정의
탐색적 자료 분석(EDA)는 데이터 수집 시 데이터에 대해서 이해를 할 때 하는 분석이다. EDA는 다양한 차원의 관점에서 데이터를 보고 각각의 변수를 조합해 봄으로써 편견에 치우치지 않고 데이터를 있는 그대로 바라보는 분석이다.
탐색적 자료 분석을 왜??
일반적인 통계 가설을 세울 때는 사람이 직접 함으로 주관적인 의견이 들어가기 마련이다. 빅데이터 분석을 할 시에 데이터 자체를 볼 때는 인간의 생각, 감정 등이 개입해서는 안되기 때문에 이를 보완하기 위해 EDA를 사용한다. EDA를 사용하면 데이터를 있는 그대로 직관적으로 볼 수 있기 때문이다.
그리고 빅데이터란 말 그대로 방대한 양의 데이터를 분석하는 것이다. EDA를 사용한다면 한번에 이 많은 양들의 데이터가 어떤 특징을 가지는지, 사실들을 볼 수 있다.
EDA 4가지 주제
저항성의 강조잔차 계산자료변수의 재표현그래프를 통한 현시성
EDA를 어떻게?
데이터를 수집하고 EDA를 통해 데이터를 분석해보자.
우리가 분석시에 가져올 데이터를 보면 엄청난 양의 속성들이 존재할 것이다. 그렇다면 전체적인 관점으로 보기 전에 각각의 속성들이 어떤 것인지, 어떤 특징을 가지고 있는지 확인을 해야한다. 개별적인 속성도 모르는데 전체를 어떻게 볼 수 있을까??
개별적인 분석 후 전체적으로 변수들간의 관계를 살펴보며 이 데이터의 특징이 무엇이 있는지 알아볼 수 있다.
또한 EDA과정에서 이상치도 찾아낼 수 있어야 한다.
이 모든 과정을 시각화를 통해 할 수 있다.
EDA in Visualization
R에서 mtcars 데이터를 이용해서 EDA를 해보자
bar plot
head(mtcars) #데이터에 어떤 속성이 있는지 확인하기 위해 head()를 실행
mtcars라는 데이터를 보면 11개의 속성을 가지고 있다. 이 속성들이 어떤 특징을 가지고 있는지 확인해보자
위 속성중 vs는 V model engine / straight model engine 인지 일종의 명목형 변수이다.
이 vs속성에서 각각 몇개씩 존재하는지 확인해보자
ggplot(data = mtcars, aes(x = vs)) +
geom_bar(fill = 'blue')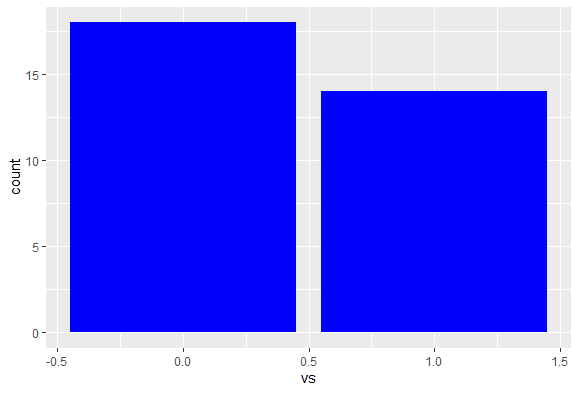
이를 통해 mtcars 데이터중에 vs라는 속성을 개별적으로 알아볼 수 있다.
histogram
간단하지만 V형 엔진이 더 많이 있다는 것을 알 수 있을 것이다. 다른것을 확인해볼까?
이번엔 mpg를 보고싶다. mile per gallon으로 그냥 연비이다.
ggplot(data = mtcars) +
geom_histogram(aes(x = mpg), binwidth = 1.5)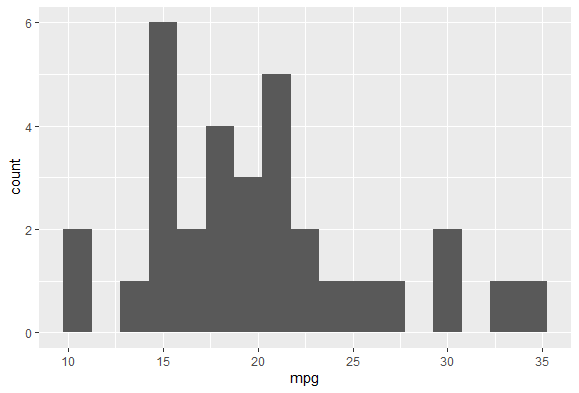
mpg는 연속형 변수라 히스토그램을 통해 표현해봤다. 이를 통해 각 도수마다 어느정도인지 확인할 수 있을 것이다.
이 mpg에 대해 더 알아보기 위해 집중적으로 모여있는 12.5 ~ 27.5정도의 범위 내를 확인해보자
library(dplyr)
x <- mtcars %>%
filter(mpg >= 12.5 & mpg <= 27.5)
ggplot(data = x) +
geom_histogram(aes(x = mpg), binwidth = 1)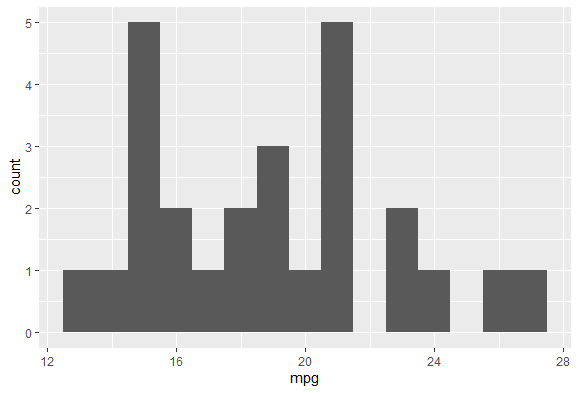
이렇게 특정 구간만 따로 확인이 가능하다.
그런데 히스토그램은 일정 구간마다 평균을 내어 평균치를 카운트하는데, 이것보다 더 좋은 그래프가 있다.
히스토그램에서 vs마다 mpg를 구분해줄수도 있다.
ggplot(data = mtcars, aes(x = mpg, fill = as.factor(vs))) +
geom_histogram(binwidth = 1)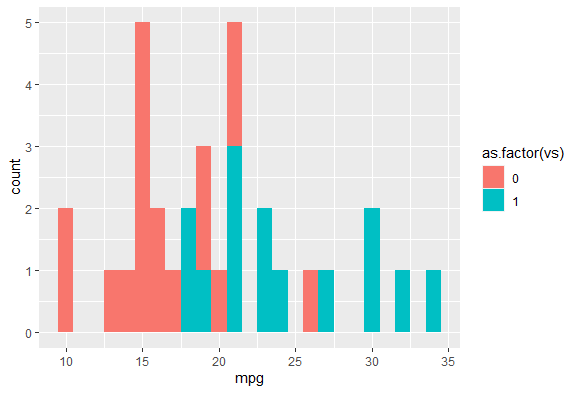
vs속성 각각마다 mpg를 카운트해준 그래프이다.
freqploy
이 freqploy를 쓰면 연속적인 구간을 선으로 표현하기 때문에 히스토그램보다 더 정확히 확인할 수 있다.
ggplot(data = mtcars, aes(mpg)) +
geom_freqpoly(binwidth = 1)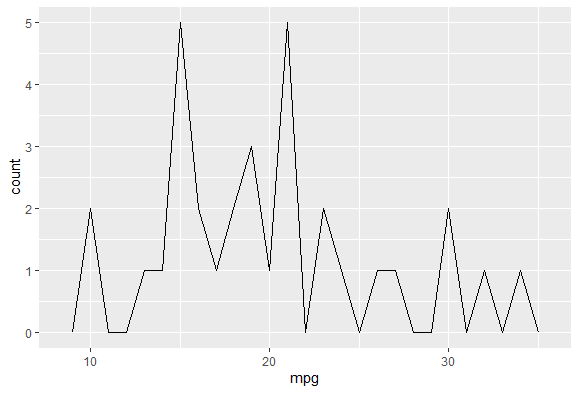
위 그래프처럼 선으로 표현되는 것을 알 수 있다. 여기다 vs마다 색깔을 다르게 해볼 수도 있다.
ggplot(data = mtcars, aes(x = mpg, colour = as.factor(vs))) +
geom_freqpoly(binwidth = 1)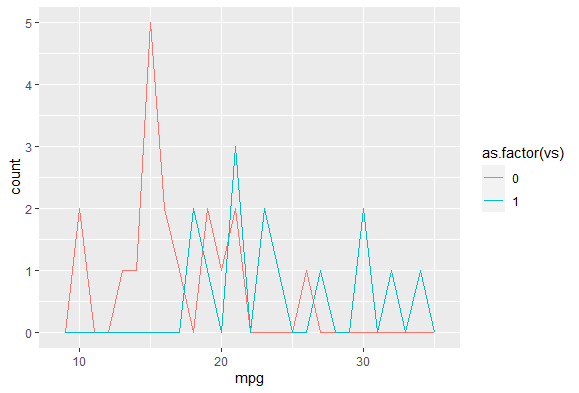
vs가 numeric데이터로 되어있어 factor형으로 변환해준다음 colour을 통해 vs마다 mpg를 카운트해줬다.
boxplot
outlier 발견?
이상치는 통계적인 숫자로는 판단하기 힘들다. 그래퍼 boxplot과 같은 그래프로 확인하고들 한다.
위에선 mt_cars를 통해 시각화했지만 이번엔 diamonds라는 데이터를 가지고 이상치를 확인해보자
mtcars엔 마땅한 결측치가...
ggplot(data = diamonds) +
geom_boxplot(aes(x = y))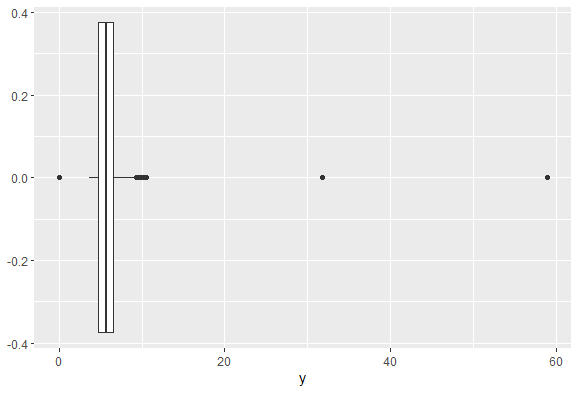
boxplot을 통해 y라는 속성을 나타내보았다. 보시다시피 박스를 중심으로 오른쪽에 대략적으로 2개정도 결측치가 보이는 것을 확인할 수 있다.
boxplot도 있지만 히스토그램으로도 가능하다. binwidth를 극히 작게 해서 표현해준다면
ggplot(data = diamonds) +
geom_histogram(aes(x = y), binwidth = 0.5)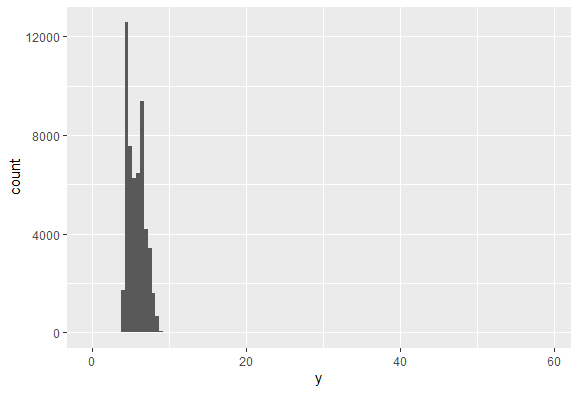
막대가 너무 작아 육안으로 보이지는 않지만 y의 범위를 보면 60까지 있는걸 볼 수 있다. 히스토그램이 집중적으로 그려진건 왼쪽인데 60까지 범위가 넓혀져있는 것을 보면 이상치가 있다는 것을 알 수 있을것이다.
결측치
EDA를 할 때는 결측치도 확인해줘야 한다. 이번에 사용할 데이터는 corona-19관련 데이터이다. 시간이 지남에 따라 얼마나 사망자가 높아지는지 확인하기위해 point를 통해 그려보려고 했는데??
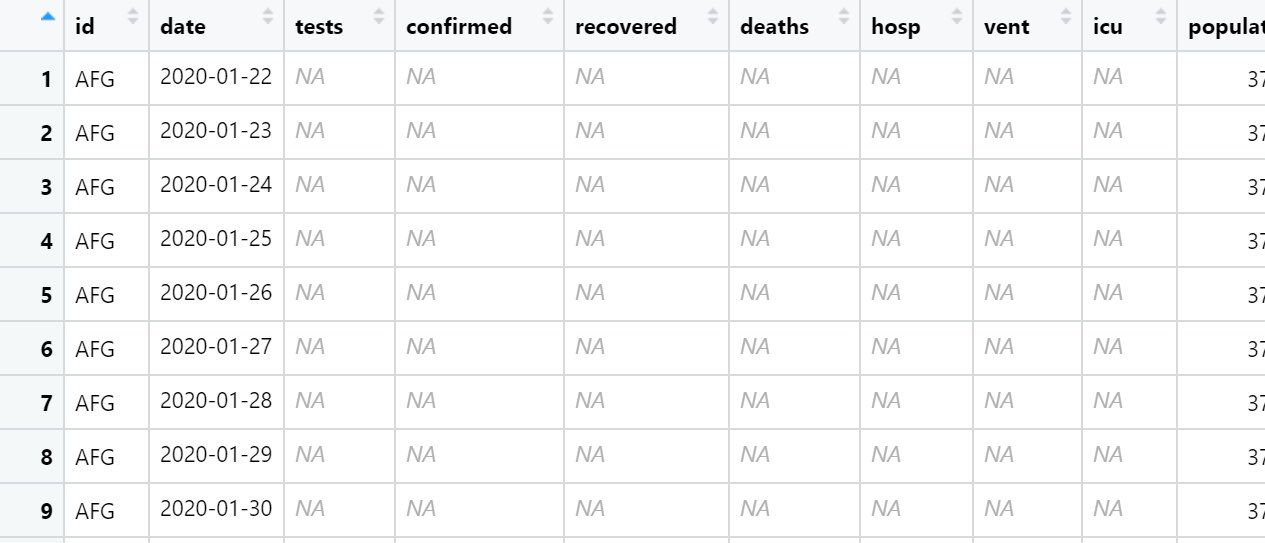
데이터를 생성하자마자 보이는건 숫자가 아닌 글자요. 숫자는 어디갔는지 인구수에서밖에 보이지가 않소..
결측치를 처리하지 않고 그래프를 그리면

그래프는 그려지는데 다음과 같은 경고메세지가 뜬다. 그래서 결측치를 제거해주는 것이 좋다.
ggplot(data = df, aes(x = date, y = deaths)) +
geom_point(na.rm = F, aes(color = id)) +
theme(legend.position = "none")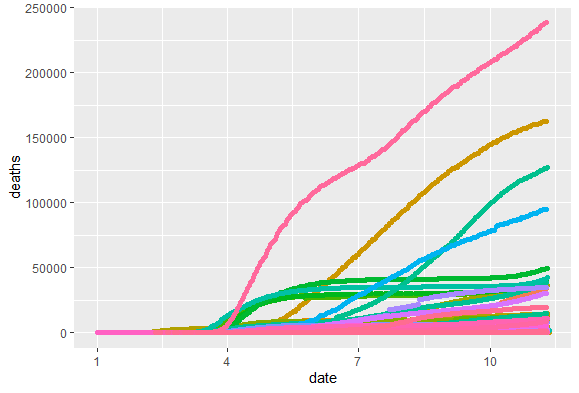
그래서 geom_ 함수에서 na.rm = T를 통해 결측치를 제거해주자.
그나저나 저 핑크나라... 아마 미국같아보이는데 사망자수가ㅠㅠ
오늘 EDA는 여기까지 살펴보자. 더 쓸 수 있는 시각화는 많지만 다음에 확인해보는것으로
