연결 리스트(LinkedList)
연결 리스트를 이용하여 리스트를 구현하는 방법은 구현이 복잡하고 오류가 발생하기 쉽다는 단점이 있지만 삽입과 삭제가 효율적이고 배열처럼 크기가 제한되지 않는다는 장점이 있어 많이 쓰이고 있다.
시간복잡도도 빅오표기법으로 O(1)이 된다.(배열은 O(n))
연결리스트에를 구성하는 요소에는 노드와 헤드포인터가 있다.
-
노드(node) : 데이터 필드 + 링크 필드로 구성/ 데이터 필드는 값을 담고 링크 필드는 다음 노드를 가리킨다.
노드를 생성하기 위해서는 필요할때마다 동적 메모리 생성을 이용해 생성해야한다. -
헤드포인터(head pointer) : 리스트의 첫번째 노드를 가리키는 포인터 변수

연결 리스트에는 단순 연결, 원형 연결 리스트, 이중 연결 리스트가 존재한다.
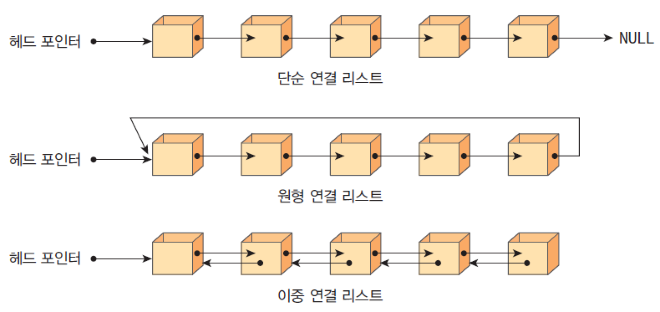
단순 연결 리스트(singly linked list)
단순 연결 리스트는 하나의 링크 필드를 이용하여 연결하는 방식으로 마지막 노드의 링크값에는 NULL값이 들어간다. 한 방향으로 연결되기 때문에 단일 연결 리스트라고 부르기도 한다.
삽입과 삭제 연산을 구현할 때도 링크를 조정하면 끝이기 때문에 메모리상의 움직임이 없어 효율적으로 프로그램을 작동시킬 수 있다.
단순 연결 리스트의 구현
- 노드의 정의
typedef char element;
typedef struct ListNode {
element data;
struct ListNode *link; //자체참조구조체
} ListNode; //데이터 필드와 링크 필드로 이루어진 ListNode 정의- 노드의 생성(동적 메모리 할당)과 반납
ListNode *p1;
p1 = (ListNode *)malloc(sizeof(ListNode); //동적 할당으로 노드 생성
free(p);//메모리를 반납해서 메모리 누수를 막아야한다.
- 데이터 필드와 링크 필드의 설정
p1->data = 10;
p1->link = NULL; - 두번째 노드 생성과 연결
ListNode *p2;
p2 = (ListNode *)malloc(sizeof(ListNode)); //두번째 노드 생성
p2->data = 20;
p2->link = NULL; //마지막 필드의 링크값은 null로 설정
p1->link = p2; 첫번째 노드의 링크가 두번째 노드를 가리키도록
insert_node의 구현(삽입)
먼저 insert_node에 들어가는 인자는 다음과 같다.
void insert_node(ListNode **phead, ListNode *p, ListNode *new_node)- phead : 헤드포인터 head에 대한 포인터
- p : 삽입될 위치의 선행노드를 가리키는 포인터(이 노드가 가리키는 다음이 삽입 위치)
- new_node : 새로운 노드를 가리키는 포인터
또 삽입을 할 때 노드의 3가지 경우에 따라 구현하는 것이 달라진다.
-
head가 NULL인 경우 : 현재 리스트가 비어있는 경우로 삽입하려는 노드가 첫번째 노드가 되는 것이다.
new_node->link = NULL
head = new_node -
p가 NULL인 경우 : 가리키는 선행노드가 없다는 뜻으로 리스트의 제일 처음에 삽입하는 경우이다
new_node->link = head
head = new_node-> head 포인터가 가리키던 앞의 노드를 new_node의 링크에 연결시키고 head 포인터는 new_node를 가리키도록 하면 끝
-
일반적인 경우 : 1,2번을 빼고 리스트의 중간에 삽입하는 경우를 말한다.
new_node->link = p->link (new_node의 링크가 p노드의 링크가 가리키는 노드를 가리키도록 연결)
p->link = new_node
(선행노드의 링크를 new_node를 가리키도록 연결)
-> new_node의 링크가 선행노드가 가리키도 있던 앞의 노드를 가리키도록 연결하고 선행노드의 링크에는 new_node를 가리키도록 연결하면 끝
이걸 바탕으로 코드를 구현하면 다음과 같다.
void insert_node(ListNode **phead, ListNode *p, ListNode *new_node)
{
if(*phead = Null){ //리스트가 공백인 경우(1)
new_node->link = NULL;
*phead = new_node;
}
else if(p == NULL){ //첫번째 노드로 삽입하는 경우(2)
new_node->link = *phead;
*phead = new_node;
}
else{
new_node->link = p->link;
p->link = new_node;
}
}
remove_node의 구현(삭제)
remove_node 함수의 인자는 다음과 같다.
void remove_node(ListNode **phead, ListNode *p)
- phead : 헤드포인터의 포인터
- p : 삭제될 노드의 선행 노드를 가리키는 포인터
삭제에 경우에도 노드의 2가지 경우를 먼저 생각해야 한다.
- p가 NULL인 경우 : 선행 노드가 없다는 뜻으로 맨 앞의 노드를 삭제하는 경우이다.
removed = head
head = head->link
free(removed)
- p가 NULL이 아닌 경우 : p가 가리키는 그 다음 노드를 삭제하면 된다.
removed = p->link
p->link = removed->link
free(removed)
위 내용을 코드로 구현하면 다음과 같다.
void remove_noed(ListNode **phead, ListNode *p)
{
ListNode *removed;
if(p == NULL){ //맨앞의 노드를 삭제하는 경우(1)
removed = *phead;
*phead = (*phead)->link;
}
else{ //중간 노드를 삭제하는 경우(2)
removed = p->link;
p->link = removed->link;
}
free(removed);
}
Traversal - 방문함수의 구현
리스트상의 모든 노드를 한번씩 순차적으로 방문하는 연산이다.
void display(ListNode *head)
{
ListNode *p = head;
while(p != NULL){
printf("%d->", p->data);
p = p->link;
}
printf("\n");
}
seach 함수의 구현(탐색)
리스트상 특정한 데이터 값을 갖는 노드를 찾는 동작이다.
ListNode *search(ListNode *head, int x)
{
ListNode *p = head;
while(p != NULL){
if(p->data == x) return p; //탐색 성공
p = p->link;
}
return p; // 탐색 실패시 null값 반환
}
[참고자료]
교재: C언어로 쉽게 풀어쓴 자료구조
