선형대수 필요성
선형대수를 간단히 설명하자면 주어진 데이터를 어떤 공간(2차원 등등)으로 표현한 것이라고 할 수 있다. 이러한 서형대수는 머신러닝에서는 필수부가결한 역할을 한다.
관객 100명으로부터 영화 100편의 선호도를 조사하는 예를 보자
| 토이스토리 | 배트맨 | 어벤져스 | ... | |
|---|---|---|---|---|
| 관객1 | 5 | 2 | ||
| 관객2 | 4 | 1 | ||
| 관객3 | 4 | 3 | 5 | |
| ... | 5 |
위 데이터는 관객이라는 하나의 차원과 영화라는 하나의 차원으로 설명이 가능하다. 결국 총 두 차원의 조합으로 이해되며, 각각의 차원으로도 이해가 가능하다.
이해란 각 차원에 속하는 수치를 알고 있는 것으로 해석 가능. 해당 현상의 여러 속성을 값으로 파악하는 것.
이와 같이 2차원으로 표현된 데이터를 이해하는 다양한 개념과 방법을 제공하는 것이 선형대수의 역할이다.
- 정량적인 속성 : 수치로 표현. 정량적인 속성을 객관적이고 과학적으로 이해하려면 수학적 접근과 표현이 필요.
- 정성적인 표현 : 글이나 문자로 표현
숫자로 표현된 1차원 or 2차원 수치 값을 효과적이고 과학적으로 다루는 방법은 선형대수라는 이름으로 정리되어 있다. 선형대수를 바탕으로 1차원 또는 2차원 수치를 계산할 수 있고, 데이터를 요약하거나, 공간의 관점에서 이해 가능하다.
선형대수는 데이터를 분석하는 많은 알고리즘의 기본이 된다.
협업 필터링 추천 알고리즘: 많은 사용자들로부터 얻은 기호정보에 따라 사용자들의 관심사를 자동적으로 예측하는 방법소셜 네트워크 분석 알고리즘: 개인적인 인간관계가 확산되어 형성된 사람들 사이의 연결된 네트워크인 사회 연결망을 분석선형 회귀 분석: 종속변수 y와 한 개 이상의 독립변수 x와의 선형 상관 관계를 모델링하는 기법텍스트 마이닝: 비정형 데이터 마이닝의 유형 중 하나. 텍스트 마이닝은 비정형 및 반정형 데이터에 대하여 자연어 처리 기술과 문서 처리 기술을 적용하여 유용한 정보를 추출, 가공하는 목적으로 하는 기술연관 규칙 분석: 어떤 두 아이템 집합이 번번히 발생하는가를 알려주는 일련의 규칙들을 생성하는 알고리즘주성분 분석: PCA는 데이터 하나 하나에 대한 성분을 분석하는 것이 아니라, 여러 데이터들이 모여 하나의 분포를 이룰 때 이 분포의 주 성분을 분석해 주는 방법.특이값 분해: 행렬을 특정한 구조로 분해하는 방식으로, 신호 처리와 통계학 등의 분야에서 자주 사용.
등등 다양한 기법의 바탕에 선형대수를 사용
행렬의 내적과 외적
- 행렬의 곱
.jpg)
행렬의 곱은 쉬우니 대충 넘어간다.
- 하나의 횡 벡터와 하나의 종 벡터가 곱을 이루는 경우 하나의 숫자가 나오게 되고 이를
내적이라고 한다. (스칼라 생성) 내적과 반대로 종벡터와 횡벡터의 곱은외적이라 하며내적값과 전혀 다른 결과를 출력한다. (행렬 생성)
행렬 연산의 의미와 활용
행렬은 곱셈이라는 방식을 통해 계산하면 좀 더 특별한 의미를 가지게 된다. 바로 어떤 공간이나 상태를 변형시키는 것이며 이를 사영(projection)이라고 한다.
방정식을 행렬로도 표현이 가능하다.
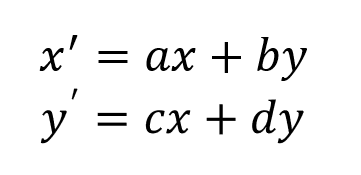
위와 같은 두 방정식이 있다고 하자.
여기서 x, y, x', y'는 미지수이며, a, b, c , d는 수치(계수)이다. 이를 행렬로 표현하면
.jpg)
다음과 같이 나타낼 수 있다. 그러면 이러한 행렬의 곱셈이 어떻게 데이터 과학에 응용되는지를 확인해보자
분석모형 응용 - 유사도행렬의 계산
행렬의 의미와 곱셈만으로도 단순한 머신 러닝의 추천 알고리즘을 구현 가능하다.
다음 문제 하나를 살펴보자
- 손님 4명이 제품 5개에 대해 갖는 선호도
| 손님1 | 손님2 | 손님3 | 손님4 | |
|---|---|---|---|---|
| 소고기 | 5 | 1 | 1 | |
| 치킨 | 4 | 1 | ||
| 우유 | 4 | |||
| 치즈 | 5 | 4 | 4 | |
| 콩 | 5 |
위 표는 손님이 제품에 대한 선호도를 1 ~ 5점으로 기록한 것이다. 결측값의 경우에는 아직 손님이 제품을 구매하지 않았음을 의미
이 표를 보면 손님 사이의 성향이 유사한지 아닌지를 알 수 있다.(정확성은 100프로는 아니다). 예를 들어, 손님 2와 4는 소고기와 치즈를 구매했고, 치즈를 좋아하는 유사성이 있다. 손님 2는 아직 치킨을 사지 않았지만 대체적으로 둘은 유사한 성향을 보인다. 그렇다면 이와 같은 데이터를 통해 어떤 마케팅이 가능한가?
손님2에게 '당신과 유사한 성향을 가진 손님 4가 치킨을 샀으니, 당신도 잡숴봐라!' 라며 제안을 할 수있다.
이것이 머신 러닝의 사용자 기반 협업 필터링 추천 기법의 원리이다. 문제는 손님 간의, 물건 간의 이러한 관계를 하나씩 계산할 수 없다. 이러한 문제를 해결하기 위해 행렬의 개념을 사용
위의 표는 손님이 물건에 평가를 매긴 평가 행렬이고, 손님 간의 유사한 정도를 알려주는 유사도 행렬을 구할 수 있다.
| 손님1 | 손님2 | 손님3 | 손님4 | |
|---|---|---|---|---|
| 손님1 | 0 | 0.13 | 0 | 0.28 |
| 손님2 | 0.13 | 0 | 0.61 | 0.97 |
| 손님3 | 0 | 0.61 | 0 | 0.59 |
| 손님4 | 0.28 | 0.97 | 0.59 | 0 |
손님 2와 4가 유사하게 나타남을 확인 가능
.jpg)
평가도 행렬과 유사도 행렬을 곱하는 과정을 보면 평가행렬에서 각 제품에 대한 손님의 선호도 값과 유사도행렬에서 각 손님들 사이의 유사도 값을 곱하는 것
즉, 손님 2의 치킨 선호도 예측값은 손님 4뿐만 아니라 다른 손님과의 유사도도 고려 가능하다
그럼 손님 2의 치킨 선호도 값은
4 x 0.13 + 0 x 0 + 0 x 0.61 + 1 x 0.97 = 1.49
가 된다.
결국은 모든 손님에 대한 선호도 값을 표로 작성하면
.jpg)
- 이 선호도 표를 보면 손님 2는 치킨에 대해 높은 값이 나왔으니 치킨을 구매하라고 장려 할 수 있다. 콩도 마찬가지
이와 같이 행렬 간의 곱셈이 데이터 분석에 사용 가능하다.
출처 : 머신러닝을 위한 수학 with 파이썬, R
