
1.1 결정 트리란 ?
결정 트리 : 예/아니오 질문들 + 이 질문들을 답해나가면서 분류 하는 알고리즘
ex) 교통 사고 생존 여부 분류
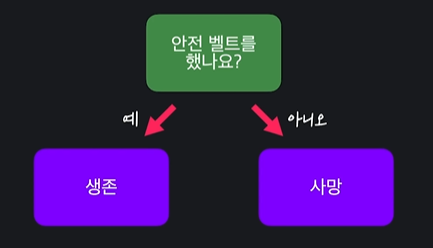
많게 나타낼 수도 있다
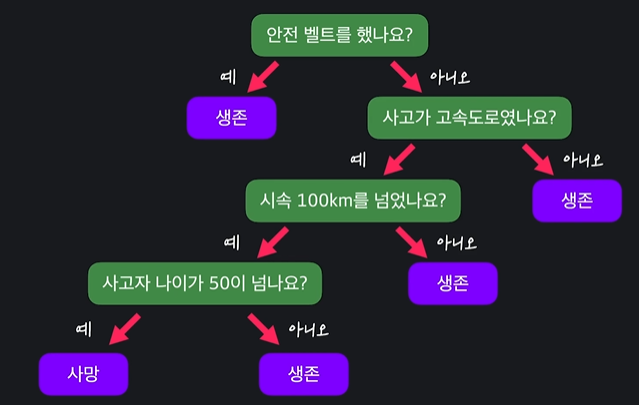
중요 !! ) 한 속성을 딱 한 번만 사용할 수 있는 것은 아니다
- 똑같은 속성을 여러번 사용 가능
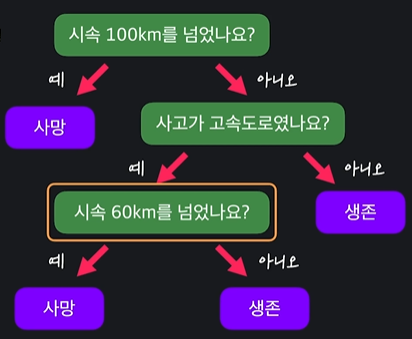
1.2 (실습) if-else 문으로 간단한 결정 트리 구현하기
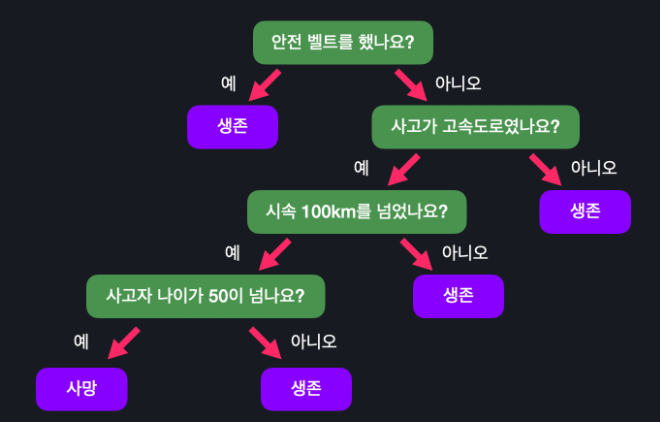
이번 과제에서는 위 결정 트리를 if-else 문을 이용해서 구현해보겠습니다.
survival_classifier함수
survival_classifier 함수는 안전 벨트를 했는지를 나타내는 불린형 파라미터, seat_belt, 고속도로였는지를 나타내는 불린형 파라미터, highway, 사고 당시 주행속도를 나타내는 숫자형 파라미터, speed, 사고자 나이를 나타내는 숫자형 파라미터, age를 받습니다.
그리고 위에 나와 있는 결정 트리대로 교통 사고 데이터가 생존할 건지 사망할 건지를 리턴합니다. (생존을 예측할 시 0을 리턴하고, 사망을 예측할 시 1을 리턴합니다.)
code
def survival_classifier(seat_belt, highway, speed, age):
if seat_belt == True:
return 0
else:
if highway == True:
if speed > 100:
if age > 50:
return 1
else:
return 0
else:
return 0
else:
return 0
print(survival_classifier(False, True, 110, 55))
print(survival_classifier(True, False, 40, 70))
print(survival_classifier(False, True, 80, 25))
print(survival_classifier(False, True, 120, 60))
print(survival_classifier(True, False, 30, 20))1.3 지니 불순도
지니 불순도
: 데이터 셋 안에 서로 다른 분류들이 얼만큼 섞여있는지

= 순수한 데이터 셋
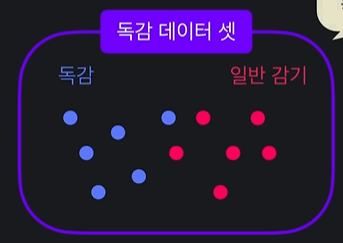
= 불순한 데이터 셋
공식

ex) 독감 데이터 셋 중 독감 : 70, 일반 : 30
GI = 1 - (0.7)^2 - (0.3)^2 = 0.42
ex) 독감 데이터 셋 중 독감 : 100, 일반 : 0
GI = 1 - (1)^2 - (0)^2 = 0
-> 낮을수록 순수한 데이터
ex) 독감 데이터 셋 중 독감 : 50, 일반 : 50
GI = 1 - (0.5)^2 - (0.5)^2 = 0.5
-> 높을 수록 불순한 데이터 = 데이터셋에 다양한 데이터가 섞여있다는 뜻
정리
지니 불순도
- 데이터 셋 안에 서로 다른 분류들이 얼만큼 섞여있는지를 나타냄
- 작을수록 데이터 셋이 순수하고, 클수록 데이터 셋이 불순하다
1.4 분류 노드 평가하기
root node 만들기
분류 : 독감, 일반 감기
이렇게 만들거나
질문 : 고열이 있나요?, 기침이 있나요?, 몸살이 있나요?
로 만들수도 있다
ㄴ 가장 좋은 노드로 선택해야하는데 이 때 지니 불순도를 사용 ~~
ex) 독감 : 50, 일반 감기 : 40
ㄴ 여기서는 독감이 더 많기 때문에 독감 노드를 고른다
좋은 분류 노드는 최대한 많은 데이터들을 맞게 예측 해야한다 !!
-> 데이터 셋이 독감 데이터가 많을수록 좋다
-> 데이터 셋이 순수할수록(지니 불순도가 낮을수록) 좋다
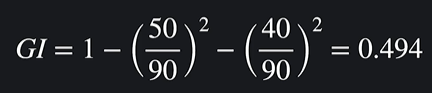
ㄴ 지금은 불순도가 꽤 높다
불순도가 높다는 것은 독감과 일반 감기 데이터가 많이 섞여있다는 뜻 ! = 데이터가 불순할 때는 분류 노드로 만들면 별로 성능이 안좋다는 뜻
- 분류 노드를 만들려고 하는 경우에, 분류하려는 데이터 셋의 불순도를 계산하면, 이 노드가 어느 정도의 데이터를 맞출 수 있는지를 한 번에 알 수 있다
1.5 질문 노드 평가하기
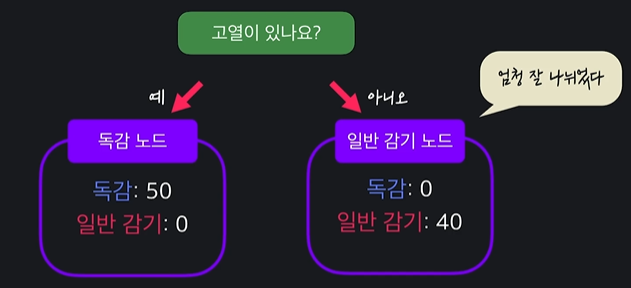
좋은 질문
안 좋은 질문
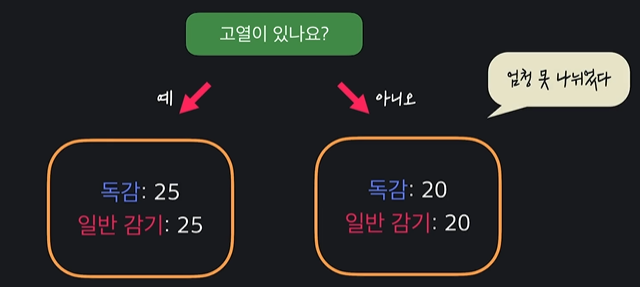
ㄴ 데이터들이 너무 섞여있음
= 좋은 질문은 데이터를 잘 나눠서 아래 노드들이 분류하기 쉽게 만들어준다
ㄴ 질문으로 나뉜 데이터 셋이 순수할 수록 (지니 불순도가 낮을수록) 더 좋다
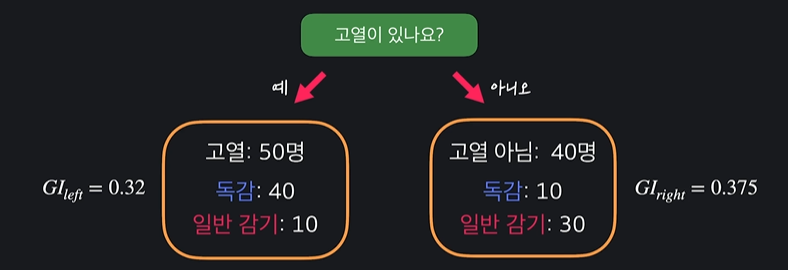
( 고열이 있는 데이터와 없는 데이터의 불순도 계산 )
ㄴ 이걸 평균 내면

지니 불순도 평균 = (고열 사람 수 고열 데이터 불순도) + (고열 아닌 사람 수 고열 아닌 데이터 불순도) / 전체 사람 수
ㄴ 낮을 수록 좋고 높을 수록 안 좋다
1.6 노드 고르기
질문들의 불순도를 계산해줌 -> 불순도가 가장 낮은 노드를 뽑기
분류 노드의 불순도가 가장 작은 것 = 데이터가 잘 나눠져 있기 떄문에 있는 그대로 분류해도 된다는 뜻
질문 노드의 불순도가 가장 작으면 질문을 통해서 지금 있는 데이터 셋보다 불순도를 더 낮출 수 있다는 뜻

그림으로 표현하면 루트 노드는
이렇게 된다
1.7 모든 노드 만들기
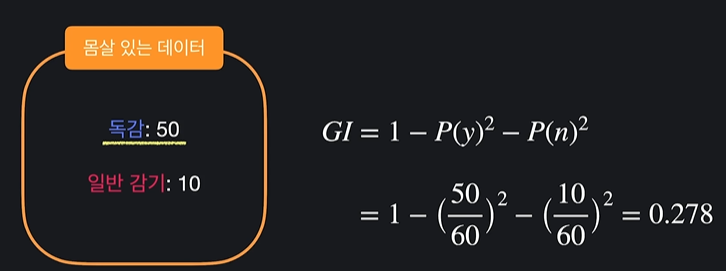
(분류 노드 불순도 계산)
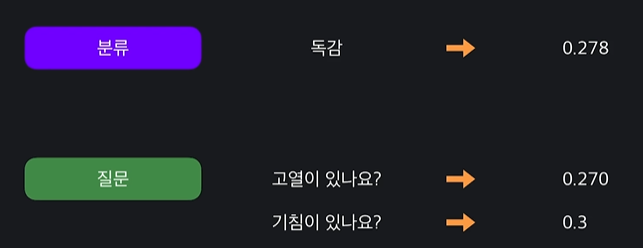
이 중에서 질문 중에 고열이 있나요? 질문이 가장 불순도가 적으므로 이 질문을 노드로 만들어주면 된다
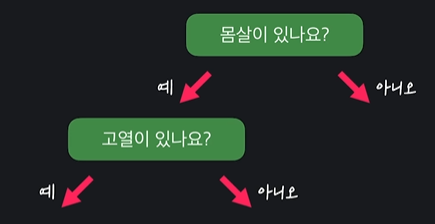
이 과정을 리프노드들이 모두 분류 노드가 될 때까지 만들어주면 된다 !
- 결정 트리 깊이
: 트리가 몇 층까지 내려가는지를트리의 깊이라고 표현한다
ex) 깊이 3 이상 내려가지마라 ! 라고 정해주면 더 이상 불순도를 비교하는게 아니라 멈추고 분류 노드로 만들어주면 된다
1.8 속성이 숫자형일 때 질문 노드
데이터가 숫자형으로 있는 경우에는 만들 수 있는 질문이 엄청 많다 !
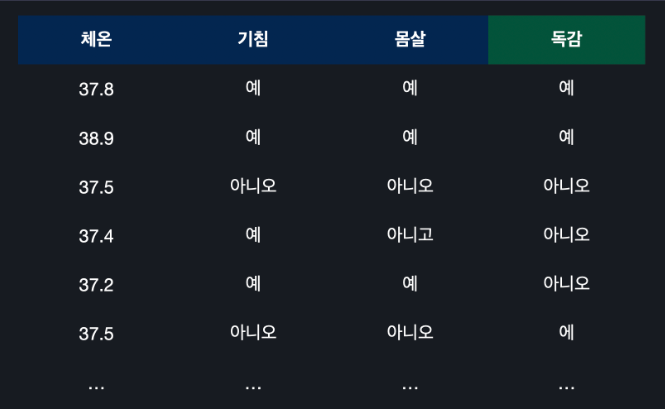
ex) 체온이 37.1도를 넘나요?, 37.2도를 넘나요? ... 처럼 끝도 없이 질문이 많아진다
이걸 방지 하기 위해
-
체온 데이터를 정렬시킨다
작은 순서 부터 큰 순서대로 데이터가 나열됨 -
연속된 체온 데이터의 평균을 계산
이 평균들을 이용해서 질문들을 하나씩 만드는 것이다 -
모든 평균 체온에 대해서 지니 불순도를 계산
평균을 기준으로 삼았을 때 데이터가 얼마나 잘 분류 됐는지를 전부 다 계산해주는 것이다
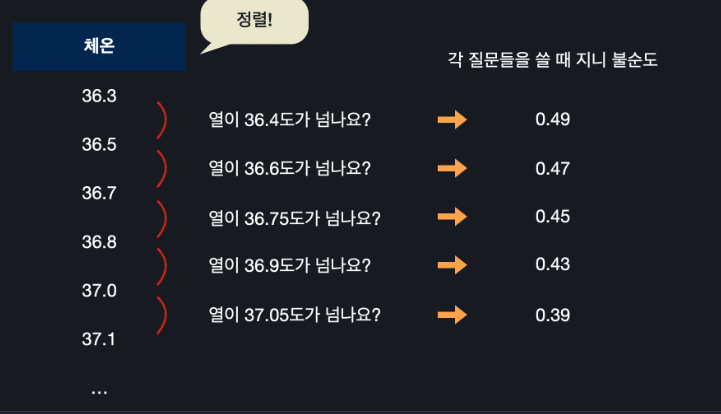
37.5로 나눴을 때 지니 불순도가 가장 낮다고 하면 체온 속성 관련 질문 노드를 만들 때 체온이 37.5도가 넘나요?를 사용하면 되다
근데 이걸 사용하긴 해도 몸살이 있는지 없는지가 더 좋은 기준이 될 수 있기 때문에
37.5가 넘나요?, 몸살이 있나요?, 기침이 있나요? 이 세 질문과 독감 분류 노드들 중 가장 지니 불순도가 낮은 것을 선택하면 된다
1.9 속성 중요도
결정트리 장점
- 데이터를 분류하는 방법이 직관적이다
- 쉽게 해석할 수 있다 (어떤 속성이 중요하게 사용됐는지 알 수 있다)
속성 중요도는 노드 중요도를 알아야 한다
노드 중요도
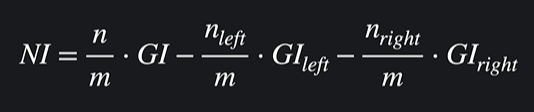
여기서 n은 노드까지 오는 데이터 수, GI는 노드 지니 불순도, m은 전체 학습 데이터 수를 나타낸다
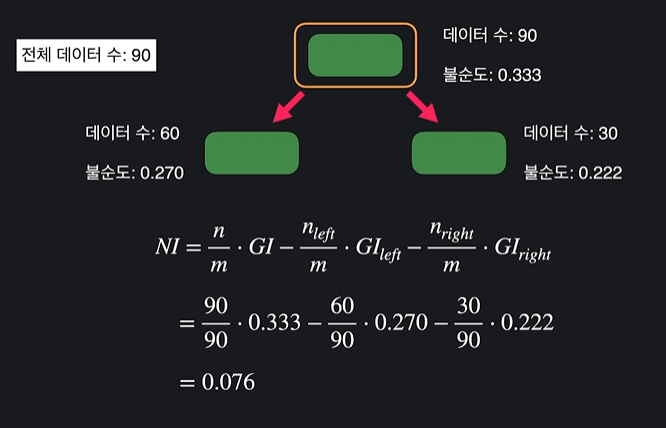
중요도는 0.076이 나오는데, 이건 위 노드에서 아래 노드로 내려오면서 계산하는데 여기에 그냥 각 노드들까지 가는 데이터의 비율을 맞춰준 것이다
= 불순도가 얼마나 줄어들었는지 계산
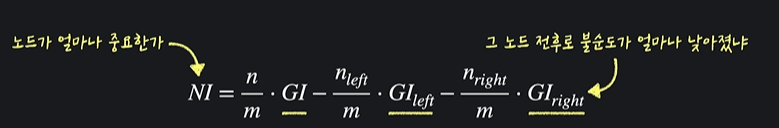
모든 노드의 중요도를 다 계산해주면 특정 속성이 얼마나 중요한지 알 수 있다

ㄴ ex) 고열이 얼마나 중요한지 알고싶다고 하면 고열 질문을 갖는 모든 노드의 중요도를 더하고 트리 안에 모든 노드의 중요도의 합으로 나눠준다
쉽게 생각하면, 모든 노드가 데이터를 양 갈래로 나누면서 나누는 데이터 셋들의 지니 불순도를 낮추는데, 전체적으로 낮춰진 불순도에서 특정 속성 하나가 낮춘 불순도가 얼마나 되는지를 계산하는 것이다
= 특정 속성을 질문으로 갖는 노드들의 중요도의 평균을 구한 것과 비슷 ! (속성의 평균 지니 감소 라고 부르기도 한다)
각 속성의 평균 지니 감소를 이용하면, 특정 속성이 결정 트리 안에서 평균적으로 얼마나 불순도를 낮췄는지를 계산할 수 있고, 이게 있으면 결정 트리 안에서 그 속성이 얼마나 중요한지를 판단할 수 있는 것이다
1.10 scikit-learn 데이터 준비하기
붓꽃 데이터를 이용하려하기 때문에
from sklearn.datasets import load_iris
import pandas as pd함수 불러오고 잘 들어있나 확인
iris_data = load_iris()
print(iris_data.DESCR)입력 변수를 데이터프레임으로 받기
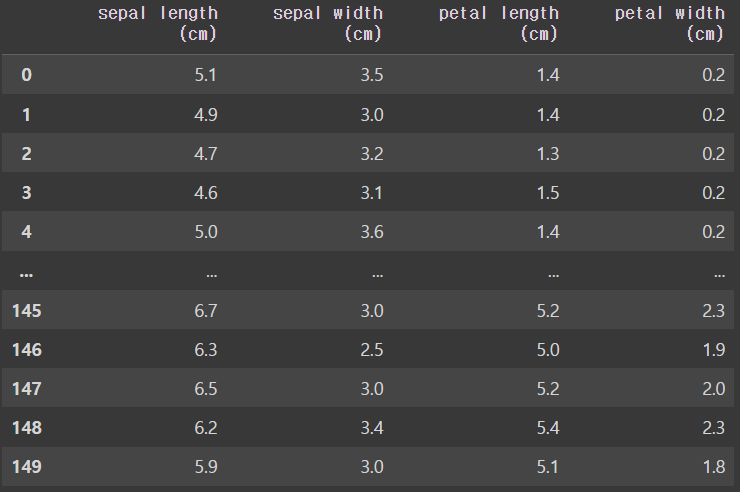
X = pd.DataFrame(iris_data.data, columns = iris_data.feature_names)
Xoutput
목표 변수를 데이터프레임으로 받기
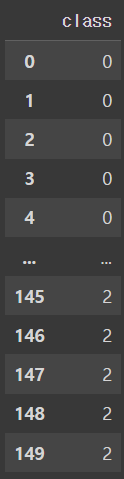
y = pd.DataFrame(iris_data.target, columns = ['class'])
youtput
1.11 scikit-learn으로 결정 트리 쉽게 이용하기
training set과 test set 분류
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.2, random_state = 5)결정 트리 모델을 설정할 때에는 DecisionTreeClassifier()을 설정한다
그리고 만드려는 결정 트리의 최대 깊이를 설정해주고 싶으면 파라미터로 max_depth = ? 를 넣어주면 된다
model = DecisionTreeClassifier(max_depth = 4)모델 학습하기는 .fit() 쓰기
model.fit(X_train, y_train)output
분류 예측하기는 .predict()를 사용하자 !!
model.predict(X_test)output
array([1, 1, 2, 0, 2, 2, 0, 2, 0, 1, 1, 1, 2, 2, 0, 0, 2, 2, 0, 0, 1, 2,
0, 1, 1, 2, 1, 1, 1, 2])ㄴ 분류 문제여서 예측값들이 다 0,1,2 뿐이다
분류 모델 평가하기는 .score()을 쓰고 파라미터로는 test set을 넣어주장
model.score(X_test, y_test)output
0.86666666666666671.12 scikit-learn으로 속성 중요도 확인하기
속성 중요도에 필요한 모듈들을 더 추가시켜주었다
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd속성들의 중요도가 배열안에 저장되도록 하였음
importances = model.feature_importances_속성 중요도를 시각화 하는 코드 !
indices_sorted = np.argsort(importances) # 속성 중요도를 시각화 하는 코드
plt.figure()
plt.title('Feature importances')
plt.bar(range(len(importances)), importances[indices_sorted])
plt.xticks(range(len(importances)), X.columns[indices_sorted], rotation=90)
plt.show()output
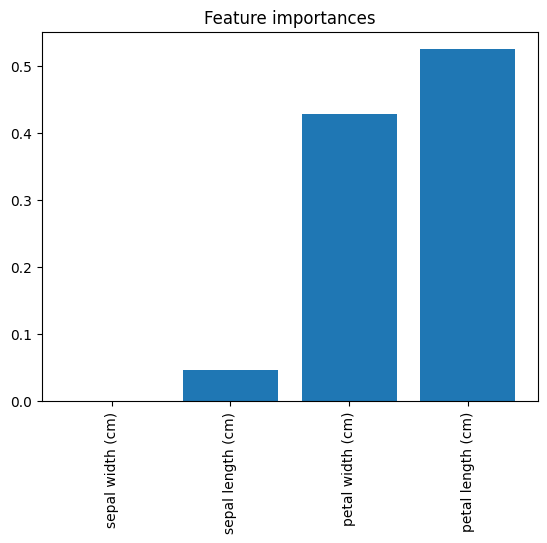
ㄴ 학습시킨 결정트리에서 각 속성들의 중요도가 얼마나인지 한눈에 알 수 있다
붓꽃 종류를 분류하는데 꽃잎 길이가 가장 중요하게 사용 되었다는 것을 알 수 있음
1.13 (실습) scikit-learn 유방암 데이터 준비하기
이번 과제에서는 sklearn 라이브러리의 유방암 데이터 셋을 학습에 사용할 수 있게 준비해 보겠습니다. 이 데이터 셋은 처음 보시는 분들이 많으실 테니, 간단히 설명드릴게요.
암은 사람한테 치명적인 악성(malignant)과 그렇지 않은 양성(benign)암으로 나뉩니다. sklearn 유방암 데이터 셋은 유방암세포들의 다양한 속성들과 (길이, 넓이, 둘레 등등) 암이 악성인지 양성인지를 저장하고 있습니다.
(채점되지는 않지만, 꼭 print(cancer_data.DESCR)를 실행해서 데이터 셋을 살펴보세요.)
- 데이터 셋은 load_breast_cancer 함수를 호출해서 cancer_data 변수에 저장했습니다.
- 속성들은 cancer_data.data에, 악성인지 양성인지는 cancer_data.target에 저장돼있습니다.
- 속성 이름은 cancer_data.feature_names에 저장돼있고, 목표 변수 열 이름은 "class"로 지어주세요.
해야할 일
- print(cancer_data.DESCR)를 해서 유방암 데이터를 살펴보세요. (채점하지는 않음)
- cancer_data 변수에 저장된 데이터를 입력과 목표 변수로 나눠서 pandas dataframe에 저장하세요.
- train_test_split를 이용해서 데이터 셋을 training/test 셋으로 나누세요.
조건
- 채점을 위해서
train_test_split옵셔널 파라미터는test_size=0.2, random_state=5로 설정하세요. - 향후 모델을 학습시킬 때 경고 메시지가 나오지 않게 training set 목표 변수에 대해서
y_train = y_train.values.ravel()이 코드를 추가해주세요. - 채점은
X_train.head()를 출력해서 확인합니다.
code
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
# 데이터 셋 불러 오기
cancer_data = load_breast_cancer()
# 데이터 셋을 살펴보기 위한 코드
# 입력 변수를 사용하기 편하게 pandas dataframe에 저장
X = pd.DataFrame(cancer_data.data, columns = cancer_data.feature_names)
# 목표 변수를 사용하기 편하게 pandas dataframe에 저장
y = pd.DataFrame(cancer_data.target, columns = ['class'])
# training-test 셋 나누기
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=5)
# 후에 모델 학습시킬 때 경고 안나게 하기
y_train = y_train.values.ravel()
# 테스트 코드
X_train.head()1.14 (실습) 결정 트리로 악성/양성 유방암 분류하기
저번 과제에서는 sklearn 라이브러리에 있는 유방암 데이터를 학습에 사용할 수 있게 준비했는데요. 이번에는 준비한 데이터를 가지고 결정 트리 모델을 직접 사용해 볼게요.
해야 하는 일
- 결정 트리 모델(
DecisionTreeClassifier)을 만든다. (옵셔널 파라미터:max_depth=5, random_state=42) - 지난 실습 과제에서 준비한 training set 데이터를 가지고 모델을 학습시킨다.
- 학습시킨 모델에 testing set 데이터를 넣어서 예측한다. (결과는
predictions변수에 저장) - testing set 데이터를 사용해서 학습시킨 모델의 성능을 평가한다. (결과는
score변수에 저장)
조건
predictions,score변수를 출력하여 채점한다.
code
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# 데이터 셋 불러 오기
cancer_data = load_breast_cancer()
# 입력 변수를 사용하기 편하게 pandas dataframe에 저장
X = pd.DataFrame(cancer_data.data, columns = cancer_data.feature_names)
# 목표 변수를 사용하기 편하게 pandas dataframe에 저장
y = pd.DataFrame(cancer_data.target, columns = ['class'])
# training-test 셋 나누기
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=5)
# 후에 모델 학습시킬 때 경고 안나게 하기
y_train = y_train.values.ravel()
# 결정 트리 모델 정의
model = DecisionTreeClassifier(max_depth = 5, random_state = 42)
# 모델 학습
model.fit(X_train, y_train)
# 예측하기
predictions = model.predict(X_test)
# 모델의 성능 파악
score = model.score(X_test, y_test)
predictions, score