머신러닝
1.머신러닝을 위한 선형대수_1
.jpg)
선형대수를 간단히 설명하자면 주어진 데이터를 어떤 공간(2차원 등등)으로 표현한 것이라고 할 수 있다. 이러한 서형대수는 머신러닝에서는 필수부가결한 역할을 한다.관객 100명으로부터 영화 100편의 선호도를 조사하는 예를 보자| |토이스토리 |배트맨| 어벤져스| .
2.Numpy 예제들

넘파이를 import하는데 이후에 쓸 때 np라는 약어를 사용arr1 ~ arr4까지 총 4가지 경우의 ndarray를 생성했다. 배열은 \[]를 기준으로 차원을 나눈다. 이 네 배열의 type를 살펴보면arr1 type : <class 'numpy.ndarra
3.Pandas 예제들

Pandas의 DataFrame의 예제를 살펴보기 위해 Kaggle의 타이타닉 데이터를 사용하려고 한다.Pandas는 Numpy와는 다르게 데이터 핸들링이 용이하다. 보통 데이터를 불러올 때 2차원적인 데이터를 불러오는데, 주로 read_csv를 사용한다. 다른 수단으
4.Pandas 예제들2

정렬 Numpy에서 정렬을 위해서 np.sort(), ndarray.sort()을 사용했었다. DataFrame와 Series을 정렬하기 위해서는
5.sklearn - 분류
파이썬 모듈 중에서 사이킷런을 사용하여 iris 데이터를 분류를 해보려고 한다.분류(Classification)은 대표적인 지도학습 머신러닝 알고리즘으로, training 데이터를 가지고 학습하여 별도의 test 데이터의 Label을 예측할 수 있다.iris 데이터의
6.타이타닉 데이터 예측
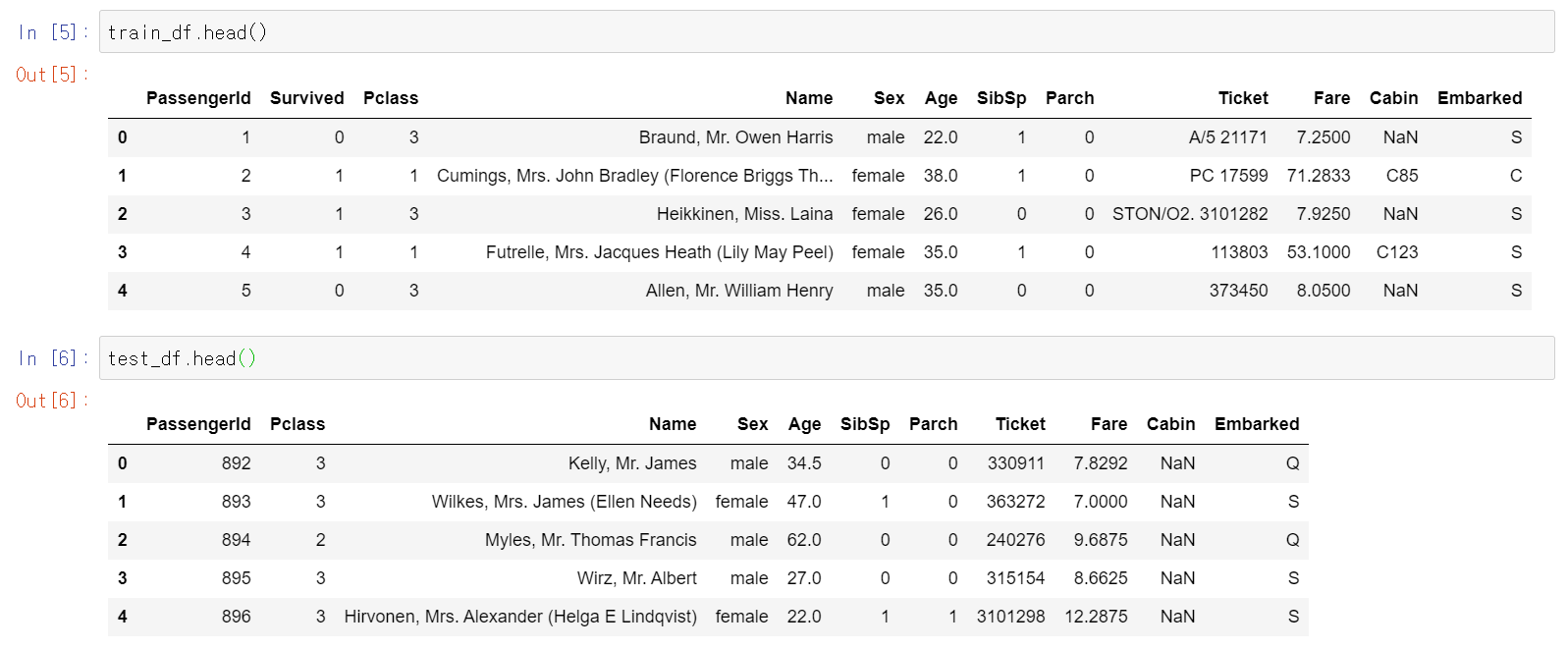
간단하게 배운 DecisionTreeClassifier 머신러닝 알고리즘으로 타이타닉 데이터를 분석해보았다.복습차원에서 공부한것이라 큰 의미는 없는 분석이다.sklern 패키지에서 의사결정나무 모듈은 import하고 titanic 데이터에서 성별과 같은 데이터를 인코더
7.Model Selection
.jpg)
sklearn의 model_selection은 데이터셋을 train 및 test 데이터셋으로 분리하거나 교차검증 분할 및 평가, 지도학습 클래스(Estimator)의 하이퍼 파라미터를 튜닝하는 모듈이다.기본적인 데이터셋을 학습 및 테스트 데이터 셋으로 분리하는 메서드이