4.1 Pandas란?

예전에 R이 Python보다 인기가 많았던 이유 중에 하나는 dataframe인데 이를 파이썬이 pandas라는 이름으로 베껴옴
numpy와 pandas는 뭐가 다를까?
pandas는 numpy의 문법으로 만들어져서 numpy의 기능들이 기본적으로 pandas에 다 있다고 보면되고 거기에 추가로
- 외부 데이터 읽고 쓰기
- 정리된 데이터 새로운 파일에 저장
- 데이터 시각화
등의 편리한 기능이 추가 되었다고 보면 된다
그리고 표 형식의 데이터를 numpy보다 pandas가 훨씬 잘한다
4.2 DataFrame 소개
DataFrame = 표 형식의 자료를 담는 자료형
표에서
column은 데이터의 특징을 담고
row는 레코드를 부름
4.3 DataFrame 사용해 보기
import pandas as pd
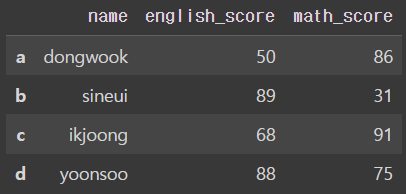
two_dimensional_list = [['dongwook',50,86],['sineui',89,31],['ikjoong',68,91],['yoonsoo',88,75]] #2차원 배열 지정
my_df = pd.DataFrame(two_dimensional_list,columns = ['name','english_score','math_score'],index =['a','b','c','d'])
my_dfㄴ 원래 numpy에서는 np.array()로 했지만 pandas에서는 pd.DataFrame으로 지정해준다. 행을 나타내는 columns와 원래 열을 나타내는 row를 쓰지 않고 pandas에서는 index를 쓰기 때문에 각각 지정해주었다.
output
type(my_df)
my_df.columns # 행에 무슨 값들이 있는지 추출
my_df.index # 열에 무슨 값들이 있는지 추출
my_df.dtypes # 해당 열에 저장된 값들의 자료형을 추출output
pandas.core.frame.DataFrame
Index(['name', 'english_score', 'math_score'], dtype='object')
Index(['a', 'b', 'c', 'd'], dtype='object')
name object # pandas에서는 문자열을 object라고 한다
english_score int64
math_score int64
dtype: object4.4 DataFrame을 만드는 다양한 방법
From list of lists, array of arrays, list of series
2차원 리스트나 2차원 numpy array로 DataFrame을 만들 수 있고 심지어 pandas Series를 담고 있는 리스트로도 DataFrame을 만들 수 있다
import numpy as np
import pandas as pd
two_dimensional_list = [['dongwook',50,86],['sineui',89,31],['ikjoong',68,91],['yoonsoo',88,75]]
two_dimensional_array = np.array(two_dimensional_list)
list_of_series = [
pd.Series(['dongwook',50,86]),
pd.Series(['sineui',89,31]),
pd.Series(['ikjoong',68,91]),
pd.Series(['yoonsoo',88,75])
]
df1 = pd.DataFrame(two_dimensional_list)
df2 = pd.DataFrame(two_dimensional_array)
df3 = pd.DataFrame(list_of_series)
print(df1)output
0 1 2
0 dongwook 50 86
1 sineui 89 31
2 ikjoong 68 91
3 yoonsoo 88 75From dict of lists, dict of arrays, dict of series
파이썬 딕셔너리로도 DataFrame을 만들 수 있다. 사전의 key로는 column의 이름을 쓰고, 그 column에 해당하는 리스트, numpy array 혹은 pandas Series를 사전의 value로 넣어주면 된다
names = ['dongwook','sineui','ikjoong','yoonsoo']
english_scores = [50,89,68,88]
math_scores = [86,31,91,75]
dict1 = {
'name':names,
'english_score':english_scores,
'math_score':math_scores
}
dict2 = {
'name':np.array(names),
'english_score':np.array(english_scores),
'math_score':np.array(math_scores)
}
dict3 = {
'name':pd.Series(names),
'english_score':pd.Series(english_scores),
'math_score':pd.Series(math_scores)
}
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
df3 = pd.DataFrame(dict3)
print(df1)output
name english_score math_score
0 dongwook 50 86
1 sineui 89 31
2 ikjoong 68 91
3 yoonsoo 88 75From list of dicts
리스트가 담긴 딕셔너리가 아니라 딕셔너리가 담긴 리스트로도 DataFrame을 만들 수 있음
my_list = [
{'name':'dongwook','english_score':50,'math_score':86},
{'name':'sineui','english_score':89,'math_score':31},
{'name':'ikjoong','english_score':68,'math_score':91},
{'name':'yoonsoo','english_score':88,'math_score':75}
]
df = pd.DataFrame(my_list)
print(df)output
name english_score math_score
0 dongwook 50 86
1 sineui 89 31
2 ikjoong 68 91
3 yoonsoo 88 754.5 실습 스타들의 생일은 언제?
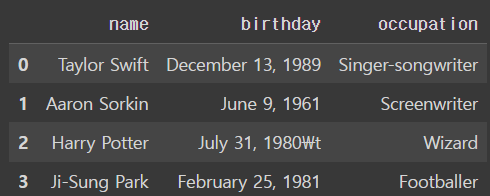
아래와 같은 결과가 나오도록 DataFrame을 만들고 출력해 보세요.
column은 name, birthday, occupation 총 3개입니다.

code
names = ['Taylor Swift','Aaron Sorkin','Harry Potter','Ji-Sung Park']
birthdays = ['December 13, 1989','June 9, 1961','July 31, 1980 ','February 25, 1981']
occupations = ['Singer-songwriter','Screenwriter','Wizard','Footballer']
dict1 = {
'name':names,
'birthday':birthdays,
'occupation':occupations
}
df = pd.DataFrame(dict1)
dfoutput
4.6 pandas의 데이터 타입
pandas DataFrame에는 다양한 종류의 데이터를 담을 수 있는데, dtypes를 사용해서 각 column이 어떤 데이터 타입을 보관하는지 확인할 수 있다
import pandas as pd
two_dimensional_list = [['dongwook',50,86],['sineui',89,31],['ikjoong',68,91],['yoonsoo',88,75]]
my_df = pd.DataFrame(two_dimensional_list, columns = ['name','english_score','math_score'],index = ['a','b','c','d'])
print(my_df.dtypes)output
name object
english_score int64
math_score int64
dtype: objectㄴ 'name' column은 object라는 데이터 타입을, 'english_score'와 'math_score' column은 int64라는 데이터타입을 보관하는 것이다 !
= 한 column 내에서는 모든 값이 동일한 데이터 타입임
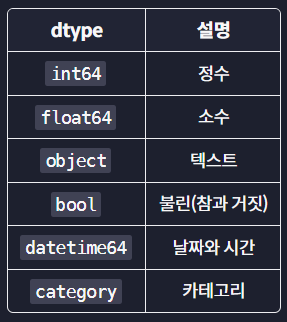
pandas에 담을 수 있는 dtype 종류
4.7 pandas로 데이터 읽어들이기
csv = 'Comma-Separated Values'의 약자로 쉼표로 구분된 값을 가지는 텍스트 파일 형식을 말함 ! (csv 파일은 간단하고 효율적인 방법으로 표 형태의 데이터를 저장하는데 사용
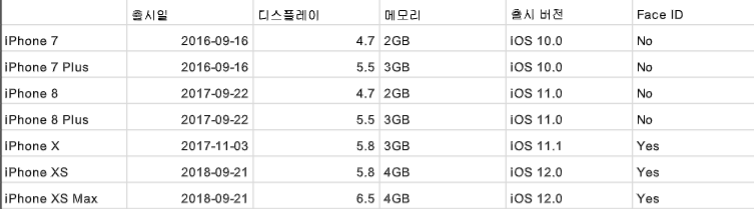
iphone.csv파일을 깔아줬다
데이터를 불러오는 read_csv를 사용해서
import pandas as pd
iphone_df = pd.read_csv('drive/MyDrive/dataScience/data/iphone.csv')
iphone_dfoutput
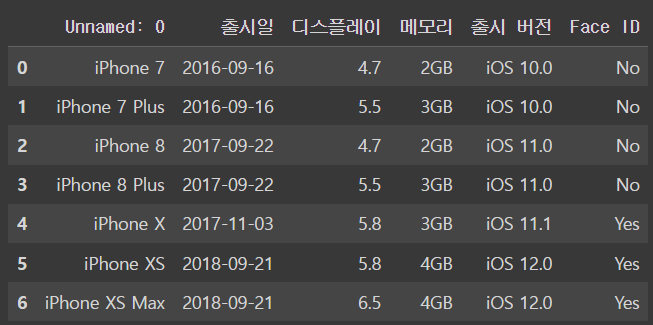
ㄴ여기서 봐야할 점은 read_csv를 쓰면 csv파일의 첫번째 줄이 자동적으로 헤더로 들어간다는 것이당
그리고 csv 파일에서 특정 column을 row이름으로 지정이 가능한데
import pandas as pd
iphone_df = pd.read_csv('drive/MyDrive/dataScience/data/iphone.csv',index_col=0)
iphone_df이렇게 뒤에 index_col=0을 붙이면
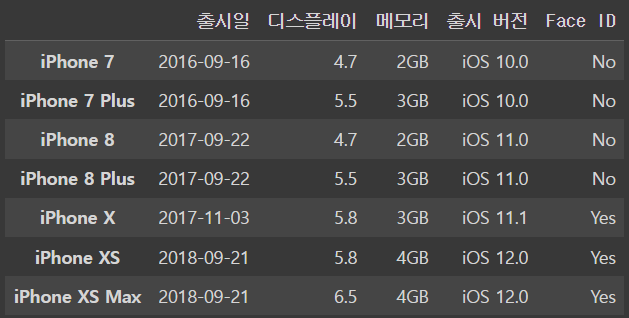
0번 column이 row가 되는 것이다
데이터 타입을 알아보자면
type(iphone_df)output
pandas.core.frame.DataFrame이것이당
4.8 실습 가장 인기 있는 아기 이름은?
아기의 성별과 어머니의 인종에 따른, 뉴욕에서 가장 인기 있는 아기 이름이 무엇인지 조사를 해 봤습니다.
조사 결과가 data 폴더의 popular_baby_names.csv라는 파일에 담겨 있는데요. 안에 있는 정보를 DataFrame으로 읽어 들이고, DataFrame을 출력해 주세요.

code
df = pd.read_csv('drive/MyDrive/dataScience/data/popular_baby_names.csv')
dfoutput
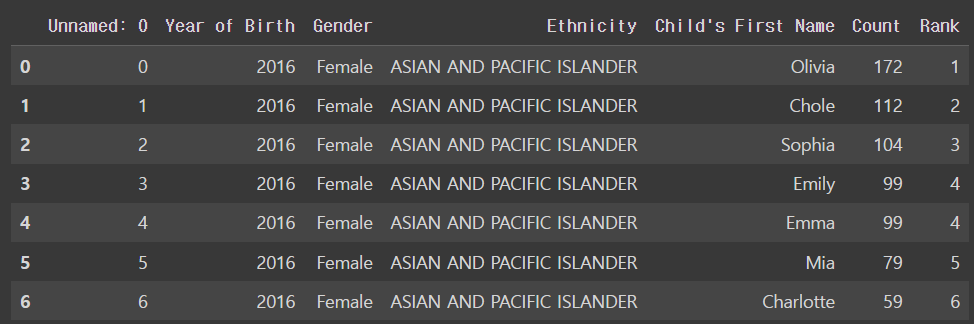
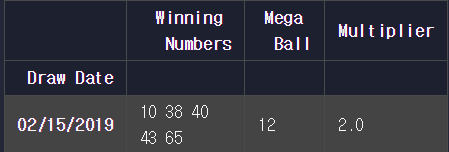
4.9 실습 메가밀리언 로또 당첨 번호
‘메가밀리언’은 ‘파워볼’과 더불어 미국에서 양대산맥을 이루는 복권입니다. 당첨될 확률이 약 3억분의 1 정도로 굉장히 낮은 대신, 당첨시 금액이 어마어마하죠. 2018년에는 한 명이 무려 1.8조원을 가져가기도 했습니다.
메가밀리언 측에서 2002년부터 현재(2/15/19)까지의 당첨 번호가 담긴 mega_millions.csv 파일을 공개했는데요. 이 데이터를 DataFrame에 넣어 봅시다.
날짜(Draw Date)가 이 DataFrame의 인덱스가 되도록 해 주세요!
code
import pandas as pd
df = pd.read_csv('data/mega_millions.csv', index_col=0)
dfoutput