XGBoost를 가지고 위스콘신 유방암 데이터를 분석해보자.
모듈
import xgboost as xgb
from xgboost import plot_importance
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')데이터 불러오기
dataset = load_breast_cancer()
x_features = dataset.data
y_label = dataset.target
df = pd.DataFrame(data=x_features, columns=dataset.feature_names)
df['target'] = y_label
df.head()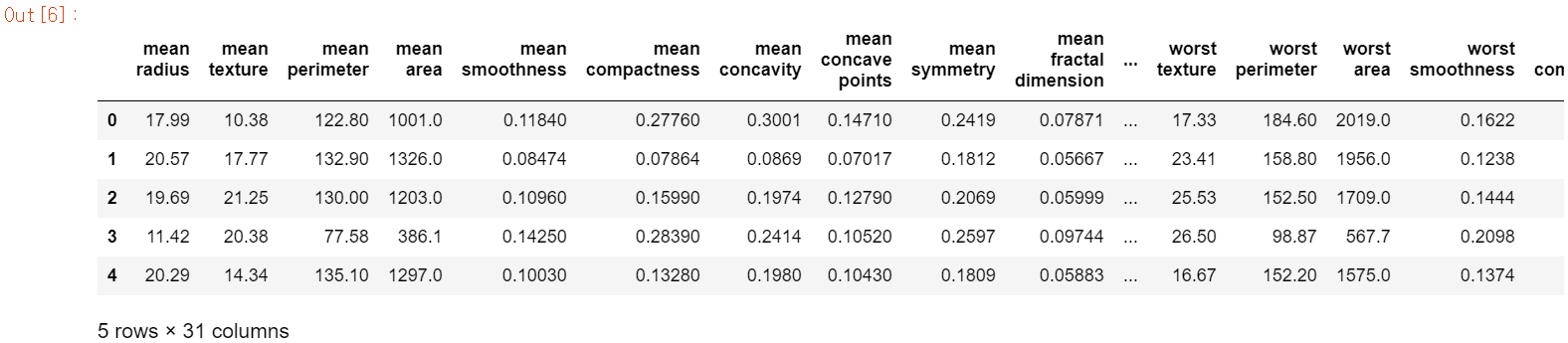
print(dataset.target_names)
print(df['target'].value_counts())['malignant' 'benign']
1 357
0 212
Name: target, dtype: int64
데이터 분리
x_train, x_test, y_train, y_test = train_test_split(x_features, y_label, test_size=0.2, random_state=156)
print(x_train.shape, x_test.shape)(455, 30) (114, 30)
DMatrix
파이썬 래퍼 XGBoost는 train, test 데이터 세트를 위해 별도의 객체인 DMatrix를 생성해야 한다.
DMatrix는 넘파이 ndarray, DataFrame.values, libsvm txt 포멧 파일, xgboost 이진 버퍼 파일을 파라미터로 입력 받는다.
dtrain = xgb.DMatrix(data=x_train, label=y_train)
dtest = xgb.DMatrix(data=x_test, label=y_test)XGBoost 모델 생성
우선 XGBoost를 실행하기 위해 하이퍼 파라미터를 지정해줘야 한다.
params = {
'max_depth' : 3,
'eta' : 0.1,
'objective' : 'binary:logistic',
'eval_metric' : 'logloss',
'early_stoppings' : 100
}
num_rounds=400XGBoost에서 early_stoppings을 설정할 땐 반드시 eval_set과 eval_metric이 함께 설정되어야 한다. XGBoost는 반복마다 eval_set으로 지정된 데이터 세트에서 eval_metric이 지정된 평가 지표로 얘축 오류를 측정.
- eval_set : 성능 평가를 수행할 평가용 데이터 세트
- eval_metric : 평가 세트에 적용할 성능 평가 방법. 분류일 경우 주로 'error;, 'logloss'를 사용
# train 데이터 세트는 'train', eval 데이터 세트는 'eval'로 명시
wlist = [(dtrain, 'train'), (dtest, 'eval')]
xgb_model = xgb.train(params=params, dtrain=dtrain, num_boost_round=num_rounds,\
early_stopping_rounds=100, evals=wlist)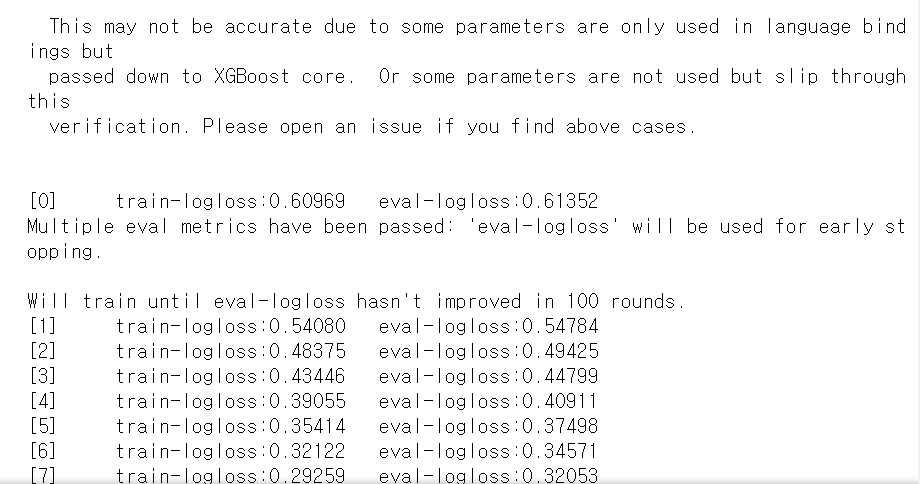

모델링 결과값을 보면 train_logloss와 eval_logloss가 둘다 줄어들었다. 또한 311번째 학습에서 조기 종료가 된 것을 확인할 수 있다.
pred_probs = xgb_model.predict(dtest)
print('predict() 수행 결과값 10개 표시, 예측 확률값로 표시된다.')
print(np.round(pred_probs[:10], 3))predict() 수행 결과값 10개 표시, 예측 확률값로 표시된다.
[0.934 0.003 0.91 0.094 0.993 1. 1. 0.999 0.997 0. ]
XGBoost의 예측 결과는 값이 아니라 예측 확률값으로 표시된다.
따라서 확률이 0.5보다 크면 1, 아니면 0으로 예측 값을 결정해야 한다.
pred = [ 1 if x > 0.5 else 0 for x in pred_probs]
print('예측값 10개 표시 : \n', pred[:10])예측값 10개 표시 :
[1, 0, 1, 0, 1, 1, 1, 1, 1, 0]
예측 평가
from sklearn.metrics import roc_auc_score
from sklearn.metrics import f1_score
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
# 3장 내용
def get_clf_eval(y_test, pred, pred_probs):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
# ROC-AUC
roc_auc = roc_auc_score(y_test, pred_probs)
print('오차 행렬')
print(confusion)
# ROc-AUC
print('정확도 : {:.4f}, 정밀도 : {:.4f}, 재현율 : {:.4f},\
F1 : {:.4f}, AUC : {:.4f}'.format(accuracy,precision,recall,f1,roc_auc))
get_clf_eval(y_test, pred, pred_probs)오차 행렬
[[35 2][ 1 76]]
정확도 : 0.9737, 정밀도 : 0.9744, 재현율 : 0.9870, F1 : 0.9806, AUC : 0.9951
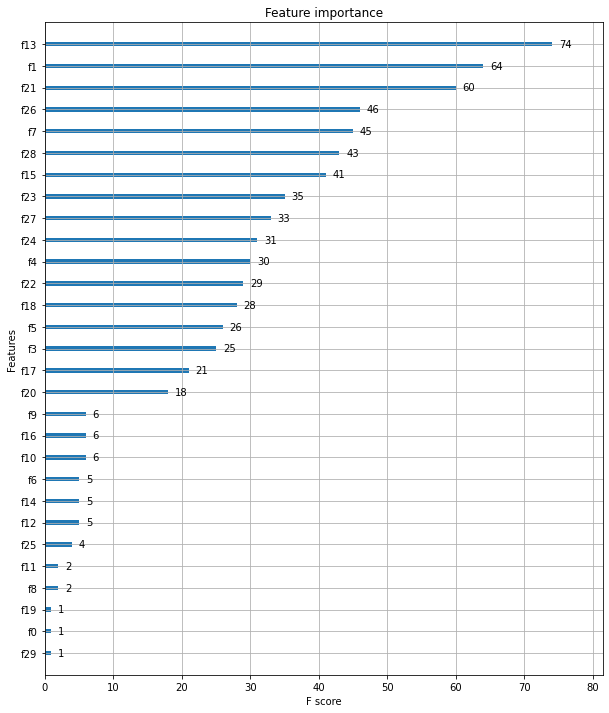
plot_importance
사이킷런에서 featureimportances처럼 XGBoost는 plot_importance로 변수의 중요도를 시각화할 수 있다. 기본 평가 지표로 f1 score를 사용한다.
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)