[SHAP 논문 리뷰]
A Unified Approach to Interpreting Model Predictions
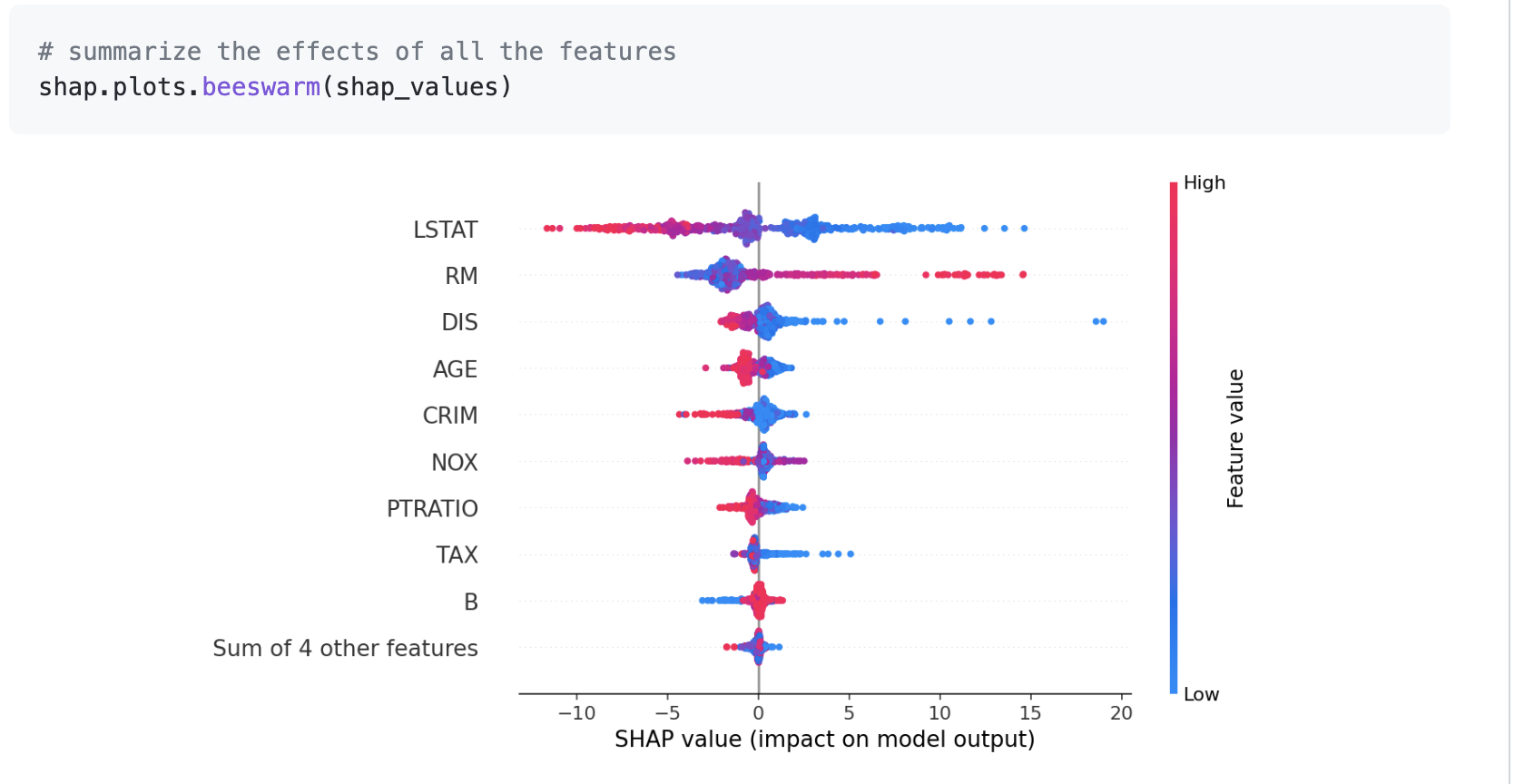
(일반적인 shap 그래프) https://github.com/slundberg/shap
설명 가능한 인공 지능의 중요성
1) 대부분 예측력이 높은 ML 모델들은 black box model
-> 사용자의 질문이 Model이 내린 예측 및 판단의 근거가 인간과 동일한지 알 수 없음.
-> 대안책 : Model Agnostic(종류에 구애받지 않는) Methods

SHAP (SHapley Additive exPlanations) 같은 feature 중요성을 찾아내는 방법을 통해서 모델을 설명가능할 수 있음
기본적인 용어:
f: 원래 블랙박스 모델
g: f를 설명하기 위한 모델
x: f에 들어가는 input
x': g 에 들어가는 x의 다른 input
hx : x'을 x로 매핑하는 함수 , 즉 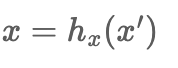
additive feature attribute methods 설명
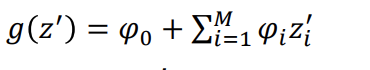
g(z') -> 전체를 합한 점수!
z' -> 개개인
파이값 -> 개개인의 점수
위의 식의 문제점
1) surrogate 모델에서 x를 뽑더라도 랜덤성에 의해 최종의해 최중 구해지는 내부변수 파이가 달라지게 된다.
2) NUll feature 0 에 대해서는 0으로 취급되지 않는다.
shapley는 이런 addivity/ consistency / missingness의 특성을 해결하고자 한다.
예시

1) importance of i = f(with i ) - f(without i)
2) Shapley Value for player(i) , in game f = Average over all player'subsets
3) subset에 대한 모든 순열조합을 계산해야한다.
DEFINITION: shap value ϕi의 계산식
ϕi는 기여도 이고, S⊂F 를 만족하는 모든 set s 에대하여 feature i 가 있을때와 없을때의 score의 차이 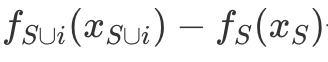 룰 기여분으로 계산하고, 부분 집합 S에 대하여, 전체 집합 F를 줄 세우는 경우의 수 ∣F∣!를 S를 줄세우는 경우의 수 ∣S∣!와 Feature
룰 기여분으로 계산하고, 부분 집합 S에 대하여, 전체 집합 F를 줄 세우는 경우의 수 ∣F∣!를 S를 줄세우는 경우의 수 ∣S∣!와 Feature
i와 S 를 제외한 나머지를 줄 세우는 경우의 수 (∣F∣−∣S∣−1)!
으로 가중평균을 한다.

따라서, addivity/ consistency / missingness 문제점을 해결하기 위한 방법은 아래의 식 뿐! (Theorem 1)
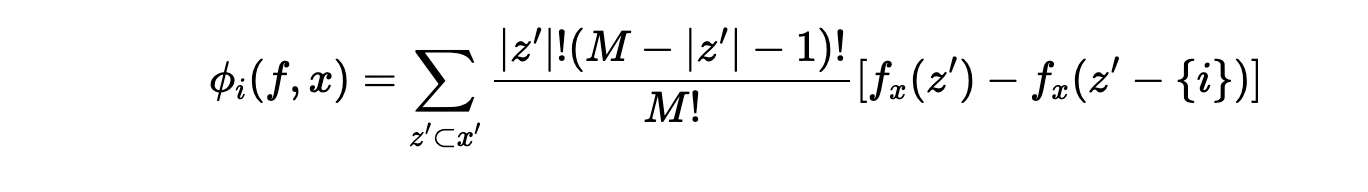
SHAP 변수 정의는 어떻게?

다음으로 kernel SHAP
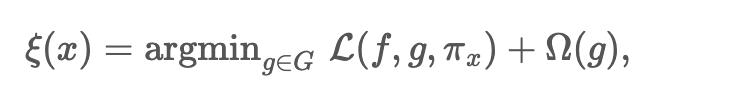
기본적으로 LIME 은 다음과 같은 식을 사용하여 EXPlanation model 을 계산한다 .
여기서 L, pi, Ω 를 무엇으로 정하는지가 관건이다.
이를 토대로 addivity/ consistency / missingness 를 해결할 수 있는 공식을 구한다.
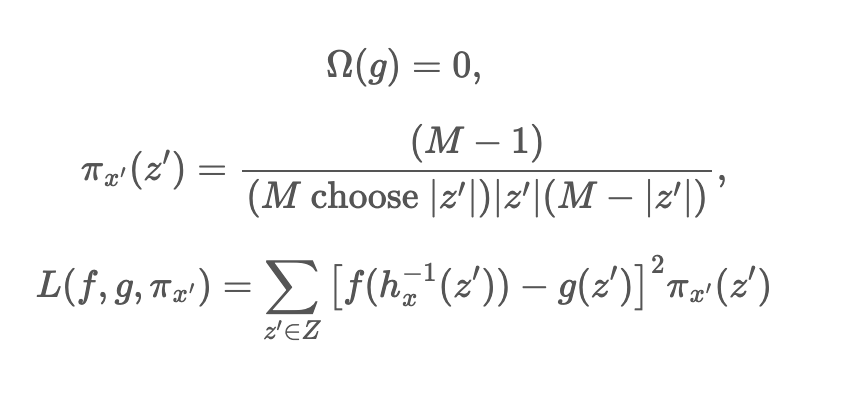
SHAP variations
(1) KernelSHAP : Truly model-agnostic/ Relatively Slow / Approximate Calculation
(2) TreeSHAP : for Tree models/ Fast / Exact calculation
(3) DeepSHAP, GradientSHAP : for deep learning model
참고 문헌:
1. MT Ribeiro et al. (2016). “LIME: “Why Should I Trust You? : Explaining the Predictions of Any Classifiers”. ACM-KDD
2. Scott Lundberg et al. (2017). “A Unified Approach to Interpreting Model Predictions”. NeurIPS.
3.http://dmqm.korea.ac.kr/activity/seminar/297
