비즈니스 활용 사례로 배우는 데이터 분석:R 참고
이번엔 어플을 떠나는 고객들의 유형을 파악하기 위한 탐색적 데이터 분석을 해보려고 한다.
User들의 로그인 데이터와 어플에 가입할 때 제공한 User에 대한 정보 데이터를 가지고 어떤 User들이 어플을 떠나는지 파악하려고 한다. User 탈퇴 여부는 log_date를 가지고 판별한다.
탐색적 데이터 분석 : 원인은 분명하지는 않지만 어떤 현상에 대한 문제점이 발생했을 때 그에 대한 원인을 찾아내는 분석
분석 데이터
dau = pd.read_csv('C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section4-dau.csv');
user_info = pd.read_csv('C:/Users/HwanSeob/Desktop/R/DataAnalysis_src/R/section4-user_info.csv');
dau.head()
user_info.head()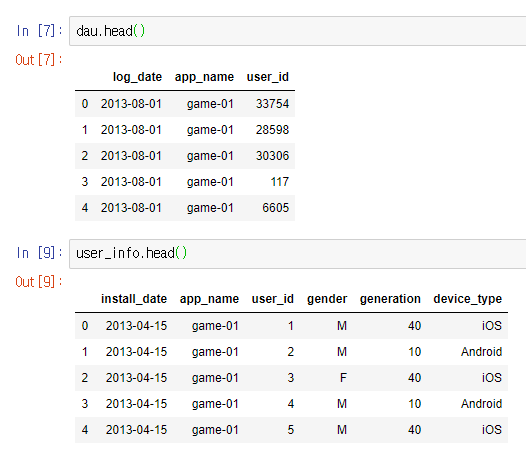
dau
log_date: User의 로그인한 날app_name: User가 이용한 app Name
app_name에 어떤 값들이 존재하는지 확인하기 위해서 unique 활용
dau['app_name'].unique()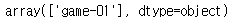
user_id: 로그인한 User id
user_info
install_date: User가 app을 설치한 날app_name: User가 이용한 app Nameuser_id: app을 설치한 User idgender: 성별generation: 나이 세대device_type: 앱을 설치한 OS환경
이 데이터에서 8월달과 9월달의 user 추세를 파악하기 위해 pie chart를 이용
.png)
9월달의 User가 확연히 줄어든 것을 알 수 있다.
그러면 데이터 분석을 하기 전에 두 데이터를 합쳐서 분석을 하려고 한다.
df = pd.merge(dau, user_info, how = 'left', on = ['user_id'])
df.sort_values(by = ['user_id'], axis=0)
그리고 월 별 User 현황을 파악하기 위해 log_date, install_month를 이용하여 log_month와 install_month 데이터를 생성하고 두 데이터 프레임을 병합하면서 app_name 속성이 겹쳐 한 열을 제거했다.
df['log_month'] = df['log_date'].str[:7]
df['install_month'] = df['install_date'].str[:7]
df = df.drop(columns = ['app_name_y'])
df = df.rename(columns = {'app_name_x' : 'app_name'}) 일단 어떤 형태의 User가 탈퇴를 했는지 파악해보기 위해 데이터를 전처리하려고 한다.
1. 성별에 따른 User
df_sex = df.groupby(['log_month', 'gender'], as_index=False)['user_id'].count()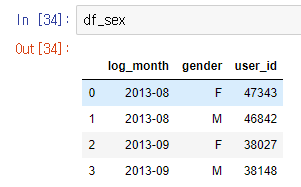
우선 성별에 따른 탈퇴 현황을 파악해보려고 전처리를 해보았다.
8월달과 9월달의 남녀 user 현황수를 비교해보면 남녀 다 줄어든것을 확인할 수 있다. 두 성별 중 특별히 더 많이 줄어들지는 않았다. 그래서 성별에 따라 문제가 있다고는 생각을 할 수 없다.
2. 나이에 따른 User
df_age = df.groupby(['log_month', 'generation'], as_index=False)['user_id'].count()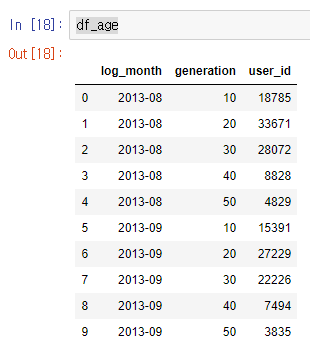
나이에 따라서도 데이터를 확인해봤는데 10대부터 50대까지 모든 나이대에서 골고루 User수가 감소한 것을 알 수 있따.
3. 나이 및 성별에 따른 User
df_sex_age = df.groupby(['log_month', 'generation', 'gender'], as_index=False)['user_id'].count()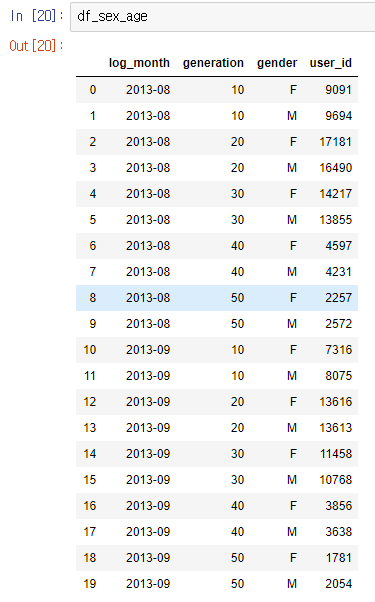
데이터 프레임을 육안으로 분석하기에는 힘이 들다.
그래서 8월달 데이터와 9월달 데이터를 분리하여 차이를 비교해봤다.
df_8 = df_sex_age[df_sex_age['log_month'] == "2013-08"]
df_8 = df_8.reset_index()
df_8
df_9 = df_sex_age[df_sex_age['log_month'] == "2013-09"]
df_9 = df_9.reset_index()
df_9
df_9['gap'] = df_9['user_id'] - df_8['user_id']
df_9['percent'] = (df_8['user_id'] - df_9['user_id']) / df_8['user_id']
df_9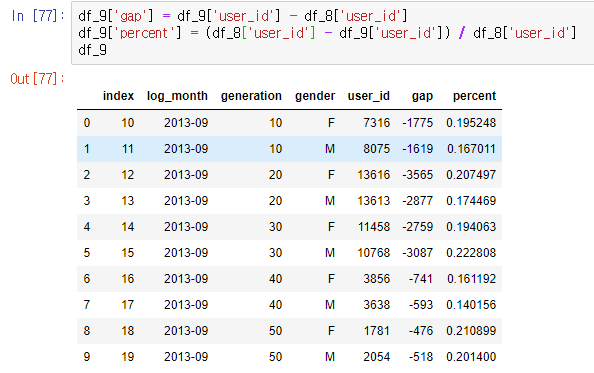
단순히 감소한 수만 보면 20대 30대의 남녀의 수가 가장 많은거로 보이지만 percent로 보게 된다면 전 연령, 전 성별 감소한 비율이 비슷하다고 볼 수 있다.
4. OS별 User
df_os = df.groupby(['log_month', 'device_type'], as_index = False)['user_id'].count()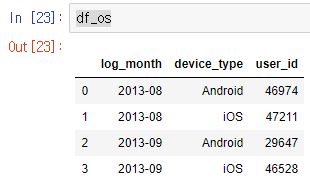
device_type로 보면 Android는 큰 폭으로 user수가 감소했만 iOS는 별다른 변환가 없는 것을 알 수 있다.
df_device = df.groupby(['log_date', 'device_type'], as_index = False)['user_id'].count()
fig = px.line(df_device, x = 'log_date', y = 'user_id', color = 'device_type')
fig.show().png)
log_date별 User수를 가시화해서 확인해보면 확실하게 알 수 있다.
이번 탐색적 데이터 분석을 통해서 가설을 검정해보았다. 데이터 분석 시에는 가설을 세우는 것이 중요하다. 이 기초부터 꼬이기 시작하면 분석을 할 시에 효율적이지 못하게 되기 때문이다.
특히 데이터를 깊게 분석하다보면 필요 이상으로 분석에 시간을 낭비하게 되는 경우가 생기는데, 이를 방지하기 위해 데이터 분석 전에 가설을 세워야 한다.
이번 데이터 분석 전에 세웠던 가설은
1. 9월달 유저수가 8월달에 비해 줄어들었다. (사실)
2. 특정 세그먼트에서 User수가 확연히 줄어들었을 것이다. (가설)
3. 해당 세그먼트에 대한 대책을 세워 User 수를 회복한다. (대책)
이 가설에 대한 검정은 다음과 같다.
성별, 나이대에 대해서 확연하게 줄어든 세그먼트는 없다. 단지 Android OS체제에서 User수가 줄어든 것을 알 수 있었다. Android 환경 내에서 앱의 문제점이 있는지 확인해보고 해결책을 세워 User수를 8월달로 회복시켜야 한다.
