
3.1 k겹 교차 검증
training set과 test set으로 나눠서 예측 및 평가를 하다보면 딱 이 test set에서만 성능이 안 좋을 수도 있음
-> 이거를 막아주는게 k겹 교차 검증
ex) 1000개의 데이터
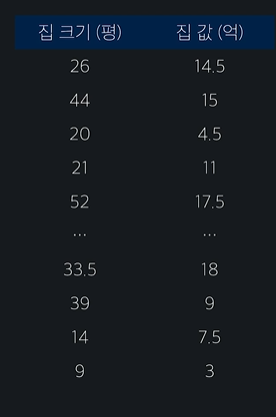
이 데이터 셋을 5개로 나눈다
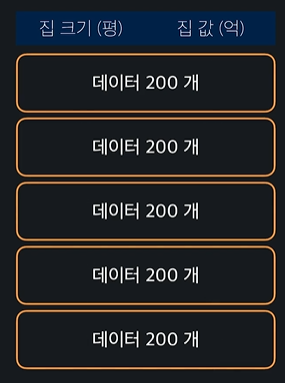
맨 앞 200개를 test set, 그 나머지 800개를 training set으로 나눠서 training set으로 모델을 학습, test set으로 모델 성능 평가
ㄴ 이랬을 때 성능 80%
이번에는

이렇게 했을 때 70%
계속 반복함
그러면
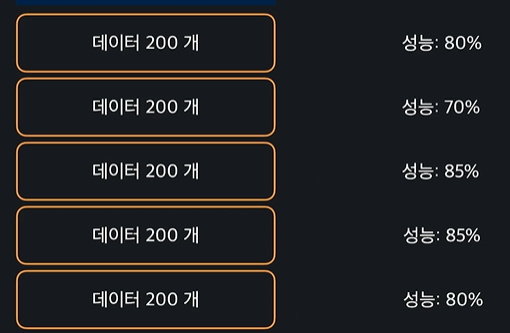
이렇게 나오는데, 이 다섯개의 평균 성능은 80%가 나오고 이게 모델 성능이 되는 것이다
k겹 교차 검증에서 k가 데이터 셋을 몇개로 나눌건지 정하는 변수인 것이다
주로 5개로 나눔 (5겹 교차 검증)
3.2 scikit-learn으로 k겹 교차 검증 해보기
모듈 임포트 !
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
import numpy as np
import pandas as pd
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning) # 얘는 오류 안나게 하는 코드붓꽃 데이터 불러오고 변수 설정
iris_data = datasets.load_iris()데이터 프레임으로 저장하고 목표 변수도 데이터 프레임으로 저장
X = pd.DataFrame(iris_data.data, columns = iris_data.feature_names)
y = pd.DataFrame(iris_data.target, columns = ['Class'])로지스틱 회귀하기
logistic_model = LogisticRegression(max_iter = 2000)k겹 교차검증을 해주는 코드는 cross_val_score()이다 한번에 데이터를 나눠주고 반복시켜 학습시켜줌
cross_val_score(logistic_model, X, y.values.ravel(),cv = 5)ㄴ cv=5는 5겹 교차 검증 하겠다는 뜻
output
array([0.96666667, 1. , 0.93333333, 0.96666667, 1. ])평균을 내면 로지스틱 모델의 성능을 좀 더 정확하게 알 수 있음
np.average(cross_val_score(logistic_model, X, y.values.ravel(),cv = 5))output
0.97333333333333343.3 (실습) k겹 교차 검증 직접 해보기
이번 과제에서는 scikit-learn 라이브러리를 사용해서 k-겹 교차 검증을 직접 구현해 보겠습니다.
저희가 사용할 데이터는 성별 데이터인데요. 데이터를 살펴보면 (gender_df.head()로 데이터를 꼭 한 번 살펴보세요!) 데이터를 살펴보면 각 행은 한 명의 사람을 나타냅니다. 'Gender' 열을 살펴보면 성별 데이터가 있고요, 나머지 열들은 각 사람이 가장 좋아하는 색, 음악 장르, 주류, 음료가 저장돼 있습니다.
GENDER_FILE_PATH = './datasets/gender.csv'
gender_df = pd.read_csv(GENDER_FILE_PATH)
X = pd.get_dummies(gender_df.drop(['Gender'], axis=1)) # 입력 변수를 one-hot encode한다
y = gender_df[['Gender']].values.ravel()입력 변수인 취향 데이터는 One-hot encoding 해서 변수 X에, 목표 변수인 성별 데이터는 변수 y에 저장해 줄게요.
이번 과제에서는 입력 변수 취향을 가지고 성별을 예측할 때 로지스틱 회귀 모델의 성능을 k-겹 교차 검증을 사용해서 파악해 볼게요. 아래 나와 있는 내용들을 코드로 구현해 보세요!
- 로지스틱 회귀 모델을 정의하세요. (옵셔널 파라미터는
solver='saga', max_iter=2000로 설정하세요.) - numpy 라이브러리의
average()메소드와sklearn.model_selection모듈의cross_val_score()을 사용해서 정의한 로지스틱 회귀 모델의 성능을 5-겹 교차 검증 성능을 파악하세요. (이 데이터는k_fold_score변수에 저장하세요)
code
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
import numpy as np
import pandas as pd
GENDER_FILE_PATH = './datasets/gender.csv'
# 데이터 셋을 가지고 온다
gender_df = pd.read_csv(GENDER_FILE_PATH)
X = pd.get_dummies(gender_df.drop(['Gender'], axis=1)) # 입력 변수를 one-hot encode한다
y = gender_df[['Gender']].values.ravel()
logistic_model = LogisticRegression(solver = 'saga', max_iter = 2000)
k_fold_score = np.average(cross_val_score(logistic_model, X, y,cv = 5))
# 테스트 코드
k_fold_scoreoutput
0.604761904761904833.4 그리드 서치
하이퍼파라미터 = 학습을 하기 전에 미리 정해줘야 하는 변수 또는 파라미터들
ex) model = Lasso(alpha = 0.01, max_iter = 1000)
ㄴ alpha = 손실함수의 정규화 항에 곱해주는 함수
max_iter = 경사 하강법을 몇 번 할 건지
: 어떤 값을 넣어주느냐에 따라 성능이 달라진다 !
grid search = 하이퍼파라미터 후보들을 몇개 정하고, 다 해봤을 때 가장 성능이 좋았던 하이퍼파라미터 조합을 결정해줌
ex) model = Lasso(alpha = ?, max_iter = ?)
후보값 정할 때 표를 쓴다
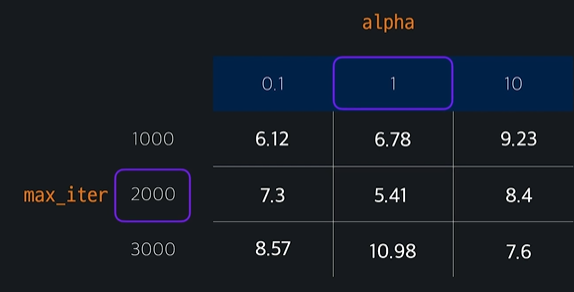
가장 작은 값이 나오는 하이퍼 파라미터 조합을 골라서
model = Lasso(alpha = 1, max_iter = 2000) 이렇게 완성시킨다
3.5 scikit-learn으로 그리드 서치 해보기
module import 하기
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import GridSearchCV
from math import sqrt
import numpy as np
import pandas as pd데이터 준비하기
ADMISSION_FILE_PATH = 'drive/MyDrive/dataScience/data/admission_data.csv'
admission_df = pd.read_csv(ADMISSION_FILE_PATH).drop('Serial No.', axis = 1)
X = admission_df.drop(['Chance of Admit '],axis = 1) # 입력변수 따로 저장
polynomial_transformer = PolynomialFeatures(6) #6차항 변형기 정의
polynomial_features = polynomial_transformer.fit_transform(X.values) # 인풋 데이터 넣어서 변수를 높은 차항으로 해줌
features = polynomial_transformer.get_feature_names_out(X.columns) #변수 이름 생성
X = pd.DataFrame(polynomial_features, columns = features)
y = admission_df[['Chance of Admit ']]최적화 할 파라미터들과 후보값들이 들어간 파이썬 딕셔너리 만들기 !!
hyper_parameter = {
'alpha':[0.01,0.1,1,10],
'max_iter':[100,500,1000,1500,2000]
}Lasso 모델 저장
lasso_model = Lasso()GridSearchCV = 모델 성능을 평가하면서 주어진 하이퍼파라미터 값들의 조합을 모두 시도해서 최적의 조합을 찾아줌
fit(X,y) = 가능한 모든 하이퍼파라미터 조합에 대해 교차 검증을 수행하며 최적의 조합을 찾음
hyper_parameter_tuner = GridSearchCV(lasso_model, hyper_parameter, cv=5) # 최적의 하이퍼파라미터 조합과 그 때의 모델 성능 점수들 저장
hyper_parameter_tuner.fit(X,y)output
.best_params_를 쓰면 가장 좋은 하이퍼파라미터 조합을 바로 뱉어낸다
hyper_parameter_tuner.best_params_ # 가장 좋은 하이퍼파라미터 조합 뱉어냄output
{'alpha': 1, 'max_iter': 100}3.6 (실습) 그리드 서치 직접 해보기
이번 과제에서는 scikit-learn 라이브러리로 직접 Grid Search를 구현해 보겠습니다.
사용할 데이터는 이미 여러 번 본 성별 데이터입니다. read_csv() 메소드를 사용해서 저장된 경로에서 데이터를 가지고 오고, one-hot encoding을 해서 입력 변수를 X에 저장해서 준비하고, 목표 변수는 y에 저장합니다.
GENDER_FILE_PATH = './datasets/gender.csv'
# 데이터 셋을 가지고 온다
gender_df = pd.read_csv(GENDER_FILE_PATH)
X = pd.get_dummies(gender_df.drop(['Gender'], axis=1)) # 입력 변수를 one-hot encode한다
y = gender_df[['Gender']].values.ravel()로지스틱 회귀 모델을 사용해서 사람들의 다양한 취향을 써서 성별을 예측하려고 하는데요. 로지스틱 회귀 모델에 어떤 하이퍼 파라미터(옵셔널 파라미터)를 사용하는 게 좋을지 알고 싶습니다. 아래 나와 있는 내용들을 코드로 구현해 보세요!
- 로지스틱 회귀 모델을 정의한다
- 실험해보고 싶은 하이퍼 파라미터 조합을 파이썬 딕셔너리로 정의한다 ('penalty': ['l1', 'l2'], 'max_iter': [500, 1000, 1500, 2000]조합을 확인해보세요!)
- GridSearchCV를 이용해서 정의한 로지스틱 회귀 모델에서 어떤 하이퍼 파라미터 조합을 쓰는 게 가장 좋을지 알아내서 변수 best_params에 저장하세요. (그리드 서치를 할 때 각 조합의 성능을 5 겹 교차 검증을 통해서 확인해 보세요.)
code
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
# 경고 메시지 출력 억제 코드
import warnings
warnings.simplefilter(action='ignore')
GENDER_FILE_PATH = './datasets/gender.csv'
# 데이터 셋을 가지고 온다
gender_df = pd.read_csv(GENDER_FILE_PATH)
X = pd.get_dummies(gender_df.drop(['Gender'], axis=1)) # 입력 변수를 one-hot encode한다
y = gender_df[['Gender']].values.ravel()
# 딕셔너리 정의
hyper_parameter = {
'penalty': ['l1', 'l2'],
'max_iter': [500, 1000, 1500, 2000]
}
# 로지스틱 회귀 모델 정의
logistic_model = LogisticRegression()
# 최적의 하이퍼 파라미터 조합 찾아줄 GridSearchCV 정의
hyper_parameter_tuner = GridSearchCV(logistic_model, hyper_parameter, cv=5)
# 최적의 성능 갖는 하이퍼 파라미터 조합 계산
hyper_parameter_tuner.fit(X,y)
best_params = hyper_parameter_tuner.best_params_
# 테스트 코드
best_params