개인 프로젝트로 티켓 예매 서비스를 구현하면서 좌석 선택 기능에서 발생한 동시성 이슈와 해결 방법, Hazelcast의 분산 락을 사용하여 동시성 제어 구현 내용을 공유하고자 합니다.
동시성 이슈
동시성 이슈란 공유 자원에 동시에 2개 이상의 프로세스 혹은 스레드가 접근하여 실행 결과가 기댓값과 다른 문제를 말합니다. 공유 자원은 로직 상에서 다루는 변수나 데이터베이스에 저장된 데이터 등이 될 수 있습니다.
문제점
좌석 선택 기능은 다음과 같은 플로우로 진행됩니다.
- ‘선택한 공연에 대한 유효성 검증’
- ‘선택한 좌석에 대한 유효성 검증’
- ‘유저 정보와 함께 선택한 좌석 정보 DB에 저장’
2번과 3번 과정 사이에서 동시성 이슈가 발생했습니다.
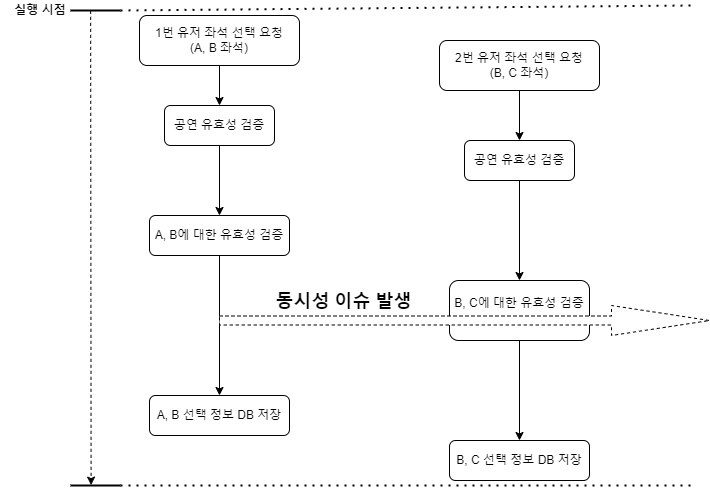
1번 유저의 선택 정보가 DB에 반영되기 전에 2번 유저의 요청에서 B 좌석에 대해 검증하면 선택 가능한 것으로 판단되기 때문입니다.
Commit 전의 변경 사항도 조회할 수 있도록 트랜잭션 격리 수준을 Read Uncommitted로 조정했지만 별개의 로직 사이에서는 얼마든지 데이터 조회가 이뤄질 수 있기 때문에 save가 실행되기도 전에 데이터를 읽는 다면 역시 동일한 문제가 발생합니다.
좌석 선택 기능에서 달성해야 하는 조건을 기반으로 가장 적절한 방법을 고민했습니다.
✅ 충족 해야 할 조건
- 예매가 완료될 때까지 선택한 좌석의 점유가 보장되어야 함
- 별개의 요청에 대해서도 점유가 보장되어야 함( = 좌석 선택과 예매는 별개로 처리될 수 있어야 됨)
- 일정 시간이 지나면 자동으로 점유 해제되어야 함
- 점유 정보는 모든 요청에서 확인 가능해야 됨
해결 방안
동시성 제어 방법으로 DB 수준의 Lock 걸기, 분산 락을 두고 고민하였습니다.
synchronized 키워드를 통해 로직 상에서 제어하는 것은 다중 서버 환경에서 동시성 이슈를 해결할 수 없으므로 제외하였습니다.
DB 수준의 Lock
✔️ 데이터베이스는 MySQL의 경우만 고려했으며, 데이터베이스 종류에 따라 다를 수 있습니다.
Optimistic Lock(낙관적 락)
낙관적 락은 충돌이 발생하는 순간에 이슈를 해결하는 방법입니다. 레코드에 락을 설정하지 않고, Version 속성을 사용하여 데이터를 업데이트할 때 해당 데이터의 마지막으로 읽힌 후의 업데이트 여부를 확인하여 동시성을 관리합니다.(Version으로 사용되는 데이터 타입으로는 Integer와 Timestamp 또는 Datetime 등이 있습니다.)
동시에 같은 데이터의 업데이트가 요청되었을 때 버전을 확인하여 일치하는 요청만 반영하고, 나머지는 실패 처리합니다.
데이터베이스 수준의 락을 설정하지 않기 때문에 데드락이나 동시성 성능 이슈를 방지할 수 있습니다.
또한 JPA에서는 LockMode를 설정하여 비교적 쉽게 락을 구현할 수 있습니다.
// EntityManager
public <T> T find(Class<T> entityClass, Object primaryKey, LockModeType lockMode);
public void lock(Object entity, LockModeType lockMode);
// Query
Query setLockMode(LockModeType lockMode);
// Spring Data JPA에서 제공
public @interface Lock {
LockModeType value();
}Pessimistic Lock(비관적 락)
비관적 락은 충돌이 자주 발생할 것이라 가정하고 레코드에 대해 공유 락 또는 배타 락을 설정합니다.
공유 락(Shared Lock)은 동시에 여러 트랜잭션에서 획득할 수 있어 공유 락을 가진 경우, 같은 데이터를 동시에 읽을 수 있습니다. 쓰기는 불가합니다.
배타 락(Exclusive Lock)은 동시에 여러 트랙잭션에서 획득할 수 없어(공유 락도 불가) 배타 락이 설정된 경우, 읽기와 쓰기 모두 불가합니다.
위에서 살펴본 낙관적 락은 충돌이 실제로 발생했을 때 처리하는 방식이기 때문에 동시 요쳥 수가 많은 서비스에서는 빈번하게 예외가 발생할 수 있습니다. 이때는 비관적 락을 통해 빠르게 요청을 실패 처리하는 것이 유리할 수 있습니다.
비관적 락은 트랜잭션 충돌없이 데이터의 무결성을 보장할 수 있습니다. 낙관적 락과 마찬가지로 JPA를 사용한다면, 쉽게 락을 구현할 수 있습니다.
하지만 데이터베이스 수준의 락을 걸기 때문에 데드락 발생 위험이 존재하고, 동시 처리 성능이 떨어질 수 있습니다.
Named Lock
MySQL에서는 Lock 관련 함수를 통해 문자열 타입의 데이터(ex. 특정 컬럼의 값)에 락을 설정할 수 있습니다.
GET_LOCK(str,timeout) : str에 대해 timeout으로 설정된 시간 동안의 락 획득을 시도합니다.
IS_FREE_LOCK() : 현재 락 획득 가능 여부
IS_USED_LOCK() : 현재 락이 점유 중인지 여부
RELEASE_ALL_LOCKS() : 현재 세션이 가진 락을 모두 반납
RELEASE_LOCK(str) : 해당 락 반납
락 획득과 반환에 대해 수동으로 처리해주어야 하지만 명시적으로 획득과 반환을 처리함으로써 락의 범위와 제한 시간을 세밀하게 제어할 수 있다는 장점이 있습니다.
또한 분산 환경에서 일관된 락 메커니즘을 제공할 수 있는 분산 락 구현이 가능합니다.
위의 세 가지 방식은 모두 DB에서 제공하는 메커니즘을 사용하기 때문에 DB 커넥션과 밀접한 연관이 있습니다.
데이터베이스의 커넥션은 무한정 늘릴 수 없습니다. AWS RDS의 MySQL을 기준으로 M4.xlarge 사양의 max_connections 값은 1320입니다.
계산 식을 통해 계산해보면 16 1024 1024 1024 / 12582880 = 약 1365 입니다. 운영 체제 및 RDS 관리 용으로 예약된 메모리가 있기 때문에 실제 허용된 값은 계산 값보다 작습니다.*
(※ 12582880는 AWS 문서에 명시된 값입니다.)
만약 12,000석의 좌석에 대해 DB 커넥션을 사용하여 락을 점유하려고 한다면 커넥션은 금방 고갈됩니다. 보통 서비스에는 좌석 선택 외의 기능도 존재하니, 서비스 장애로 이어질 것임을 예상할 수 있습니다.
스케일 업을 통해 커넥션 수를 늘리는 데에는 한계가 있기 때문에 커넥션이 고갈되지 않도록 관리하는 것이 중요합니다.
대신 스케일 아웃을 통한 성능 향상을 생각해봐야 하는데, RDB는 수평 확장에 유연하지 않습니다. 수평 확장을 하게 되면 데이터베이스 간의 동기화를 고려해야 하는데, 항상 일관성 보장을 달성하기란 거의 불가능합니다.
따라서 데이터베이스의 커넥션을 사용하지 않으면서 분산 환경에 맞게 설계된 기술을 사용하는 것이 적절하다고 판단했습니다.
또한 좌석 점유 데이터를 DB에 저장하면 고려해야 하는 지점이 한 가지 더 있습니다. ‘일정 시간이 지나면 자동으로 점유 해제되어야 한다.’는 조건입니다.
좌석은 선택했지만 예매 완료까지 이어지지 않은 상황이 존재할 수 있고, 이때는 해당 좌석에 대한 점유 데이터를 삭제해야 합니다. 별도의 트리거없이 점유 된 좌석마다 일정한 유효 시간을 설정할 수 있는 Lock 매커니즘을 선택하고자 했습니다.
결과적으로 유효 시간을 설정할 수 있으면서 다중 서버 환경에서도 사용할 수 있는 별도의 분산 락 기술을 도입하기로 했습니다.
별도의 기술을 사용한 분산 락 - 선택✅
분산 락은 여러 서버가 존재하는 분산 환경에서 동일한 자원에 대한 동시성 이슈를 제어할 수 있습니다.
Redis, Zookeeper, Hazelcast 등을 통해 분산 락을 구현할 수 있습니다. 별도의 인프라 구축 및 관리가 필요하기 때문에 그에 대한 비용과 러닝커브가 존재하기는 합니다. 하지만 동시 요청량이 매우 많은 서비스라면 데이터베이스 외의 자원을 사용하여 동시성 이슈를 처리하는 것이 효과적일 수 있습니다.
분산 락을 지원하는 여러 기술 중 Hazelcast, Redis 두 가지를 두고 마지막까지 고민하였고, 최종적으로는 Hazelcast를 선택했습니다. Zookeeper는 자체가 비교적 무겁고, 동일한 Lock을 두고 경쟁하는 클라이언트가 매우 많은 경우에는 큰 성능 저하가 있어 제외하였습니다.
✔️ 일관성을 보장하는 분산 락 지원
Redis의 Redisson을 통해 분산 락을 구현할 수 있습니다. 분산 환경에서는 split-brain 이슈가 발생했을 때의 잠금의 일관성을 확보하는 것이 매우 중요합니다.
Redis는 네트워크 지연, 높은 부하로 인해 프로세스가 일시 중지되었을 때 잠금의 일관성이 보장되지 않습니다.
Hazelcast는 클러스터를 주기적으로 검사하는 백그라운드 작업이 포함되어 있어 split-brain이 발생했을 때 복구가 유연하게 이루어집니다.
Split-brain : 클러스터로 구성된 시스템 간의 네트워크가 일시적으로 동시에 단절거나 기타 시스템 상의 이유로 클러스터 상의 모든 노드가 자신을Primary로 인식하게 되는 현상
✔️ 높은 확장성
Hazelcast는 여러 시스템의 메모리에 데이터를 분산 저장하는 형태인 IMDG(In Memory Data Grid) 구조를 가지고 있습니다. 내부적으로 TCP 통신을 통해 노드를 자동으로 검색하고, 복제를 통해 데이터의 신뢰성을 보장하여 확장을 유연하게 꾀할 수 있습니다. 또한 해당 구조는 데이터 처리 시 대기 시간이 짧고 처리량 높다는 장점도 있습니다.
✔️ Multi-Thread
대부분 싱글 스레드로 동작하는 Redis와 달리 Hazelcast는 스레드 풀을 사용하여 멀티 스레드로 I/O 작업이 처리됩니다. 요청량이 일정 수준 이상으로 증가했을 때 하젤캐스트의 처리량이 Redis보다 높습니다.
Hazelcast uses a pool of threads for I/O. A single thread does not perform all the I/O. Instead, multiple threads perform the I/O.
🔗 https://docs.hazelcast.com/imdg/4.2/performance/threading-model#io-threading
Single threaded nature of Redis
Redis uses a mostly single threaded design. This means that a single process serves all the client requests, using a technique called multiplexing. This means that Redis can serve a single request in every given moment, so all the requests are served sequentially.
🔗 https://redis.io/docs/management/optimization/latency/#single-threaded-nature-of-redis
✔️ 다른 기능으로의 확장성
하젤캐스트는 분산 락 외에 DistributedMap과 같은 ****여러 분산 자료 구조를 제공합니다. 해당 저장소에서 데이터를 조회할 때 RDB와 유사하게 SQL문을 사용할 수 있고, 트랜잭션도 지원합니다. 이 밖에 배치 및 스트리밍 데이터 작업도 가능합니다.
실제로 이번 구현에서 좌석 선택 정보를 Hazelcast의 분산 Map에 저장하여 관리했습니다.
추후 다른 기능이 필요할 때에도 같은 기술을 고려해볼 수 있다는 것 또한 장점이라 생각했습니다.
분산 락 적용
Flow
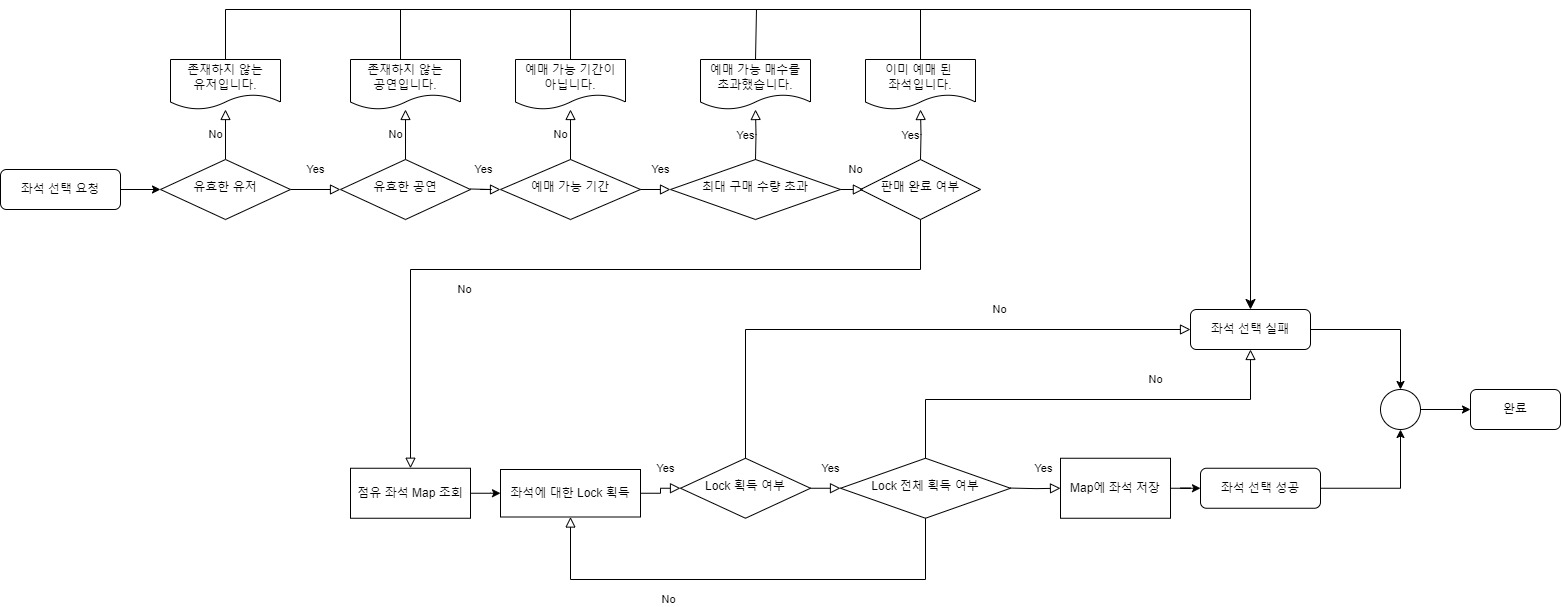
좌석 선택 기능의 전체 플로우이며 아래에서 진행되는 ‘테스트는 점유 좌석 Map 조회 ~ Map에 좌석 저장’ 부분에 대해서만 적용된 것이니 참고 부탁드립니다.
좌석 선택 기능을 구현하면서 Lock 대상, 해제 시점 등을 달리하여 시도했던 방법들을 정리하였습니다.
데이터의 일관성 및 무결성을 보장하면서 빠른 처리를 구현하는 것이 예상보다 더 쉽지 않았습니다. 확실하게 처리하기 위해 좌석이 아닌 상위 데이터에 Lock을 거는 방법도 적용해보았지만 10건 중 2건 정도 밖에 성공하지 못해 처리량이 너무 낮아 선택할 수 없었습니다.(lock 대기 시간 0.1s)
| Lock 대상 | Lock 타입 | Lock 해제 시점 | 이슈 | |
|---|---|---|---|---|
| 좌석 | FencedLock | 선택 좌석 저장 직후 | 동시성 이슈 잔존 | |
| IMap의 Key | 유효 시간 후 자동 해제 | Lock 간의 동시성 이슈 발생 | ||
| 공연 | FencedLock | 선택 좌석 저장 직후 | 낮은 처리율 | |
| 좌석 | FencedLock | 좌석 선택 데이터가 삭제되었을 때 | ✅ 최종 선택 |
Lock과 선택 좌석 데이터는 Hazelcast에서 지원하는 객체를 사용하였습니다.
FencedLock은 자바의 Lock 인터페이스를 구현합니다. 락 요청 시간을 제한할 수 있고, 분산 환경에서 피할 수 없는 Split brain 현상에서도 무결성을 보장해줍니다.
✅ Split brain : 클러스터링 또는 다중 노드 환경에서 일시적인 네트워크의 단절 등의 이유로 두 개 이상의 노드가 자기 자신을 main 노드로 인식하는 상황
IMap은 자바의 ConcurrentMap 인터페이스를 구현하였습니다. Key에 유효 시간과 함께 Lock을 걸 수 있고, 저장한 value에 대해서도 유효 시간을 설정할 수 있습니다.
데이터 저장과 Lock을 한 번에 처리할 수 있어 관리 포인트가 줄고, 제한 시간을 설정할 수 있기 때문에 해제 되지 않아 발생하는 메모리 누수를 막을 수 있습니다.
하지만 IMap은 Hazelcast가 제공하는 AP/CP 구조 중 AP에 속하기 때문에 분산 락 구현에는 적합하지 않다고 판단했습니다. CP FencedLock과 IMap의 Lock을 동시에 사용하는 것도 고려했지만 Hazelcast 서버와의 통신 횟수가 증가하고, Lock 간의 동시성 이슈가 발생할 수 있어 제외하였습니다.
최종적으로는 좌석의 PK에 Lock을 설정하고, 예매를 완료하거나 제한 시간이 만료되었을 때 Lock을 해제하는 것으로 구현하였습니다.
Lock 해제 시점 변경하기 - 최종 선택✅
CP 시스템의 Lock을 그대로 사용하면서 동시 처리 성능도 지킬 수 있는 방법을 고민하다가
IMap에 데이터가 완전히 반영되기 전에 Lock을 해제하는 것이 문제라면, Lock 해제를 더 늦게 하면 되는 거 아닌가?
하는 생각을 했습니다.
FencedLock은 따로 유효 시간을 설정할 수 없기 때문에 해제를 할 수 있는 별도의 트리거가 필요합니다. IMap은 특정 동작(삽입, 삭제, 유효 시간 만료)이 발생할 때 실행할 수 있는 EventListener를 추가할 수 있어 이것을 적용했습니다.
@FunctionalInterface
public interface EntryRemovedListener<K, V> extends MapListener {
void entryRemoved(EntryEvent<K, V> event);
}
@FunctionalInterface
public interface EntryExpiredListener<K, V> extends MapListener {
void entryExpired(EntryEvent<K, V> event);
}좌석 선택 정보가 저장된 IMap의 데이터가 삭제되거나 만료될 때마다 해당 Lock을 unlock 하도록 구현하였습니다.
Hazelcast는 Lock을 해제할 때 Lock을 획득한 Session과 Thread ID을 통해 소유자를 판단합니다. 이벤트를 통해 처리하면 thread가 달라지기 때문에 처음에는 unlock() 대신 thread 확인 없이 생성된 Lock 객체 자체를 클러스터에서 제거하는 destroy()를 호출했습니다.
destroy된 Key로는 FencedLock을 재생성 할 수 없어 unlock()으로 다시 수정하게 되었습니다.
CP Data Structures
If you call thedestroy()method on a CP data structure object, that data structure is terminated in the underlying CP group and cannot be reinitialized until the CP group is force-destroyed. For this reason, please make sure that you are completely done with a CP data structure before destroying it.
그럼 여전히 Lock 소유자가 달라 lock을 해제할 수 없는 문제가 남아있습니다. Hazelcast에서 Lock을 다루는 로직을 살펴보면서 스레드를 다루는 공통 유틸 클래스인 ThreadUtil을 알게 되었습니다.
Hazelcast가 지원하는 트랜잭션 처리, Lock 해제 시 등 스레드에 대한 정보가 필요할 때 내부적으로 해당 클래스를 사용합니다. ThreadUtil은 현재 스레드 아이디를 조회하거나 임의로 설정할 수 있는 메서드를 제공합니다.
IMap에 데이터를 저장할 때 스레드 아이디도 함께 저장한 후, 해제 시에 사용하였습니다.
통합 테스트
요구 사항을 기반으로 Lock에 대한 단위 테스트를 다시 진행했습니다. Hazelcast는 테스트 용 환경을 지원하여 해당 의존성을 추가한 후 세팅해주었습니다.
테스트 항목
- n개이 좌석을 점유할 수 있다.
- 요청된 좌석이 모두 선택되거나 실패한다.(선택한 좌석의 일부만 점유할 수 없다.)
- 중복 요청은 한 번만 반영된다.
- 이미 lock이 걸린 경우 예외가 발생한다.
- 다른 유저가 점유한 좌석인 경우 예외가 발생한다.

앞서 시도했던 방법으로 내내 실패했던 10개의 요청에 대한 테스트도 통과하였습니다. 또한 같은 공연의 다른 좌석에 대한 요청이 지연 없이 처리 되는 것도 확인할 수 있었습니다.
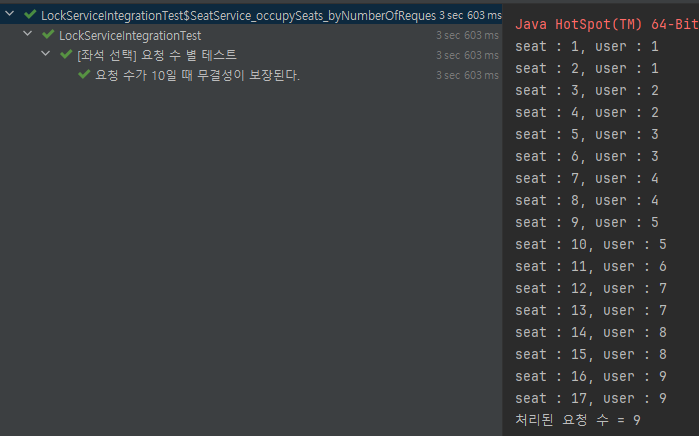
성능 테스트
통합 테스트를 진행하였지만 처리할 수 있는 요청의 규모는 파악할 수 없어 성능 테스트를 진행하였습니다.
환경 세팅
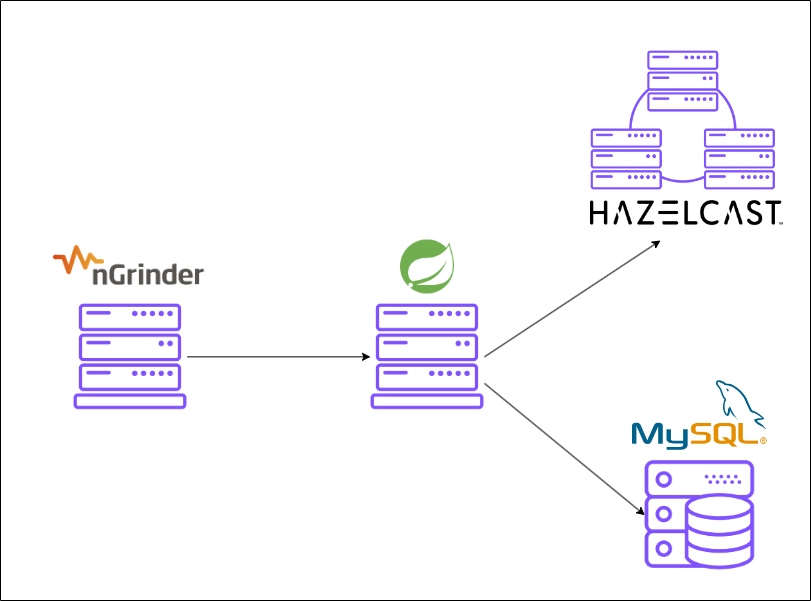
위키를 참고하여 가상 사용자 수를 설정하였고, nGrinder용 서버를 별도로 생성하였고, 최대 요청 수를 10만, 머무는 시간은 1분으로 하여 vUser 수를 1700으로 가정하였습니다.
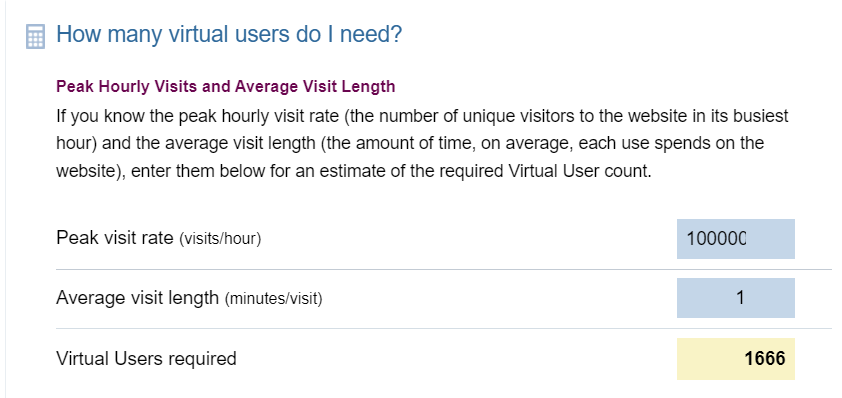
https://www.webperformance.com/library/tutorials/CalculateNumberOfLoadtestUsers/
Hazelcast의 서버 사양을 증설해보면서 테스트하였습니다.
테스트 조건
- 유저 1명 당 3개의 좌석을 선택한다.
- HTTP Status = 200일 때, 요청한 좌석과 점유한 좌석이 일치한다.
- 점유 된 총 좌석 수를 조회한다.
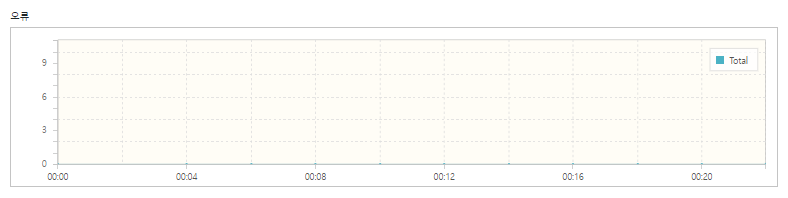
1.2Core, 8GB
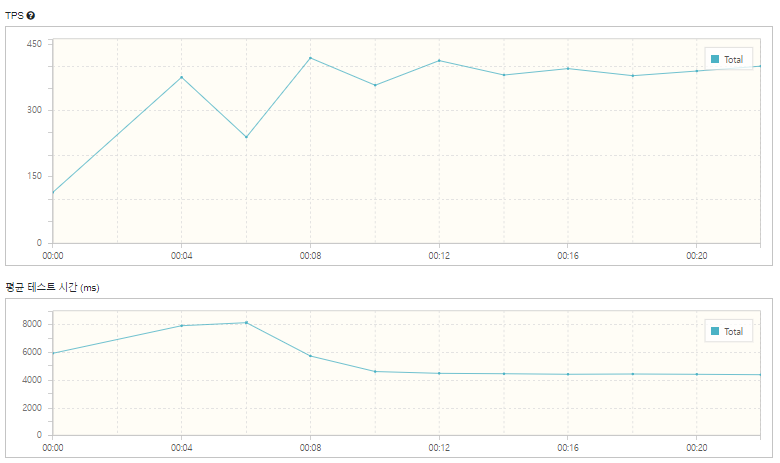
| 총 실행 테스트 수 | 7710 |
|---|---|
| 오류 | 0 |
| 점유 된 좌석 수(occupancy seat/total) | 450/510(약 88%) |
| 최고 TPS | 418 |
| 평균 TPS | 349.9 |
| 평균 테스트 시간 | 5.1s |
2.4Core, 16GB
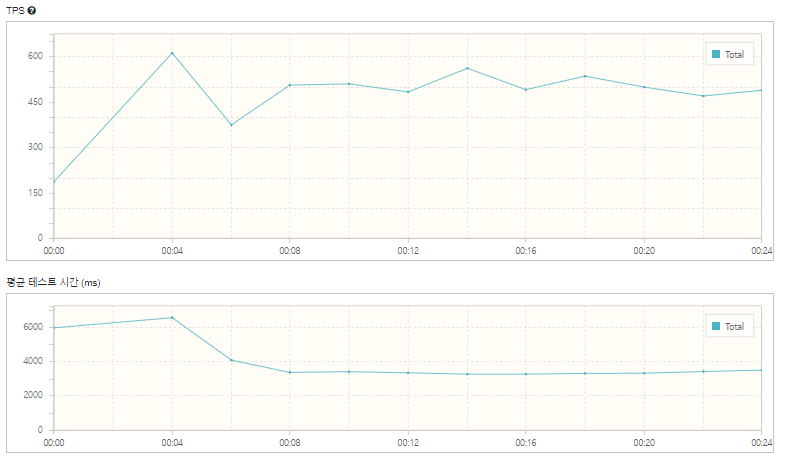
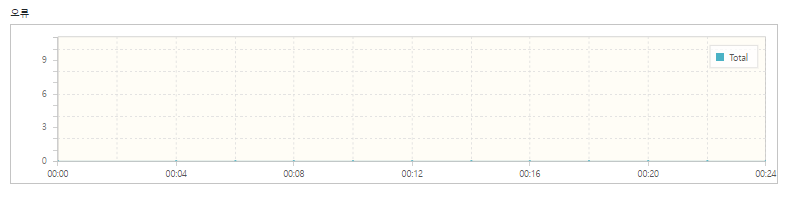
| 총 실행 테스트 수 | 11,428 | |
|---|---|---|
| 오류 | 0 | |
| 점유 된 좌석 수(occupancy seat/total) | 489/510(95.8%) | 약 8% 향상 |
| 최고 TPS | 611.5 | 약 1.46배 향상 |
| 평균 TPS | 475.7 | |
| 평균 테스트 시간 | 3.6s | 약 1.42배 개선 |
기존 대비 점유 좌석 수와 TPS가 모두 향상되었고, 실행 시간도 감소한 것을 확인할 수 있었습니다. 모든 테스트에서 오류가 0건으로 점유한 좌석에 대한 정합성도 보장되는 것을 알 수 있습니다.
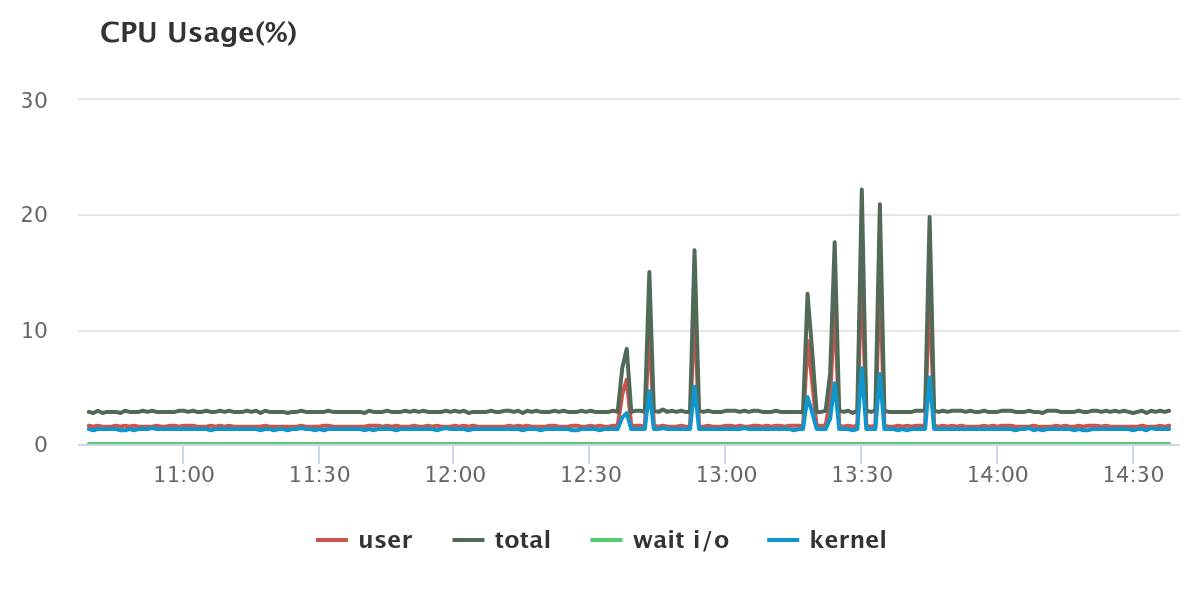
MySQL 서버
- CPU 사용률 ⇒ 25% 미만
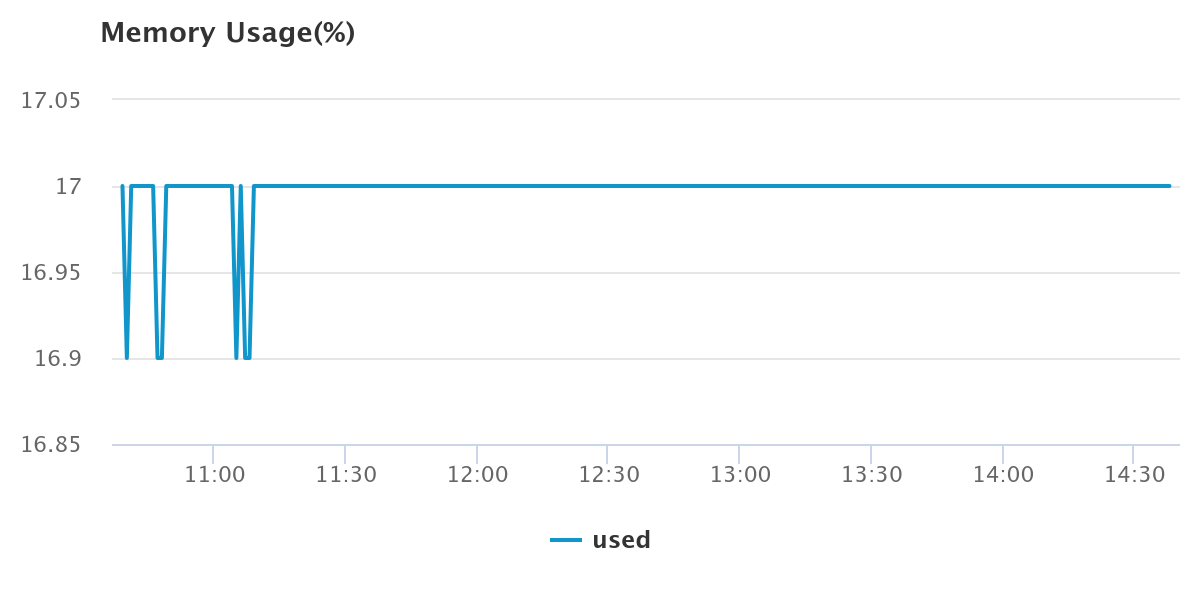
- 메모리 사용률 ⇒ 17% 미만
결론
| 오류(건) | 0 |
|---|---|
| 점유 된 좌석 | 95.8% |
Hazelcast 분산 락을 통해 10만 건의 동시 요청에 대한 선택 좌석의 정합성을 보장 하는 환경을 구현할 수 있었습니다. 또한 전체 좌석에 대한 점유 된 좌석 비율이 95.8%로 실질적인 처리량도 확보하였습니다.
락 데이터 및 점유 좌석 데이터를 Hazelcast에 저장함으로써 CPU 사용률 25% 미만, 메모리 사용률 17% 이하로 데이터베이스에 큰 부하를 주지 않고 요청을 처리할 수 있었습니다.
Hazelcast는 확장에 유연하고 CP(일관성과 분할 내성)를 보장하는 잠금 객체와 AP(가용성과 분할 내성)을 보장하는 자료구조를 모두 지원하기 때문에 대용량 동시 처리 서비스에서 좋은 선택지 중 하나가 될 것 같습니다.
참고
- https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html#innodb-shared-exclusive-locks
- https://dev.mysql.com/doc/refman/8.0/en/locking-functions.html
- https://www.ibm.com/docs/en/rational-clearquest/7.1.0?topic=clearquest-optimistic-pessimistic-record-locking
- https://www.baeldung.com/jpa-optimistic-locking
- https://www.baeldung.com/jpa-pessimistic-locking
- https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/CHAP_Limits.html#RDS_Limits.MaxConnections
- https://novemberde.github.io/post/2018/01/29/Mysql_maxConnection/
- https://sawadeekab.tistory.com/15
- https://d2.naver.com/helloworld/106824
- https://hazelcast.com/blog/hazelcast-responds-to-redis-labs-benchmark/?_gl=1*19hzow5*_up*MQ
- https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
- https://docs.hazelcast.com/hazelcast/latest/
- https://github.com/naver/ngrinder/wiki
