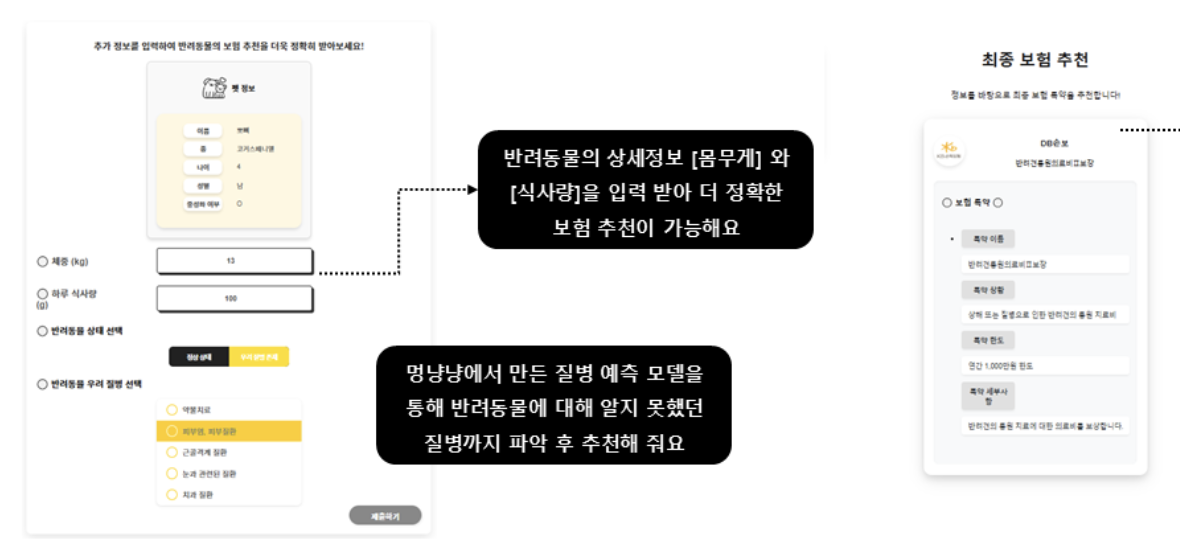
멍냥냥의 보험 추천 서비스는 반려동물의 정보를 입력받아 노출될 위험이 있는 질병을 머신러닝을 통해 예측하고, 그 질병에 대한 보장을 가장 잘 해줄 수 있는 보험 상품과 특약을 추천해줍니다. 병원에 가서 진료를 받지 않고도 반려동물의 건강상태에 대한 정보를 대략적으로 파악하고, 미리 대비할 수 있도록 돕는 것이죠.
RAG 의 도입
예측된 질병을 보장하는 보험 상품을 사용자에게 추천해주기 위해, 처음 떠올린 방법은 Retrieval-Augmented Generation(RAG) 였습니다. LLM 응답을 생성하기 전에 학습 데이터 외부의 지식 베이스를 참조하도록 하는 프로세스죠. RAG는 이미 강력한 LLM의 기능을 특정 도메인이나 조직의 내부 지식 기반으로 확장하므로 모델을 다시 교육할 필요가 없습니다. 보험에 대한 도메인 지식을 공부하고 LLM 훈련을 위한 dataset 구축보다 훨씬 효율적이라고 판단해 RAG 사용을 우선 선택했습니다.

LLM 에게 전달되는 context 는 위 사진과 같은 보험 상품 설명서 PDF 의 내용이었습니다. 예측된 질병이 키워드로 주어지면, 그 질병을 포함하는 특약 이름을 검색(retrieve)하는 방식으로 추천을 진행했습니다.
하지만 이 방법에는 응답 시간이 너무 오래 걸린다는 문제가 있었습니다. 사용자에게 특약의 세부 정보까지 제공해야 하다 보니 context 가 길었고, 추천 요청을 받을 때 마다 긴 context 사이에서 retrieval 을 진행하는 것은 많은 시간이 소요되었습니다.
응답속도 개선?
이를 개선하기 위해 LLM 을 활용해 보험 상품 정보에 대한 DB 를 구축하는 방법을 생각하게 되었습니다. 이 선택이 합리적인 이유는 다음과 같습니다.
- 입력(질병 이름) 이 긴 문장이 아닌 키워드다.
- 보험 상품 정보와 추천 결과는 고정적이다.
- 한 번의 LLM 호출로 DB를 구축하면 리소스 활용 효율이 높아진다.
- 새로운 보험 상품이 추가될 때, 업데이트가 훨씬 용이하다.
PDF parser 개발
우선 PDF 내의 특약 정보를 정리하기 위해 PyPDFLoader 라이브러리를 이용해 PDF parser 를 개발했습니다. 특약 이름들의 list 를 입력 받으면, 문서를 탐색하며 각 특약에 대한 설명은 별도의 document 로 저장하는 객체를 만드는 방식으로 구현했습니다.
# 문서 내 각 특약의 제목에 marker 를 표시 => marker 사이 내용이 특약 정보
# terms: {특약 이름, 페이지} 가 저장된 dict
def extract_terms(self, s3_path, terms):
"""
s3_path 로부터 PDF 파일 다운
"""
extracted_terms = []
for term in terms:
term = term.dict()
term_name = normalize_text(term["term_name"])
page = doc[page_num]
target = page.search_for(term_name)[0] # 처음 만난 특약 이름이 제목인 것으로 간주
page.add_highlight_annot(target)
extracted_terms.append(term_name)
return extracted_terms각 특약 정보를 담은 document 의 정보 (보험사 이름, 특약 이름) 은 metadata 로 저장해 관리했습니다.
요약 모델 개발
각 상품의 특약 정보를 구조화된 형식으로 요약하기 위해 ChatOpenAI 를 이용한 요약 모델을 개발했습니다. 요약 형식은 다음과 같이 정의했습니다.
{
"company": 보험사 이름,
"insurance": 보험 상품 이름,
# 특약 정보 리스트
"special_terms": [
{
"name": 특약 이름,
"summary": {
"causes": 보장되는 상황,
"limits": 보장 한도,
"details": 특약 내용 한줄 요약
},
"illness": [보장하는 질병들]
}
]
}위와 같은 형식으로 요약하기 위해 코드로 JSON format 을 정의하고, prompt 에 구조를 전달했습니다. 이제 고려할 점이 두 가지가 생겼습니다.
- LLM 이 정보를 일관되게 요약할 수 있는가?
- 모든 특약에 대해 위 항목에 대한 내용을 작성할 수 있는가?
위 고민들은 model 의 창의성을 조절하는 temperature 와 관련이 있습니다. temperature 이 낮으면 있는 그대로의 내용을 사용하려는 경향이 높아지기 때문에 정보를 일관되게 요약할 수 있는 반면, 상대적으로 부족한 정보는 잘 요약하지 못하는 trade-off 가 있습니다. 이를 실험하기 위해 추출 요약 task 에서 사용되는 temperature 범위를 조사하고, 범위 내에서 temperature 를 조절하며 모델의 출력을 관찰했습니다. 그 결과, temperature 를 0.3 으로 설정했을 때 일관성과 적절한 창의성을 모두 챙길 수 있었습니다.
DB 구축
위와 같이 구조화된 형식으로 특약 정보가 요약이 가능했기 때문에, JSON 을 그대로 저장하는 NoSQL 보다는 RDB 를 사용하는 것으로 결정했습니다. 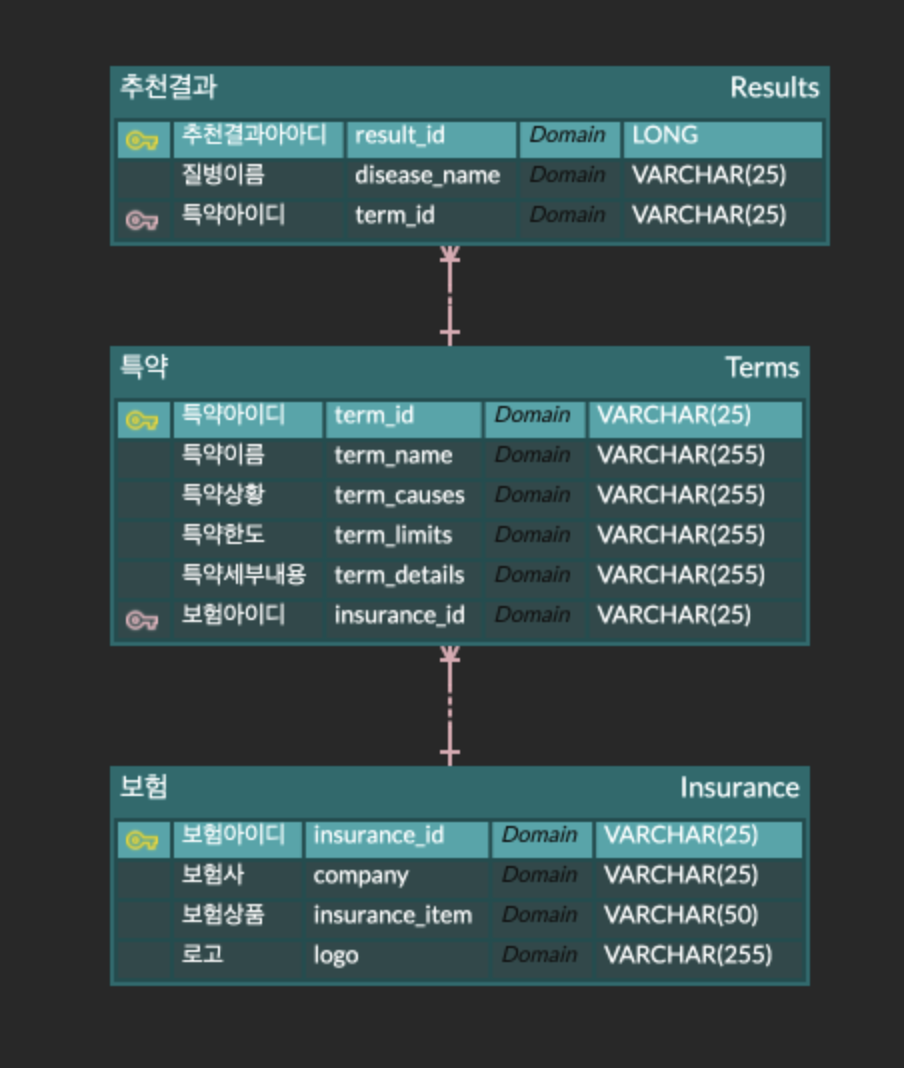
위와 같이 ERD를 설계한 후, 각 테이블에 알맞은 정보를 삽입하기 위해 JSON을 입력받아 SQL로 변환하는 함수를 작성했습니다.
def generate_term_query(data):
insurance_id = data.get("company")
term_list = data.get("special_terms")
query_list = []
for i, term in enumerate(term_list):
term_id = f"{insurance_id}_term_{i}"
term_name = term.get("name")
summary = term.get("summary")
term_causes = summary.get("causes")
term_limits = summary.get("limits")
term_details = summary.get("details")
query_list.append(
f"""INSERT INTO Terms (term_id, insurance_id, term_name, term_causes, term_limits, term_details)
VALUES("{term_id}", "{insurance_id}", "{term_name}", "{term_causes}", "{term_limits}", "{term_details}")
ON DUPLICATE KEY UPDATE
term_name = VALUES(term_name),
term_causes = VALUES(term_causes),
term_limits = VALUES(term_limits),
term_details = VALUES(term_details);"""
)
return query_list그리고 이 함수에서 반환된 query 들은 mysql_connector 를 이용해 DB 에 접근한 후 실행됩니다.
def execute_queries(queries):
connection = mysql_connection()
try:
with connection.cursor() as cursor:
for query in queries:
cursor.execute(query)
connection.commit()
except Exception as e:
connection.rollback()
print(f"Error executing queries: {e}")
finally:
connection.close()이제 추천 요청 시마다 LLM 을 호출할 필요가 없어졌습니다. 한 번의 LLM 호출로 DB 를 구축해 리소스 사용 효율을 증대시키고, 응답 시간도 1초 이내로 크게 단축할 수 있게 되었습니다.
DB 구축 프로세스 자동화
Production 환경에서 새로운 보험 상품 정보가 수집되는 경우를 대비해, DB 구축 프로세스를 자동화 할 필요성을 느꼈습니다. 이는 FastAPI 를 이용해 위 프로세스를 RestAPI 형태로 만들고, 관리자 페이지에서 호출되도록 구현했습니다.
@app.post("/insurance/admin")
async def save_summary(request: InfoRequest):
try:
terms = request.terms
file_path = request.file_path
if not terms or not isinstance(terms, list):
raise HTTPException(status_code=400, detail="Invalid terms provided")
if not file_path or not isinstance(file_path, str):
raise HTTPException(status_code=400, detail="Invalid file_path provided")
loader = Loader(file_path, terms)
company = extract_company_name(file_path)
save_summaries(loader, company)
insert_insurances(company)
insert_terms(company)
insert_results(company)
return "Summary Pipeline Successful!"
except Exception as e:
print(f"Error: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))이제 관리자 페이지에서 보험 상품 정보 PDF 를 업로드하면 DB 에 Update 가 자동으로 이루어집니다.
향후 계획
DB 구축은 정해진 입력과 출력 내에서는 RAG 보다 월등히 빠르고 효율적이라는 장점이 있었습니다. 하지만, 사용자 입력이 자연어 문장으로 다채로워진다면, RAG 의 사용이 불가피할 것으로 생각됩니다. 이전처럼 정해진 정보를 입력하는 것에서 발전해 반려동물의 증상을 자연어로 설명하는 등 다채로운 사용자 경험을 위해 RAG 를 사용하는 서비스도 개발하고 싶습니다. 이때 응답 품질과 속도 개선을 위해 RAG 고급 기법들과 caching 등의 아키텍처를 도입하고자 합니다.
