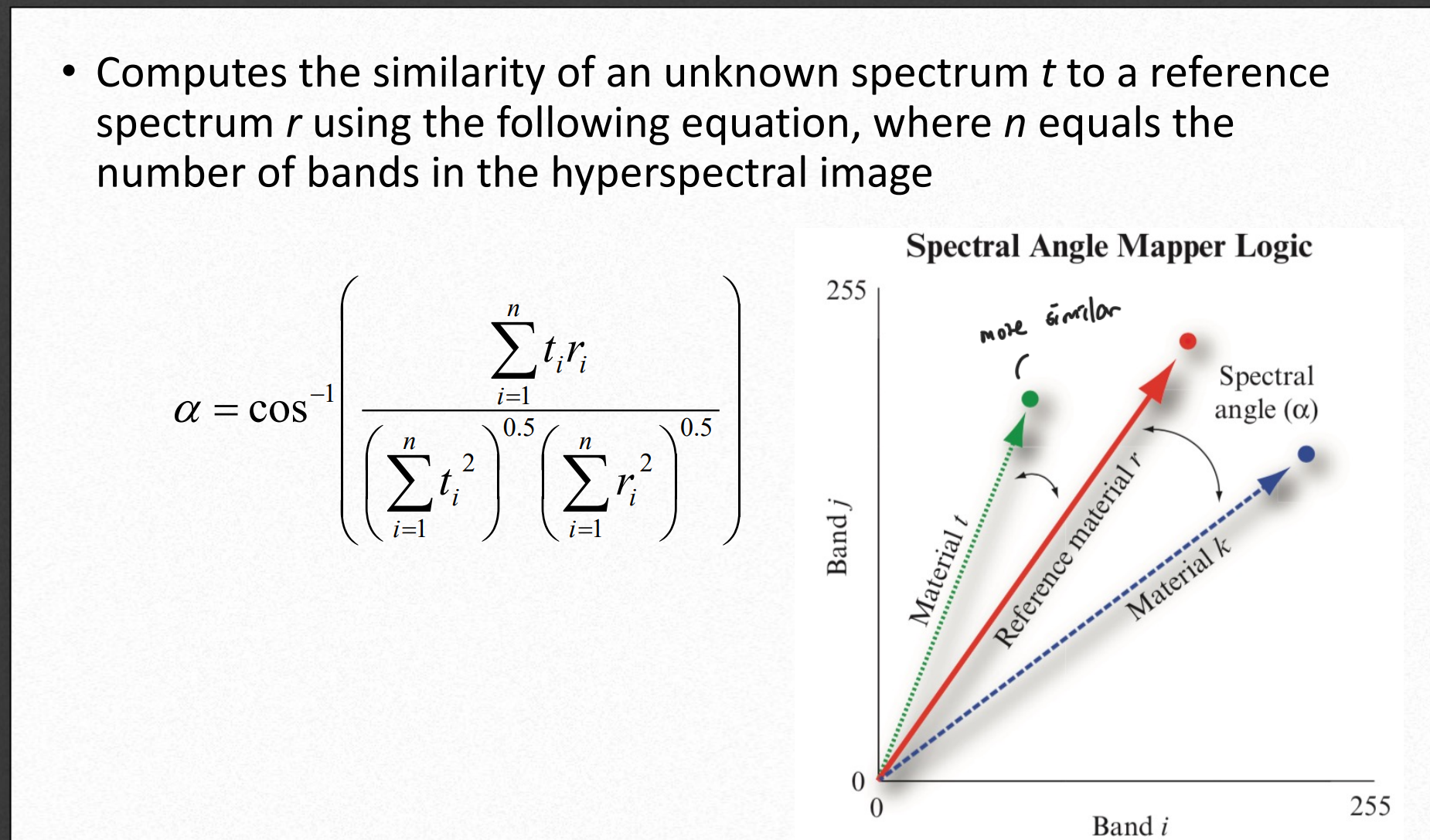
공식을 보면 어떤 스펙트럼 (사진에선 1~n까지의band)가 있을 때 기준이 되는 사진과 비교하고 싶은 사진의 band끼리 위 공식을 통해 계산하면 각 band가 결국 벡터이기 때문에 두 벡터가 이루는 각도를 알 수 있고 가까울수록 원본이미지에서 해당 스펙트럼이 의미하는 물질과 비슷하다는 것이다.
Subpixel classification
한 픽셀 내에 존재하는 여러 land의 종류를 분류하는 것인데 linear specetral unimxing을 사용한다고 한다. 전혀 이해 못했다.
Single-pixel classification이 내가 아는 Image segmentation이고 object-based image segmentation은 여러 픽셀을 뭉뚱그려 분류하겠다는 것 같다. 자세한건 안나와있다.
정확도평가
land cover classification도 결국 분류기 때문에 분류 문제에서 항상 등장하는 오차행렬을 통해 오차를 표시한다고 한다. 또 다른 방법은 이항분포를 사용하는 것이다.

위 사진에서 p가 기대하는 정확도이고 q는 1-p, E는 허용가능한 오차이다.(이게 뭔지 잘 모르겠다.) 이 공식을 통해 나온 값이 테스트할 셋의 사이즈이다. 이렇게 구한 size만큼 test image에서 임의의 point에서 샘플링을하면된다.
샘플링을하는 방법도 여러가지가 있는데 랜덤 샘플링이 있고 균일한 위치 간격으로 샘플링하는 방법이 있고 제일 좋은게 Stratified random sample(층화임의표집)인데 이미지 안에 존재하는 class들의 비율을 구한 다음 그 비율에 맞게 샘플링 point들을 설정하는 것이다. 예를 들어 이미지의 20%가 바다고 80%가 육지면 10개 샘플링 할 때 2개는 바다 8개는 육지 이런식으로 샘플링하는 것이다.
오차행렬을 가지고 정확도를 평가하는 방법도 있다.
Overall accuracy: 그냥 흔히 아는 정확도이다. 맞춘 픽셀개수 / 전체픽셀 수 이다.
Producder's accuracy(Omission error): 하나의 정답 클래스의 대해서 구하는 것이고 잘 분류한 픽셀 / 해당 정답 클래스의 픽셀 수
User's accuracy(commission error): 하나의 예측 클래스(모델이 해당 클래스라고 예측한 것들)에서 잘 분류한 픽셀 수 / 모델이 해당 클래스라고 예측한 필셀 수
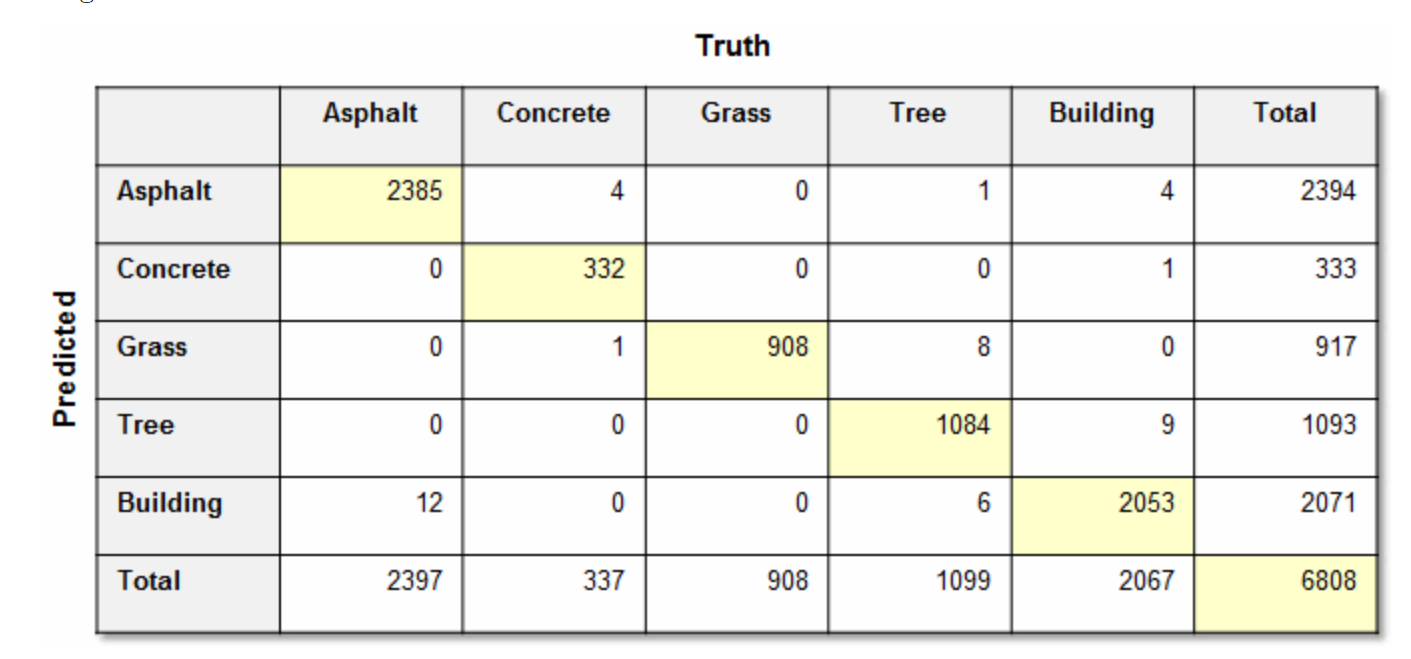
쉽게 말해서 위 사진에서 가로방향으로 잘 분류한 개수를 더해서 오른쪽 끝에 있는 total로 나누면 comission error고 세로로하면 omission error이다.
Kappa analysis
모델의 정확도를 계산할 때 단순히 맞춘것에 대해서만 판단하는 것이 아니라 틀린 것들까지 고려해서 전체적인 성능을 %로 표현하는 방법이다.
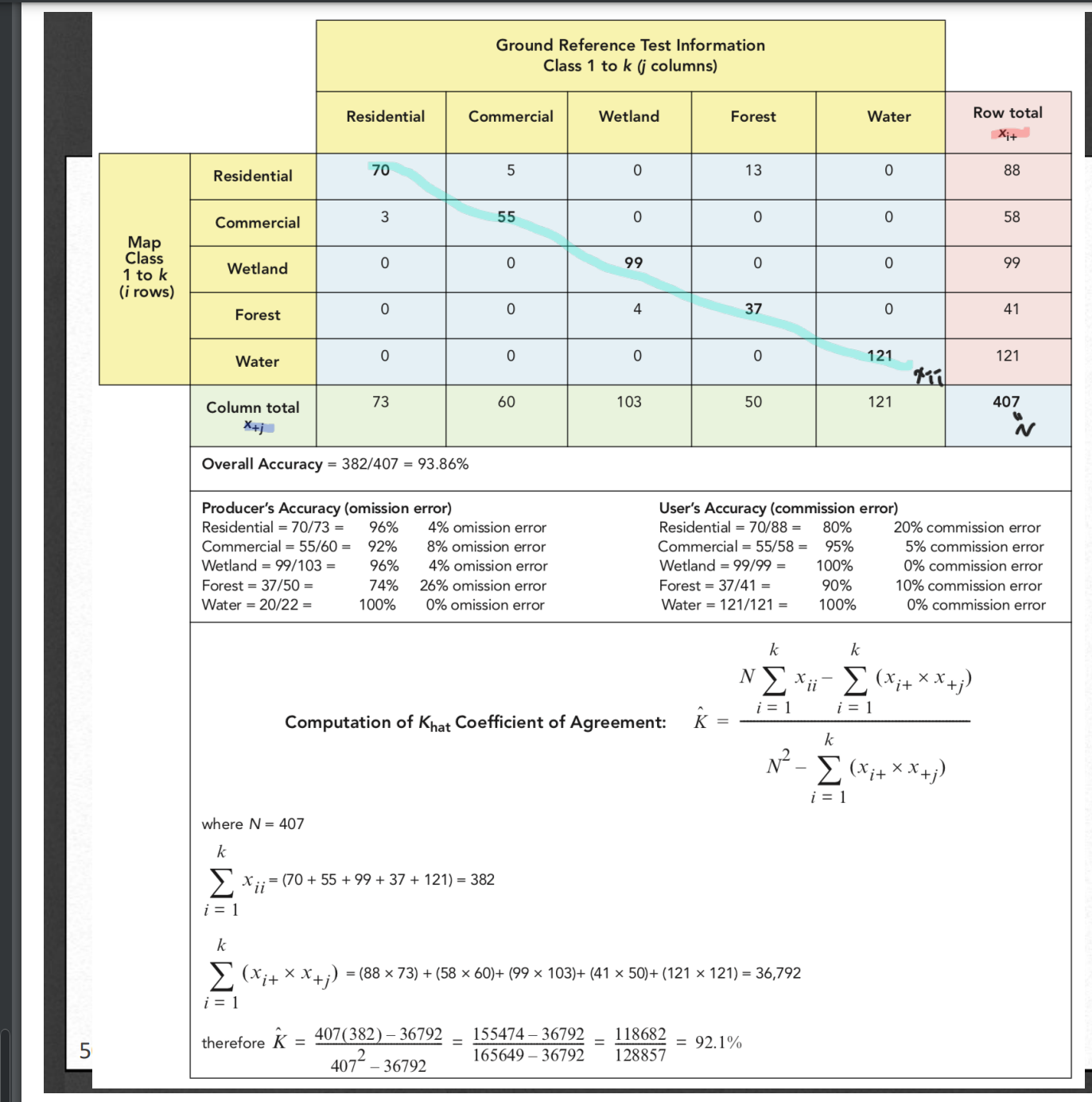
위 사진에 공식까지 친절히 나와있고 이해가 쉽다.
