[출처] : https://programmers.co.kr/
문제
두 개의 단어 begin, target과 단어의 집합 words가 있습니다. 아래와 같은 규칙을 이용하여 begin에서 target으로 변환하는 가장 짧은 변환 과정을 찾으려고 합니다.
- 한 번에 한 개의 알파벳만 바꿀 수 있습니다.
- words에 있는 단어로만 변환할 수 있습니다.
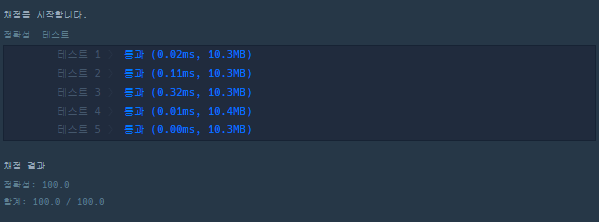
예를 들어 begin이 "hit", target가 "cog", words가 ["hot","dot","dog","lot","log","cog"]라면 "hit" -> "hot" -> "dot" -> "dog" -> "cog"와 같이 4단계를 거쳐 변환할 수 있습니다.
두 개의 단어 begin, target과 단어의 집합 words가 매개변수로 주어질 때, 최소 몇 단계의 과정을 거쳐 begin을 target으로 변환할 수 있는지 return 하도록 solution 함수를 작성해주세요.
제한사항
- 각 단어는 알파벳 소문자로만 이루어져 있습니다.
- 각 단어의 길이는 3 이상 10 이하이며 모든 단어의 길이는 같습니다.
- words에는 3개 이상 50개 이하의 단어가 있으며 중복되는 단어는 없습니다.
- begin과 target은 같지 않습니다.
- 변환할 수 없는 경우에는 0를 return 합니다
입출력 예
접근(1)
각 단어에서 한글자씩만 바꾸되, 바꿀 단어는 words에 있어야 한다.
한글자씩 바꿔서 최종적으로 begin값을 target값으로 바꾸는 문제다.
이 문제의 접근은 다음과 같다.
- 각 단어를 노드로 생각한다(start노드는 begin안에 있는 변수)
- 인접노드는 한글자만 바뀌고 words안에 있는 단어로 구성한다.
- 한글자 차이의 확인은 별도의 함수(check)를 통해서 판단하도록 한다
- begin을 시작노드로 하고, words의 단어로 트리를 생성한다.
- bfs로 탐색하면서 노드 탐색시마다 가중치를 1씩더해서 최소 몇번만에 도달했는지 확인한다
- 방문노드 확인을 dict로 만들어서 value에 거친 단계의 최소값을 저장한다
- 최종적으로 방문확인 dict를 반환하고 target노드의 값을 출력한다.
결국 단어를 노드로 보고, 간선으로 연결된 노드는 한글자만 바뀐단어라고 생각해서 그래프로 보고 탐색을 해주면 되는 문제였다.
최종 변환 단계를 출력해야되니, 간선의 가중치를 1로 생각해서 인접노드로 갈때 마다 +1 씩해서 변환단계를 세 주면 되는 것이었다.
이 방법은 처음 접근한 방법이다.
check함수를 만들어서 두 단어가 한글자 차이가 나는지 확인하도록 하였다.
내부 로직은 단순하게 반복문을 글자수만큼 돌려서 비교하는 식으로 했다.(모든 단어의 길이가 같기 때문에 가능함)
bfs함수는 그래프로 만들고 이를 탐색하면서 시작노드를 [노드번호, 0] 으로 두고, 인접노드로 넘어갈때마다 +1해서 저장하도록 하여 target단어에 도달했을때 몇단계를 거쳤는지 확인할수 있도록 하였다.
solution함수는 실제로 실행하는 함수이다.
여기서는 우선 words안에 target단어가 없으면 0을 반환해주었다.
그 다음 check함수를 이용해서 dict형태에 그래프를 만들었다.
{노드(단어):[인접 노드들]} 이와 같이 만들어주었다.
만든 그래프를 bfs탐색을 해서 몇 단계를 거쳤는지 해당값을 반환해주었다.
from collections import deque
#단어차이가 1인 것을 판별하는 함수
def check(node,word:str)-> bool:
count= 0
for i in range(len(node)):
if node[i] != word[i]:
count+=1
if count >=2:
return False
if count == 1:
return True
else:
return False
#만들어진 트리를 탐색하는 함수
def bfs(start_node:str,graph:dict)-> dict:
visited = dict()
need_visited = deque(list())
#탐색을 위해 처음 값 넣기
need_visited.append([start_node,0])
#반복하면서 탐색
while need_visited:
current_node,current_count = need_visited.popleft()
if current_node not in visited:
visited[current_node] = current_count
if current_node in graph:
for i in graph[current_node]:
need_visited.append([i,current_count+1])
elif current_node in visited and visited[current_node] > current_count:
visited[current_node] = current_count
return visited
#실제로 돌아가는 로직
def solution(begin, target, words):
answer = 0
#target단어가 words안에 없다면
if target not in words:
return 0
#그래프형태로 만들기 - dict형태로 만듦
temp = [begin] + words
graph = {node:list() for node in temp}
temp_queue = deque(temp)
for i in temp:
for j in temp:
if check(i,j) == True:
graph[i].append(j)
result = bfs(begin,graph)
return result[target]
접근(2)
위의 방법은 반복문을 이용해서 미리 그래프를 만들어야 된다는 단점이 있다.
단어 변환과정에서 사용되지 않을 단어도 있을텐데, 이러한 단어들도 전부 그래프에 들어간다는 점이 속도저하를 일으키지 않을까 라고 생각했다.
따라서 그래프를 미리 만들지 않고 bfs탐색시에 만들면서 탐색하는 방법을 고민해보았다.
(문자 체크 함수는 그대로 썼다)
- bfs함수의 인자에는 그래프 대신 words리스트가 들어올것이다
- 탐색이 필요한 노드에 주어진
begin단어와 count=0 이 들어갈것이다 - word를 반복문으로 돌면서 자식노드로서 조건에 부합하는 값이 있으면 방문표시를 True로 하고 다음 탐색을 위해 need_visited에 넣는다.
4.need_visted에서 하나씩 꺼내면서 탐색하다가, target을 만나면 해당 노드에 저장된 count값을 출력한다.
이러한 방법은 훨씬 빠르며 노드가 늘어날수록 더 빠를것이다.
미리 그래프를 반복문을 돌면서 만들 필요없이 bfs 탐색시에 하위노드를 만들면서 검사하는 것이다.
시작노드 단어만 넣어두고 check함수를 이용해서 해당 단어의 인접노드가 될 값들을 찾아서 저장하는 방식이다.
이러면 굳이 미리 그래프를 만들필요가 없어져서 좀 더 빠른 속도를 낼수 있다.
from collections import deque
#단어차이가 1인 것을 판별하는 함수
def check(node,word:str)-> bool:
count= 0
for i in range(len(node)):
if node[i] != word[i]:
count+=1
if count >=2:
return False
if count == 1:
return True
else:
return False
def bfs(start_node,target,graph) -> int:
visited = [False for _ in range(len(graph))]
count = 0
need_visited = deque(list())
need_visited.append([start_node,0])
while need_visited:
current_node,current_count = need_visited.popleft()
#만약 target단어면 current_count를 return
if current_node == target:
count = current_count
break
for i in range(len(graph)):
if check(current_node,graph[i]) == True:
if visited[i] == False:
visited[i] = True
need_visited.append([graph[i],current_count+1])
return count
def solution(begin, target, words):
#target단어가 words안에 없다면
if target not in words:
return 0
result = bfs(begin,target,words)
return result결과
아래의 두 결과를 보면 속도 차이가 나는 것을 볼 수 있다.
그렇다고 극과 극으로 차이가 나진 않았지만, 만약 그래프의 노드수가 정말 크다면, 이 속도차이는 크게 벌어질 것이라고 생각한다.
-
첫번째 접근 결과
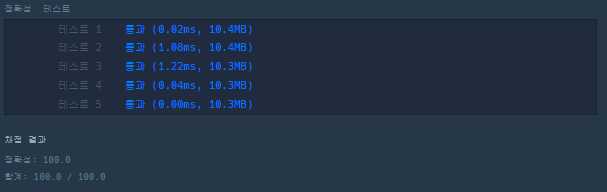
-
두번째 접근 결과