
5.1 DataFrame 인덱싱 I
일단 iphone.csv 파일을 불러와줍니당
import pandas as pd
iphone_df = pd.read_csv('drive/MyDrive/dataScience/data/iphone.csv',index_col=0)
iphone_dfoutput
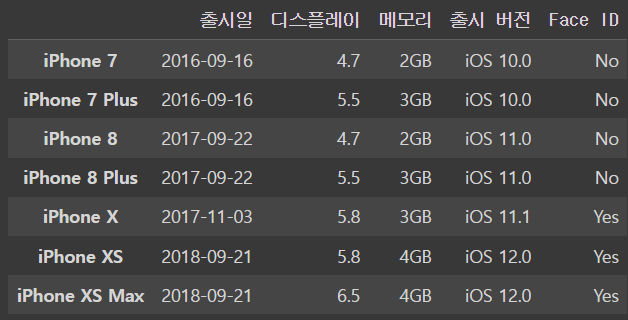
.loc은 pandas에서 data frame이나 Series에서 특정 행과 열을 선택하기 위해 사용되는 인덱싱 방법중 하나이다!
iphone_df.loc['iPhone 8','메모리'] # row를 쓰고 column을 써야함output
2GB해당하는 열의 값을 다 가져오고 싶으면
iphone_df.loc['iPhone X', :]output
출시일 2017-11-03
디스플레이 5.8
메모리 3GB
출시 버전 iOS 11.1
Face ID Yes
Name: iPhone X, dtype: object이렇게 해도 위와 동일하다
iphone_df.loc['iPhone X']output
출시일 2017-11-03
디스플레이 5.8
메모리 3GB
출시 버전 iOS 11.1
Face ID Yes
Name: iPhone X, dtype: object데이터 타입은
type(iphone_df.loc['iPhone X'])output
pandas.core.series.Seriesㄴ Series인 이유는 Series가 일차원 자료형이기 인데 loc으로 한 줄만 받아왔으므로 Series가 나오는 것이다
해당하는 행의 값을 다 받아오고 싶다면
첫 번째에 콜론을 쓰고 두 번째에 해당하는 행을 써주면 된다
iphone_df.loc[:,'출시일']output
iPhone 7 2016-09-16
iPhone 7 Plus 2016-09-16
iPhone 8 2017-09-22
iPhone 8 Plus 2017-09-22
iPhone X 2017-11-03
iPhone XS 2018-09-21
iPhone XS Max 2018-09-21
Name: 출시일, dtype: object이렇게 해도 위와 동일하다
iphone_df['출시일']ㄴ 열을 받아올 때와 차이점은 .loc을 안 쓴다는 것이다 !!
output
iPhone 7 2016-09-16
iPhone 7 Plus 2016-09-16
iPhone 8 2017-09-22
iPhone 8 Plus 2017-09-22
iPhone X 2017-11-03
iPhone XS 2018-09-21
iPhone XS Max 2018-09-21
Name: 출시일, dtype: object타입은 Series로 동일하다
type(iphone_df['출시일'])output
pandas.core.series.Series5.2 (실습) 방송사 시청률 받아오기 I
지난 시간에 DataFrame에서 원하는 부분을 선택하는 인덱싱을 배웠는데요. 이를 통해서 값을 찾는 연습을 해봅시다.
2016년도에 KBS방송국의 시청률을 찾아봅시다.
데이터를 한번 잘 살펴보고 어떻게 값을 찾아야 할지 고민해보세요!
code
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[2016,'KBS']5.3 (실습) 방송사 시청률 받아오기 II
이번에는 DataFrame에서 한 줄을 찾는 연습을 해보겠습니다.
JTBC의 시청률을 확인하려면 어떻게 해야 할까요?
code
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df['JTBC']5.4 (실습) 방송사 시청률 받아오기 III
이번에는 DataFrame에서 여러 줄을 찾는 연습을 해보겠습니다. SBS와 JTBC의 시청률만 확인하려면 어떻게 하면 될까요?
code
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df[['SBS','JTBC']]!! 여러개의 열을 받아오고 싶으면 df[['a','b']] 형식으로 작성하면 된다 !!
ex) iphone_df[['출시일','메모리']]
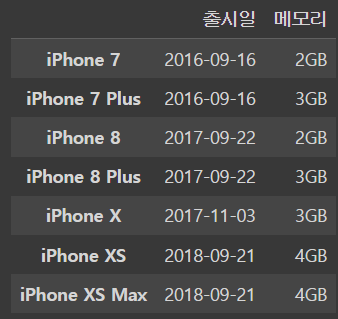
5.5 카드사 고객 분석
데이터의 중요성을 깨달은 “삼송카드”와 “현디카드”가 협업을 하기로 결정했습니다.
두 카드사는 사람들이 요일별로 지출하는 평균 금액을 “요일”, “식비", “교통비”, “문화생활비”, “기타” 카테고리로 정리해서 우리에게 공유해 주기로 했는데요. 각각 samsong.csv 파일과 hyundee.csv 파일을 보냈습니다.
두 회사의 데이터를 활용해서, 사람들의 요일별 문화생활비를 분석해보려 합니다. 아래와 같은 형태로 출력이 되도록 DataFrame을 만들어보세요.
code
days = ['MON','TUE','WED','THU','FRI','SAT','SUN']
samsongs = [4308,7644,5674,8621,23052,15330,19030]
hyundees = [5339,3524,5364,9942,33511,19397,19925]
dict1 = {
'day':days,
'samsong':samsongs,
'hyundee':hyundees
}
df = pd.DataFrame(dict1)
dfoutput
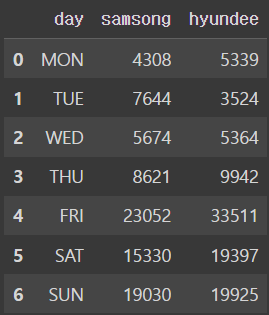
궁금점 : 내가 csv 파일을 보고 값을 다 쳐서 DataFrame으로 합치는 방법 말고, 두 csv 파일을 읽어서 위에 처럼 합치는 방법은 없을까?
5.6 DataFrame 인덱싱 II
여러 행(row)를 받아오는 법
iphone_df.loc[['iPhone X','iPhone 8']]output
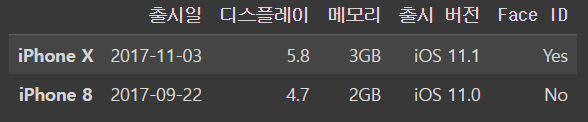
dtype은 DataFrame 이다
type(iphone_df.loc[['iPhone X','iPhone 8']])output
pandas.core.frame.DataFrameㄴ 이유 : 2차원이기 때문에 Series가 아니라 DataFrame이다
여러 열(column)을 받아오는 법
iphone_df[['Face ID','출시일','메모리']]output

열 슬라이싱 하는법 -> 콜론을 이용하자 !!
iphone_df.loc['iPhone 8':'iPhone XS']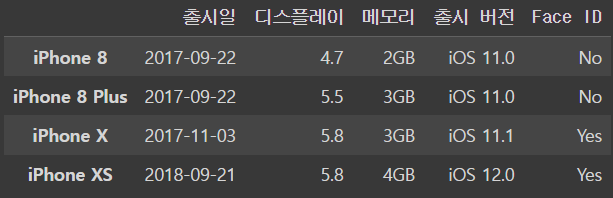
앞에 시작점을 안쓰면 다 불러와진다
iphone_df.loc[:'iPhone XS']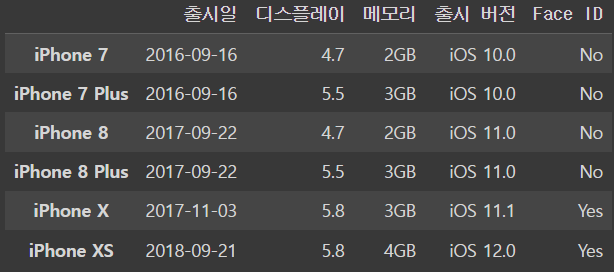
하지만 행과 다르게 열을 슬라이싱 하는 거는 방법이 다르다
행 슬라이싱 하듯이 하면
iphone_df['메모리':'Face ID']output

이상해진다 !
그래서 앞에 :(콜론)을 붙여줘야한다
iphone_df.loc[:,'메모리':'Face ID']output
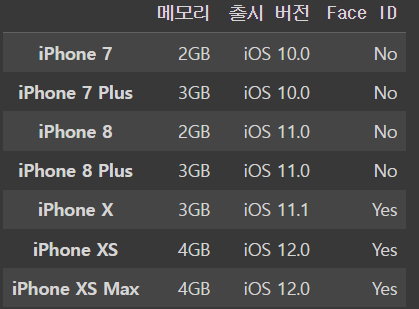
행과 열 다 슬라이싱 하는 법 !!
iphone_df.loc['iPhone 7':'iPhone X','메모리':'Face ID']output
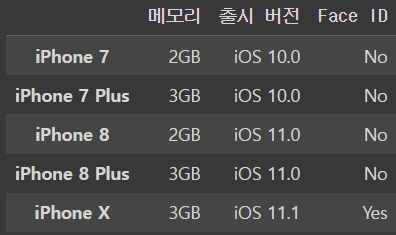
5.7 방송사 시청률 받아오기 IV
이번에는 DataFrame에서 연속된 여러 줄을 찾는 연습을 해보겠습니다.
방송사는 'KBS'에서 'SBS'까지, 연도는 2012년부터 2017년까지의 시청률만 확인하려면 어떻게 하면 될까요?
code
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[2012:2017,'KBS':'SBS']5.8 DataFrame 조건으로 인덱싱
boolean 형식으로 값 받아오기 !
import pandas as pd
iphone_df=pd.read_csv('drive/MyDrive/dataScience/data/iphone.csv',index_col=0)
iphone_dfoutput
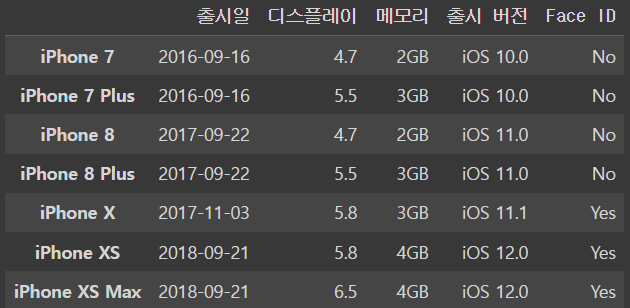
boolean 값으로 해서
iphone_df.loc[[True,False,True,True,False,True,False]]output
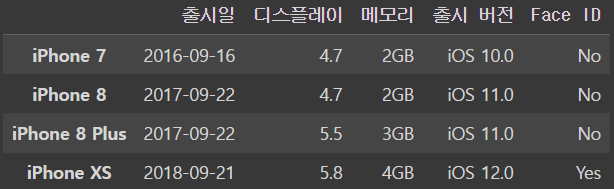
나머지를 생략하고 쓰면
iphone_df.loc[[True,False,False,True]]이렇게 쓸 수도 있는데
여기서는 오류가 나지만 원래는 나머지 없는 인덱스는 다 False로 처리한다!
output
이것도 마찬가지다ㅎㅎ
iphone_df.loc[:,[True,False,False,True]]boolean으로 받는 것 말고 다른 방법도 있는데
iphone_df['디스플레이']>5이처럼 수식으로 5이상만 가져오는 방법도 있다
output
iPhone 7 False
iPhone 7 Plus True
iPhone 8 False
iPhone 8 Plus True
iPhone X True
iPhone XS True
iPhone XS Max True
Name: 디스플레이, dtype: boolㄴ 이거는 Series 형식이고
DataFrame 형식으로도 만들 수 있는데 이 때에는 .loc[]안에 써주면 된다 !
iphone_df.loc[iphone_df['디스플레이']>5]output
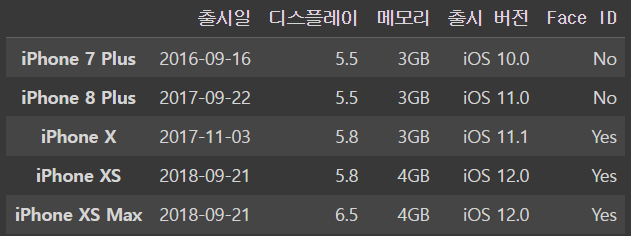
열(column)을 가져오는 방식 !
iphone_df['Face ID']=='Yes'output
iPhone 7 False
iPhone 7 Plus False
iPhone 8 False
iPhone 8 Plus False
iPhone X True
iPhone XS True
iPhone XS Max True
Name: Face ID, dtype: bool열도 똑같이 .loc[]에 넣으면 된다
iphone_df.loc[iphone_df['Face ID']=='Yes']output
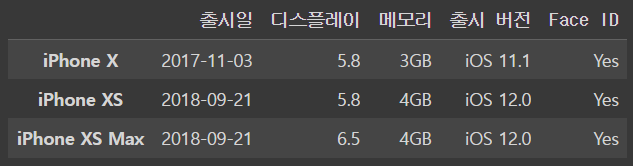
만약 두가지 조건에 만족하는 것들만 받아오고 싶다면?
= () 안에 넣고 & 연산자로 처리해주면 된다
(iphone_df['디스플레이']>5)&(iphone_df['Face ID']=='Yes')output
iPhone 7 False
iPhone 7 Plus False
iPhone 8 False
iPhone 8 Plus False
iPhone X True
iPhone XS True
iPhone XS Max True
dtype: boolDataFrame 형식으로 하고싶다면 []안에 넣어주면 된다
condition = (iphone_df['디스플레이']>5)&(iphone_df['Face ID']=='Yes')
iphone_df[condition]output
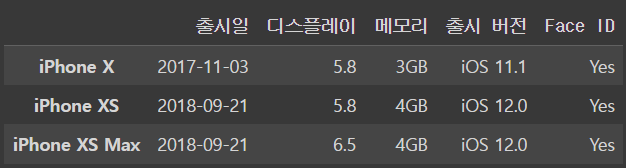
둘 중 하나만 만족하는 것을 불러오고 싶다면 |연산자로 처리하자
condition2 = (iphone_df['디스플레이']>5)|(iphone_df['Face ID']=='Yes')
iphone_df[condition2]output
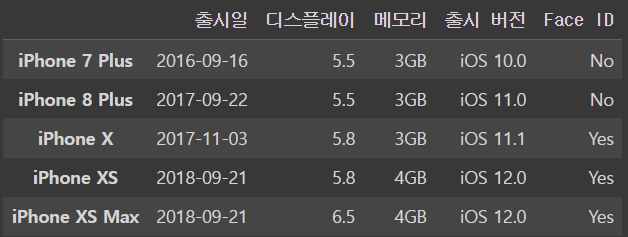
5.9 방송사 시청률 받아오기 V
이번에는 DataFrame에서 조건에 해당하는 데이터를 찾는 연습을 해보겠습니다.
'KBS'에서 시청률이 30이 넘은 데이터만 확인해보려면 어떻게 하면 될까요?
code
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
boolean_KBS = df['KBS'] > 30 # 30이 넘는지 안넘는지 여부가 boolean값으로 나옴
df.loc[boolean_KBS, 'KBS'] #KBS 값만 나오게 하려면 뒤에 ,KBS를 넣어야함5.10 방송사 시청률 받아오기 VI
이번에는 좀 더 DataFrame을 다방면으로 분석해봅시다.
주어진 데이터에서 SBS가 TV CHOSUN보다 더 시청률이 낮았던 시기의 데이터를 확인해보려고 합니다.
어떻게 하면 될까요?
code
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
rate = (df['TV CHOSUN']>df['SBS'])
res = df.loc[rate,['SBS','TV CHOSUN']]
res처음에는 코드를
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
rate = (df['TV CHOSUN']>df['SBS'])
df[rate,'SBS','TV CHOSUN']이렇게 작성했는데 'Series' objects are mutable, thus they cannot be hashed 라는 에러가 떴다
왜냐하면 pandas에서는 한 번에 하나의 열만 선택하거나 여러개의 열을 리스트로 묶어서 선택해야 하기 때문 !
=> .loc을 사용하여 조건에 맞는 행을 선택하고 원하는 열을 리스트로 전달해야한다 !!
5.11 DataFrame 위치로 인덱싱하기
인덱스를 이용해서 값을 찾을 수 있다 !
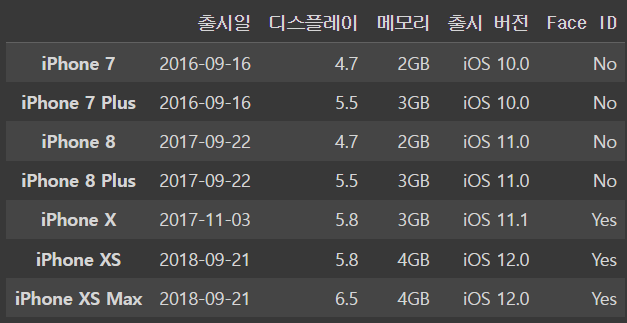
위 표에서 2번 행, 4번 열에 해당하는 값 (=No)을 찾고 싶다면
iloc[a,b]형식으로 써주면 된다
iphone_df.iloc[2,4]output
No여러개의 값을 원한다면
iphone_df.iloc[[1,3],[1,4]]output
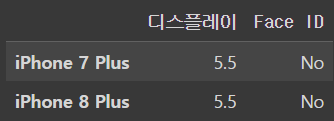
이건 1,3열만 열로 들어오고 1,4 행만 행으로 들어와서 dataframe이 형성된다는 의미이다
슬라이싱 또한 가능하당
iphone_df.iloc[3:,1:4]output
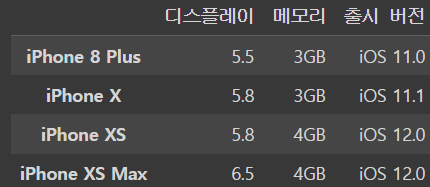
ㄴ 3번 열 부터 끝까지가 row로 들어가고 1~4번 열이 column으로 들어간다는 의미
5.12 DataFrame 인덱싱 문법 정리
(이름으로 인덱싱하기)
하나의 row 이름 - df.loc['row4']
row 이름의 리스트 - df.loc[['row4','row5','row3']]
row 이름의 리스트 슬라이싱 - df.loc['row2':'row5'] -> (단축 형태) df['row2':'row5']
하나의 column 이름 - df.loc[:,'col1'] -> (단축 형태) df['col1']
column 이름의 리스트 - df.loc[:,['col4','col6','col3']] -> (단축 형태) df[['col4,'col6','col3']]
column 이름의 리스트 슬라이싱 - df.loc[:,'col2':'col5']
(위치로 인덱싱하기)
하나의 row 위치 - df.iloc[8]
row 위치의 리스트 - df.iloc[[4,5,3]]
row 위치의 리스트 슬라이싱 - df.iloc[2:5] -> (단축 형태) df[2:5]
하나의 column 위치 - df.iloc[:,3]
column 위치의 리스트 - df.iloc[:,[3,5,6]]
column 위치의 리스트 슬라이싱 - df.iloc[:,3:7]

좋은 글이네요. 공유해주셔서 감사합니다.