비즈니스 활용 사례로 배우는 데이터 분석:R 참고
특정 앱에서 인게임 아이템을 매월 세일한다. 하지만 매상은 높으나 구매율이 다른 앱 대비 높지 않아 구매율이 낮은 원인을 밝혀내려고 한다.
그래서 구매율이 낮은 원인을 알아내어 다른 앱과 같은 수준의 구매율을 실현하는 것이 목표이다.
가설
- 아이템 세일 내용에 문제가 있다.
- 필요하지 않은 아이템을 세일로 내놓는 문제
- 세일 폭이 크지 않아 User에게 크게 어필이 되지 않고 있다.
- 광고에서 표시 내용에 문제가 있다.
-> 기획부에서 확인한 결과 아이템 세일 내용에는 문제를 발견 못했다. 마케팅부에서 가설 2에 대한 회의를 한 결과 광고 내용 표시에 문제가 있다고 판단
앱의 배너광고 클릭율이 다른 앱보다 낮다는 것이 확인되었고 배너 광고 품질에 문제가 있다는 것을 알게 되었다. 고로 다른 앱의 광고와 비교하여 광고 배너의 품질을 개선하는게 우선시이다.
그래서 다른 두개의 앱의 배너 광고 중 어떤 앱의 배너 광고가 더 나은지 데이터를 분석하려고 한다.
검증 방법
가장 단순하게 생각해서 시계열 데이터를 가지고 어떤 시기를 기준으로 전에는 A 광고 배너를, 후에는 B 광고 배너를 걸어 구매율을 비교를 하면 된다.
하지만 이런 시계열 데이터는 외부요인으로 인해서 차이가 날 수도 있다. 예를 들어 광고 배너 외에 다른 광고 요인에 인한 구매율 상승이라던가, 해당 앱의 이벤트가 크게 터졌다던가 등등 이 있을 수도 있다. 그래서 단순 분석만으로는 어떤 앱의 광고 배너가 좋다고 할 수 없다.
그래서 A/B 테스트로 외부 요인을 제거하고 분석한다. 이는 여러 선택지 중에서 어느 것이 가장 좋은 결과를 가져다 주는지 알아보기 위한 검증 방법이다.
분석
분석 데이터
ab_test_imp = pd.read_csv("C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section5-ab_test_imp.csv")
ab_test_goal = pd.read_csv("C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section5-ab_test_goal.csv")ab_test_imp
배너 광고의 표시 횟수 정보를 다룬 데이터이다.

log_date: 표시된 날짜test_name: 테스트 이름test_case: 테스트 케이스user_id: User IDtransaction_id: 트랜잭션 ID
ab_test_goal
배너 광고의 클릭 횟수 정보를 다룬 데이터이다.

log_date: 클릭한 날짜test_name: 테스트 이름test_case: 테스트 케이스user_id: User IDtransaction_id: 트랜잭션 ID
데이터 가공
두 개의 데이터를 결합하여 User가 배너를 클릭했는지 여부를 파악한다.
df = ab_test_imp.merge(ab_test_goal, how = 'outer', on = ['user_id', 'transaction_id', 'test_case'])
df = df.drop(columns = ['app_name_y', 'test_name_y', 'app_name_x'])
두 데이터를 결합한 결과 log_date_y가 클릭한 날짜인데 결측값인 부분은 클릭을 하지 않았다는 것이고, 날짜가 남아있는 경우는 클릭했다는 의미이다.
따라서 다음과 같은 처리를 하였다.
def click(data):
if data == '0':
return "No"
else:
return "Yes"df.log_date_y.fillna('0', inplace = True)
df['click'] = df.apply(lambda x: click(x['log_date_y']), axis = 1)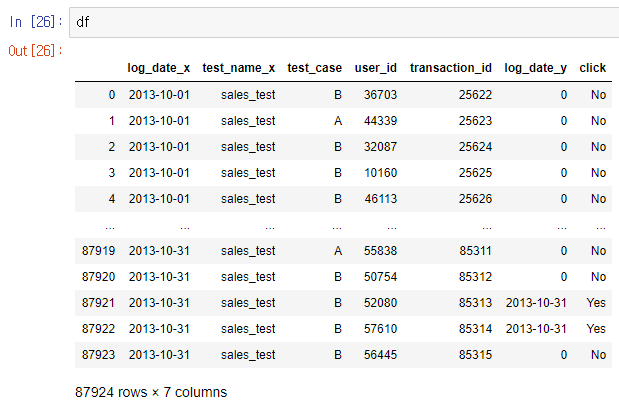
결측값을 특정 문자로 처리해주고 클릭여부를 만들어줄 함수를 써서 click라는 열에 따로 클릭 여부를 적어주었다.
test_case A와 B의 각 클릭율을 구해주자.
df_a_click = len(df[(df['click'] == 'Yes') & (df['test_case'] == 'A')]) / len(df[df['test_case'] == 'A'])
df_a_click
df_b_click = len(df[(df['click'] == 'Yes') & (df['test_case'] == 'B')]) / len(df[df['test_case'] == 'B'])
df_b_clickclick_A : 0.08025558526306249
click_B : 0.11546015071934232
A의 클릭율은 대략 8%, B는 대략 12%로 나타났다.
카이제곱 검정
A와 B의 차이가 광고 배너 클릭에 관련성이 있는지 판단하기 위해 카이제곱검정을 이용했다.
카이제곱검정이란 질적자료와 질적자료간에 서로 통계적으로 관계가 있는지 판단하는 검정이다.
귀무가설:test_case와click간에 관련성이 없다.대립가설:test_case와click간에 관련성이 있다.
import scipy.stats as stats
result = pd.crosstab(df.test_case, df.click)
stats.chi2_contingency(observed = result)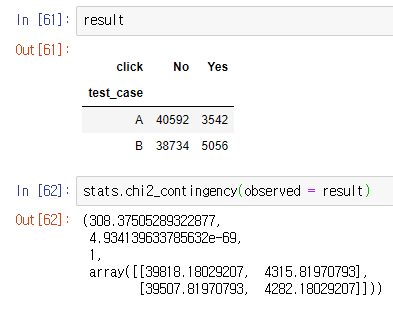
카이제곱 검정을 한 결과 p-value가 4.934139633785632e-69로 0.05 이하여서 관련성이 있다라고 판단할 수 있다.
시계열 시각화
df_fig = df.groupby(['log_date_x', 'test_case', 'click'], as_index = False)['user_id'].count()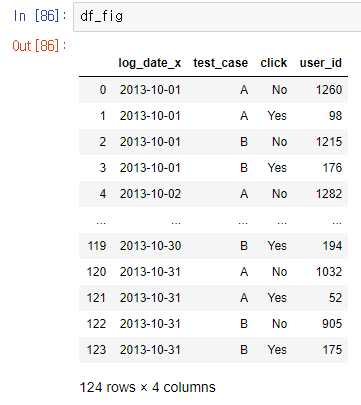
우선 log_date 및 test_case별 광고 배너를 클릭한 여부에 따라 user 수를 나눴다.
df_fig_2 = df_fig.groupby(['log_date_x', 'test_case'], as_index = False)['user_id'].sum()
list = df_fig[df_fig['click'] == 'Yes'].user_id
list = list.drop(columns = ['index'])
df_fig_2['click'] = list['user_id']
df_fig_2['percent'] = df_fig_2.click / df_fig_2.user_iddf_fig_2라는 log_date 와 test_case별 총 user수를 구한 다음, list라는 click == 'Yes'인 행만 따로 뽑아 df_fig_2에 넣은 다음, percent라는 열을 만들어서 클릭한 비율을 구하였다.
fig = px.line(df_fig_2, x = 'log_date_x', y = 'percent', color = 'test_case')
fig.show().png)
비율을 구할 때 다음과 같이 해도 된다.
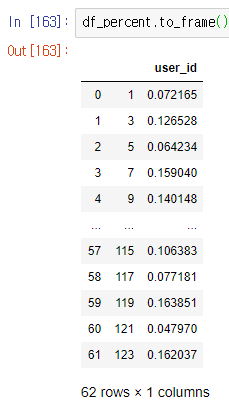
def func(df): return df[df['click'] == 'Yes'].user_id / df.user_id.sum() df_percent = df_fig.groupby(['log_date_x', 'test_case'], as_index = False).apply(lambda x: func(x)) df_percent.to_frame()
groupby에서 apply를 적용하기 위해 func라는 함수를 만들었는데 이는click== 'Yes'인 User수를log_date와test_case로 묶었을 때의 User 수의 합으로 나누는 함수이다.
따라서 위와같은 전체 User수 대비 광고 배너를 클릭한 User수의 비가 계산이 된다.