[논문리뷰] GAN
기본개념

특징 1: Class Y에서 특징을 뽑아낸다.
특징 2: The generator produces fake data (fake 데이터 생성)
특징 3: The generator takes as input noise (노이즈 같이 학습)
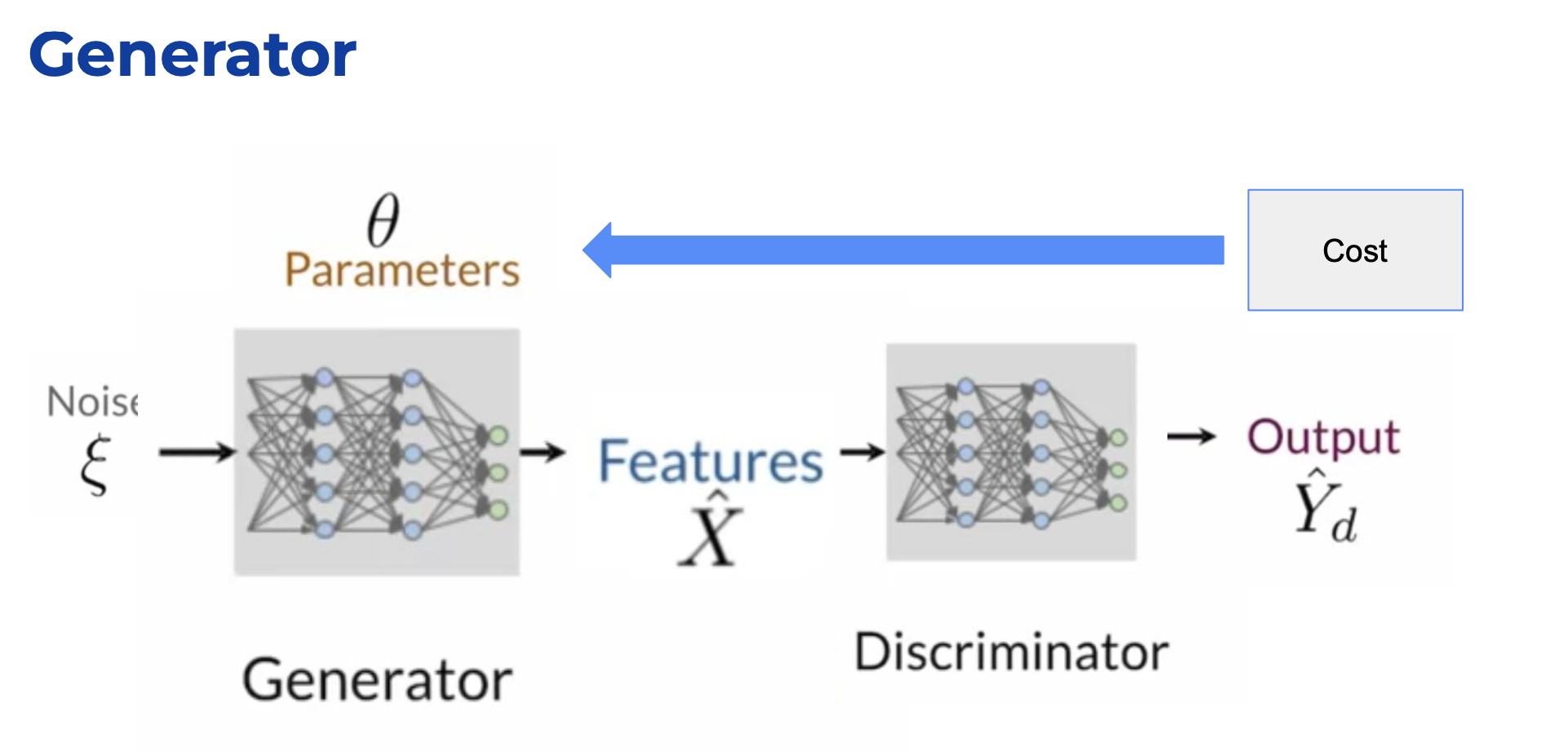
위 그림이 가장 기본적인 구조라고 할 수 있음.
Reference : https://arxiv.org/abs/1406.2661v1
실제 논문에서 이야기하는 학습하는 구조. 
녹색 -> 생생자가 만들어 내는 확률분포
파란색 점선 -> 판별자의 확률분포
마지막 (d) 의 단계에서는 real/fake 데이터가 거의 비슷한 선상에 위치하게 된다.
어떻게 cost를 학습하는 거지?
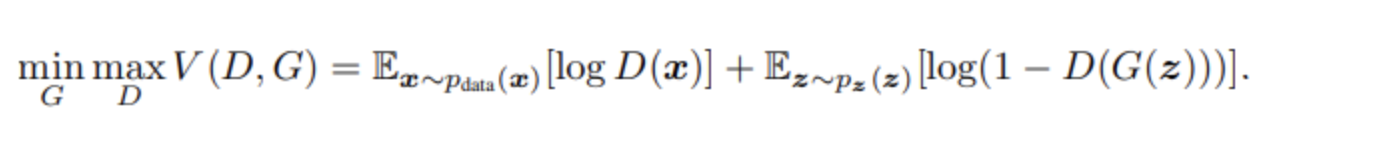
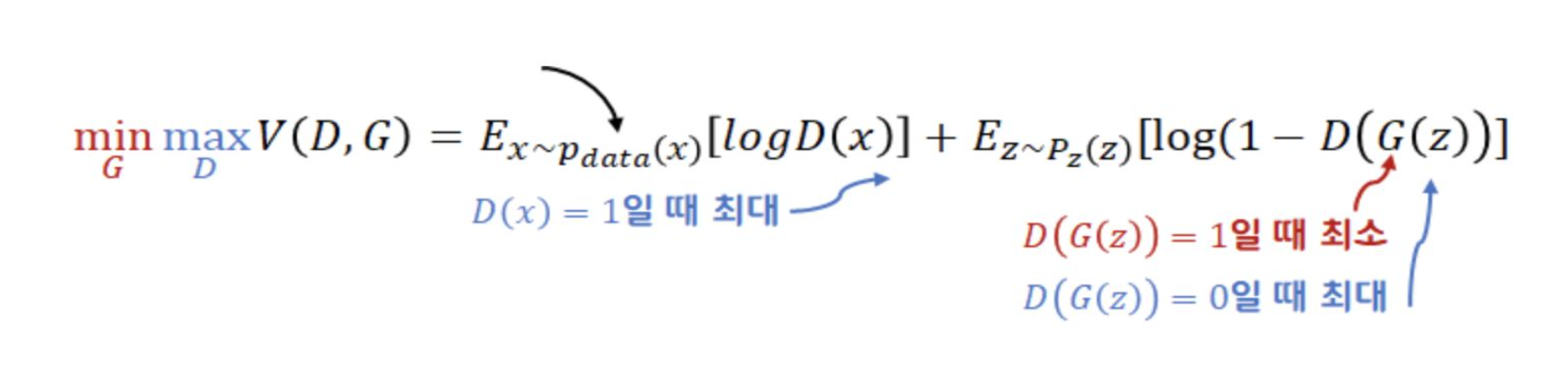
이것의 간단한 원리는 generator 는 minimize distance ,
판별자는 Maximize distance 한값으로 cost를 계산한다.
수식으로 하변 처음에는 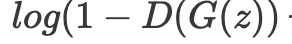 포화가 된다 왜? -> 이미 너무 마르기 때문에 reject! 하지만,
포화가 된다 왜? -> 이미 너무 마르기 때문에 reject! 하지만, 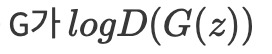 를 최대화 하도록 학습 시킬 수 있다.
를 최대화 하도록 학습 시킬 수 있다.
실제 수식으로 정의된 알고리즘

증명1 : Global Optimality
무엇을 ? P(G)가 P(data)로 수렴하는지에 대한 증명과정
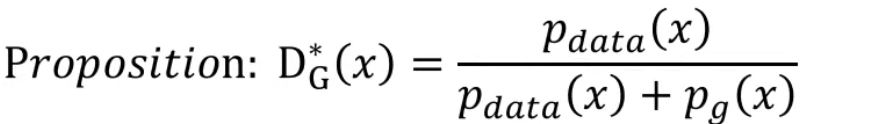

G가 고정되어 있을때 , D의 optimal 포인트가 P(data)로 수렴하는지에 대한 증명.

어려운 수식보고 겁먹지말고, 위의 공식처럼 똑같은 구조라고 생각하면 된다.
function y 에 대하여 a/ a+b 에서 극댓값을 가질 수 있다고 생각된다.
증명2 : Global Optimality
그렇다면 global optimal 포인트는 어디인가?!
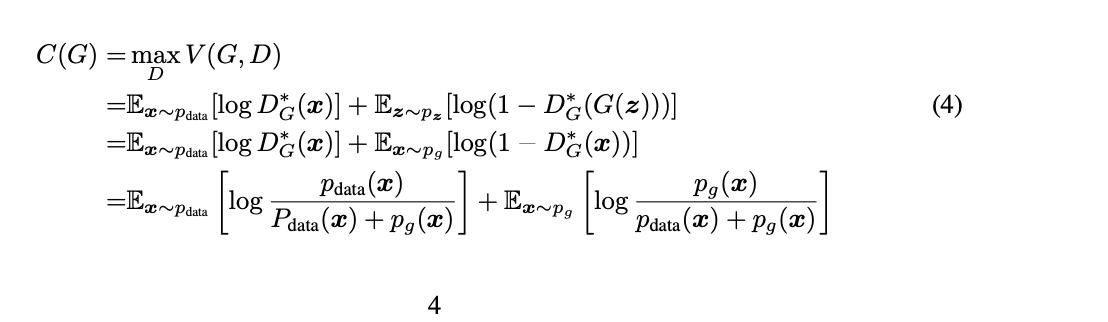
위의 공식대로하면, 위의 생성자와 실제 데이터가 극대화될때, pt = pdata가 된다.
즉, D가 이미 최적이라는 가정 하에, GAN이 목적함수를 최적화한다는 과정은
P(data) 와 P(G) 사이의 Jensen-Shannon divergence(JSD)를 최소화하는 것과 같다.
JSD는 Kullback–Leibler divergence의 대칭(symmetrized and smoothed) 버전이다. 그래서 GAN은 KLD를 최소화하는 것이라고 말하기도 한다.
실험

ㅗ
장/단점
장점 1) 기존의 어떤 방법보다고 가장 실제에 가까움
2) 확률 분포를 명확히 정의하지 않아도 fake데이터를 만들어낸다.
3) MCMC 를 사용하지 않고, backprop 을 이용하여 gradient를 구할 수 있음.
4)
단점 1) 평가가 매우 주관적이다.
2) 어떤 데이터가 생성될지 예측하기 어려움
3) Helvetica scenario 를 피하기 위해 G는 D가 업데이트 하기 전에 학습을 너무 많이 하면 안된다.
