
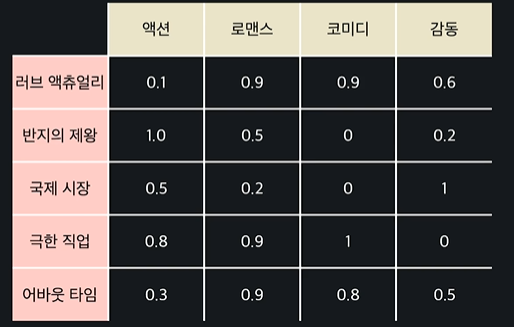
2.1 내용 기반 추천이란
: 상품의 속성, 즉 '어떤' 상품인지를 사용해서 추천
ex)
머신 러닝 모델 학습
2.2 데이터 표현하기
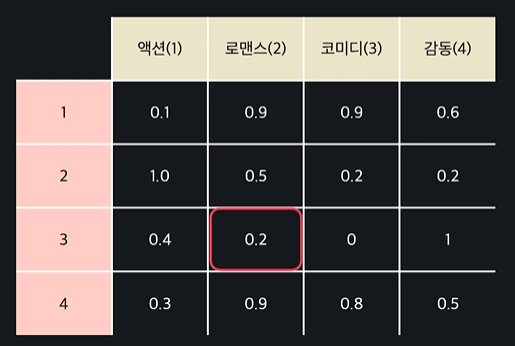
각 영화들에 대한 속성과 한 유저의 평점 데이터를 갖고 있을 때 이런 식으로 데이터를 입력, 목표 변수로 나눠서 머신러닝 학습
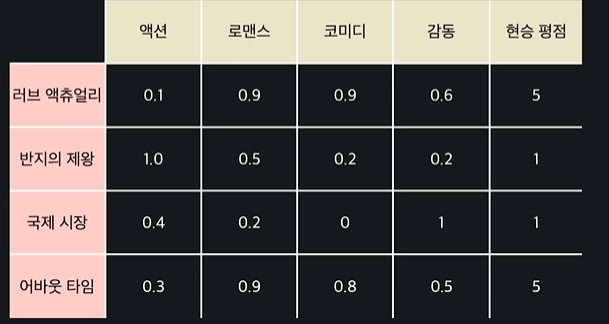
-> 유저의 평점 예측 가능 !
선형회귀 )
입력 변수를 x, 목표 변수를 y라고 나타냄
입력 변수 개수 : n, 학습 데이터의 개수 : m
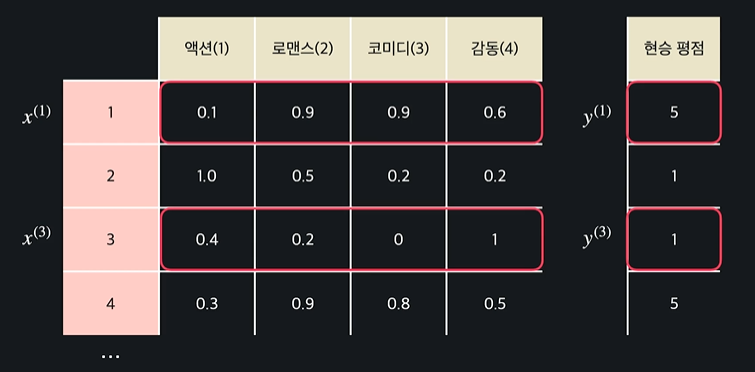
열을 표현할 땐 이렇게 x위에 해당하는 숫자를 쓰면 됨
그리고 각 x는
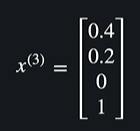
벡터이다 !
그렇다면 3행 2열에 있는 데이터는 어떻게 표현할까?
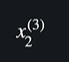
이렇게 표현하면 된다 !
일반화하면

이렇게 표현이 가능 !!
2.3 다중 선형 회귀 가설 함수
선형회귀 )
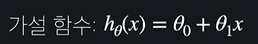
가설함수는 이렇게 생겼고
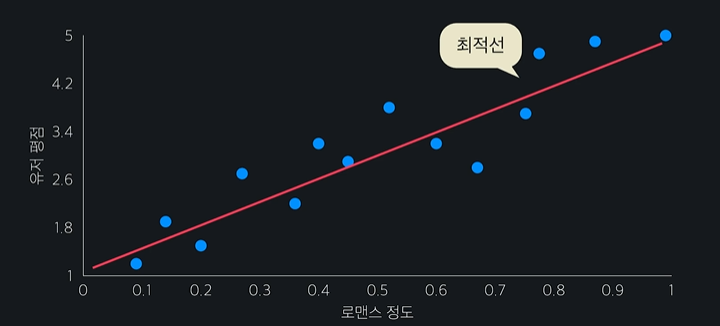
최적선은 이렇게 생겼다
다중 선형 회귀 )
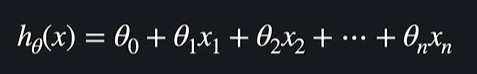
가설함수는 이렇게 생겼다
다중선형회귀에선 세타값들을 조율해서 최적의 값들을 구하고자 한다
벡터로 표현하면 더 간단하게 만들 수 있다
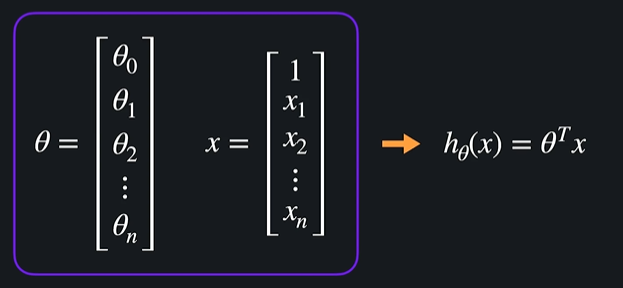
2.4 다중 선형 회귀 경사 하강법
손실함수
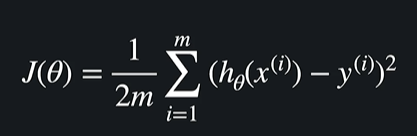
- 손실함수가 크면 가설함수가 데이터에 잘 안 맞는 것
- 손실함수가 작으면 가설함수가 데이터에 잘 맞는 것
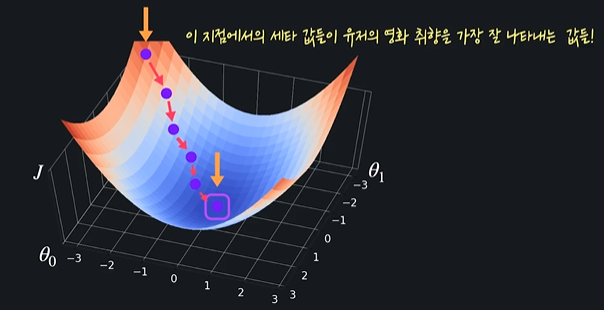
경사하강법
: 손실함수의 아웃풋을 최소화 하기 위해 세타값들을 바꿔주는 방법
선형회귀 경사 하강법
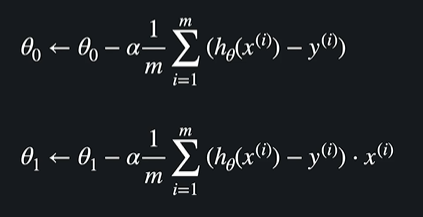
다중 선형 회귀 경사 하강법은 똑같은데 단지 세타값들이 많을 뿐이다

입력 변수가 n개 있다고 하면 세타 0 부터 세타 n 까지 쭉 업데이트를 해야, 경사 하강을 한 번 했다고 할 수 있음
일반화 시키면
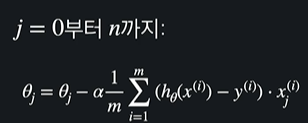
이렇게 나타낼 수 있다. 이 과정 한 번 거칠 때마다, 손실을 최대한 빨리 감소시키는 방향으로 세타값들이 업데이트 되는 것 ! 이걸 충분히 반복하면 결국 손실을 최소에 가깝게 줄일 수 있다 => 학습데이터에 잘 맞는 세타값들, 그러니까 최적의 유저 취향값들을 찾게 된다
2.5 학습시킨 모델로 추천하기
영화 평점 데이터에서 구한 세타값과 x값을 통해 가설함수를 만들어보자

대입하면 h(x) = 4.75가 나온다
이걸 유저들마다 반복한다

그리고 나서 학습한 각 유저의 취향과 영화 속성 데이터로 평가하지 않은 영화 평점을 예측한다 !!
마지막엔 예측평점이 높은 영화들을 유저들에게 추천해주면 된다
2.6 (실습) sklearn으로 유저 평점 예측하기
이번 과제에서는 sklearn 라이브러리를 사용해서 선형 회귀로 직접 유저 평점을 예측해 보겠습니다.
수행할 내용들은 아래 3 가지입니다.
- LinearRegression을 사용해서 선형 회귀 모델을 만드세요.
- training set 데이터(X_train, y_train)를 사용해서 선형 회귀 모델을 학습시키세요.
- 학습시킨 모델을 사용해서 'X_test'에 대해 예측해 보세요. (결괏값은 꼭 y_test_predict 변수에 저장해 주세요!)
code
# 필요한 도구들을 가지고 오는 코드
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
# 유저 평점 + 영화 속성 데이터 경로 정의
MOVIE_DATA_PATH = './data/movie_rating.csv'
# pandas로 데이터 불러 오기
movie_rating_df = pd.read_csv(MOVIE_DATA_PATH)
features =['romance', 'action', 'comedy', 'heart-warming'] # 사용할 속성들 이름
# 입력 변수와 목표 변수 나누기
X = movie_rating_df[features]
y = movie_rating_df[['rating']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5)
# 선형회귀 모델 정의
model = LinearRegression()
# 선형회귀 모델 학습시키기
model.fit(X_train, y_train)
# 데이터에 대한 예측값들을 리턴받음
y_test_predict = model.predict(X_test)
# 테스트 코드
y_test_predict2.7 내용 기반 추천 장단점
내용 기반 추천 장점
- 상품을 추천할 때 다른 유저 데이터가 필요하지 않다
- 새롭게 출시한 상품이나, 인기가 없는 상품을 추천할 수 있다
내용 기반 추천 단점
- 적합한 속성을 고르는 것이 어렵다
- 고른 속성 값들이 주관적으로 선정될 수 있다
- 유저가 준 데이터를 벗어나는 추천을 할 수 없다
- 인기가 많은 상품들을 더 추천해 줄 수 없다
