
3.1 협업 필터링이란?
내용 기반 추천 : 상품의 속성, 즉 '어떤' 상품인지를 사용해서 추천
ㄴ 한 유저의 평점이 다른 유저의 평점에 영향을 미치지 않는다
-> 유저들이 평점이 서로 독립적이다
ex)
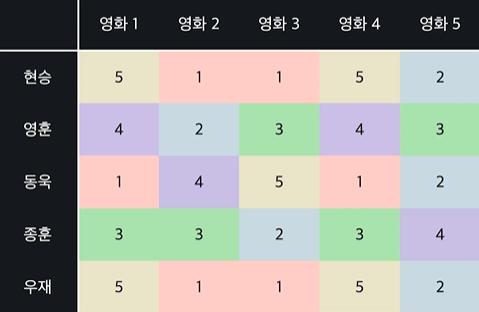
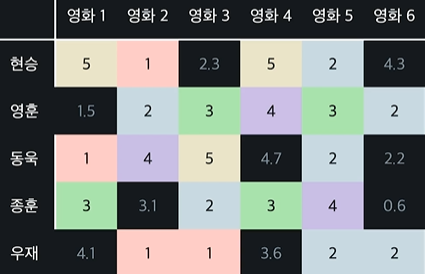
- 우재와 현승은 같은 평점을 줌 = 영화 취향이 같은 사람
- 영화 1과 영화 4를 보면 모든 사람이 같은 평점을 줌 = 둘이 비슷한 영화
협업 필터링
: 수많은 유저 데이터들이 협업해서 상품을 추천
ex) 유저 현승에게 영화 추천
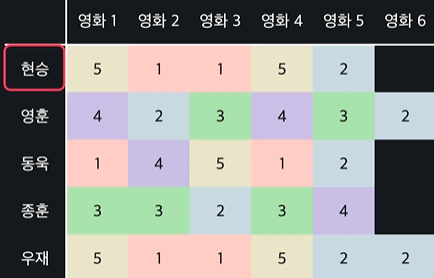
- 현승과 비슷한 유저 100명을 찾는다
- 비슷한 유저는 비슷한 영화를 좋아한다는 가설을 바탕으로 현승 유저가 평가하지 않은 영화들의 평점을 평가해줌
3.2 데이터 표현하기
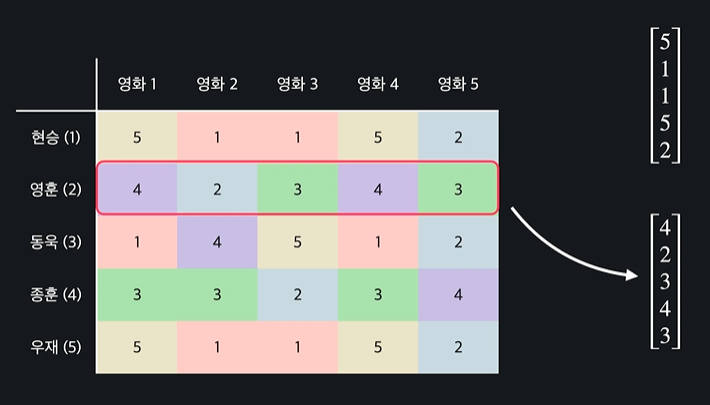
평점을 벡터 형식으로 묶어서 만들기
이렇게 하면

이런식으로 r을 써서 일반화 가능하고 유저 a의 평점 백터를 r^(a)라고 한다
3.3 비슷한 유저 정의하기 I : 유클리드 거리

이걸 일직선에 표시하면
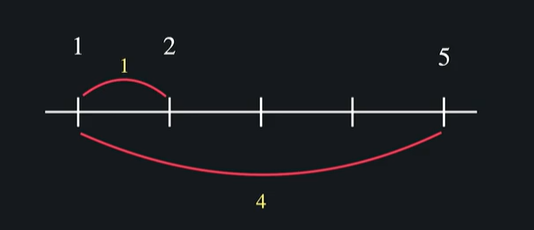
이렇게 표현이 되고 거리를 나타낼 수 있다 -> 1과 2가 더 비슷하다 !!
그렇다면 이 벡터들은 어떻게 거리를 비교할 수 있을까 ?

이 데이터들을 좌표로 표현할 수 있다
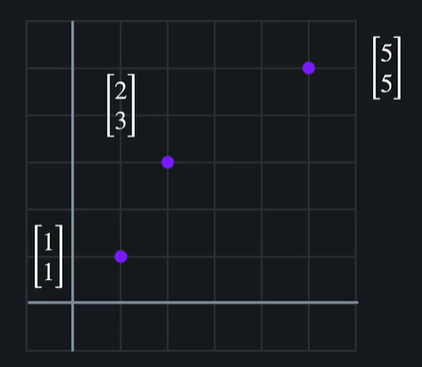
두 점 사이의 거리를 사용해서 (1,1)과 (2,3)이 거리가 더 비슷하다고 볼 수 있다 !
평점이 세 개 이상일 때는 ?
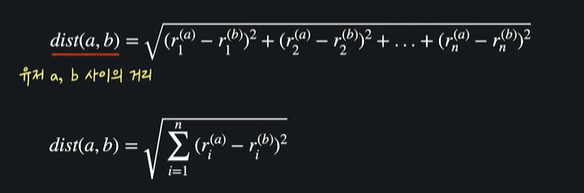
이렇게 할 수 있다. 이 거리를 유클리드 거리 라고 한다
유클리드 거리가 작을 수록 비슷하고, 멀 수록 비슷하지 않다

현승과 동욱 사이의 거리
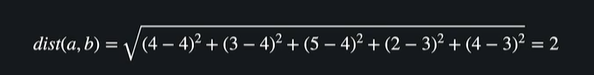
현승과 영훈 사이의 거리
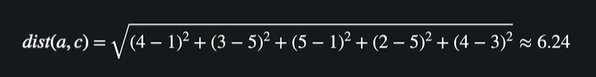
현승과 동욱의 거리가 현승과 영훈의 거리보다 더 짧다 = 현승이 동욱과 더 비슷한 유저이다
3.4 numpy 연산 복습 노트
갑자기 왜 나온지는 모르겠지만 .. 일단 있으니까 쓴다
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, 2, 3, 1],
[3, 1, 4, 3, 1],
])
B = np.array([
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
])이런 두 행렬이 있다고 치고 사칙 연산은
- A + B
- A - B
- A * B
- A / B
로 간단히 할 수 있다
그리고 numpy에선 비어있는 값/ 요소를 nan으로 표시함
사칙 연산의 앞이나 뒤 행렬 중 하나라도 nan값이 있으면 결괏값에 원소도 nan으로 표시됨
ex)
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, np.nan, 3, 1],
[3, 1, 4, 3, 1],
])
B = np.array([
[1, np.nan, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[np.nan, 4, 4, 4, 4],
])
A + Boutput
array([[ 4., nan, 3., 4., 2.],
[ 7., 4., 4., 5., 3.],
[ 6., 6., nan, 6., 4.],
[nan, 5., 8., 7., 5.]])numpy 행렬 모든 원소에 하나의 수를 곱해주고 싶을 떄는 그냥 행렬과 숫자를 * 연산자를 사용해서 곱해주면 됨
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, 2, 3, 1],
[3, 1, 4, 3, 1],
])
5 * Aoutput
\array([[15, 15, 10, 15, 5],
[25, 10, 10, 15, 5],
[15, 15, 10, 15, 5],
[15, 5, 20, 15, 5]])두 행렬을 그냥 곱하고 싶을 때는 @를 사용하자 !
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, 2, 3, 1],
[3, 1, 4, 3, 1],
])
B = np.array([
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
[1, 2, 3, 4, 5],
])
A @ Boutput
array([[12, 24, 36, 48, 60],
[13, 26, 39, 52, 65],
[12, 24, 36, 48, 60],
[12, 24, 36, 48, 60]])3.5 numpy 기본 함수
np.sum함수
: 파라미터로 넘겨주는 행렬 안에 있는 모든 원소들의 합을 구해주는 함수이다
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, 2, 3, 1],
[3, 1, 4, 3, 1],
])
np.sum(A)output
49행렬 안에 nan값이 있으면 항상 np.sum 함수도 nan을 리턴한다 ! nan 값들만 제외하고 계산을 하고 싶을 때는 np.nansum이라는 함수를 사용하자
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, np.nan, 3, 1],
[3, 1, 4, 3, 1],
])
np.nansum(A)output
47.0np.mean함수
: 행렬의 모든 원소들의 평균 값을 계산해 주는 함수
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, 2, 3, 1],
[3, 1, 4, 3, 1],
])
np.mean(A)output
2.45ㄴ 원소 중 단 한 개라도 nan 값이면 결과도 nan값이 되기 때문에 똑같이 그럴땐 np.nanmean을 쓴다
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, np.nan, 3, 1],
[3, 1, 4, 3, 1],
])
np.nanmean(A)output
2.4736842105263163.6 numpy 데이터 접근법
- 기본 인덱스 접근법
A의 0번째 행에 접근하고 싶으면 A[0], 3번째 행에 접근하고 싶으면 A[3] 이런식
A = np.array([
[3, 3, 2, 3, 1],
[5, 2, 2, 3, 1],
[3, 3, 2, 3, 1],
[3, 1, 4, 3, 1],
])
A[0] # array([3, 3, 2, 3, 1]) 리턴
A[3] # array([3, 1, 4, 3, 1]) 리턴0행 3열에 접근하고 싶으면 A[0][3]으로 쓰면 된다
- 열 접근법
3열에 접근하고 싶으면 A[:,3] 이렇게 쓰자
A[:, 3] # array([3, 3, 3, 3])행도 이런식으로 똑같이 접근할 수 있다. 이건 반대로 A[3,:] 이런 식
A[3, :] # array([3, 1, 4, 3, 1]) 리턴3.7 (실습) numpy로 유저 간 거리 구하기
두 벡터 사이의 거리 수학 공식
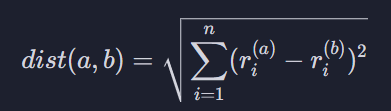
두 유저들이 각 영화에 준 평점들의 차이를 제곱해서 다 더한 후, 제곱근을 씌워줌
distance() 함수
distance 함수는 파라미터로 두 유저 평점 벡터 user_1과 user_2를 받습니다. 그리고 이 두 유저 벡터 사이의 거리를 리턴합니다.
np.sum() 메소드
numpy의 sum() 메소드를 사용하면, numpy 배열 안에 있는 모든 원소들의 합을 리턴해 줍니다. 아래 예시를 참고해 주세요.
vector_1 = np.array([1, 2, 3, 4, 5])
np.sum(vector_1) # 15 리턴sqrt() 함수
파이썬 math 모듈의 sqrt 함수는 주어진 숫자의 제곱근을 리턴해 줍니다. 아래 예시 코드를 참고해 주세요.
sqrt(4) # 2.0 리턴
sqrt(9) # 3.0 리턴code
import numpy as np
from math import sqrt
def distance(user_1, user_2):
sum = (user_1 - user_2) ** 2 # 두 유저 벡터들의 원소 간 차이
res = np.sum(sum) # 차이 값들의 제곱 계산
return sqrt(res) # 제곱근 씌워서 리턴
# 테스트 코드
user_1 = np.array([0, 1, 2, 3, 4, 5])
user_2 = np.array([0, 1, 4, 6, 1, 4])
distance(user_1, user_2)3.8 비슷한 유저 정의하기 II : 코사인 유사도
코사인 유사도를 사용할 때는 점이 아닌 선을 이용하고 두 선 사이의 각도를 이용함
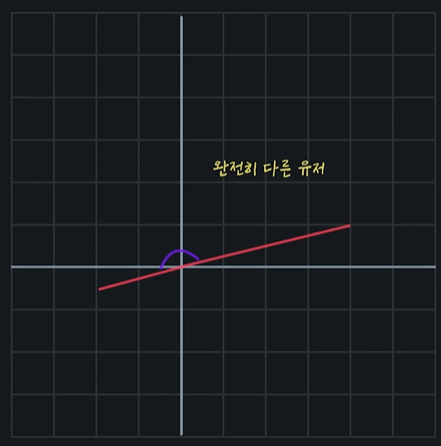
완전 정반대의 선이 그어져서 각도가 180도가 나오면 완전히 다른 유저인 것이고
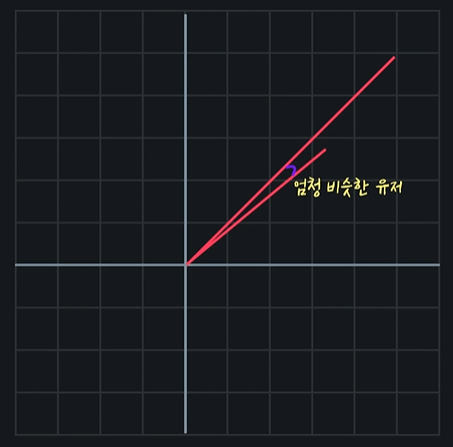
두 선이 거의 겹치면 취향이 비슷한 유저인 것이다
이렇게 해서 생긴 각도를 코사인 함수에 넣어서 사용하는 것임 !
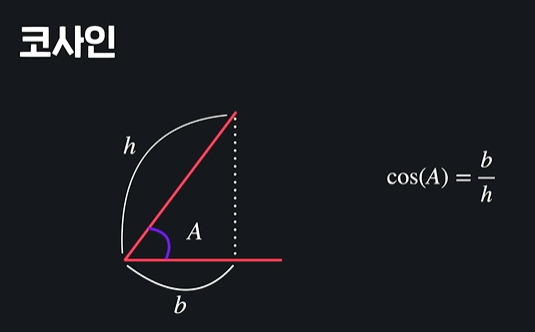
두 선이 완전히 겹칠 때 (각도가 0도일 때) -> cos(0) = 1
두 선이 완전히 반대일 때 (각도가 180도 일 때) -> cos(180) = -1
두 선이 완전히 직각일 때 (각도가 90도일 때) -> cos(90) = 0
데이터가 비슷할수록 크고, 다를수록 작다 -> 유사도로 사용하기 좋음
공식
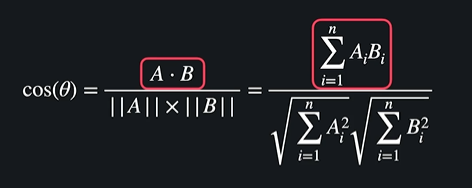
하나하나 봐보자면
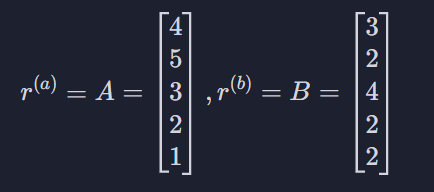
이런 벡터가 있다 치고
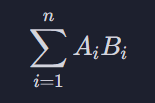
이걸 벡터의 내적곱이라고 한다. 각 벡터의 첫 번째 원소를 곱하고, 두번째 원소를 곱하고 쭉 그러겠다는 뜻 (12 + 10 + 12 + 4 + 2)
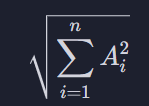
이 시그마의 내용은 A의 모든 원소들을 제곱해서 이걸 다 더하고 거기에 제곱근을 씌워주겠다는 뜻 √(16 + 25 + 9 + 4 + 1)
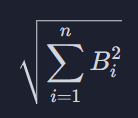
이 부분은 방금 한 걸 B에 대해 하겠다는 뜻 √(9 + 4 + 16 + 4 + 4)
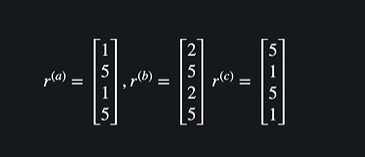
이런 벡터가 있을 때 )
a와 b의 유사도 : 0.983
a와 c의 유사도 : 0.384
-> a와 b가 훨씬 비슷하다
3.9 평점 데이터 전처리
아까 전에는 A와 B의 모든 원소에 값이 있다고 가정 했는데 평점 데이터는 사실
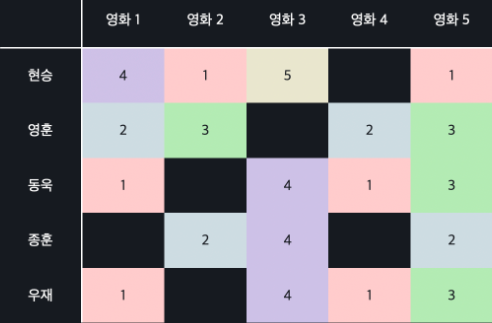
이렇게 군데군데 비어있을 수 밖에 없다
거리 또는 유사도를 측정할 때 비어있는 데이터들을 처리할 수 있는 방법 !! 알아보기
0으로 계산하기
: 모두 0으로 생각하고 유사도를 계산하는 것
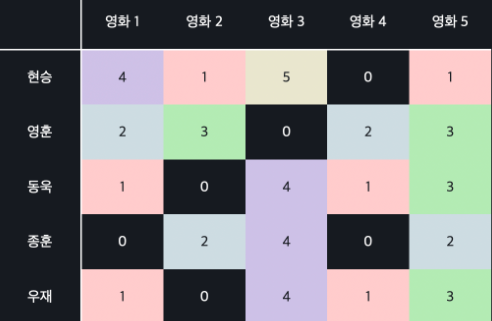
이런식으로 ㅇㅇ
하지만 이 방법에 문제는 추천시스템이 0은 최악의 평점으로 계산된다는 뜻
= 당순히 평점을 안 준 것 뿐인데 유저가 싫어하는 영화로 계산이 되면 추천 시스템의 정확도가 별로 안 좋게 나오게 됨
유저 별 평균 평점으로 계산하기
비어있는 값들을 유저의 평균 평점으로 채워 넣는 방법
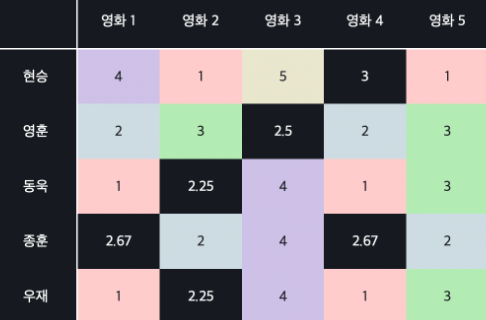
이러면 유저의 준 평점들의 평균은 유저가 좋아하지도, 싫어하지도 않는다고 해석할 수 있음 ( 0을 사용하는 것 보다는 합리적으로 유사도를 계산할 수 있다 )
Mean Normalization으로 계산하기
빈값을 모두 유저 별 평균 평점으로 채워 넣었다고 하고 각 유저 평점에서 각 유저의 평균 평점을 다시 빼주는 것
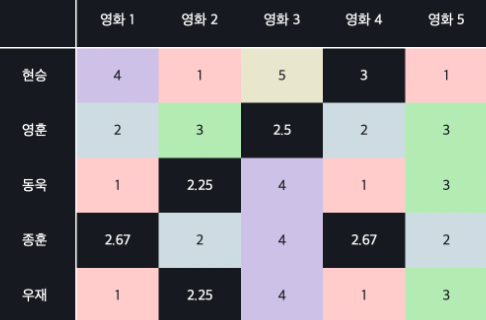
이렇게 평점을 채워넣고
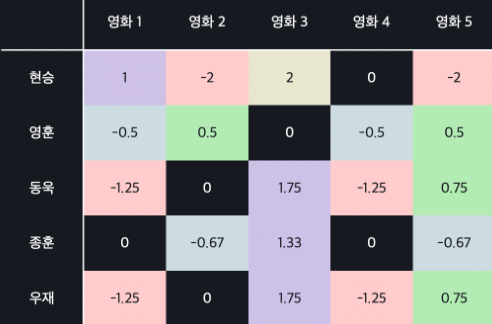
빼준다 ㅇㅇ
장점 - 모르는 값들을 합리적으로 채워 넣을 수 있고 까다로운 유저들과 유한 유저들에 대한 처리를 해줄 수 있음
3.10 유클리드 거리 vs 코사인 유사도
유클리드 거리와 코사인 유사도의 직관적인 차이는 각 벡터 또는 선의 크기가 중요하지 않다는 것이다 !
ex) 추천 시스템을 만들 때 평점 데이터가 아니라 유저가 특정 물품을 몇개 샀는지를 사용
첫 번째 원소 : 닭 가슴살, 두 번째 원소 : 아령, 세 번째 원소 : 맥주, 네 번째 원소 : 피자
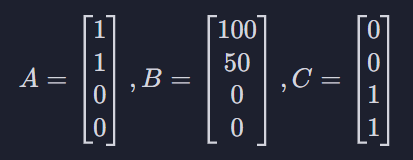
이 유저 A는 닭가슴살과 아령을 하나씩, B는 닭 가슴살 백개와 아령을 오십개, C는 맥주와 피자를 하나씩 삼
딱 보았을 때 A와 B가 A와 C보다 훨씬 더 비슷한 구매 취향을 갖고 있는 유저인 것 같음. 거리를 사용하면 B는 벡터가 엄청 길어서 A 다른 유저로 계산됨 = A와 B보다 A와 C가 훨씬 더 비슷하다고 나오는 것
하지만 코사인 유사도를 사용하면 A와 B 벡터의 방향이 비슷해서 A와 B가 A와 C보다 더 비슷하다고 나온다 !!
유클리드 거리
= 거리가 클 수록 두 데이터가 다르고, 작을수록 두 데이터가 비슷하다는 뜻
( 유저 A와 가장 비슷한 유저를 찾으려면 거리가 가장 작은 유저를 찾아야 됨 )
코사인 유사도
= 두 데이터가 비슷하고, 작을수록 두 데이터가 다르다는 뜻
( 유저 A와 가장 비슷한 유저를 찾으려면 거리가 가장 큰 유저를 찾아야 됨 )
3.11 상품 추천하기

이걸 간단하게
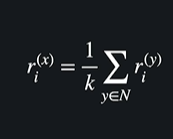
시그마 밑에는 이웃에 속한 각각 유저 y에 대해서 유저 x의 이웃들의 영화 i에 대한 평점을 더해주겠다는 뜻
k는 이웃들의 숫자
= 이웃들의 영화 i에 대한 평균
이 공식을 써서 유저 별로 예측 평점이 높은 영화들을 추천해준다
3.12 (실습) 이웃들 구하기
이번 레슨에서는 평점 데이터가 주어졌을 때 그 안에서 특정 유저와 비슷한 k 명의 이웃들을 구하는 함수, get_k_neighbors() 함수를 구현해 보겠습니다.
distance()함수
지난 과제에서 구현했던, 두 유저 간의 유클리드 거리를 계산해 주는 함수입니다. 파라미터로는 두 유저의 평점 벡터를 받아서 거리를 리턴합니다.
def distance(user_1, user_2):
"""유클리드 거리를 계산해주는 함수"""
return sqrt(np.sum((user_1 - user_2)**2))filter_users_without_movie()함수
filter_users_without_movie() 함수는 파라미터로 평점 데이터 행렬과 영화 번호를 받아서 평점 데이터 행렬에서 해당 영화를 평가하지 않은 유저 정보를 미리 다 제거해 주는 함수입니다. 유저의 이웃을 구하는데 이웃들이 원하는 영화에 평점을 안 줬으면 어차피 사용할 수 없으니까 미리 없애주기 위해 있습니다.
def filter_users_without_movie(rating_data, movie_id):
"""movie_id 번째 영화를 평가하지 않은 유저들은 미리 제외해 주는 함수"""
return rating_data[~np.isnan(rating_data[:,movie_id])]fill_nan_with_user_mean함수
평점 데이터 행렬의 빈값들을 각 유저의 평균 평점으로 채워 넣어주는 함수입니다. 이 함수는 파라미터로 평점 데이터 행렬을 받고, 빈값들이 유저의 평균 평점으로 채워진 새로운 행렬을 리턴합니다.
def fill_nan_with_user_mean(rating_data):
"""평점 데이터의 빈값들을 각 유저 평균 값으로 채워 주는 함수"""
filled_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사
row_mean = np.nanmean(filled_data, axis=1) # 유저 평균 평점 계산
inds = np.where(np.isnan(filled_data)) # 비어 있는 인덱스들을 구한다
filled_data[inds] = np.take(row_mean, inds[0]) #빈 인덱스를 유저 평점으로 채운다
return filled_dataget_k_neighbors()함수 구현하기
def get_k_neighbors(user_id, rating_data, k):
"""user_id에 해당하는 유저의 이웃들을 찾아 주는 함수"""
distance_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사
# 마지막에 거리 데이터를 담을 열을 추가한다
distance_data = np.append(distance_data, np.zeros((distance_data.shape[0], 1)), axis=1)
# 여기에 코드를 작성하세요
# 데이터를 거리 열을 기준으로 정렬한다
distance_data = distance_data[np.argsort(distance_data[:, -1])]
# 가장 가까운 k개의 행만 리턴한다 + 마지막(거리) 열은 제외한다
return distance_data[:k, :-1]과제로는 위 함수, get_k_neighbors()를 구현합니다. get_k_neighbors() 함수는 파라미터로 몇 번째 유저인지를 user_id로, 평점 데이터를 rating_data로, 그리고 몇 명의 이웃들을 찾을지를 k로 받습니다. user_id는 그냥 각 행렬 안에서의 순서라고 생각하시면 됩니다. 그리고 user_id의 유저와 가장 가까운 k 명의 유저 평점 데이터를 리턴하죠.
이미 작성된 코드를 간단하게 설명해 드릴게요.
distance_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사distance_data에는 빈값이 없는 평점 데이터의 복사본이 저장돼 있습니다.
# 맨 뒤 위치에 거리 데이터를 담을 열을 추가한다
distance_data = np.append(distance_data, np.zeros((distance_data.shape[0], 1)), axis=1)그리고 이 복사본의 가장 뒤 열에는 각 행까지의 거리 정보를 저장할 새로운 열을 추가시켜 줬죠. 여러분이 작성하실 부분은, 이 새로운 열을 반복문을 통해 채워 넣는 겁니다. 주의하셔야 될 점은 각 행의 마지막 열은 거리 정보를 저장하는 열이기 때문에 거리 계산에서 제외해 줘야 합니다.
반복문을 돌면서 user_id 번째 유저가 나올 때는, 해당 데이터의 거리 정보는 무한대, np.inf로 저장해 주시면 됩니다.
과제는 이 마지막 열들을 모두 user_id 번째 유저와의 거리로 채우며 끝나는데요. 이걸 채워 넣으면 그 후에는 평점 데이터를 거리 열을 기준으로 정렬한 후, 마지막 열은 제외하고 가장 가까운 k개의 행, 그러니까 user_id 유저의 이웃들을 리턴해 줍니다.
# 데이터를 거리 열을 기준으로 정렬한다
distance_data = distance_data[np.argsort(distance_data[:, -1])]
# 가장 가까운 k개의 행만 리턴한다 + 마지막(거리) 열은 제외한다
return distance_data[:k, :-1]code
import pandas as pd
import numpy as np
from math import sqrt
RATING_DATA_PATH = './data/ratings.csv' # 받아올 평점 데이터 경로 정의
np.set_printoptions(precision=2) # 소수점 둘째 자리까지만 출력
def distance(user_1, user_2):
"""유클리드 거리를 계산해주는 함수"""
return sqrt(np.sum((user_1 - user_2)**2))
def filter_users_without_movie(rating_data, movie_id):
"""movie_id 번째 영화를 평가하지 않은 유저들은 미리 제외해주는 함수"""
return rating_data[~np.isnan(rating_data[:,movie_id])]
def fill_nan_with_user_mean(rating_data):
"""평점 데이터의 빈값들을 각 유저 평균 값으로 체워주는 함수"""
filled_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사
row_mean = np.nanmean(filled_data, axis=1) # 유저 평균 평점 계산
inds = np.where(np.isnan(filled_data)) # 비어 있는 인덱스들을 구한다
filled_data[inds] = np.take(row_mean, inds[0]) # 빈 인덱스를 유저 평점으로 채운다
return filled_data
def get_k_neighbors(user_id, rating_data, k):
"""user_id에 해당하는 유저의 이웃들을 찾아주는 함수"""
distance_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사
# 마지막에 거리 데이터를 담을 열 추가한다
distance_data = np.append(distance_data, np.zeros((distance_data.shape[0], 1)), axis=1)
for i in range(len(distance_data)): # distance_data 행렬의 행 살펴보기
row = distance_data[i] # 각 순서의 행들을 변수 row에 저장
if i == user_id: # 같은 유저면 거리를 무한대로 설정
row[-1] = np.inf # np.inf = 무한대를 의미
else: # 다른 유저면 마지막 열에 거리 데이터를 저장
row[-1] = distance(distance_data[user_id][:-1], row[:-1])
# 데이터를 거리 열을 기준으로 정렬한다
distance_data = distance_data[np.argsort(distance_data[:, -1])]
# 가장 가까운 k개의 행만 리턴한다 + 마지막(거리) 열은 제외한다
return distance_data[:k, :-1]
# 테스트 코드
# 영화 3을 본 유저들 중, 유저 0와 비슷한 유저 5명을 찾는다
rating_data = pd.read_csv(RATING_DATA_PATH, index_col='user_id').values # 평점 데이터를 불러온다
filtered_data = filter_users_without_movie(rating_data, 3) # 3 번째 영화를 보지 않은 유저를 데이터에서 미리 제외시킨다
filled_data = fill_nan_with_user_mean(filtered_data) # 빈값들이 채워진 새로운 행렬을 만든다
user_0_neighbors = get_k_neighbors(0, filled_data, 5) # 유저 0과 비슷한 5개의 유저 데이터를 찾는다
user_0_neighbors3.13 (실습) 유저 평점 예측하기
이번 과제에서는 특정 유저의 이웃들이 주어졌을 때, 해당 유저의 평점을 예측해 주는 함수를 작성해 보겠습니다. 유저 평점 예측은 이웃들이 해당 영화에 준 평점의 평균을 사용해서 계산합니다. (템플릿에 있는 함수들은 predict_user_rating을 제외하고 다 저번 과제에서 이미 본 함수들입니다.)
np.mean()함수
np.mean함수는 파라미터로 주어진 numpy 배열 원소들의 평균을 리턴해 주는 함수입니다. 이런 식으로 사용할 수 있습니다.
array_0 = np.array([0, 1, 2, 3, 4])
np.mean(array_0) # 평균 값인 2.5 리턴predict_user_rating() 함수 구현하기
def predict_user_rating(rating_data, k, user_id, movie_id,):
"""예측 행렬에 따라 유저의 영화 평점 예측 값 구하기"""
# movie_id 번째 영화를 보지 않은 유저를 데이터에서 미리 제외시킨다
filtered_data = filter_users_without_movie(rating_data, movie_id)
# 빈값들이 채워진 새로운 행렬을 만든다
filled_data = fill_nan_with_user_mean(filtered_data)
# 유저 user_id와 비슷한 k개의 유저 데이터를 찾는다
neighbors = get_k_neighbors(user_id, filled_data, k)
# 여기에 코드를 작성하세요지난 과제에서 작성한 코드를 사용해서 user_id 유저와 비슷한 k 명의 유저 데이터를 구했습니다.
함수 predict_user_rating은 평점 데이터 rating_data, 사용할 이웃 수 k, 유저 순서 user_id, 영화 순서 movie_id를 파라미터로 받아서 user_id 유저가 movie_id 번째 영화에 평점 몇 점을 줄지 예측합니다.
neighbors의 movie_id 영화에 대한 평균을 리턴해서 함수를 완성해 주세요.
code
import pandas as pd
import numpy as np
from math import sqrt
RATING_DATA_PATH = './data/ratings.csv' # 받아올 평점 데이터 경로 정의
np.set_printoptions(precision=2) # 소수점 둘째 자리까지만 출력
def distance(user_1, user_2):
"""유클리드 거리를 계산해주는 함수"""
return sqrt(np.sum((user_1 - user_2)**2))
def filter_users_without_movie(rating_data, movie_id):
"""movie_id 번째 영화를 평가하지 않은 유저들은 미리 제외해주는 함수"""
return rating_data[~np.isnan(rating_data[:,movie_id])]
def fill_nan_with_user_mean(rating_data):
"""평점 데이터의 빈값들을 각 유저 평균 값으로 체워주는 함수"""
filled_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사
row_mean = np.nanmean(filled_data, axis=1) # 유저 평균 평점 계산
inds = np.where(np.isnan(filled_data)) # 비어 있는 인덱스들을 구한다
filled_data[inds] = np.take(row_mean, inds[0]) #빈 인덱스를 유저 평점으로 채운다
return filled_data
def get_k_neighbors(user_id, rating_data, k):
"""user_id에 해당하는 유저의 이웃들을 찾아주는 함수"""
distance_data = np.copy(rating_data) # 평점 데이터를 훼손하지 않기 위해 복사
# 마지막에 거리 데이터를 담을 열 추가한다
distance_data = np.append(distance_data, np.zeros((distance_data.shape[0], 1)), axis=1)
# 코드를 쓰세요.
for i in range(len(distance_data)):
row = distance_data[i]
if i == user_id: # 같은 유저면 거리를 무한대로 설정
row[-1] = np.inf
else: # 다른 유저면 마지막 열에 거리 데이터를 저장
row[-1] = distance(distance_data[user_id][:-1], row[:-1])
# 데이터를 거리 열을 기준으로 정렬한다
distance_data = distance_data[np.argsort(distance_data[:, -1])]
# 가장 가까운 k개의 행만 리턴한다 + 마지막(거리) 열은 제외한다
return distance_data[:k, :-1]
def predict_user_rating(rating_data, k, user_id, movie_id,):
"""예측 행렬에 따라 유저의 영화 평점 예측 값 구하기"""
# movie_id 번째 영화를 보지 않은 유저를 데이터에서 미리 제외시킨다
filtered_data = filter_users_without_movie(rating_data, movie_id)
# 빈값들이 채워진 새로운 행렬을 만든다
filled_data = fill_nan_with_user_mean(filtered_data)
# 유저 user_id와 비슷한 k개의 유저 데이터를 찾는다
neighbors = get_k_neighbors(user_id, filled_data, k)
# 유저 이웃 데이터 행렬에서 movie_id 번째 열만 접근하고 싶을 때는 neighbors[:, movie_id]로 써야함 (= 이웃 유저들이 movie_id 번쨰 영화에 준 평점 데이터 )
n = neighbors[:, movie_id]
return np.mean(n)
# 테스트 코드
# 평점 데이터를 불러온다
rating_data = pd.read_csv(RATING_DATA_PATH, index_col='user_id').values
# 5개의 이웃들을 써서 유저 0의 영화 3에 대한 예측 평점 구하기
predict_user_rating(rating_data, 5, 0, 3) 3.14 상품 기반 협업 필터링
유저 기반 협업 필터링을 배웠다면 상품 기반 협업 필터링도 있음
ex) 상품 기반 협업 필터링으로 우재가 영화4에 어떤 점수를 줄지 예측
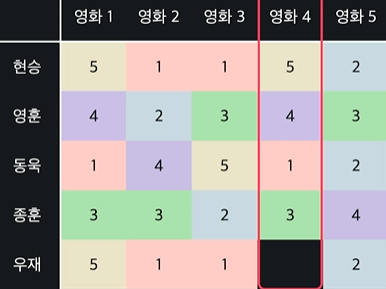
유사도 사용해서 영화 4와 비슷한 영화들 찾기
-> 거리나 코사인 유사도를 써서 유사도를 찾으면 됨
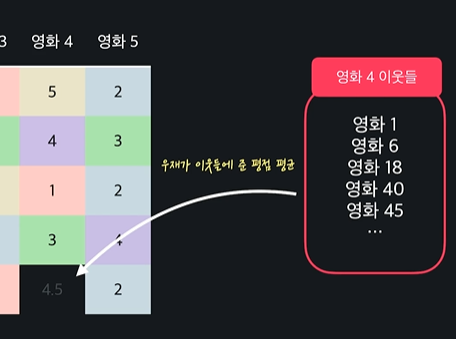
비슷한 영화들의 평점을 내서 우재의 평점을 예측
예측값이 높으면 우재에게 추천, 안 높으면 추천 안해주면 됨
상품 기반 협업 필터링 : 비슷한 상품을 써서 예측
유저 vs 상품 기반 협업 필터링
- 이론상으로 유저와 상품 기반 협업 필터링은 큰 차이가 없다
- 하지만 실전에서는 상품 기반 협업 필터링이 더 성능이 좋은 경우가 많다 (유저들이 상품보다 복잡하기 때문)
3.15 상품 기반 협업 필터링 수학
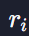
: 영화 i에 대한 평점 데이터 벡터
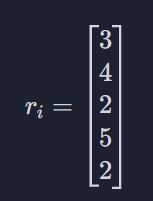
먼저 r 하고 오른쪽 아래에 i가 있는 표현은 영화 i의 영화 평점 벡터를 나타냅니다. 보시는 벡터에서 첫 번째 유저는 3점, 두 번째 유저는 4점을 준 거죠.
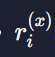
: 유저 x의 영화 i에 대한 평점
N : 유저 x가 평가한 영화 중, 영화 i와 가장 비슷한 영화 k개의 집합
비슷한 영화는 유클리드 거리, 코사인 유사도, 또는 다른 유사도의 척도를 써서 구합니다.
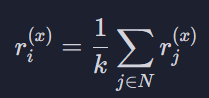
왼쪽 식 = 유저 x의 영화 i에 대한 평점
오른쪽 = 시그마 밑에 이웃에 속한 모든 영화들, j에 대해서 오른쪽 항, 유저 x의 평점을 다 더해주겠다는 뜻
3.16 협업 필터링 장단점
장점
- 속성을 찾거나 정할 필요가 없다
(비슷한 유저와 상품을 오로지 평점 데이터로만 찾아내기 때문에 상관이 없어진다) - 좀 더 폭넓은 상품을 추천할 수 있다
- 내용 기반 추천보다 성능이 더 좋게 나오는 경우가 많다
단점
- 데이터가 많아야 한다 (유저 한 명이 열심히 평점을 줘도 다른 사람들도 열심히 평점을 줘야 한다, 새로운 물건이나 유저에게 추천해 주기 힘들다)
- 인기가 많은 소수의 상품이 추천 시스템을 장악할 수 있다
- 어떤 상품이 왜 추천됐는지 정확히 알기 힘들다

여러 방식을 합쳐서 사용하면 모델들의 단점을 보완하면서 장점을 살릴 수 있다 !!
