[CVAE 리뷰]
기본적인 Simple Autoencoder 와 Variational Autoencoders 에대한 비교
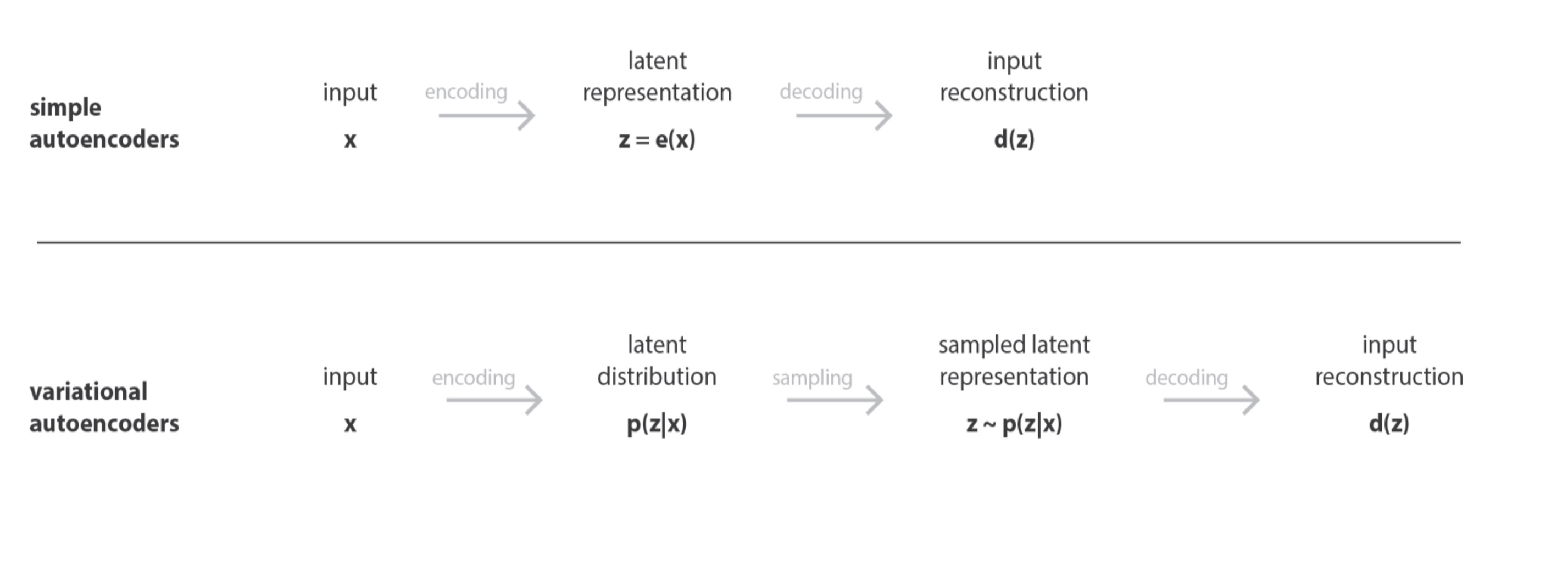
x 라는 input 에 대하여 latent distribution prior x에 대하여 x 잠재변수 z의 확률을 만든다. -> 그 뒤 z 를 sampling 한 후 -> input reconstruction 을 실행한다.
예시)
그렇다면, 일반적인 generative model과 vae 의 기본적인 구조의 차이를 살펴보자,
Generative model - p(X) 라는 최종적인 값을 구하기 위함.
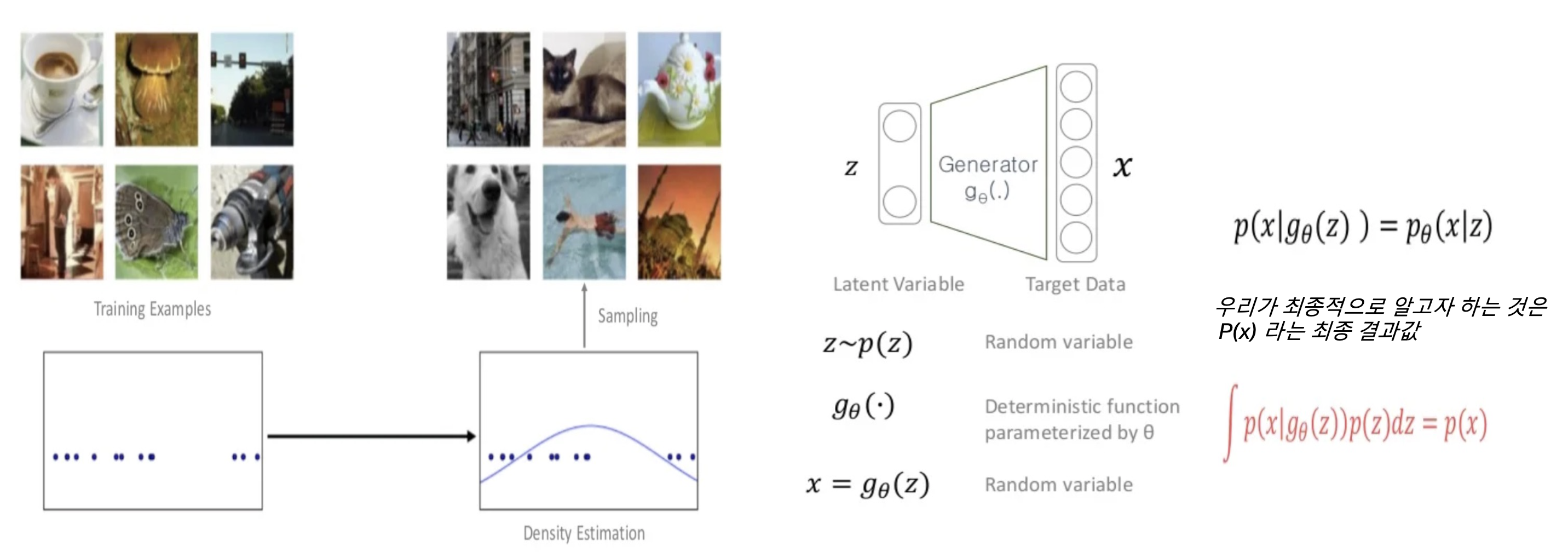
모델 VAE의 경우에는 출력값이 있을때, 우리가 원하는 정답 x가 나올 확률이 높길바란다. -> 이것의 의미는 x의 likelihood 최대화하는 확률분포를 찾는것 maximize 가 핵심
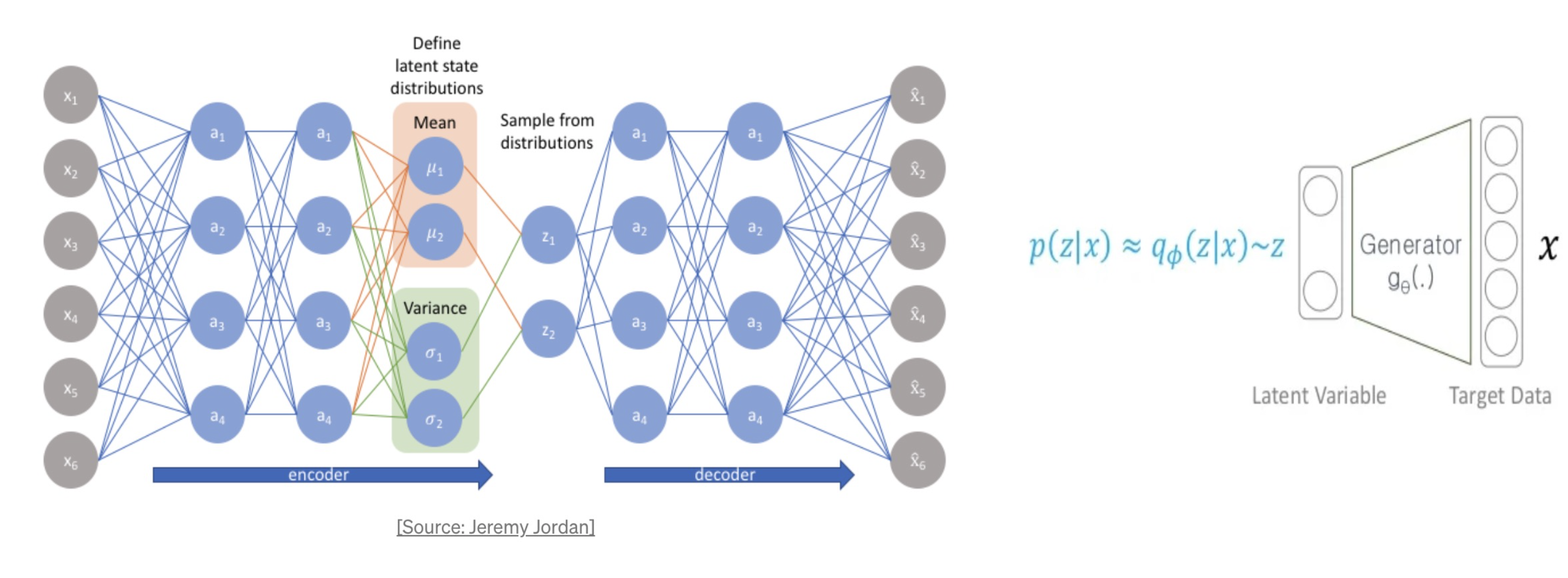
어떻게 학습?
위그림 참조 : https://di-bigdata-study.tistory.com/4
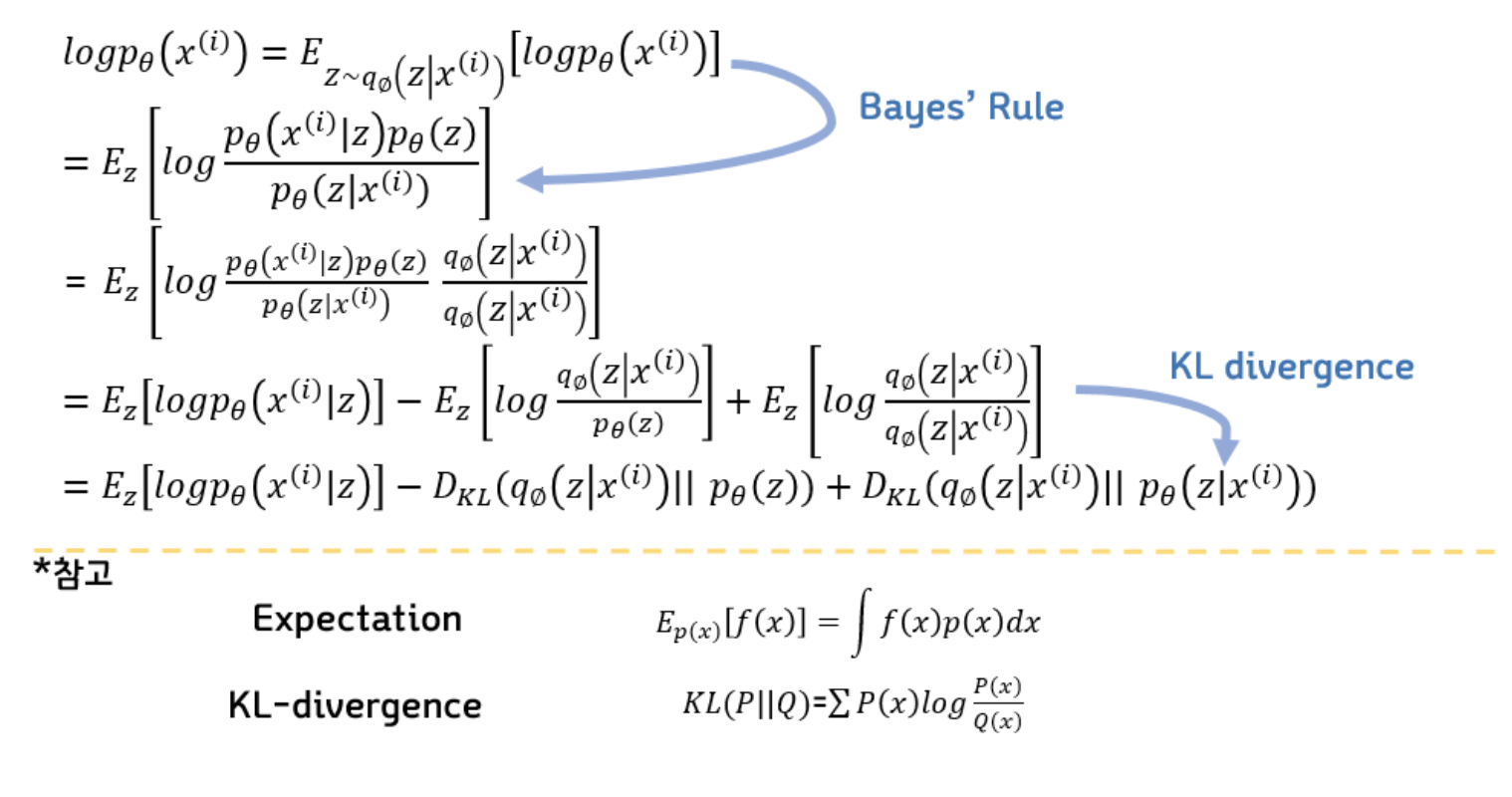
(1) 먼저 $ 를 expectation 값에 넣는다.
(2) Bayes Rule 를 이용하여 분해
(3) KL divergence 의 정의를 활용하여 maximize 하는 parameter theta를 찾고, likelihood를 maximize 하는 parameter를 찾을 수 있다.
(4) ELBO의 경우에는 p(x|z)와 q(z|x) 사이의 negative cross entropy와 같다. 그렇기 때문에 이는 encoder와 decoder가 autoencoder처럼 reconstruction을 잘 할 수 있게 만들어주는 error라고 할 수 있기 때문에 reconstruction error라고 부른다.
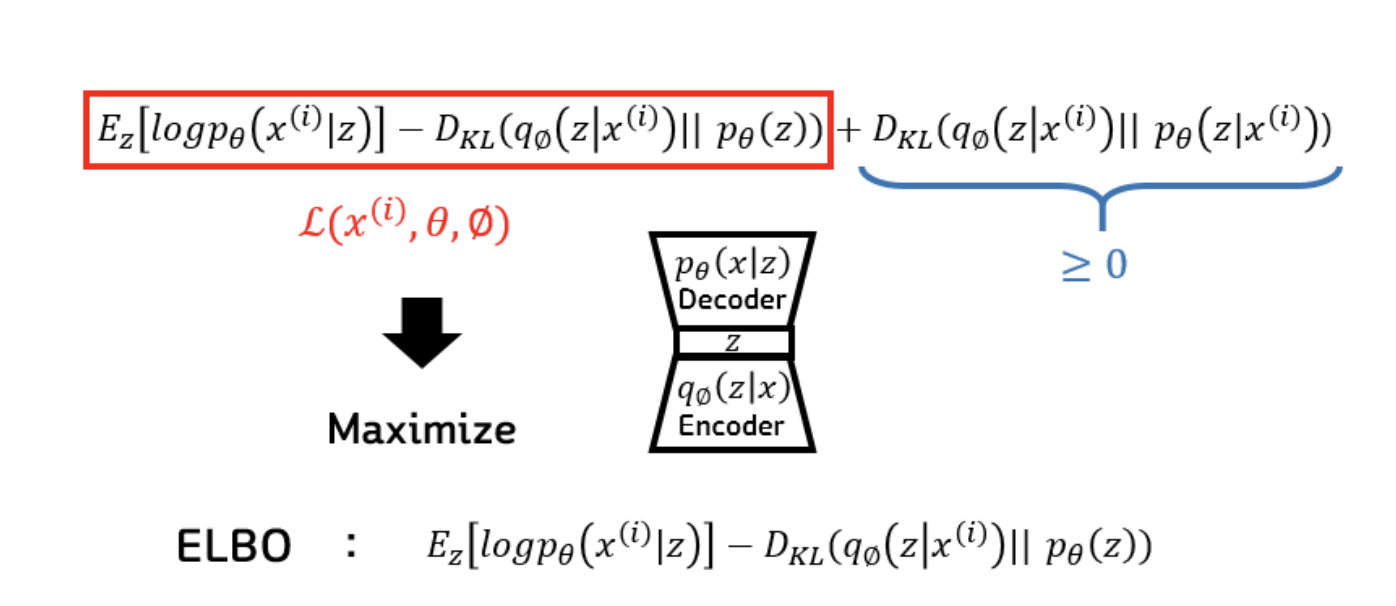
결론 : 학습을 위해서는 미분을 하고 gradient(기울기)값을 구해야 하는데 intractable한 pθ(x)를 tractable하게 유도하여 lower bound 문제로 정의해 주는 것입니다
lower bound인 이유는 첫 번째 term과 두 번째 term의 값의 합 이상으로 MLE를 구해야 하기 때문입니다. (마지막 term은 0이상이니깐!)
위의 식을 구조로 바꾸면?
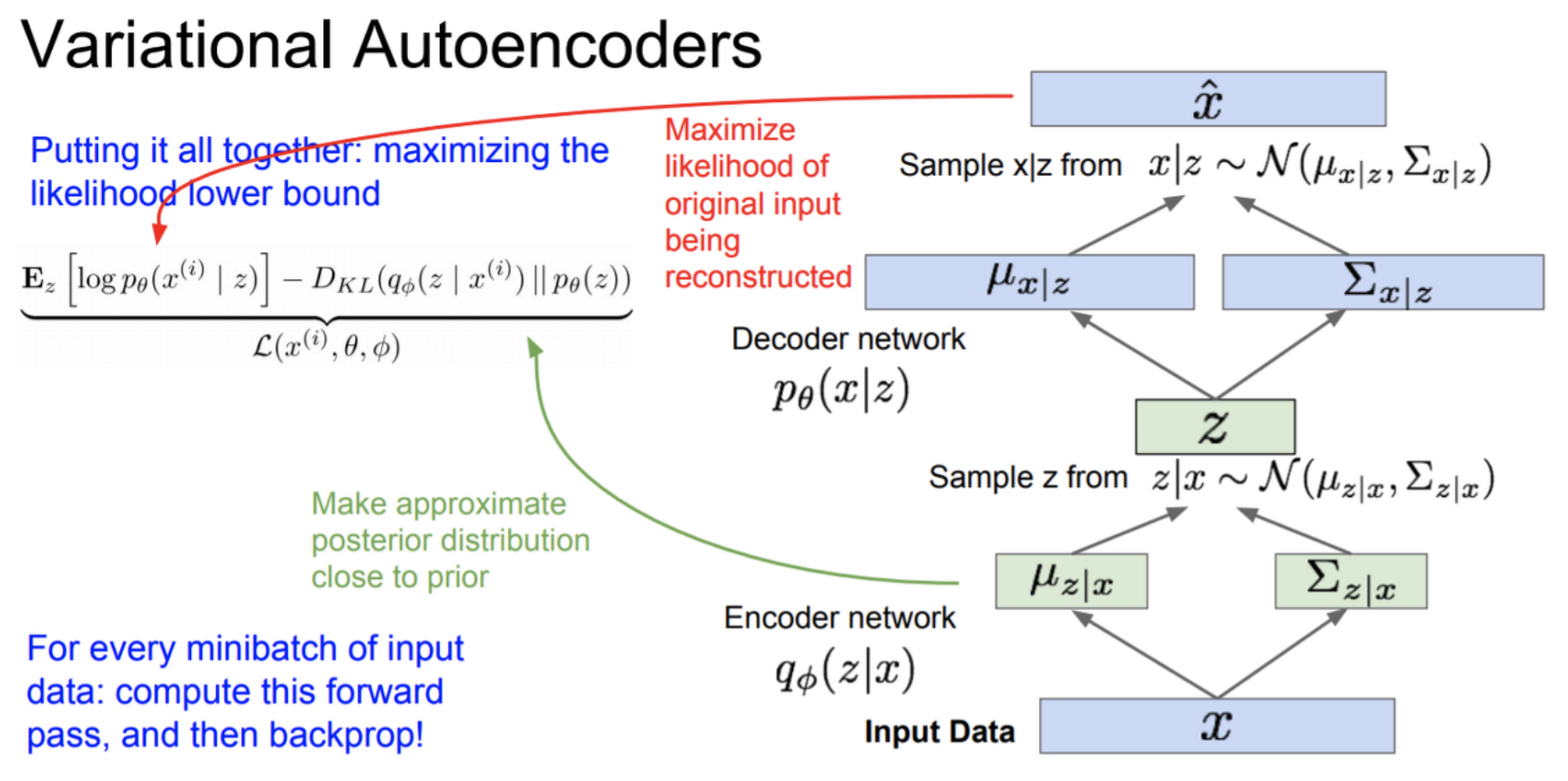
위그림 참조: cs231n_2017_lecture13
부제 : reparameterization trick
샘플링을 최적화 하는 방법 중에 하나 (미분 가능하게 바꿈!)
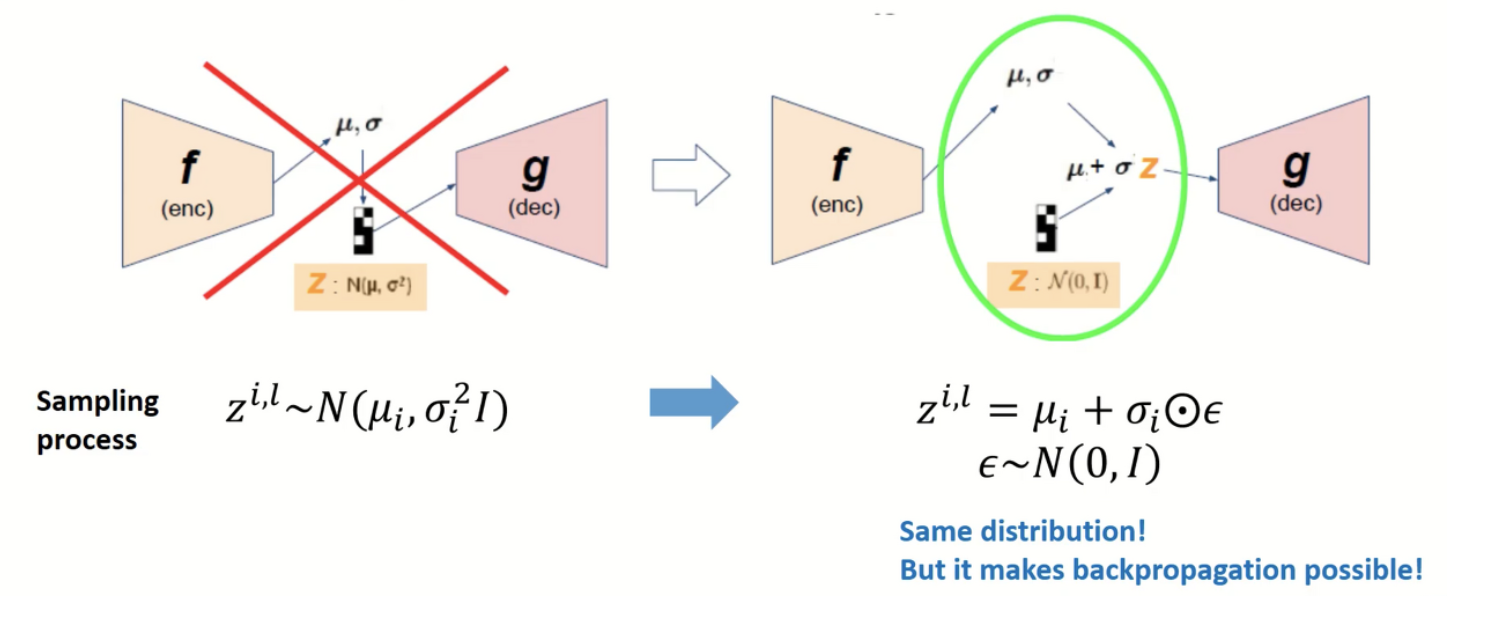
왜해야하지?
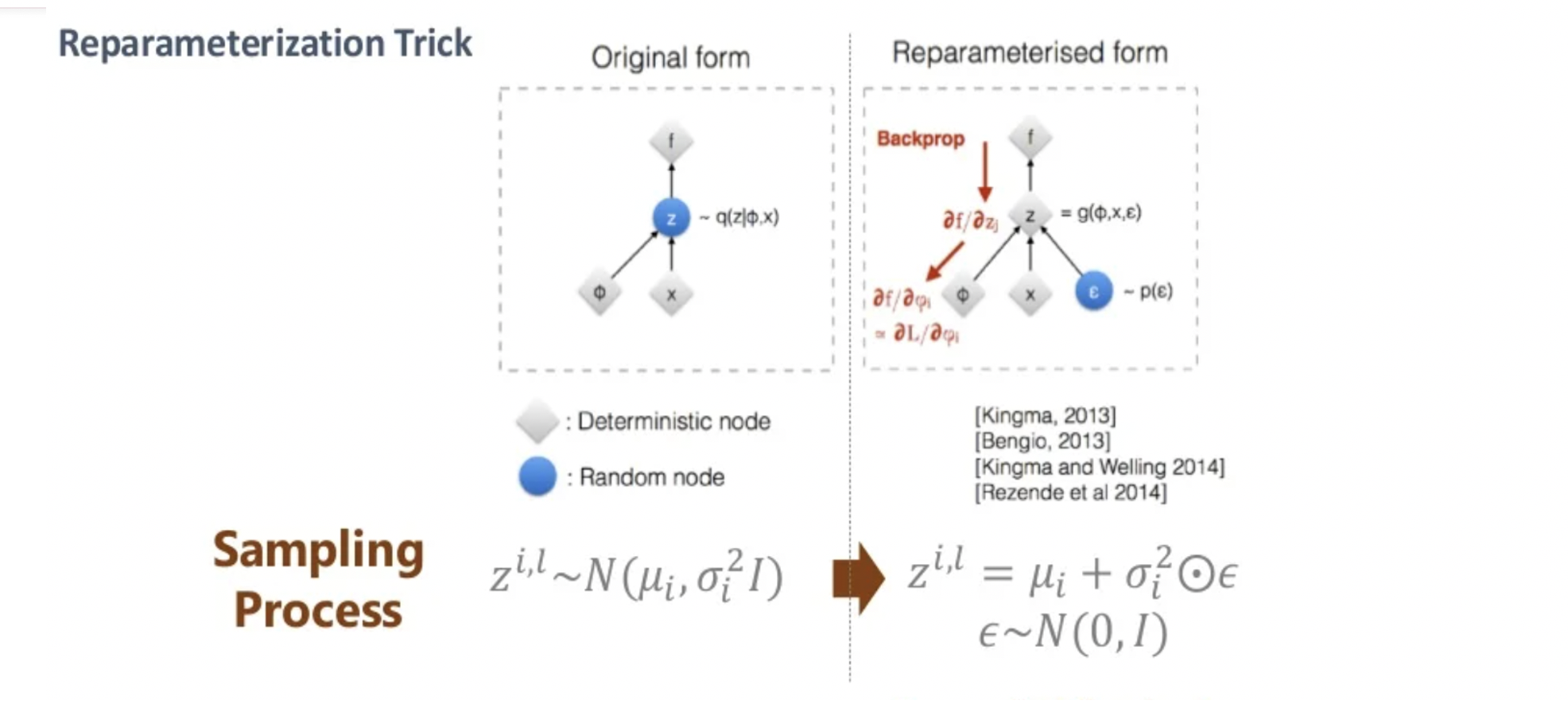
Encoder 와 연결시켜서 학습시켜주어야 한다!!
간단한 CVAE vs VAE 의 차이
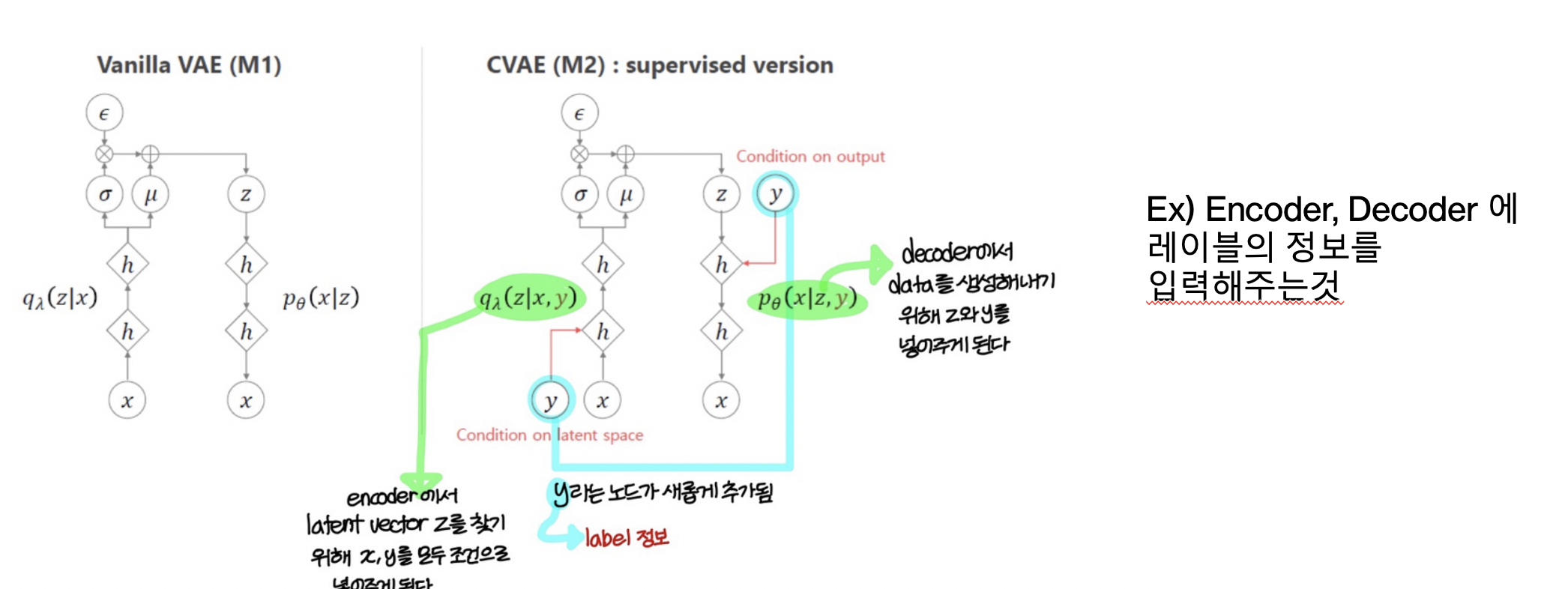
Sampling 할때 어떤 숫자가 샘플링 될지 제어할 수 없으니까 CVAE에 label 을 함으로써 해결가능하다
앞서 살펴본 VAE는 latent space가 임의로 sampling되면 VAE는 어떤 숫자가 샘플링될지 제어할 수 없다.
하지만 CVAE는 생성할 숫자의 조건(one-hot lable)을 도입함으로써 이 문제를 해결할 수 있다.
이 조건은 Encoder와 Decoder에 모두 제공된다 .
Reference :
1)https://huidea.tistory.com/296
2) https://deepinsight.tistory.com/121
