🚀부스팅(Boosting)
부스팅은 여러개의 분류기가 순차적으로 학습하는데, 이전에 학습한 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있게 다음 분류기에게 가중치를 부여하면서 학습과 예측을 진행한다.
부스팅의 대표적인 알고리즘은
- AdaBoost
- Gradient Boost
가 있다.
AdaBoost
AdaBoost에 대해 그림으로 메커니즘을 공부해보자.
데이터 세트가 다음과 같이 분포해있다고 하자.
.jpg)
-
Step 1
첫번째 약한 학습기가 분류 기준 1로+와-를 분류한다.
.jpg)
-
Step 2
첫번째 단계에서 오분류된+에 가중치를 더한다. 가중치가 덜해진+데이터는 다음 약한 학습기가 더 잘 분류되게 크기가 커진다.(가중치 = 0.3)
.jpg)
-
Step 3
두번째 약한 학습기로 분류한다.
.jpg)
-
Step 4
2단계에서 처럼 오분류된-데이터에 가중치를 부여한다.(가중치 = 0.5)
.jpg)
-
Step 5
세번째 약한 학습기가 분류 기준 3으로 분류한다. AdaBoost는 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행한다.(가중치 = 0.8)
.jpg)
-
Final Step
마지막으로 첫번째, 두번째, 세번째 약한 학습기를 결합하여 결과를 예측한다. 개별 약한 학습기보다 정확도가 더 높아졌다.
.jpg)
Gradient Boost
GBM도 AdaBoost 와 유사하다. 차이점이 있다면 가중치 업데이트를 경사 하강법(Gradient Desecnt)을 이용한다는 점이다. 이는 반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법이다. GBM은 bisa는 줄일 수 있어도 과적합이 일어날 수 있다. 따라서 sampling, penalizing 등의 regularization 테크닉을 이용하여 더 advanced 된 모델을 이용하는 것이 일반적이다.
경사 하강법?
분류의 실제 결과값 :
feature :
feature에 기반한 예측 함수 :
오류식 :
GBM은 CART기반의 다른 알고리즘처럼 분류와 회귀 다 가능하다.
사이킷런에서 GBM기반 Classifier이 사용 가능하다.
from sklearn.ensemble import GradientBoostingClassifier
import time
import warnings
warnings.filterwarnings('ignore')
# GBM 수행 시간 측정
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(x_train, y_train)
gb_pred = gb_clf.predict(x_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도 : {:.4f}'.format(gb_accuracy))
print('GBM 수행 시간 : {:.1f}초'.format(time.time() - start_time))GBM 정확도 : 0.9393
GBM 수행 시간 : 526.2초
(왜 책에서 시간 측정을 했는지 이제야 알겠다...)
GBM은 일반적으로 랜덤 포레스트보다 예측 성능이 조금 뛰어난 경우가 많다. 근데 시간이.. 너무 오래걸린다.(참고로 필자 노트북 M1 Ram 16Gb)
GBM은 멀티 CPU 코어 시스템을 사용하더라도 병렬 처리가 지원되지 않는다. 따라서 대용량 데이터의 경우 학습에 많은 시간이 필요하다.
하이퍼 파라미터
GBM도 트리 기반 자체의 파라미터를 포함한다.
- loss : 경사 하강법에서 사용할 비용 함수를 지정. 특별 이유가 없으면 default값인
deviance를 사용. - learning_rate : GBM이 학습을 진행할 때마다 적용하는 학습률. 약한 학습기가 순차적으로 오류값을 보정해 나가는데 적용하는 계수. default값은 0.1이고 0 ~ 1 사이의 값을 가진다.
작은 값을 적용 시 업데이트되는 값이 작아져서 최소 오류 값을 찾아 예측성능은 높아진다. 하지만 너무 오래걸린다. 또한 모든 약한 학습기의 반복이 끝나도 최소 오류값을 찾지 못할 수도 있다. 반대로 크다면 최소 오류 값을 찾지 못하고 그냥 지나쳐 예측 성능이 떨어질 가능성이 높지만, 빨라진다.
이러한 특성으로 인해 learning rate는 n_estimators와 상호 보완적으로 조합한다. learning rate를 작게, n_estimators를 크게 하면 더이상 성능이 좋아지지 않는 한계점까지는 예측 성능이 조금씩 좋아질 수 있다. 하지만 너무 오래걸리며 예측 성능도 현격히 좋아지지는 않는다.(비효율적) - n_estimators : week learner의 개수. week learner가 순차적으로 오류를 보정하므로 개수가 많아질수록 예측 성능이 일정 수준까지는 좋아질 수 있다. 하지만 너무 오래걸린다. default값은 100.
- subsample : week learner이 학습에 사용하는 데이터 샘플링 비율. default는 1이고 이는 전체 데이터를 학습. 과적합이 염려되는 경우 subsample을 1보다 작게 설정
learning rate(학습률) - 추가 학습
이 사이트 참고
learning rate 는 각 결정트리에 대해서 다음 결정 트리로 넘어갈 때 오류가 얼마나 빠르게 수정되는지에 대한 하이퍼 파라미터이다.
만약 어떤 결정 트리에 대해서 현재의 예측이 0.2라고 하고 다음 트리의 예측이 0.8이라고 할 때
수정은 +0.6이다. 이 때 learning rate가 1이라면 updated 예측은 0.2 + 0.6(1) = 0.8이고, learning rate가 0.1이라면 0.2 + 0.06(0.1) = 0.26이 수정된 예측값이 된다.
왠만한 파라미터들 중 learning rate와 트리 수만 적절하게 조합한다면 큰 영향을 미칠 수 있다.하지만 우선적으로는 max_depth를 얕게(2~5)하고 subsampling을 80~90%로 설정한다면 경험상 꽤 효과적이라고 한다. learning rate와 트리 수는 이 다음 문제다.
learning rate(L)와 트리 수(t)는 반비례적인 관계가 있다. 만약 L이 L/n만큼 줄어든다면 t는 nt만큼 커진다. 이때 GBM의 학습시간은 트리 수에 비례하므로 트리 수가 커질수록 속도도 어마어마해진다.(500초 넘긴건 너무하잖아유 ㅠㅠㅠ) 그럼 왜 learning rate를 낮출까?
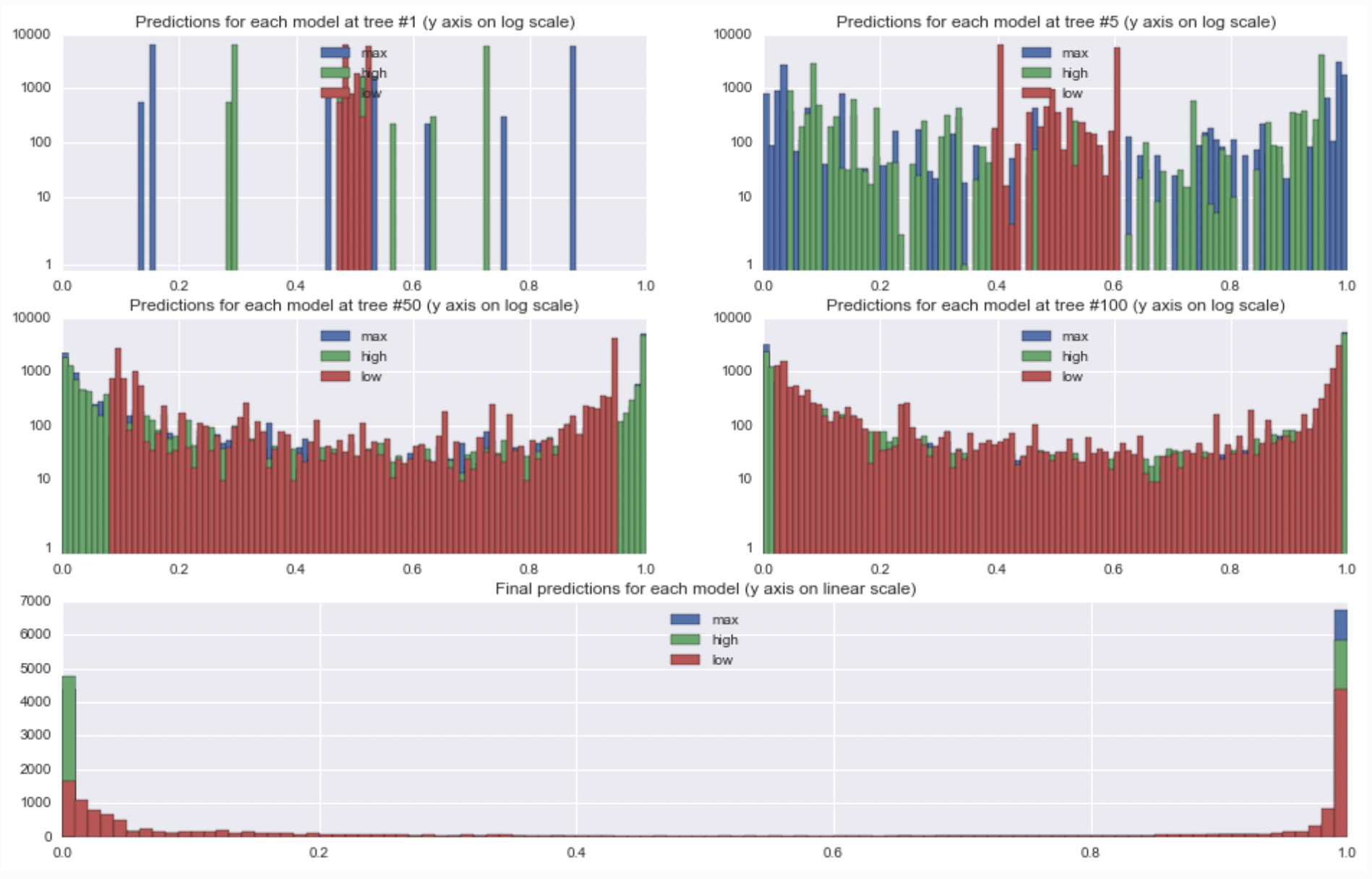
(이부분은 솔직히 이해가 잘 안됬다. 과적합 얘기같기도 하고..)
위 그림은 하이퍼 파라미터를 다음과 같이 조정한 모델이다.
- n_estimators = 500
- max_depth = 3
- subsample = 0.9 (개별 약한 학습기가 전체 데이터중 90%의 데이터를 가지고 학습함)
- learning rate = (low : 0.05), (high : 0.5), (max : 1)
각 그래프가 의밀하는 내용은 title을 보면 된다. 각각 18000개의 데이터를 트리 수(1, 5, 50, 100, 500)개일때의 예측을 히스토그램으로 표현한 도표이다.
트리 수 1개 도표를 보면 모든 예측값이 대략 0.5로부터 시작된다. 그리고 이 이후의 트리수를 보면 각각의 예측이 0,5 - LR, 0.5 + LR로 퍼지게 된다.max_depth가 작아 예측이 0이나 1로 끝나지는 않는다.
위 도표에서 한가지 흥미로운 점은 트리 1에서 각 모델의 기본적인 트리 모델이 동일하다는 것이다. learning rate 0.5와 1의 모양을 보면 간격은 다르지만 모양이 동일한 것을 볼 수 있다.
트리 수가 점점 많아지면 높은 learning rate의 대부분 예측이 0과 1에 도달했다. 이에 반해서 낮은 learning rate는 쉬운 예제만 0과 1에 도달하기 시작한다. 최종 모델에서 learning rate가 낮은 모델이 약간 다른 모델보다 보수적(?)이긴 하지만 모든 모델에서 상대적으로 확실하다고 느끼는 포인트가 있다.(가 무슨 소리인지 모르겠다.)
이 블로그에서 살펴보니 과적합에 대한 내용이 맞다. 만약 learning rate가 높다면 빠르게 예측값이 1에 도달하지만 이는 새로운 데이터에 대해서 예측이 잘 안될 것이다.
기존 오차값이 15이고 예측값이 73이라 가정하자. 학습률이 1이면 다음 예측값은 88이다. 위에서 말했듯이 이는 과적합 문제가 일어날 가능성이 다분하다. 대신 학습률이 0.1이라면? 73 + 1.5 = 74.5이다. 88보다는 낮지만 오차도 줄고(88 - 74.5 = 13.5) 과적합도 일어날 가능성이 낮아진다.
XGBoost
요새 Kaggle에서 상위권을 차지하는 많은 알고리즘이 바로 XGBosst이다. 이 알고리즘은 GBM에 기반하지만, GBM의 큰 단점인 느린 수행 시간과 과적합 규제 부재 등의 문제를 해결했다. 병렬 CPU 환경에서 병렬 학습이 가능하여 기존 GBM보다 빠르다.
또한 나무 가지치기라는 기능이 있다. GBM은 분할 시 부정 손실이 발생하면 분할을 더이상 수행하지 않지만, 이러한 방식도 자칫 지나치게 많은 분할을 발생할 수 있다. XGBoost는 max_depth으로 분할 깊이를 조정하기도 하지만, tree pruning으로 더 이상 긍정 이득이 없는 분할을 가지치기해서 분할 수를 더 줄이는 추가적인 장점이 있다.
마지막으로 XGBoost는 자체 내장된 교차검증과 결손값을 자체 처리한다. 교차 검증은 지정된 반복 횟수가 아니고 교차 검증을 통해 평가 데이터 세트의 평가 값이 최적화 되면 반복을 중간에 멈출 수 있는 조기 중단 기능이 있다.
하이퍼 파라미터
파이썬 래퍼 XGBoost와 사이킷런 래퍼 XGBoost 모듈의 일부 하이퍼 파라미터는 약간 달라 주의가 필요하다. 기능은 동일하지만 사이킷런 파라미터의 범용화된 이름 규칙때문에 이름이 달라진다.
파이썬 래퍼 XGBoost
XGBoost 파라미터에는 3가지 유형이 있다.
일반 파라미터: default에서 거의 바꾸지 않는 파라미터. 실행 시 스레드 개수나 silent 모드 등의 선택을 위한 파라미터.부스터 파라미터: 트리 최적화, 부스팅, regularization 등과 관련된 파라미터.학습 태스크 파라미터: 학습 수행 시의 객체 함수, 평가를 위한 지표 등을 설정
일반 파라미터
booster: gbtree 또는 gblinear 선택. default는 gbtree.silent: default는 0. 출력 메세지를 나타내고 싶지 않으면 1.nthread: CPU의 실행 스레드 개수를 조정, default는 전체 스레드를 사용. 멀티 코어/스레드 CPU 시스템에서 전체 CPU를 사용하지 않고 일부 CPU만 사용해 ML 애플리게이션을 구동하는 경우 변경.
부스터 파라미터
-
eta(default = 0.3, alias : learning rate)
GBM의 learning rate같은 파라미터. 0 ~ 1의 값을 가지며 부스팅 스탭을 반복적으로 수행할 때 업데이트 되는 학습률 값. 사이킷런 래퍼 기반일 경우 eta는 learning rate로 대체, default는 0.1이다. 보통0.01 ~ 0.2의 값을 선호. -
num_boost_rounds
GBM의 n_estimators와 같다. -
min_child_weight(default = 1)
트리에서 추가적으로 가지를 나눌지 결정하기 위해 필요한 데이터들의 weight 총합. 값이 클수록 분할을 자제한다. 과적합 조절하기 위해 사용. -
gamma(default=0, alias : min_split_loss)
트리의 리프 노드를 추가적으로 나눌지를 결정할 최소 손실 감소 값. 해당 값보다 크 손실이 감소된 경우에 리프 노드를 분리. 클수록 과적합 감소 효과가 있다. -
max_depth(default=6)
트리 기반 모델의 max_depth와 같다. 0으로 지정하면 깊이에 제한이 없다. 값이 높으면 특정 피치 조건에 특화되어 룰 조건이 만들어지므로 과적합 가능성 상승. 보통 3~10의 값 사용. -
colsample_bytree(default=1)
GBM의 max_feature와 유사하다. 트리 생성에 필요한 feature를 임의로 샘플링하는데 사용. 매우 많은 feature가 있는 경우 과적합 조정하는데 적용. -
sub_sample(default=1)
GBM의 subsample와 동일하다. 일반적으로 0.5 ~ 1사이의 값 사용. -
lambda(default = 1, alias : reg_lambda)
L2 Regularization 적용 값. feature 개수가 많을 경우 적용을 검토. 값이 클수록 과적합 감소 효과. -
alpha(default = 0, alias : reg_alpha)
L1 Regularization 적용 값. feature 개수가 많을 경우 적용을 검토. 값이 클수록 과적합 감소 효과. -
scale_pos_weight(default = 1)
특정 값으로 치우친 비대칭한 클래스로 구성된 데이터 세트의 균형을 유지하기 위한 파라미터.
학습 태스크 파라미터
-
objective
최솟값을 가져야할 손실 함수 정의. 주로 사용되는 손실함수는 이진 분류인지 다중 분류인지에 따라 달라진다. -
binary:logistic
이진 분류일 때 적용 -
multi:softmax
다중 분류일 때 적용. 손실 함수가multi:softmax일 경우에는 레이블 클래스의 개수인 num_class 파라미터를 지정해야 한다. -
multi:softprob
multi:softmax와 유사하나 개별 레이블 클래스의 해당되는 예측 확률을 반환. -
eval_metric
검증에 사용되는 함수를 정의. default는 회귀인 경우엔 mse, 분류일 경우엔 error이다.
1.rmse: Root Mean Square Error
2.mae: Mean Absolute Error
3.loglosss: Negative log-likelihood
4.error: Binary classification error rate (0.5 threshold)
5.merror: Multiclass classification error rate
6.mlogloss: Multiclass logloss
7.auc: Area under the curve
과적합 문제시 하이퍼 파라미터 적용
- eta값을 낮춘다.(0.01 ~ 0.1). eta값을 낮출 경우 num_round(n_estimators)는 반대로 높여야 한다.
- max_depth 값을 낮춘다.
- min_child_weight 값을 높인다.
- gamma 값을 높인다.
- subsample과 colsamlpe_bytree를 조정하는 것도 트리가 복잡하게 생성되는 것을 막아 과적합에 도움이 된다.
그 외 기능
XGBoost는 교차 검증, 성능 평가, 피처 중요도 등의 시각화 기능을 갖고 있다. 또한 수행 속도를 향상시키는 대표적인 기능인 조기 중단이 있다. GBM과 달리 XGBoost와 LightGBM은 모두 조기 중단 기능이 있어 n_estimators에 지정한 부스팅 반복 횟수에 도달하지 않아도 예측 오류가 더 이상 개선되지 않으면 중간에 중지한다.
cv()
XGBoost는 사이킷런의 GridSearchCV처럼 교차 검정 후 최적 파라미터를 구할 수 있는 방법을 cv() API로 구현했다.
xgboost.cv(params, dtrain, num_boost_round=10,
nfold=3, stratified=false, folds=None, metrics=(),
obj=None, feval=None, maximize=False,
early_stopping_rounds=None, fpreproc=None,
as_pandas=True, verbose_eval=None, show_stdv=True,
seed=0, callbacks=None, shuffle=True)- params (dict) : 부스터 파라미터
- dtrain (DMatrix) : 학습 데이터
- num_boost_round (int) : 부스팅 반복 횟수
- nfold (int) : CV 폴드 개수
- stratified (bool) :CV 수행 시 층화 표본 추출 수행 여부
- metrics (string or list of strings) : CV 수행 시 모니터링할 성능 평가 지표
- early_stopping_rounds (int) : 조기 중단을 활성화 시킴. 반복 횟수 지정
cv()의 반환값은 DataFrame 형태이다.
LightGBM
-
LightGBM은 XGBoost보다 학습에 걸리는 시간이 훨씬 적고(XGBoost는 Gradient보다 빠른데...), 메모리 사용량도 상대적으로 적다. 왜 Light란 별칭이 붙여진지 알것 같다. -
Light라는 이름때문에 가벼워보일 수 있지만(예측 성능이 상대적으로 떨어진다던가??) 아니다!!
LightGBM과 XGBoost의 예측 성능엔 별다른 차이가 없다. 오히려 기능상 다양성은 오히려 LightGBM이 약간 더 많다. -
LightGBM의 단점은 적은 데이터 세트에 적용할 경우 과적합이 발생하 기 쉽다라는 것이다. 적은 데이터란 상대적인 값이지만 일반적으로 10000건 일하의 데이터 세트라고 생각하면 된다.
-
카테고리형 feature의 자동 변환과 최적 분할을 한다. (원-핫 인코딩 등을 사용하지 않고도 카테고리형 feature를 최적으로 변환하고 이에 따른 노드 분할 수행한다.)
-
XGBoost와 마찬가지로 대용량 데이터에 대한 뛰어난 예측 성능 및
병렬 컴퓨팅 기능을 제공하며, 최근에는 추가로GPU까지 제공 -
LightGBM은 일반 GBM과 다르게 리프 중심 트리 분할(Leaf Wise)방식을 사용한다. 기존 대부분 트리 기반 알고리즘은 트리의 깊이를 효과적으로 줄이기 위해 균형 중심 트리 분할(Level Wise) 방식을 사용한다.
.jpg)
.jpg)
-
균형 트리 분할 (Level Wise)
1) 균형 트리 분할은 최대한 균형 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화될 수 있다.
2) 균형 잡힌 모델은오버피팅에 보다 더 강한 구조를 가질 수 있다고 알려져 있다.
3) 균형을 맞추기 위해 시간이 오래 걸린다. -
리프 중심 트리 분할 (Leaf Wise)
1) 트리의 균형을 맞추지 않고,최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 규칙 트리가 생성된다.
2) 최대 손실 값을 가진 리프 노드를 지속적으로 분할해 생성된 규칙 트리는 학습을 반복할수록 결국은 균형 트리 분할 방식보다예측 오류 손실을 최소화 할 수 있다.
3) 이 방식은 데이터 개수가 적을 때 오버피팅을 일으키기 때문에, LightGBM은 트리의 깊이를 제한하기 위해max_depth파라미터를 가지고 있다. 그런데 이 파라미터를 명시해도 트리가 지속적으로 자란다...??
하이퍼 파라미터
LightGBM의 하이퍼 파라미터는 XGBoost와 유사하다. 하지만 LightGBM은 XGBoost와 달리 리프 노드가 계속 분할되면서 트리의 깊이가 깊어지므로 이런 트리 특성에 맞는 하이퍼 파라미터 설정이 필요하다.(예로 max_deoth를 매우 크게 가짐)
주요 파라미터
-
num_iterations (default=100) ==
n_estimaotrs(사이킷런 래퍼)
반복 수행하려는 트리의 개수 지정. 크게 지정하면 예측 성능 높아질 수 있으나, 너무 높으면 과적합 가능성 있다. -
learning_rate (default=0.1)
부스팅 스탭을 반복적으로 수행할 때 업데이트 되는 학습률. 일반적으로 n_estimators를 크게, learning_rate를 작게하여 성능 높일 수 있으나, 과적합과 시간이 오래걸리는 단점도 존재. -
max_depth (default=-1)
-
min_data_in_leaf (default=20) ==
min_child_samples
결정 트리의 min_samples_leaf와 같다. -
num_leaves (default=31)
하나의 트리가 가질 수 있는 최대 리프 개수 -
boosting (default=gbdt)
1) gbdt : 일반적인 그래디언트 부스팅 결정 트리
2) rf : 랜덤 포레스트 -
bagging_fraction (default=1.0) ==
subsample
트리가 커서 과적합되는 것을 제어하기 위해 데이터를 샘플링하는 비율. -
feature_fraction (default=1.0) ==
colsample_bytree
개별 트리를 학습할 때마다 무작위로 선택하는 feature 비율. -
lambda_l2 (default=0.0) ==
reg_lambda
L2 regulation 제어를 위한 값. feature 수가 많을 경우 적용을 검토 -
lambda_l1 (default=0.0) ==
reg_alpha
L1 regulation 제어를 위한 값
Learnging Task 파라미터
- objective : 최솟값을 가져야 할 손실함수 정의. XGBoost와 동일하다.
하이퍼 파라미터 튜닝
일반적으로는 learning_rate를 작게, n_estimators를 크게하는 것이 보통이다.
-
num_leaves는 개별 트리가 가질 수 있는 최대 리프의 개수이고 LightGBM 모델의 복잡도를 제어한다. 일반적으로 개수를 높이면 정확도가 높아지나, 트리가 깊어지고 복잡도가 커져 과적합 영향도가 커진다. -
min_data_in_leaf는 과적합을 개선하기 위한 중요 파라미터이다. num_leaves와 학습 데이터 크기에 달라지나, 보통 큰값으로 설정하면 트리가 깊어지는 것 방지 -
max_depth는 num_leaves, min_data_in_leaf와 결합해 과적합을 개선한다.
LightGBM 예제(위스콘신 유방암 예측)
모듈
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split데이터
data = load_breast_cancer()
ftr = data.data
target = data.target
# 학습 데이터 : 80%로 설정
x_train, x_test, y_train, y_test = train_test_split(ftr, target, test_size=0.2, random_state=156)LGBM 모델 생성
# 반복 수행하는 트리 400개
lgbm_wrapper = LGBMClassifier(n_estimators=400)
evals = [(x_test, y_test)]
# LGBM도 조기 종료 기능을 제공한다.
lgbm_wrapper.fit(x_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(x_test)
pred_proba = lgbm_wrapper.predict_proba(x_test)[:,1]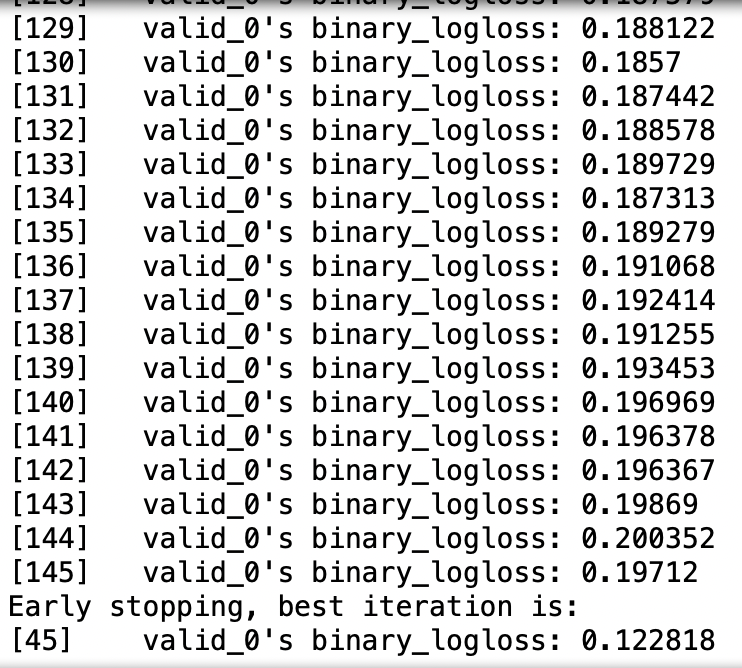
조기 중단 기능으로 145번째까지 학습을 하고 종료가 됬다.
get_clf_eval()
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
from sklearn.metrics import f1_score
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
def get_clf_eval(y_test, pred, pred_proba):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('정확도 : {:.4f}, 정밀도 : {:.4f}. 재현율 : {:.4f}, \
F1 : {:.4f}, AUC : {:.4f}'.format(accuracy, precision, recall, f1, roc_auc))
get_clf_eval(y_test, preds, pred_proba)오차 행렬
[[33 4][ 1 76]]
정확도 : 0.9561, 정밀도 : 0.9500. 재현율 : 0.9870, F1 : 0.9682, AUC : 0.9905
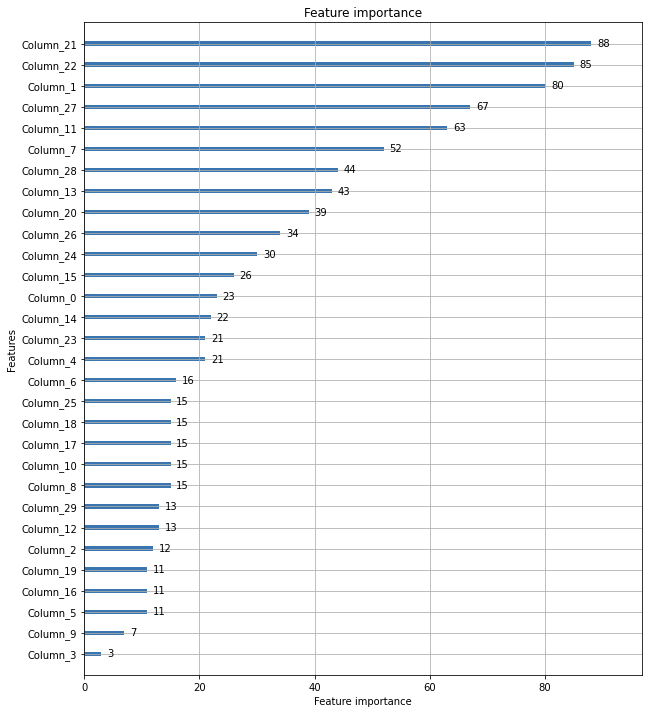
plot_importance
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgbm_wrapper, ax=ax)