빅데이터
1.연속확률분포 종류
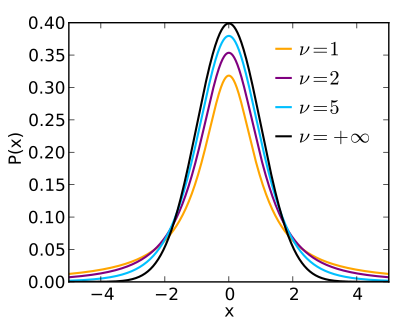
k개의 서로 독립적인 표준 정규 확률변수를 각각 제곱한 다음 합해서 얻어지는 분포. k는 자유도라고 하며, 카이제곱 분포의 매개변수가 된다.신뢰구간이나 가설검정 등의 모델에서 자주 사용감마 분포의 특수한 형태로 감마분포에서 인 분포를 나타낸다.확률 밀도 함수정규 분포의
2.데이터 과학이란?

Data Science 모든 데이터는 과학을 기반으로 한다. 과학 : 체계성 + 객관성 : 다른사람이 내가 만든 모델을 돌려도 같은 결과값이 나와야 한다.(체계성) 예측을 하지만 객관적이어야 한다.(이와 반대로 점쟁이는 객관성x) 데이터 과학 : 문제의 원인(변인, v
3.데이터 베이스(DB)
.jpg)
1차 : 체계적이거나 조직적으로 정리되고 전자식 or 기타 수단으로 개별적으로 접근할 수 있는 독립된 저작물, 데이터 또는 기타 소재의 수집물2차 : 빅데이터 출현으로 비정형 포함. 동시에 복수의 적용 업무를 지원할 수 있도록 복수 이용자의 요구에 대응해서 데이터를 받
4.데이터 처리
.jpg)
데이터 처리 데이터 분서은 통계를 기반으로 하지만, 통계 지식과 복잡한 가정이 상대적으로 적은 실용적인 학문 .jpg) legacy : 예전부터 사용해오던 기술, 소프트웨어 등을 뜻한다. 이들은 새로운 것으로 대체가 가능하다.
5.탐색적 자료 분석(EDA)

탐색적 자료 분석(EDA)는 데이터 수집 시 데이터에 대해서 이해를 할 때 하는 분석이다. EDA는 다양한 차원의 관점에서 데이터를 보고 각각의 변수를 조합해 봄으로써 편견에 치우치지 않고 데이터를 있는 그대로 바라보는 분석이다.일반적인 통계 가설을 세울 때는 사람이
6.통계란?
.jpg)
특정 집단을 대상으로 조사나 실험을 통해 나온 결과를 요약하여 나타낸 표현.집단 또는 불확실한 현상을 대상으로 자료를 수집하여 대상 집단에 대한 정보를 구하고, 적절한 통계분석 기법을 이용하여 의사결정을 하는 것.기술통계 : 주어진 자료에 대해 주관적인 의견이 개입할
7.데이터 마트
데이터의 흐름은 다음과 같다. Legacy에서 Staging을 거쳐 ODS에서 데이터 전처리를 거친다음 DW에 저장을 한다. 그 후 특정 주제, 부서에 맞게 데이터를 다시 저장즉, 작은 범위의 데이터 웨어하우스라고 할 수 있다.데이터 마트의 데이터는 대부분 DW에서 가
8.분석
.jpg)
분석 주제에는 4가지 유형이 있다. 그 4가지는 분석 대상과 분석 방법으로 결정된다.분석 기획시 고려해야할 부분이 있다.분석을 위해서는 데이터 확보가 우선적이다. 데이터의 유형에 따라 적용 가능한 솔루션과 분석 방법이 달라지기 때문에 데이터 유형에 대한 분석이 먼저 이
9.KDD 분석 vs CRISP-DM
.jpg)
데이터로부터 통계적 패턴이나 지식을 찾기 위해 활용할 수 있도록 체계적으로 정리한 데이터 마이닝 프로세스.데이터마이닝, 머신러닝, 인공지능, 패턴인식, 데이터 시각화 등에 응용KDD 분석의 과정은 다음과 같다.데이터셋 선택에 앞서 분석 대상의 비즈니스 도메인에 대한 이