카이제곱-분포(𝑥^2-분포)
정의
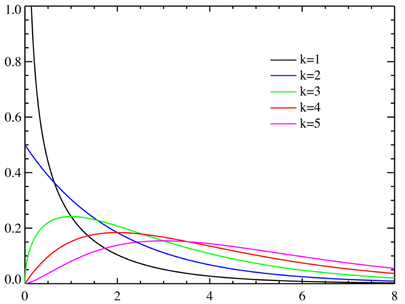
- k개의 서로 독립적인 표준 정규 확률변수를 각각 제곱한 다음 합해서 얻어지는 분포. k는 자유도라고 하며, 카이제곱 분포의 매개변수가 된다.
- 신뢰구간이나 가설검정 등의 모델에서 자주 사용
- 감마 분포의 특수한 형태로 감마분포에서
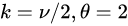 인 분포를 나타낸다.
인 분포를 나타낸다.
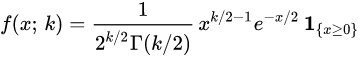
- 통계에서 분석 시에 데이터의 중심위치(평균 등)를 파악하는 것이 중요하다. 중심위치중에 평균을 기준으로 각 데이터가 흩어져있는 정도, 즉 치우침을 나타내는 대표적인 척도가 분산인데, 분산의 특징을 확률분포로 만든 것이다.
t-분포
정의
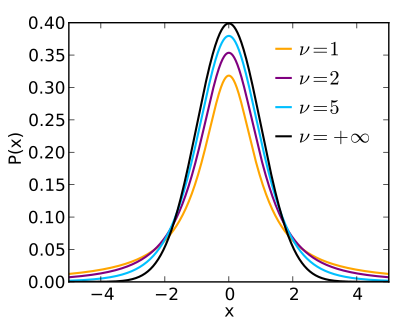
- 정규 분포의 평균의 해석에 많이 쓰이는 분포
- 모집단이 정규 분포라는 정도만 알고, 모 표준편차는 모를 때 사용
- 통계에서 보통 데이터는 평균 근처에 많이 분포하고, 평균에서 멀어질수록 적게 분포하는 정규분포 형태를 띠는 경우가 많다. 이 때 표본의 수가 적으면 신뢰도는 낮아진다.
표본을 많이 못뽑는 경우 대응책으로 정규분포보다 한 단계 예측범위가 넓은 분포를 사용한다. 이것이 t-분포이다. - 표본의 수가 30개 미만일 경우 t-분포를 사용.
F-분포

정의
- 독립적인 x^2 분포가 있을 때, 두 확률변수의 비
- 모집단 분산이 서로 동일하다고 가정되는 두 모집단으로부터 표본 크기가 각각 n1, n2인 독립적인 2개의 표본을 추출하였을 때, 2개의 표본분산의 비율
- 두 집단의 분산의 크기가 같은지 다른지를 비교한다. 이 두 분산의 나눗셈을 확률분포로 나타낸 것.
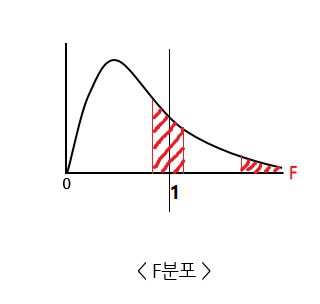
f-분포 그래프에서 1을 기준으로 1에 가까울수록(두 분산의 크기가 비슷) 분포가 많고, 1에서 멀어질수록 분포가 감소한다. - 표본의 수가 적으면 분포가 더 많다. 그래프에서 1을 기준으로 왼쪽에 해당. 그래서 표본의 수가 많아지면 그래프는 1을 중심으로 정규분포의 모양과 비슷해진다.

늦게 출발했지만 꾸준히 달려서 도착지점에 무사히 도달하자